开源公司黄页 关于/ 阿里巴巴的50款开源软件[大部分为Java语言]
服务框架 Dubbo
Dubbo 是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
主要核心部件:
Remoting: 网络通信框架,实现了 sync-over-async 和 request-response 消息机制.
RPC: 一个远程过程调用的抽象,支持负载均衡、容灾和集群功能
Registry: 服务目录框架用于服务的注册和服务事件发布和订阅
Dubbo工作原理
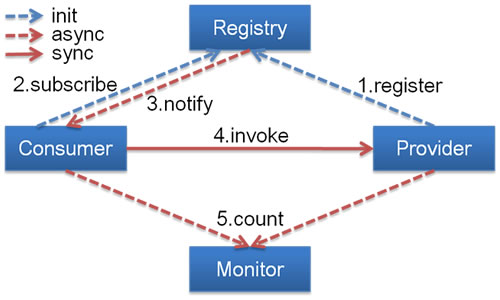
Provider
暴露服务方称之为“服务提供者”。
Consumer
调用远程服务方称之为“服务消费者”。
Registry
服务注册与发现的中心目录服务称之为“服务注册中心”。
Monitor
统计服务的调用次调和调用时间的日志服务称之为“服务监控中心”。
(1) 连通性:
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
(2) 健状性:
监控中心宕掉不影响使用,只是丢失部分采样数据
数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
注册中心对等集群,任意一台宕掉后,将自动切换到另一台
注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
服务提供者无状态,任意一台宕掉后,不影响使用
服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
(3) 伸缩性:
注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
JDBC连接池、监控组件 Druid
Druid是一个JDBC组件,它包括三部分:
DruidDriver 代理Driver,能够提供基于Filter-Chain模式的插件体系。
DruidDataSource 高效可管理的数据库连接池。
SQLParser
Druid可以做什么?
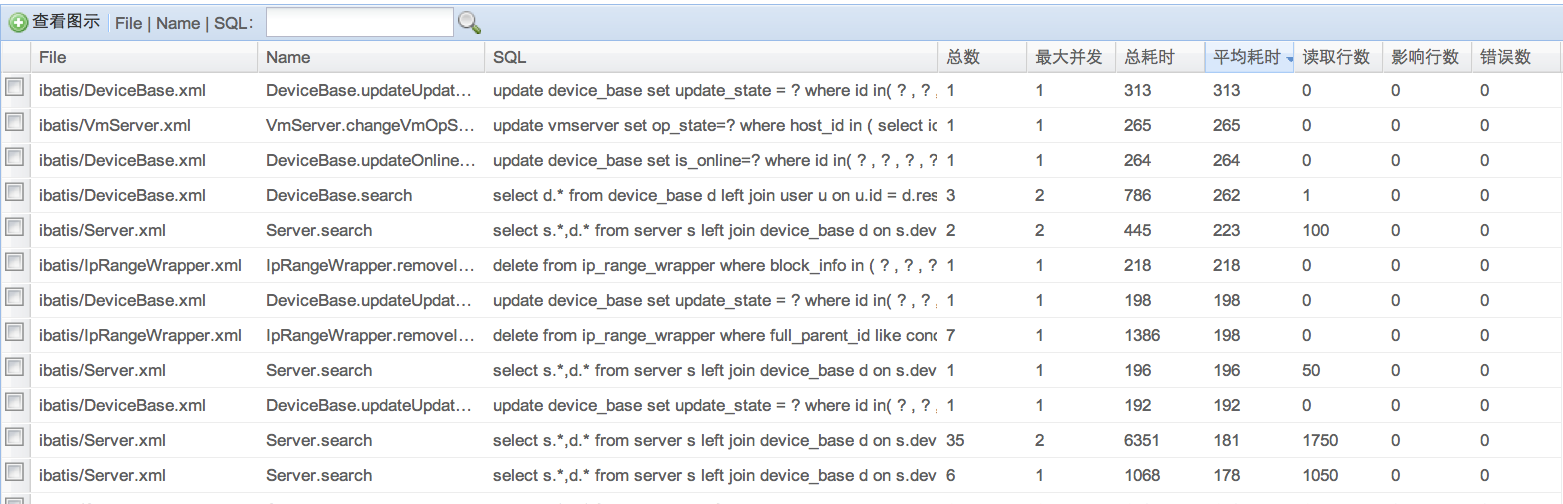
1) 可以监控数据库访问性能,Druid内置提供了一个功能强大的StatFilter插件,能够详细统计SQL的执行性能,这对于线上分析数据库访问性能有帮助。
2) 替换DBCP和C3P0。Druid提供了一个高效、功能强大、可扩展性好的数据库连接池。
3) 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver和DruidDataSource都支持PasswordCallback。
4) SQL执行日志,Druid提供了不同的LogFilter,能够支持Common-Logging、Log4j和JdkLog,你可以按需要选择相应的LogFilter,监控你应用的数据库访问情况。
扩展JDBC,如果你要对JDBC层有编程的需求,可以通过Druid提供的Filter-Chain机制,很方便编写JDBC层的扩展插件。
如下是一个基于Druid内置扩展StatFilter的监控实现:
Druid 的 JavaDoc 文档请看
http://tool.oschina.net/apidocs/apidoc?api=druid0.26
Java的JSON处理器 fastjson
fastjson 是一个性能很好的 Java 语言实现的 JSON 解析器和生成器,来自阿里巴巴的工程师开发。
主要特点:
快速FAST (比其它任何基于Java的解析器和生成器更快,包括jackson)
强大(支持普通JDK类包括任意Java Bean Class、Collection、Map、Date或enum)
零依赖(没有依赖其它任何类库除了JDK)
示例代码:
import com.alibaba.fastjson.JSON;Group group = new Group();
group.setId(0L);
group.setName("admin");User guestUser = new User();
guestUser.setId(2L);
guestUser.setName("guest");User rootUser = new User();
rootUser.setId(3L);
rootUser.setName("root");group.getUsers().add(guestUser);
group.getUsers().add(rootUser);
String jsonString = JSON.toJSONString(group);
System.out.println(jsonString);淘宝Hadoop作业平台 宙斯Zeus
宙斯(zeus)是什么
宙斯是一个完整的Hadoop的作业平台
从Hadoop任务的调试运行到生产任务的周期调度 宙斯支持任务的整个生命周期
从功能上来说,支持:
Hadoop MapReduce任务的调试运行
Hive任务的调试运行
Shell任务的运行
Hive元数据的可视化查询与数据预览
Hadoop任务的自动调度
完整的文档管理
宙斯开源,不仅仅是开源技术,更是开源产品
开发中心,一个文档管理,开发调试的环境,在任务上线前的主要工作区域
 调度中心,生产任务的调度环境,当任务调试通过后,在此处配置调度信息进行生产调度
调度中心,生产任务的调度环境,当任务调试通过后,在此处配置调度信息进行生产调度

宙斯运行原理



使用指南
快速启动(Quick Start):
1.设置配置项
在/web/src/main/filter/antx.properties 中对配置项进行设置
设置完成后,复制到${user.home}/antx.properties处
2.pom.xml本地jar地址修改
在/web/pom.xml中修改properties中的local.highcharts
因为此jar不在maven仓库中,此jar已经在/web/libs/highcharts-1.4.0.jar
将systemPath路径设置为绝对路径
3.数据库配置
zeus数据库:/web/src/main/resources/persistence.xml中对数据库进行配置
hive元数据库:/web/src/main/resources/templates/hive-site.xml中对Hive metastore数据库进行配置
4.打包
mvn package
打包在/web/target/exploded/zeus-web.war下
使用tomcat之类容器运行即可
以上步骤可以保证这个web项目正常启动,如果需要正式上线此项目,还需要配置以下内容:
1.动态模板配置
宙斯系统中有很多模板是可以动态修改的,包括以下一些,建议在正式运行之前都配置好
首页展示内容 启动后参见页面指南
首页通知内容 启动后参见页面指南
hive 默认udf函数 com.taobao.zeus.jobs.sub.HiveJob实现TODO内容
2.登陆系统
宙斯不包含单独的注册系统
建议使用单点登陆来实现登陆
大致原理:
(1) web.xml添加一个filter,用来跳转到单点登陆系统
(2) Spring容器中添加一个Bean,实现com.taobao.zeus.web.Login.Filter.SSOLogin接口
3.配置hadoop相关环境 默认的hadoop-site.xml和hive-site.xml在 /web/src/main/resources/templates下
修改相应的配置以对应相应的hadoop集群
4.超级管理员配置 在com.taobao.zeus.store.Super中进行配置
分布式消息中间件 Metamorphosis
Metamorphosis (MetaQ) 是一个高性能、高可用、可扩展的分布式消息中间件,类似于LinkedIn的Kafka,具有消息存储顺序写、吞吐量大和支持本地和XA事务等特性,适用于大吞吐量、顺序消息、广播和日志数据传输等场景,在淘宝和支付宝有着广泛的应用,现已开源。
总体结构:
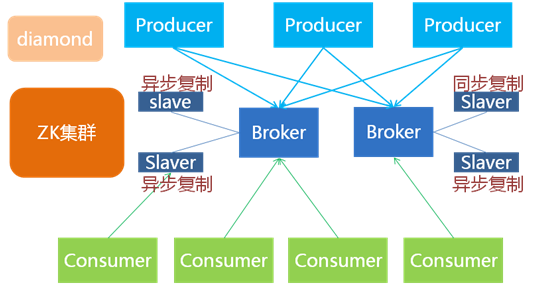
内部结构:
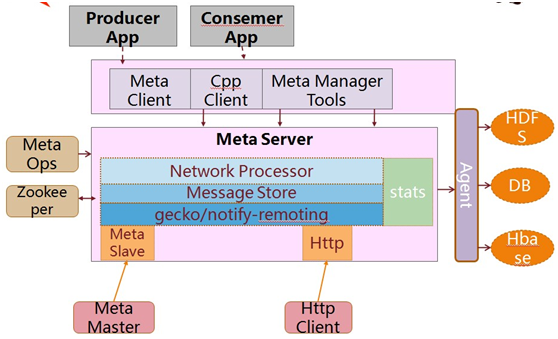
主要特点:
生产者、服务器和消费者都可分布
消息存储顺序写
性能极高,吞吐量大
支持消息顺序
支持本地和XA事务
客户端pull,随机读,利用sendfile系统调用,zero-copy ,批量拉数据
支持消费端事务
支持消息广播模式
支持异步发送消息
支持http协议
支持消息重试和recover
数据迁移、扩容对用户透明
消费状态保存在客户端
支持同步和异步复制两种HA
支持group commit
更多……
阿里巴巴分布式数据库同步系统 otter
otter 基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统。
工作原理:
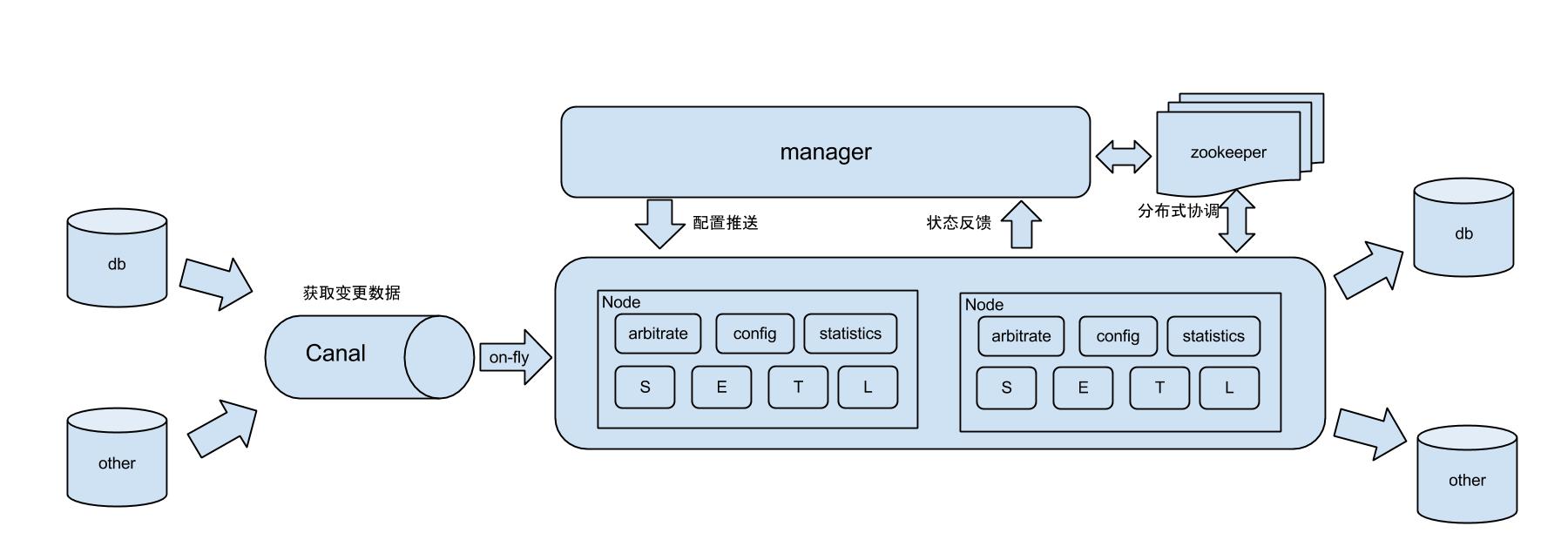
原理描述:
1. 基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, 请点击
2. 典型管理系统架构,manager(web管理)+node(工作节点)
a. manager运行时推送同步配置到node节点
b. node节点将同步状态反馈到manager上
3. 基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.
Oracle数据迁移同步工具 yugong
yugong 是阿里巴巴推出的去Oracle数据迁移同步工具(全量+增量,目标支持MySQL/DRDS)
08年左右,阿里巴巴开始尝试MySQL的相关研究,并开发了基于MySQL分库分表技术的相关产品,Cobar/TDDL(目前为阿里云DRDS产品),解决了单机Oracle无法满足的扩展性问题,当时也掀起一股去IOE项目的浪潮,愚公这项目因此而诞生,其要解决的目标就是帮助用户完成从Oracle数据迁移到MySQL上,完成去IOE的第一步.
整个数据迁移过程,分为两部分:
全量迁移
增量迁移

过程描述:
增量数据收集 (创建oracle表的增量物化视图)
进行全量复制
进行增量复制 (可并行进行数据校验)
原库停写,切到新库
架构
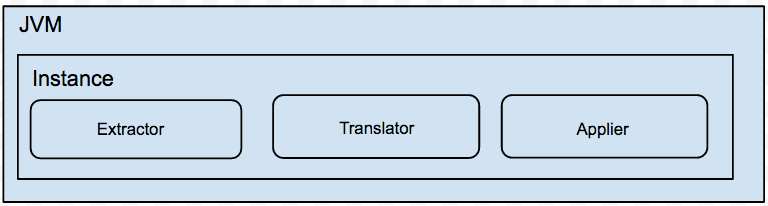
说明:
一个Jvm Container对应多个instance,每个instance对应于一张表的迁移任务
instance分为三部分
a. extractor (从源数据库上提取数据,可分为全量/增量实现)
b. translator (将源库上的数据按照目标库的需求进行自定义转化)
c. applier (将数据更新到目标库,可分为全量/增量/对比的实现)
非侵入式运行期 AOP 框架 Dexposed
Dexposed 是阿里巴巴无线事业部第一个重量级 Andorid 开源软件,基于 ROOT 社区著名开源项目 Xposed 改造剥离了 ROOT 部分,演化为服务于所在应用自身的 AOP 框架。它支撑了阿里大部分 App 的在线分钟级客户端 bugfix 和线上调试能力。
Dexposed 的 AOP 是实现了纯非侵入式,没有任何注释处理器,weaver 或者字节码重写程序。Dexposed 的集成非常简单,就像加载一个 JNI 库一样,只需要在初始化的时候插入一行代码。
经典用例
典型的 AOP 编程
仪表化 (测试,性能监控等等)
在线热修复(重要,关键,安全漏洞等等)
SDK hooking,更好的开发体验
Gradle 依赖:
native_dependencies {artifact 'com.taobao.dexposed:dexposed_l:0.2+:armeabi'artifact 'com.taobao.dexposed:dexposed:0.2+:armeabi'
}
dependencies {compile files('libs/dexposedbridge.jar')
}初始化:
public class MyApplication extends Application {@Override public void onCreate() { // Check whether current device is supported (also initialize Dexposed framework if not yet)if (DexposedBridge.canDexposed(this)) {// Use Dexposed to kick off AOP stuffs....}}...
}基础使用示例代码1:
// Target class, method with parameter types, followed by the hook callback (XC_MethodHook).DexposedBridge.findAndHookMethod(Activity.class, "onCreate", Bundle.class, new XC_MethodHook() {// To be invoked before Activity.onCreate().@Override protected void beforeHookedMethod(MethodHookParam param) throws Throwable {// "thisObject" keeps the reference to the instance of target class.Activity instance = (Activity) param.thisObject;// The array args include all the parameters.Bundle bundle = (Bundle) param.args[0];Intent intent = new Intent();// XposedHelpers provide useful utility methods.XposedHelpers.setObjectField(param.thisObject, "mIntent", intent);// Calling setResult() will bypass the original method body use the result as method return value directly.if (bundle.containsKey("return"))param.setResult(null);}// To be invoked after Activity.onCreate()@Override protected void afterHookedMethod(MethodHookParam param) throws Throwable {XposedHelpers.callMethod(param.thisObject, "sampleMethod", 2);}});基础使用示例代码2:
DexposedBridge.findAndHookMethod(Activity.class, "onCreate", Bundle.class, new XC_MethodReplacement() {@Override protected Object replaceHookedMethod(MethodHookParam param) throws Throwable {// Re-writing the method logic outside the original method context is a bit tricky but still viable....}});Android 应用热修复工具 AndFix
AndFix 是阿里巴巴开源的 Android 应用热修复工具,帮助 Anroid 开发者修复应用的线上问题。Andfix 是 "Android hot-fix" 的缩写。
AndFix 支持 Android 2.3 - 6.0,ARM 和 x86 架构,dalvik 运行时和 art 运行时。AndFix 的分支是 .apatch 文件。
AndFix 方法体取代实现规则:
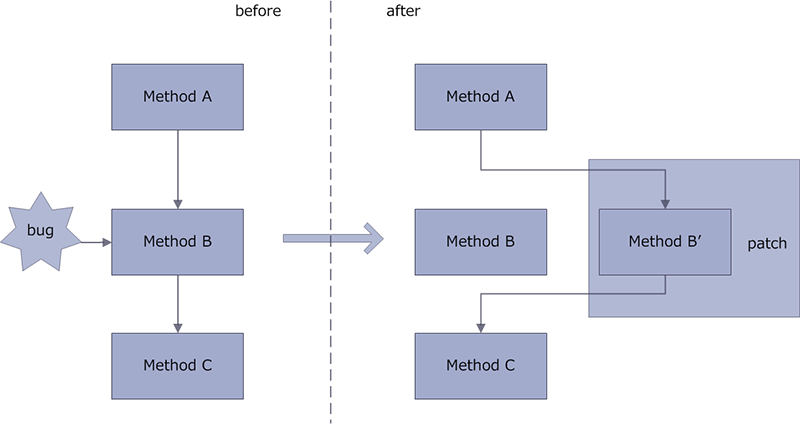
Bug 修复过程:
使用
生成 .apatch 文件:
usage: apkpatch -f <new> -t <old> -o <output> -k <keystore> -p <***> -a <alias> -e <***>-a,--alias <alias> alias.-e,--epassword <***> entry password.-f,--from <loc> new Apk file path.-k,--keystore <loc> keystore path.-n,--name <name> patch name.-o,--out <dir> output dir.-p,--kpassword <***> keystore password.-t,--to <loc> old Apk file path.合并 .apatch 文件:
usage: apkpatch -m <apatch_path...> -k <keystore> -p <***> -a <alias> -e <***>-a,--alias <alias> alias.-e,--epassword <***> entry password.-k,--keystore <loc> keystore path.-m,--merge <loc...> path of .apatch files.-n,--name <name> patch name.-o,--out <dir> output dir.-p,--kpassword <***> keystore password.
分布式SQL引擎 Lealone
Lealone 为 HBase 提供一个分布式SQL引擎,尝试将BigTable(HBase)和 RDBMS (H2数据库) 结合的项目。
Lealone 发音 ['li:ləʊn] 这是我新造的英文单词,灵感来自于在淘宝工作期间办公桌上那些叫绿萝的室内植物,一直想做个项目以它命名。 绿萝的拼音是lv luo,与Lealone英文发音有点相同, Lealone是lea + lone的组合(lea 草地/草原, lone 孤独的),也算是现在的心境:思路辽阔但又孤独。 反过来念更有意思。
应用场景:
使用Lealone的分布式SQL引擎,可使用类似MySQL的SQL语法和标准JDBC API读写HBase中的数据, 支持各种DDL,支持触发器、自定义函数、视图、Join、子查询、Order By、Group By、聚合。
对于Client/Server架构的传统单机RDBMS的场景,也可使用Lealone。
如果应用想不经过网络直接读写数据库,可使用嵌入式Lealone。
Java APNS开源库 apns4j
apns4j 是 Apple Push Notification Service 的 Java 实现!
Maven:
<dependency> <groupId>com.github.teaey</groupId> <artifactId>apns4j</artifactId> <version>1.0.1</version>
</dependency>示例代码:
KeyStoreWraper keyStore = KeyStoreHelper.getKeyStoreWraper("XXXXXXXX.p12", keyStorePasswd);
AppleNotificationServer appleNotificationServer = new AppleNotificationServer(AppleGateway.ENV_DEVELOPMENT, keyStore);
SecurityConnectionFactory connectionFactory = new SecurityConnectionFactory(appleNotificationServer);
SecurityConnection connection = connectionFactory.getSecurityConnection(); NotifyPayload notifyPayload = new NotifyPayload();
//notifyPayload.setAlert("TEST1");
notifyPayload.setBadge(2);
notifyPayload.setSound("default");
notifyPayload.setAlertBody("Pushed By apns4j");
notifyPayload.setAlertActionLocKey("Button Text");
connection.writeAndFlush(deviceTokenString, notifyPayload);
connection.close();消息中间件 RocketMQ
RocketMQ是什么?
RocketMQ 是一款分布式、队列模型的消息中间件,具有以下特点:
能够保证严格的消息顺序
提供丰富的消息拉取模式
高效的订阅者水平扩展能力
实时的消息订阅机制
亿级消息堆积能力
Metaq3.0 版本改名,产品名称改为RocketMQ
分布式数据层 TDDL
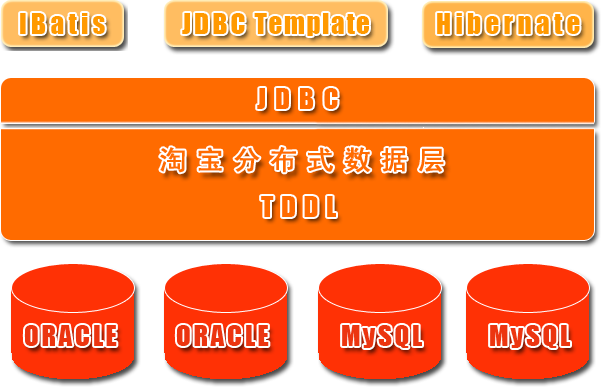
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer 外号:头都大了 ©_Ob)框架,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制,它是一个基于集中式配置的 jdbc datasource实现,具有主备,读写分离,动态数据库配置等功能。
TDDL所处的位置(tddl通用数据访问层,部署在客户端的jar包,用于将用户的SQL路由到指定的数据库中):
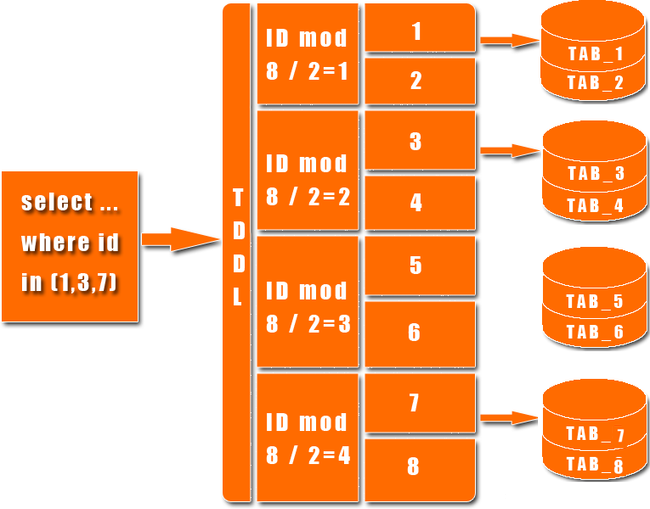
淘宝很早就对数据进行过分库的处理, 上层系统连接多个数据库,中间有一个叫做DBRoute的路由来对数据进行统一访问。DBRoute对数据进行多库的操作、数据的整合,让上层系统像操作 一个数据库一样操作多个库。但是随着数据量的增长,对于库表的分法有了更高的要求,例如,你的商品数据到了百亿级别的时候,任何一个库都无法存放了,于是 分成2个、4个、8个、16个、32个……直到1024个、2048个。好,分成这么多,数据能够存放了,那怎么查询它?这时候,数据查询的中间件就要能 够承担这个重任了,它对上层来说,必须像查询一个数据库一样来查询数据,还要像查询一个数据库一样快(每条查询在几毫秒内完成),TDDL就承担了这样一 个工作。在外面有些系统也用DAL(数据访问层) 这个概念来命名这个中间件。
下图展示了一个简单的分库分表数据查询策略:
主要优点:
1.数据库主备和动态切换
2.带权重的读写分离
3.单线程读重试
4.集中式数据源信息管理和动态变更
5.剥离的稳定jboss数据源
6.支持mysql和oracle数据库
7.基于jdbc规范,很容易扩展支持实现jdbc规范的数据源
8.无server,client-jar形式存在,应用直连数据库
9.读写次数,并发度流程控制,动态变更
10.可分析的日志打印,日志流控,动态变更
TDDL必须要依赖diamond配置中心(diamond是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理,同时diamond也已开源)。
TDDL动态数据源使用示例说明:http://rdc.taobao.com/team/jm/archives/1645
diamond简介和快速使用:http://jm.taobao.org/tag/diamond%E4%B8%93%E9%A2%98/
TDDL源码:https://github.com/alibaba/tb_tddl
TDDL复杂度相对较高。当前公布的文档较少,只开源动态数据源,分表分库部分还未开源,还需要依赖diamond,不推荐使用。
通用WEB框架 Webx
Webx是建立在Java Servlet API基础上的的通用WEB框架。用Webx搭建的应用可以运行在任何一个标准的WEB应用服务器上面:Tomcat、Jetty、Jboss、Weblogic……。
Webx是一个在阿里巴巴集团内部广泛使用的,层次化、模块化的一个Web框架。 Webx是基于经典MVC设计模式的WEB框架,推崇页面驱动和约定胜于配置的理念。 Webx是一个基于Spring的组件框架。组件是一个软件包,它可以被其它组件扩展,也可以扩展其它组件。利用这些特性,Webx不仅能够用来开发高度可定制的Web应用(这是它的主要功能),也能够用来帮助你开发高度可扩展的非WEB的应用。
分布式核心技术框架 Fourinone
FourInOne(中文名字“四不像”)是一个四合一分布式计算框架,在写这个框架之前,我对分布式计算进行了长时间的思考,也看了老外写的其他开源框架,当我们把复杂的hadoop当作一门学科学习时,似乎忘记了我们想解决问题的初衷:我们仅仅是想写个程序把几台甚至更多的机器一起用起来计算,把更多的cpu和内存利用上,来解决我们数量大和计算复杂的问题,当然这个过程中要考虑到分布式的协同和故障处理。如果仅仅是为了实现这个简单的初衷,为什么一切会那么复杂,我觉的自己可以写一个更简单的东西,它不需要过度设计,只需要看上去更酷一点,更小巧一点,功能更强一点。于是我将自己对分布式的理解融入到这个框架中,考虑到底层实现技术的相似性,我将Hadoop,Zookeeper,MQ,分布式缓存四大主要的分布式计算功能合为一个框架内,对复杂的分布式计算应用进行了大量简化和归纳。
首先,对分布式协同方面,它实现了Zookeeper所有的功能,并且做了很多改进,包括简化Zookeeper的树型结构,用domain/node两层结构取代,简化Watch回调多线程等待编程模型,用更直观的容易保证业务逻辑完整性的内容变化事件以及状态轮循取代,Zookeeper只能存储信息不大于1M的内容,FourInOne超过1M的内容会以内存隐射文件存储,增强了它的存储功能,简化了Zookeeper的ACL权限功能,用更为程序员熟悉rw风格取代,简化了Zookeeper的临时节点和序列节点等类型,取代为在创建节点时是否指定保持心跳,心跳断掉时节点会自动删除。FourInOne是高可用的,没有单点问题,可以有任意多个复本,它的复制不是定时而是基于内容变更复制,有更高的性能,FourInOne实现了领导者选举算法(但不是Paxos),在领导者服务器宕机情况下,会自动不延时的将请求切换到备份服务器上,选举出新的领导者进行服务,这个过程中,心跳节点仍然能保持健壮的稳定性,迅速跟新的领导者保持心跳连接。基于FourInOne可以轻松实现分布式配置信息,集群管理,故障节点检测,分布式锁,以及淘宝configserver等等协同功能。
其次, FourInOne可以提供完整的分布式缓存功能。如果对一个中小型的互联网或者企业应用,仅仅利用domain/node进行k/v的存储即可,因为domain/node都是内存操作而且读写锁分离,同时拥有复制备份,完全满足缓存的高性能与可靠性。对于大型互联网应用,高峰访问量上百万的并发读写吞吐量,会超出单台服务器的承受力,FourInOne提供了fa?ade的解决方案去解决大集群的分布式缓存,利用硬件负载均衡路由到一组fa?ade服务器上,fa?ade可以自动为缓存内容生成key,并根据key准确找到散落在背后的缓存集群的具体哪台服务器,当缓存服务器的容量到达限制时,可以自由扩容,不需要成倍扩容,因为fa?ade的算法会登记服务器扩容时间版本,并将key智能的跟这个时间匹配,这样在扩容后还能准确找到之前分配到的服务器。另外,基于FourInOne可以轻松实现web应用的session功能,只需要将生成的key写入客户端cookie即可。
FourInOne对于分布式大数据量并行计算的解决方案不同于复杂的hadoop,它不像hadoop的中间计算结果依赖于hdfs,它使用不同于map/reduce的全新设计模式解决问题。FourInOne有“包工头”,“农民工”,“手工仓库”的几个核心概念。“农民工”为一个计算节点,可以部署在多个机器,它由开发者自由实现,计算时,“农民工”到“手工仓库”获取输入资源,再将计算结果放回“手工仓库”返回给“包工头”。“包工头”负责承包一个复杂项目的一部分,可以理解为一个分配任务和调度程序,它由开发者自己实现,开发者可以自由控制调度过程,比如按照“农民工”的数量将源数据切分成多少份,然后远程分配给“农民工”节点进行计算处理,它处理完的中间结果数据不限制保存在hdfs里,而可以自由控制保存在分布式缓存、数据库、分布式文件里。如果需要结果数据的合并,可以新建立一个“包工头”的任务分配进行完成。多个“包工头”之间进行责任链式处理。总的来说,是将大数据的复杂分布式计算,设计为一个链式的多“包工头”环节去处理,每个环节包括利用多台“农民工”机器进行并行计算,无论是拆分计算任务还是合并结果,都可以设计为一个单独的“包工头”环节。这样做的好处是,开发者有更大能力去深入控制并行计算的过程,去保持使用并行计算实现业务逻辑的完整性,而且对各种不同类型的并行计算场景也能灵活处理,不会因为某些特殊场景被map/reduce的框架限制住思维,并且链式的每个环节也方便进行监控过程。
FourInOne也可以当成简单的mq来使用,将domain视为mq队列,每个node为一个队列消息,监控domain的变化事件来获取队列消息。也可以将domain视为订阅主题,将每个订阅者注册到domain的node上,发布者将消息逐一更新每个node,订阅者监控每个属于自己的node的变化事件获取订阅消息,收到后删除内容等待下一个消息。但是FourInOne不实现JMS的规范,不提供JMS的消息确认和消息过滤等特殊功能,不过开发者可以基于FourInOne自己去扩充这些功能,包括mq集群,利用一个独立的domain/node建立队列或者主题的key隐射,再仿照上面分布式缓存的智能根据key定位服务器的做法实现集群管理。
FourInOne整体代码短小精悍,跟Hadoop, Zookeeper, Memcache, ActiveMq等开源产品代码上没有任何相似性,不需要任何依赖,引用一个jar包就可以嵌入式使用,良好支持window环境,可以在一台机器上模拟分布式环境,更方便开发。
开发包里自带了一系列傻瓜上手demo,包括分布式计算、统一配置管理、集群管理、分布式锁、分布式缓存、MQ等方面, 每个demo均控制在少许行代码内,但是涵盖了fourinone主要的功能,方便大家快速理解并掌握。产品开源工作已经在提交中,届时欢迎更多对分布式并行计算有兴趣的人员加入担任贡献者。
Fourinone 2.0新增功能:
Fourinone2.0提供了一个4合1分布式框架和简单易用的编程api,实现对多台计算机cpu,内存,硬盘的统一利用,从而获取到强大计算能力去解决复杂问题。Fourinone框架提供了一系列并行计算模式(农民工/包工头/职介绍/手工仓库)用于利用多机多核cpu的计算能力;提供完整的分布式缓存和小型缓存用于利用多机内存能力;提供像操作本地文件一样操作远程文件(访问,并行读写,拆分,排它,复制,解析,事务等)用于利用多机硬盘存储能力;由于多计算机物理上独立,Fourinone框架也提供完整的分布式协同和锁以及简化MQ功能,用于实现多机的协作和通讯。
一、提供了对分布式文件的便利操作, 将集群中所有机器的硬盘资源利用起来,通过统一的fttp文件路径访问,如:
windows:fttp://v020138.sqa.cm4/d:/data/a.log
linux:fttp://v020138.sqa.cm4/home/user/a.log
比如以这样的方式读取远程文件:
FttpAdapter fa = FttpAdapter("fttp://v020138.sqa.cm4/home/log/a.log");
fa.getFttpReader().readAll();
提供对集群文件的操作支持,包括:
1、元数据访问,添加删除,按块拆分, 高性能并行读写,排他读写(按文件部分内容锁定),随机读写,集群复制等
2、对集群文件的解析支持(包括按行,按分割符,按最后标识读取)
3、对整形数据的高性能读写支持(ArrayInt比ArrayList存的更多更快)
4、两阶段提交和事务补偿处理
5、自带一个集群文件浏览器,可以查看集群所有硬盘上的文件(不同于hadoop的namenode,没有单点问题和容量限制)
总的来说, 将集群看做一个操作系统,像操作本地文件一样操作远程文件。
但是fourinone并不提供一个分布式存储系统,比如文件数据的导入导出、拆分存储、负载均衡,备份容灾等存储功能,不过开发人员可以利用这些api去设计和实现这些功能,用来满足自己的特定需求。
二、自动化class和jar包部署
class和jar包只需放在工头机器上, 各工人机器会自动获取并执行,兼容操作系统,不需要进行安全密钥复杂配置
三、网络波动状况下的策略处理,设置抢救期,抢救期内网络稳定下来不判定结点死亡
fourinone-3.04.25最新版升级内容:
1、编译和运行环境升级为jdk7.0版本;
2、计算中止和超时中止的支持,比如多台计算机工人同时执行查找,一旦某台计算机工人找到,其余工人全部中止并返回。以及可以由工人控制或者框架控制的计算过程超时中止。
3、一次性启动多工人进程支持,可以通过程序api一次性启动和管理“ParkServer/工头/工人”多个进程,并附带良好的日志输出功能,用于代替写批处理脚本方式,方便部署和运行。
4、工人服务化模式的支持,把工人当作通用服务来使用和封装。
5、增加了相应指南和demo。
Fourinone4.0版新特性:一个高性能的数据库引擎CoolHash(酷哈嘻)
1、CoolHash是一个数据库引擎
CoolHash只做数据库最基础核心的引擎部分,支持大部分数据类型的“插入、获取、更新、删除、批量插入、批量获取、批量更新、批量删除、高效查询(精确查、模糊查、按树节点查、按key查、按value查)、分页,排序、and操作、or操作、事务处理、key指针插入和查询、缓存持久互转”等操作和远程操作。
其他的“监控、管理、安全、备份、命令行操作、运维工具”等外围特性都剥离出去不做,开发者可以根据自己需求扩充这些功能,CoolHash也不做自动扩容,CoolHash认为分布式集群特性也可以在外围通过“分库分表”或者“分布式扩容”等中间件技术去做,目前国内很多企业都具备基于开源软件做外围中间件的能力,这样,CoolHash只维持一个高性能又轻量级的最小存储引擎。
CoolHash高度产品化,易用性强,容易嵌入使用和复制传播(200k大小),采用apache2.0开源协议,使用java实现(jdk1.7),对外提供java接口,同时支持windows和linux(unix-like),由于依赖底层操作系统,windows和linux的实现稍有不同。
2、CoolHash是一个k/v数据库
实现数据库存储结构索引有多种方法,有比较平衡减少深入的b树、b+树系列,结合内存再合并的LSM-tree系列(bigTable),借鉴字典索引技术的Trie树(前缀树、三叉树)等,不过对于key/value结构,感觉最合适的还是Hash,不过java里的Hash算法是实现在内存组件里,无法持久化,只能快速读写,但是无法模糊查询,传统的Hash不是一个“cool”的Hash,需要进行改进。
CoolHash改进后的Hash算法是一个完整的key树结构,我们知道传统Hash的key和key之间没有关系,互相独立,但是在CoolHash里,key可以表示为“user.001.name”的用“.”分开的树层次结构,如“user.001.age”和“user.001.name”都属于“user.001.*”分支,既可独立获取,也可以从父节点查询,还可以“user.*.name”方式只查询所有子节点。
提出key指针的概念:CoolHash的key可以是一个指针,指向其他树的key,这样能将两棵key树连起来,这样的设计能避免大量join操作,如果两棵key树没有直接关系,需要动态join将会非常耗时,但有了key指针可以很好的描述数据之间“1对1、1对多、多对多”的关联关系。key指针也不同于数据库外健,它可以模糊指,比如只模糊指向一个key前缀“user.001”,再补充需要获取的属性形成一个完整key;还能连续指,比如一个key指针指向另一个key指针再指向其他key指针,连续指可以将更多的树联系起来形成一个大的数据森林。CoolHash能很好的控制key指针最终值返回、key指针死循环、读写死锁等问题。
我们知道关系数据库的数据表是一个行列的二维矩阵的数据结构,表和表之间没有层次感,一个表不会是另一个表的父子节点,这就导致需要大量关联,从一个表获取另一个表的数据需要通过join操作,同时由于表和表之间彼此独立,又导致数据量大后join性能不好,多个矩阵需要动态的“求并”“求或”获取主健,再返回所有属性。很多朋友是开发业务系统出身,复杂一点的业务逻辑通常需要关联7-8个数据库表甚至更多,是相当头疼的事情。
这种矩阵行列式结构还有个不好,就是一加全加,一减全减,一行加了一列属性,所有行都要跟着加,假如有个“子女”属性,有的人有1个子女,有的人有2-3个子女,这个属性应该有时是1列,有时是3列,有时没有才好。CoolHash的父节点下的key值可以任意添加和减少,或者再任意向下扩充叶子结点,也可以任意查询,能够非常灵活,比如“子女”属性可以这样表示第一个小孩:“user.001.children.001”。
关系数据库还容易产生数据碎片,需要经常执行“OPTIMIZE TABLE”或者“压缩数据库”等操作回收空间,CoolHash对此做了设计和算法改进,对于大量数据频繁写入和删除能很好重复利用存储空间。
key和value的数据格式:CoolHash的key只能是字符串,默认最大长度为256字节。value能支持非常广泛的数据类型,基本数据类型“String(变长字符)、short(短整形)、int(整型)、long(长整形)、 double(双精度浮点型)、 float(浮点型)、Date(日期型)”,高级数据类型的大部分的java集合都能支持(List、Map、Set等),以及任意可序列化的自定义java类型,底层数据类型也可以支持二进制型。基本数据类型的value可支持按内容查询,高级数据类型和二进制类型不支持按内容查询。所有类型的value默认最大长度为2M,默认配置保证一对key/value长度不会太大,能够容易加载到内存进行处理,但是key和value的最大长度、以及region大小都是可以根据计算机性能进行配置。
CoolHash还支持HashMap缓存和持久化的统一和互相转换,并共用一套API,可以将数据放入CoolHashMap,也可以放入持久化,可以将CoolHashMap对象转成持久化,也可以从持久化数据里直接获取CoolHashMap对象。
3、CoolHash是一个并行数据库(mpp)
前几年有篇文章,国外的数据库大牛猛烈抨击map/reduce,让重复造轮子的人应该去学习一下关系数据库几十年的理论和实践积累,一个借助蛮力而不善于设计索引的数据库系统是愚蠢和低效的。这一方面说明了map/reduce技术已经侵犯到了传统数据库领域的核心利益,另一方面也暴露了分布式存储技术的某些不足。
这里的蛮力就是并行计算,在CoolHash的底层,会维持一个数据工人进程组,根据计算机性能少则几个多则上百个,对于数据库的每种操作,数据工人们像演奏交响乐一样,时而独奏,时而合奏,统一调度,紧密协作的完成任务,CoolHash从一开始就是高度并行化的设计,数据库引擎本质就是在寻求cpu、内存、硬盘的充分利用和均衡利用,“一力胜十巧”,在大量数据的读写和查询中并行计算的效果犹为明显。
同时一个好的数据库引擎应该是蛮力和技巧的结合,Hbase的一个重要启示,就是可以灵活设计它的key达到近似索引的效果,CoolHash将此特性发挥的更深入,树型结构的key本身就是最好的索引,除外CoolHash几乎不需要另外再建立索引,只需要按照业务数据特点设计好你的key。并行计算和索引的结合会得到一个很好的互补,让你的索引结构不需要维持的太精准而节省开销,举个例子:我们从一个城市找一个人,一种方法是我们有精确的索引,知道他在哪个区哪个楼那个房间,另一种是我们只大致知道他在哪栋楼,但是我们有几百个工人可以每间房同时去找,这样也能很快找到。
4、CoolHash是一个nosql数据库
nosql不等于没有sql的功能,关系数据库的sql仍然是非常方便的交互语言,而且有专门的标准,CoolHash通过函数方式实现大部分sql的功能,如果需要扩充sql支持,在外围用正则表达式做一个sql解析,然后调用CoolHash的函数支持即可。
由于CoolHash没有关系数据库的“db、table、row、col”等概念,使用树型key取代了,所以sql create语句功能就不需要了。
“put()函数”对应于“sql insert、update”语句
“remove()函数”对应于“sql delete...where”语句
“put(map)函数”对应于“sql insert/update into...select...”语句
“get()函数”对应于“sql select...where id=?”语句
“get(map)”函数对应于“sql select *...”语句
“find(*,filter)”函数对于于“sql select * where col=%x%”语句
“and()函数”对应于“sql and”语句
“or()函数”对应于“sql or”语句
“sort(comp)函数”对应于“sql desc/group”语句
5、CoolHash实现了事务处理
CoolHash实现了ACID事务属性,对写入、更新、删除的基本操作提供事务处理,在程序里调用begin()、commit()、rollback()等事务方法。
原子性(Atomic):事务内操作要么提交全部生效,要么回滚全部撤消。
一致性(Consistent):事务操作前后的数据状态保持一致,一致性跟原子性密切相关,比如银行转账前后,两个账户累加总和保持一致。
隔离性(Isolated):多个事务操作时,互相不能有影响,保持隔离。
持续性(Durable) :事务提交后需要持久化生效。
另外,对于多个事务并发操作数据的情况,JDBC规范归纳出“脏读(dirty read)、不可重复读(non-repeatable read) 、幻读(phantom read) ”三种问题,并提出了4种事务隔离级让软件制造商去实现,按照不同等级去容忍这三个问题,其实这种逐级容忍大部分都不实用,一个事务操作未提交时,按照事务隔离级,其他访问应该是读取到该事务开始前的数据,而不应该把事情搞复杂,CoolHash实现的是“TRANSACTION_SERIALIZABLE”,禁止容忍三种读取问题。
6、CoolHash是一个数据库Server
CoolHash支持远程网络访问,服务端发布一个IP和监听端口,客户端连接该IP端口即可进行远程操作,CoolHash可承受多用户高并发的网络连接访问,来源于服务端设计的相似之处,大家知道Apache HTTP Server是一个多进程模型+共享内存方式实现,在前面讲到的CoolHash会维持一个数据工人的进程组,数据工人不仅是并行计算的执行者,同时也是网络请求的响应者,数据工人身兼多职能很好的将服务端设计统一起来,避免重复设计,因此CoolHash也是一个很好的网络Server.
7、CoolHash的测试性能
有句话叫做“人生如白驹过隙”,用来形容性能就是一瞬间,数据库性能最好能接近缓存,或者直接可以当作缓存来用,能在瞬间完成读写和各种查询,这个瞬间就是秒。只有在几秒内完成操作才能做到实时交互没有等待感,否则就要离线交互。
CoolHash的单条写入和读取速度都在毫秒级别,写和读差别不大,读略快于写。
CoolHash的批量写入和读取速度都控制在秒级别,100万数据写入基准测试,普通台式机或者笔记本(4核4g)需要5-6秒,标准pc server(24核256g)需要2-3秒;批量读、批量删除和批量写入的速度差不多。
CoolHash写入缓存和写入持久的速度差别不大,100万数据写入缓存基准测试,普通台式机或者笔记本(4核4g)需要5秒左右,标准pc server(24核256g)需要2秒左右。如果是10万级别的数据读写,缓存和持久的速度大致接近等同。
CoolHash的查询速度控制在秒级别,100万数据的模糊查询(如like%str%)在没有构建索引情况下,普通台式机或者笔记本(4核4g)需要2-3秒,标准pc server(24核256g)需要1-2秒;如果是重复查询,由于CoolHash内部做了数据内存映射,第二次以后只需要毫秒级完成。
高并发多客户端的吞吐量总体速度要快于单客户端,但是受服务器cpu、内存、io等性能限制,会倾向于一个平衡值。
数据库引擎的性能通常也会受“key/value数据大小、数据类型、工人数量、硬件配置(内存大小、cpu核数、硬盘io、网络耗用)”等等因素影响。
比如同样数量但是单条key/value数据很大,整体速度要慢一些;
基本数据类型的读写速度要快过高级数据类型(如java集合类);
工人数量也有影响,对于单条写入读取单工人和多工人差不多,但是批量操作和查询多工人要好过单工人,普通台式机或者笔记本(4核4g)维持在8-10个工人可以打满cpu,标准pc server(24核256g)最大可以维持到100个左右工人,但是工人数量就算能打满cpu,也受限于后端硬盘io,到一定程度速度不再增长;
硬件配置对于性能的影响很大,普通笔记本的测试效果明显不如标准pc server,笔记本内存较小,硬盘io弱,不适合做数据库服务器。内存大的服务器测试效果好,加载数据和jvm垃圾回收速度会更快,目前测试采用的都是传统SAS/SATA硬盘,如果采用固态硬盘进行硬件升级,随机IO性能会得到进一步提升;
另外,由于存在网络耗用和序列化传送,远程网络操作的速度要比本地速度慢,但是局域网内速度会接近本地速度,这是因为远程网络操作涉及带宽接入限制和线路共享等复杂消耗,而局域网内主要取决于物理设备速度。
关于CoolHash性能的更多体验,欢迎有兴趣的朋友根据demo在各自的机器环境下,模拟各种极端条件下去压测。
三、如何使用CoolHash
CoolHash追求极简的编程体验,不需要安排配置,服务端启动CoolHashServer,指定好ip和端口,
客户端大致编程步骤如下:
CoolHashClient chc = BeanContext.getCoolHashClient("localhost",2014);//连接CoolHashServer
chc.put("user.001.name","zhang");//写入字符
chc.put("user.001.age",20);//写入整数
chc.put("user.001.weight",50.55f);//写入浮点数
chc.put("user.001.pet",new ArrayList());//写入集合对象
String name = (String)chc.get("user.001.name");//读取字符
int age = (int)chc.get("user.001.age");//读取整数
float weight = (float)chc.get("user.001.weight");//读取浮点数
ArrayList pet = (ArrayList)chc.get("user.001.pet");//读取集合对象
chc.put("user.002.name","Li");
chc.put("user.002.age",25);
chc.put("user.002.weight",60.55f);
CoolKeyResult keyresult = chc.findKey("user.001.*");//查找用户001的所有属性
CoolKeySet ks = keyresult.nextBatchKey(4);//分页获取前4条结果
System.out.println(ks);//输出[user.001.weight, user.001.age, user.001.name, user.001.pet]
CoolHashResult mapresult = chc.find("user.*.age", ValueFilter.greater(18));//查找年龄大于18岁的用户
CoolHashMap hm = mapresult.nextBatch(10);
System.out.println(hm);//输出[user.001.age=20, user.002.age=25]
......
更多的功能使用请去参考开发包里的demo
除外,4.0版本还增加了以下特性:
1、多进程多线程的无缝融合,同一套接口,改改参数,从多进程变为多线程,开发者无需改写程序逻辑;
2、提供高容错任务分配算法API:doTaskCompete(m工人,n任务),将n个任务分给m个工人并行完成,根据任务大小设置工人数量,工人间能者多劳,性能好的工人机器争抢干更多的任务,同时跟现实工作一样,如果有工人生病请假(故障),那么他的任务活由其余工人代干,除非所有工人出故障,否则就算只剩一个工人也应该加班把其他所有工人的活干完,对整体计算来说,部分工人故障对计算结果来说不受影响,只是计算时间会延长。
Coolhash压测性能指标:读写吞吐量超过百万,千万级别查询1秒完成,连续48小时打满CPU强压力运行稳定。redis官方公布读写性能在10万tps,leveldb官方公布写性能在40万tps,读在6万tps,redis和leveldb都是倾向k/v高速读写,但不具备高效检索功能,没有join关联设计。coolhash可以拿去pk世界上任何的数据库引擎产品。
Fourinone-4.15.08 新升级版本内容:
增强了CoolHash以下功能:
1、为了方便在Tomcat等多线程服务器内调用,开通了CoolHash的多线程客户端支持(4.05版由于jvm安全隔离性考虑只支持多进程客户端),提升数据库引擎对单条数据读写的高并发低延迟处理能力,做到1000-5000级别多线程并发读写几毫秒完成(网络访问,单server,8核8g内存普通配置)。详见自带Demo:ThreadClient.java
2、提供了CoolHash所有数据库操作的异步支持,灵活利用异步操作可以实现很多数据库常用功能,如多种备份策略的实现:同步备份、异步备份忽略成功、异步可靠备份,异步可靠备份即能提升性能又能确保成功,分库分表后,利用异步操作可同时查询多个CoolHash引擎数据源,将查询结果进行合并,等等。详见自带Demo:AsynClient.java
3、提供同一个CoolHash客户端同时可操作多个CoolHash Server,比如用于收到用户请求根据数据库业务分表路由,但是需要保持客户端和所有服务端配置文件的一致性。
4、增强了key模糊匹配能力,4.05版可以使用*模糊查询key,比如user.*.age查询所有人的年纪,4.15新增可以给*加上前后缀,如user.a*.age查找a开头的人的年纪,user.*z.age查找z结尾的,user.a*z.age查找a开头z结尾的。key模糊匹配和value的Filter过滤一起使用,可以实现类似sql语句的seclect * from where的查询效果。很多kv持久化数据库在数据容量超出了内存大小后性能会急剧降低,但是CoolHash此时的模糊查询性能仍然表现良好,还是会维持着和内存检索接近的速度,这是因为CoolHash带有的冷热切换特性,会将常访问的数据调整到内存中,这样即能保证性能又能极大节省硬件资源,提升单机存储容量。
4.15.08版本同时提供jdk "1.7.0_79"编译下"fourinone.jar"包和"jdk1.8.0_45"编译下"fourinone-jdk8.jar"包。
由于google code国内访问常常受限,4.15.08版本只更新oschina code和csdn code
异构数据源数据交换工具 DataX
DataX是一个让你方便的在异构数据源之间交换数据的离线同步框架/工具,实现了在任意的数据处理系统之间的数据交换,目前DataX在淘宝内部每天约有5000道同步任务分布在全天各个时段,平均每天同步数据量在2-3TB。
DataX 编译安装说明
http压力测试工具 httpsender
httpsender是一款轻量级的http压力测试工具,由淘宝的测试工程师用Java语言开发完成。它可以指定并发连接数发送指定数目的请求,还可以自定义请求的header头。请求的URL支持通过正则表达式指定范围,同时也支持从文件随机或顺序读取。它还具备验证数据是否完整和错乱等较高级的功能。默认应用环境为Linux。
【作者】邓悟 (dengwu@taobao.com)
【基本功能】
1. 指定并发连接数发送指定数目的请求
httpsender -c 10 -n 10000 http://www.test.com/[0-9]/[0-9].jpg
2. 自定义请求的header 头
httpsender -c 10 -n 10000 http://127.0.0.1/ -h "Host:www.test.com" -h "Connection:close"
3. 从文件中读取要请求的URL, "-r 1"指定随机发送,默认是顺序发送
httpsender -c 1 -n 100 -f /tmp/myfile.log -r 1
4. 发送请求时,设置http版本号是1.0,默认是1.1
httpsender -c 1 -n 1 http://www.test.com -v 1.0
5. 打印每一个请求后的响应header信息,默认不输出
httpsender -c 1 -n 1 http://www.test.com -p
6. -d 指定打印输出的时间间隔为10秒
httpsender -c 10 -n 10000 http://127.0.0.1/[0-100].jpg -h "Host:www.test.com" -r 1 -d 10
7. 验证数据是否损坏或者是否发生错乱
httpsender -c 1 -n 1 -f myfile.log -md5
此功能的目的是验证服务器返回的内容数据是否完整
使用者需要预先将被访问的URL的md5命名为该URL的文件名放到指定的文件中,如:myfile.log
http://www.test.com/4b841ef580c2f8b0085885fcb7ef8072
http://www.test.com/abc41ef5abfc2f8b0085885fcb7ef807
验证时程序会自动根据返回的body内容计算md5值,然后和请求的URL文件名做比对,比对失败会打印输出。
下载地址:
http://dl.dbank.com/c0vxx27aa5
多浏览器兼容性测试整体解决方案 F2etest
F2etest 是一个面向前端、测试、产品等岗位的多浏览器兼容性测试整体解决方案。

在之前,我们一般有三种解决方案:
本机安装大量的虚拟机,一个浏览器一个虚拟机,优点:真实,缺点:消耗硬盘资源,消耗CPU资源,打开慢,无法同时打开多个虚拟机
使用IeTester等模拟软件,优点:体积小,资源消耗小,缺点:不真实,很多特性不能代表真实浏览器
公用机器提供多种浏览器,优点:不需要本地安装,不消耗本机资源,缺点:资源利用率低,整体资源消耗非常恐怖
现在,有了F2etest,一台普通的4核CPU的服务器,我们就可以提供给20人以上同时使用。
在这之前我们需要20台机器,相比之下,至少10倍的硬件利用率提升。
相比之前的方案,我们有以下优势:
10倍硬件利用率,降低企业运营成本
非常棒的用户体验,极大的提高测试效率
真实浏览器环境,还原真实测试场景
在这个解决方案中,我们使用了以下技术:
Guacamole: 开源的HTML5远程解决方案
Windows Server: Server版Windows,最大化复用机器资源
hostsShare: 跨浏览器,跨服务器的hosts共享
产品截图

安全风险警示(非常重要)
由于本系统基于Windows Server体系搭建,因此系统的安全性完全取决于部署人的安全部署能力。
如果您希望部署本系统,请确保以下几点:
严禁将本系统部署在公网环境,仅可部署在内网环境中使用,作为内部测试用途
请将Windows Server服务端升级到最新版本及补丁,以保证没有出现安全漏洞
请将User用户之间做到完全隔离,仅提供User用户文件的访问权限,别的任何权限请勿多余授权
请将f2etest-client仅设置为管理员拥有权限,防止API接口被恶意访问
轻量级分布式数据访问层 CobarClient
Cobar Client是一个轻量级分布式数据访问层(DAL)基于iBatis(已更名为MyBatis)和Spring框架实现。
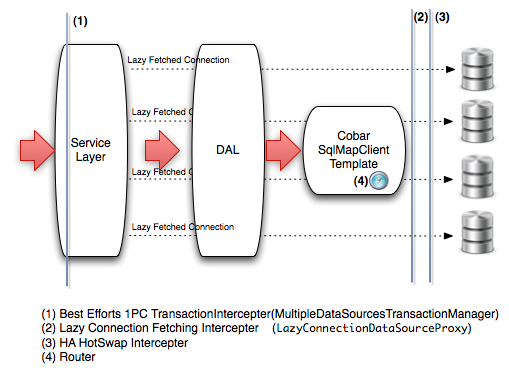
主要特性:
可以支持垂直和水平数据切分数据库集群的访问;
支持双机热备的HA解决方案, 应用方可以根据情况选用数据库特定的HA解决方案(比如Oracle的RAC),或者选用CobarClient提供的HA解决方案.
小数据量的数据集计(Aggregation), 暂时只支持简单的数据合并.
数据库本地事务的支持, 目前采用Best Efforts 1PC模式的事务管理.
数据访问操作相关SQL的记录, 分析等.(可以采用国际站现有Ark解决方案,但CobarClient提供扩展的切入接口)
binlog的增量订阅&消费组件 canal
canal 是阿里巴巴mysql数据库binlog的增量订阅&消费组件。
名称:canal [kə'næl]
译意: 水道/管道/沟渠
语言: 纯java开发
定位: 基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql
早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量 变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开 启了一段新纪元。ps. 目前内部使用的同步,已经支持mysql5.x和oracle部分版本的日志解析
基于日志增量订阅&消费支持的业务:
数据库镜像
数据库实时备份
多级索引 (卖家和买家各自分库索引)
search build
业务cache刷新
价格变化等重要业务消息
Canal 工作原理:

原理相对比较简单:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议
mysql master收到dump请求,开始推送binary log给slave(也就是canal)
canal解析binary log对象(原始为byte流)
反向代理测试套件 Macaroon
Macaroon 是一个高效的反向代理测试套件,测试框架本身基于python2.7开发,方便跨平台移植;测试例使用格式化描述,做到编程语言无关性。使用 Macaroon能够简便快捷的完成测试场景的构造、线上失效案例的重建及被测软件(DUT)的功能、模块、协议一致性测试等。
安装及使用
社区公共测试平台地址:
目前公共测试环境已经搭建配置完成,测试用户名:Tester; 登录qa1机器:ssh -l Tester -p 22292 qa1.zymlinux.net, /home/Macaroon安装有Macaroon; 登录qa2机器:ssh -l Tester -p 22293 qa2.zymlinux.net,安装有ts、squid等方向代理软件; 如有需要,请联系宗仪(QQ:624740707)或怀财(QQ:262765996)添加长期用户权限;
自行安装及使用:
i. 硬件准备:
两台机器A和B,A机器执行测试并同时作为client端与server端,B机器安装被测软件DUT--例如TrafficServer(Proxy).
ii.软件准备:
执行install.sh文件 Client&Server:LinuxPython2.7PyYaml包MacaroongitDUT( Device Under Testing) :被测软件(proxy or cache, 如TrafficServer, Swift等)Bind
iii. 配置DUT:
使从A机器client端发出的http请求能够通过DUT(proxy)后正确到达A机器server端 ----- *重要 例如: 在proxy上安装bind, 修改named的相关配置信息,使得named中存在一个域名可以指向A机器(Client的IP),使用dig <域名>确认是否成功.
iv. 修改config文件:
在macaroon目录下, 找到config.py文件,将_server的内容修改为proxy的ip或者hostname. _port修改为proxy提供的对外服务的端口, 例如:默认为80. 将DUT_Strart, DUT_Stop和DUT_Clean分别修改为proxy对应的启动, 停止和清理缓存命令.
v. 将macaroon目录下的agentsever.py 拷贝至proxy机器,并使用sudo权限执行:
sudo python agentserver.py
vi. 环境验证:
在client端执行httpmockserver.py:python httpmockserver.py 在proxy端执行curl命令,验证proxy到client的request是否可达: curl http://<proxyip>:<port>/ -H "Host:XXX:[port]"
更多问题参见:doc/Q&A
框架及case设计
参见doc/Case_Design
如何运行用例
i. 运行单个case
在根目录下执行如下命令: sh runcase.sh case文件
ii. 运行多个case
在根目录下执行如下命令:python runner.py -p your-case-path -s your-email 详见:python runner.py -h
查看case输出及日志
i. 执行和调试单个测试例
sh runcase.sh <case文件>, case执行日志屏幕输出
ii. 执行多个case
执行日志输出至日志文件,./log/record_XXXX.log,按时间排序
如何编写你的用例
i. case/下创建your case dir
ii. 拷贝case模板example/case_template_example.yaml至your case dir,并重命名
iii.编辑该文件
a. 文件头部添加case相关说明 b. 填写case步骤并准备对应步骤的数据块 c. 填充和完善每步的数据,如request header, response header, response body, 需要检查的header等 d. 保存和调试用例
更多信息
参见./doc/文档
基于 Node.js 的自动化持续集成 Reliable
Reliable 是分布式架构的持续集成系统,由 Macaca 团队的成员开发。适用于集成构建、集成构建等场景。她是典型的主从结构,分为 reliable-master 与 reliable-slave 两部分。
特点:
集群负载,合理调配
提供插件机制,易扩展
部署非常简单
便于接入 Gitlab、Github 等社区化系统
同时,她与 Macaca 无缝融合。
使用 Macaca + Reliable 为自己的团队和公司搭建一个开源的自动化集成平台是个不错的选择。

Master 一键部署
为了更加便捷的安装体验,reliable-master 是使用 Docker 部署。将源码 clone 到服务器或本机,make deploy env=prod即可,就这么简单。
更详细的配置请见: github/reliable-master/deploy
配置和功能
邮箱
支持简单邮件传输协议,通过配置smtp实现通知创建者,订阅者的的邮件推送功能。
多语言
支持多语言,默认为英文,可以通过配置文件将站点设为中文。
添加用户
通过如下命令为站点添加初始化用户或管理员。
|
1
|
$ make adduser
|

接下来可以用过 8080 端口访问的站点
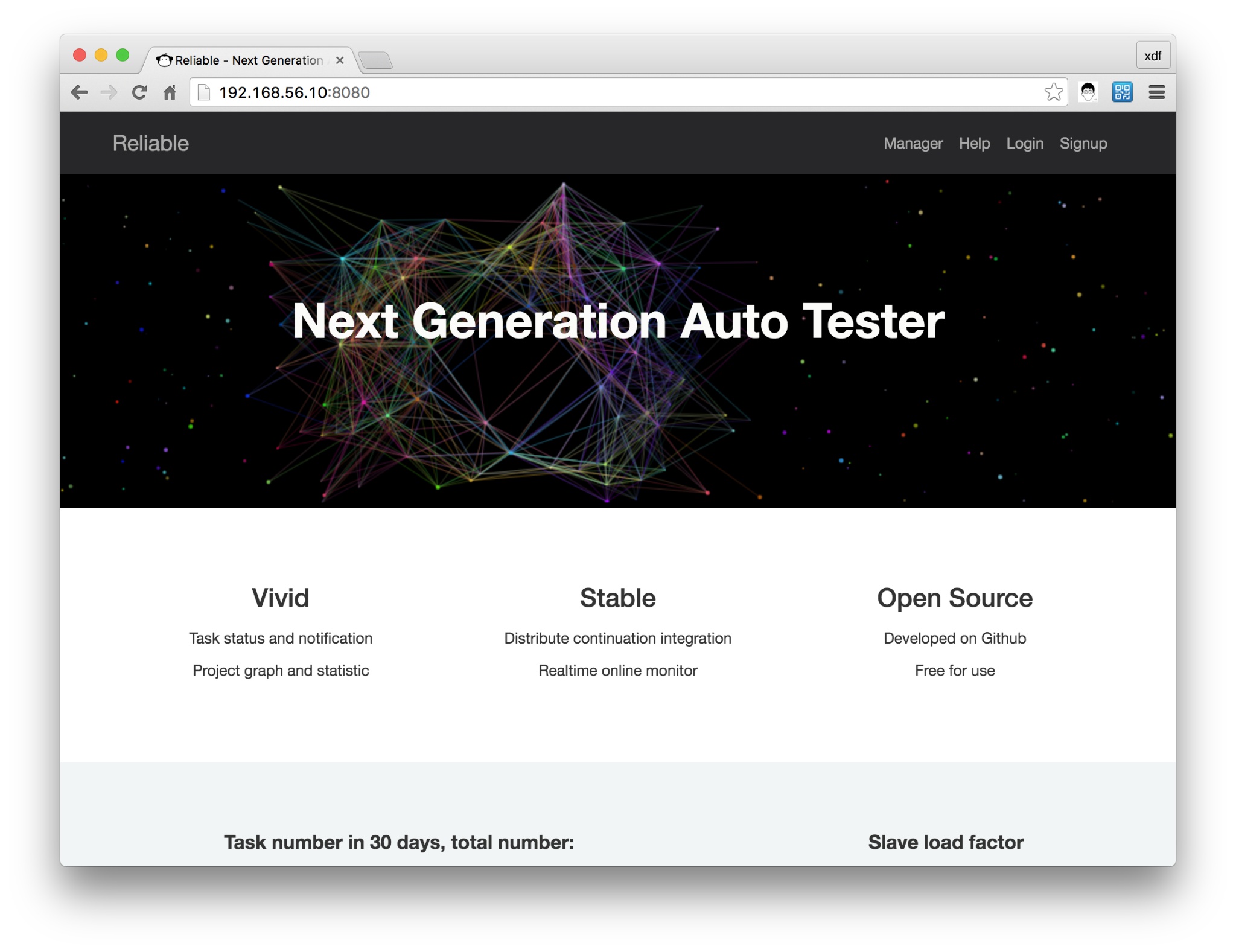
登录已经创建的用户
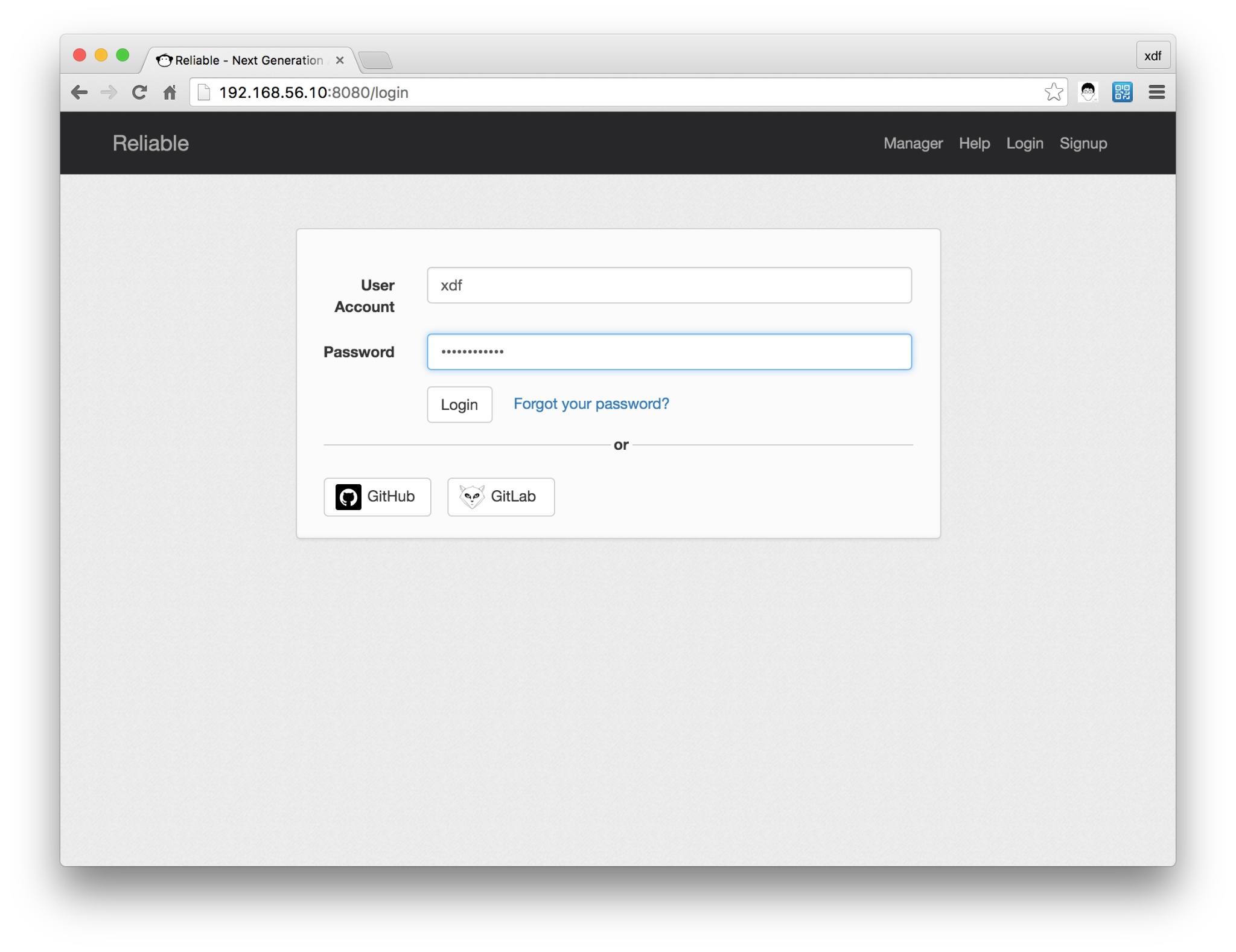
大功告成

Slave 部署
我们使用 zeromq 做消息队列,所以需要先安装 zeromq。
|
1
2
3
4
|
$ brew install pkg-config
$ brew install zeromq #
Then
$ npm install reliable-slave -g
|
指定已经部署的 Master IP 或 域名即完成部署并挂载:
|
1
|
reliable server -m <reliable-master:port> --verbose
|
文档详见
多种模式

单点模式
reliable-slave, reliable-master 部署在同一台机器
此模式节省设备,是最省的用法
集群模式
reliable-slave 推荐部署在 Windows 系统或 OSX 系统[推荐 MacMini],reliable-master 部署在专业服务器
众包模式
用户通过使用 reliable-slave 志愿挂载已经部署好的 reliable-master,提供资源
淘宝 React 框架 React Web
淘宝前端团队开源项目React Web,通过与React Native一致的API构建Web应用。
配置:
// webpack.config.js
var HasteResolverPlugin = require('haste-resolver-webpack-plugin');module.exports = {resolve: {alias: {'react-native': 'react-web'}},plugins: [new HasteResolverPlugin({platform: 'web',nodeModules: ['react-web']})]
}跨平台移动开发工具 Weex
2016年4月21日,阿里巴巴在Qcon大会上宣布开源跨平台移动开发工具Weex,Weex能够完美兼顾性能与动态性,让移动开发者通过简捷的前端语法写出Native级别的性能体验,并支持iOS、安卓、YunOS及Web等多端部署。
对于移动开发者来说,Weex主要解决了频繁发版和多端研发两大痛点,同时解决了前端语言性能差和显示效果受限的问题。开发者可通过Weex官网申请内测。(http://alibaba.github.io/weex/)
开发者只需要在自己的APP中嵌入Weex的SDK,就可以通过撰写HTML/CSS/JavaScript来开发Native级别的Weex界面。Weex界面的生成码其实就是一段很小的JS,可以像发布网页一样轻松部署在服务端,然后在APP中请求执行。
与 现有的开源跨平台移动开放项目如Facebook的React Native和微软的Cordova相比,Weex更加轻量,体积小巧。因为基于web conponent标准,使得开发更加简洁标准,方便上手。Native组件和API都可以横向扩展,方便根据业务灵活定制。Weex渲染层具备优异的性 能表现,能够跨平台实现一致的布局效果和实现。对于前端开发来说,Weex能够实现组件化开发、自动化数据绑定,并拥抱Web标准。
突出特点:
致力于移动端,充分调度 native 的能力
充分解决或回避性能瓶颈
灵活扩展,多端统一,优雅“降级”到 HTML5
保持较低的开发成本和学习成本
快速迭代,轻量实时发布
融入现有的 native 技术体系
工程化管理和监控等
轻量:体积小巧,语法简单,方便接入和上手
可扩展:业务方可去中心化横向定制组件和功能模块
高性能:高速加载、高速渲染、体验流畅
淘宝Web服务器 Tengine

Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性。Tengine的性能和稳定性已经在大型的网站如淘宝网,天猫商城等得到了很好的检验。它的最终目标是打造一个高效、稳定、安全、易用的Web平台。
从2011年12月开始,Tengine成为一个开源项目,Tengine团队在积极地开发和维护着它。Tengine团队的核心成员来自于淘宝、搜狗等互联网企业。Tengine是社区合作的成果,我们欢迎大家参与其中,贡献自己的力量。
以下沿引项目主页上的特性介绍:
继承Nginx-1.2.8的所有特性,100%兼容Nginx的配置;
动态模块加载(DSO)支持。加入一个模块不再需要重新编译整个Tengine;
更多负载均衡算法支持。如会话保持,一致性hash等;
输入过滤器机制支持。通过使用这种机制Web应用防火墙的编写更为方便;
动态脚本语言Lua支持。扩展功能非常高效简单;
支持管道(pipe)和syslog(本地和远端)形式的日志以及日志抽样;
组合多个CSS、JavaScript文件的访问请求变成一个请求;
可以对后端的服务器进行主动健康检查,根据服务器状态自动上线下线;
自动根据CPU数目设置进程个数和绑定CPU亲缘性;
监控系统的负载和资源占用从而对系统进行保护;
显示对运维人员更友好的出错信息,便于定位出错机器;
更强大的防攻击(访问速度限制)模块;
更方便的命令行参数,如列出编译的模块列表、支持的指令等;
可以根据访问文件类型设置过期时间;
Web常用UI库 kissy
kissy 是淘宝一个开源的 JavaScript 库,包含的组件有:日历、图片放大镜、卡片切换、弹出窗口、输入建议等
愿景:小巧灵活,简洁实用,使用起来让人感觉愉悦。
支持的浏览器:IE 6+, Firefox 3.5+, Safari 4+, Chrome 2+, Opera 10+
分布式文件系统 TFS
TFS(Taobao FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,其设计目标是支持海量的非结构化数据。
目前,国内自主研发的文件系统可谓凤毛麟角。淘宝在这一领域做了有效的探索和实践,Taobao File System(TFS)作为淘宝内部使用的分布式文件系统,针对海量小文件的随机读写访问性能做了特殊优化,承载着淘宝主站所有图片、商品描述等数据存储。
文章首先概括了TFS的特点:最近,淘宝核心系统团队工程师楚材(李震)在其官方博客上撰文(《TFS简介》,以下简称文章)简要介绍了TFS系统的基本情况,引起了社区的关注。
完全扁平化的数据组织结构,抛弃了传统文件系统的目录结构。
在块设备基础上建立自有的文件系统,减少EXT3等文件系统数据碎片带来的性能损耗。
单进程管理单块磁盘的方式,摒除RAID5机制。
带有HA机制的中央控制节点,在安全稳定和性能复杂度之间取得平衡。
尽量缩减元数据大小,将元数据全部加载入内存,提升访问速度。
跨机架和IDC的负载均衡和冗余安全策略。
完全平滑扩容。
当前,TFS在淘宝的应用规模达到“数百台PCServer,PB级数据量,百亿数据级别”,对于其性能参数,楚材透漏:
TFS在淘宝的部署环境中前端有两层缓冲,到达TFS系统的请求非常离散,所以TFS内部是没有任何数据的内存缓冲的,包括传统文件系统的内存缓冲也不存在......基本上我们可以达到单块磁盘随机IOPS(即I/O per second)理论最大值的60%左右,整机的输出随盘数增加而线性增加。
TFS的逻辑架构图1如下所示:
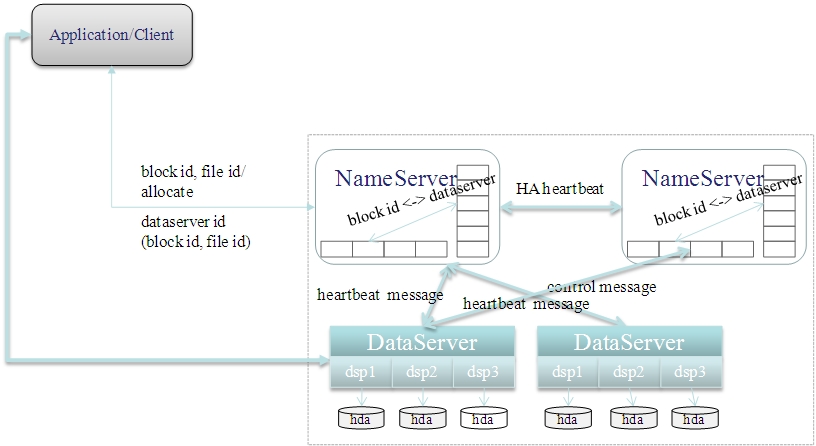
图1.TFS逻辑架构图(来源:淘宝核心系统团队博客)
楚材结合架构图做了进一步说明:
TFS尚未对最终用户提供传统文件系统API,需要通过TFSClient进行接口访问,现有JAVA、JNI、C、PHP的客户端
TFS的NameServer作为中心控制节点,监控所有数据节点的运行状况,负责读写调度的负载均衡,同时管理一级元数据用来帮助客户端定位需要访问的数据节点
TFS的DataServer作为数据节点,负责数据实际发生的负载均衡和数据冗余,同时管理二级元数据帮助客户端获取真实的业务数据。
分布式计算系统 JStorm
Storm 是一个类似Hadoop MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,Jstorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个worker 发生意外故障, 调度器立即分配一个新的worker替换这个失效的worker。因此,从应用的角度,JStorm 应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm一套类似MapReduce的调度系统。 从数据的角度, 是一套基于流水线的消息处理机制。实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的Hadoop Map Reduce,逐渐满足不了需求,因此在这个领域需求不断。
特点:
在Storm和JStorm出现以前,市面上出现很多实时计算引擎,但自storm和JStorm出现后,基本上可以说一统江湖,其优点:
开发非常迅速: 接口简单,容易上手,只要遵守Topology,Spout, Bolt的编程规范即可开发出一个扩展性极好的应用,底层rpc,worker之间冗余,数据分流之类的动作完全不用考虑。
扩展性极好:当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
健壮:当worker失效或机器出现故障时, 自动分配新的worker替换失效worker
数据准确性: 可以采用Acker机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
应用场景:
JStorm处理数据的方式是基于消息的流水线处理, 因此特别适合无状态计算,也就是计算单元的依赖的数据全部在接受的消息中可以找到, 并且最好一个数据流不依赖另外一个数据流。
日志分析:从日志中分析出特定的数据,并将分析的结果存入外部存储器如数据库。目前,主流日志分析技术就使用JStorm或Storm
管道系统: 将一个数据从一个系统传输到另外一个系统, 比如将数据库同步到Hadoop
消息转化器: 将接受到的消息按照某种格式进行转化,存储到另外一个系统如消息中间件
统计分析器: 从日志或消息中,提炼出某个字段,然后做count或sum计算,最后将统计值存入外部存储器。中间处理过程可能更复杂。
关系型数据的分布式处理系统 Cobar
Cobar是关系型数据的分布式处理系统,它可以在分布式的环境下像传统数据库一样为您提供海量数据服务。以下是快速启动场景:
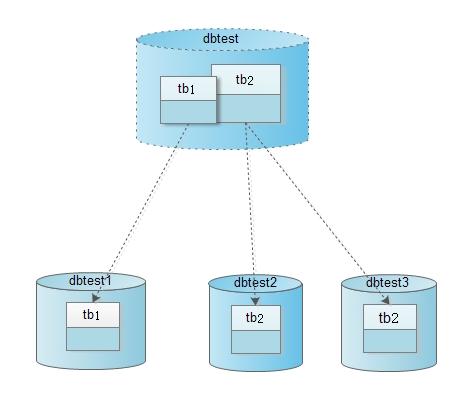
系统对外提供的数据库名是dbtest,并且其中有两张表tb1和tb2。
tb1表的数据被映射到物理数据库dbtest1的tb1上。
tb2表的一部分数据被映射到物理数据库dbtest2的tb2上,另外一部分数据被映射到物理数据库dbtest3的tb2上。
如下图所示:
产品约束
使用JDBC时,推荐使用5.1以上版本Driver进行连接
不支持跨库的关联操作:join、分页、排序、子查询。
不支持rewriteBatchedStatements=true参数设置。默认为false
不支持useServerPrepStmts=true参数设置。默认为false
BLOB, BINARY, VARBINARY字段不能使用。若特殊需求需要这三种字段,禁止使用PreparedStatement的setBlob()或setBinaryStream()方法设置参数。
不支持SAVEPOINT操作。
不支持SET语句的执行,事务和字符集设置语句除外
对于拆分表(一个表的数据被映射到多个MySQL数据库),不能更新已有记录的拆分字段(分库字段)值
只支持MySQL数据节点。
对于拆分表,插入操作须给出列名,必须包含拆分字段。
自动化云测试平台 AutoMan
AutoMan的前身是tCommon和TAM(taobao-automan),经过对两者不断的优化和扩展,逐步形成现在一套完整的页面自动化平台, 意在提高测试人员的测试效率,测试质量,象踏上“风火轮”那样腾挪驰骋于整个测试过程。
一. AutoMan 解决的问题
AutoMan对于自动化活动的一体化管理
解决了以用例为中心的思想,测试脚本作为一种测试执行的手段
执行报表不仅是测试脚步执行的一个自然产物,更是说明了执行哪些测试用例,每个测试用例的状态如何
执行报表可以结合手工执行和自动执行,统一为一个执行报表,说明测试执行的覆盖率
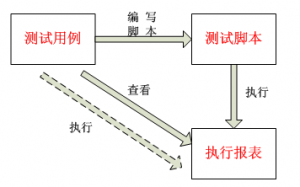
测试用例,测试脚本,执行报表在一个统一的在线平台进行维护,查看,不像以前的自动化过程中,每一个节点存在于不同的文件中,且只线性流转,如下图:
![]()
2. 自动化测试资源的模块化思想
AutoMan 高度抽象了自动化测试各个依赖资源,形成了基础词汇,专业词汇,Page Model, DB Model,测试云等概念。
使测试脚本编写只是根据测试用例,进行各个资源的组合,而不需要很强的编码能力;
使各个模块形成很强的共享能力,很好的引用了DRY (Don’t Repeat Yourself) 的思想;
由于脚本是对各个资源的简单组合,使脚本编写开始的时间不必局限于程序的开发完成,只要依赖资源可以准备了,脚本编写也就开始了,各个资源完善的过程,也就是可执行脚本完善的过程。
3. 解决了两个测试过程: 回归测试 和 项目自动化测试
AutoMan定制了淘宝回归流程的操作方法
通过各资源的模块化,提前测试脚本,测试数据的开发时间
采用分布式执行的方法的,加快了批量脚本执行的时间
形成统一的回归和项目自动化报表
二.AutoMan 现有的主要模块介绍
1.AutoMan Framework
是AutoMan自动化脚本框架的核心,提供操作浏览器,浏览器控件,数据库,windows操作等基础词汇,使用户方便的使用各个操作源。AutoMan Framework以ruby gem包的形势发布,升级。
2. Page Model
抽象了脚本依赖的页面对象,以一个页面为建模单元,对淘宝所有的页面进行建模,使成为快速编写规范脚本的强大动力。 这样脚本开发时间大大提前,并使脚本开发的成员不仅仅局限于测试人员,可以把开发,UED资源也作为脚本开发的重要成员。
3.DB Model
对测试所依赖的各个数据库和表进行建模,对数据库的操作不需要再进行麻烦的连接,取值,提交等操作,采用DB Model提供的接口使你一句话解决上面的问题,不仅解决了自动化数据操作的问题,也方便了手工测试时的数据操作问题。
对自动化脚本的初始化数据,提供一个web化管理页面,使你数据准备工作变得更为轻松,时尚
4. 云测试执行平台
采用分布式执行的方式,测试执行的效率可以根据云端测试机器的数量线性扩展
可以根据各种回归需求,定制执行流程
5. 测试报表
定制测试执行报表
产品线脚本质量报表
Bug曲线
……
最终产出对效率和质量的直观统计
三.AutoMan 的发展
AutoMan 不仅只为大家展现了一个自动化框架,从她一开始就在为提供一个测试解决方案而努力,他的发展大致有如下三步:

具体的内容如下:

对于2010年我们会致力于自动化解决方案中各模块的不断深入,比如对于自动化脚本框架,会考虑些兼容性问题,分布式执行性能的不断优化,测试用例与测试脚本的同步,易用性的提升等。
2011年我们将更多地去考虑我们整个测试的解决方案,AutoMan将不仅局限于自动化测试平台,也是测试日常工作的核心平台。
淘宝定制JVM TaobaoJVM
淘宝有几万台Java应用服务器,上千名Java工程师、及上百个Java应用。为此,核心系统研发部专用计算组的工作之一是专注于OpenJDK的优化及定制,根据业务、应用特点及开发者需要,提供稳定,高效和深度定制的JVM版本:Taobao JVM。
TaobaoJVM 基于 OpenJDK HotSpot VM,是国内第一个优化、定制且开源的服务器版Java虚拟机。目前已经在淘宝、天猫上线,全部替换了Oracle官方JVM版本,在性能,功能上都初步体现了它的价值。
开放是淘宝的重要基因之一,在服务于淘宝的同时,我们非常愿意将我们的工作成果分享给所有Java技术的应用方,希望共同交流,学习,进步,持续为JVM发展和社区的繁荣做出贡献。
专用计算组职责:
针对特定领域问题,以计算性能、效能为导向的优化。
异构计算推广及实践。
JVM优化、定制及相关工具开发。JVM相关故障,问题排查及解决。
协助优化特定应用。
Java 图片处理类库 SimpleImage
SimpleImage是阿里巴巴的一个Java图片处理的类库,可以实现图片缩略、水印等处理。
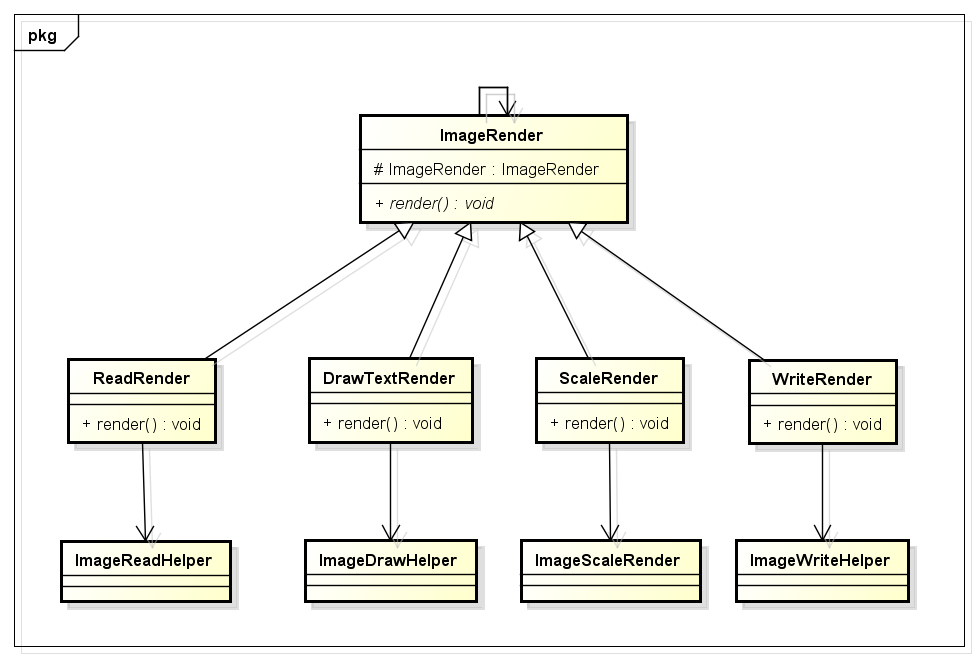
SimpleImage中的ImageRender是图片处理的基类,它是一个抽象类,我们看到,该类中定义了一个抽象方法render(),同时持有一个对ImageRender类的引用。
ReadRedner可以理解成一个组件,不是一个装饰者,因为ReadRender是所有渲染操作的第一步。
其他的子类DrawTextRender(水印处理),ScaleRender(缩略处理),WriterRender(输出)都是装饰者。
拿ScaleRender为例子,看一下它的render()类的实现。红色区域的内容,是上一层包装的实现调方法render()的调用,之后的操作是ScaleRender需要关注的图片缩略处理。
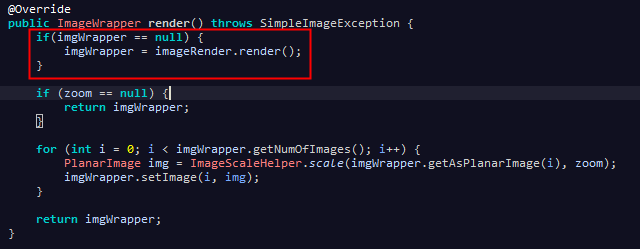
客户端的调用如下所示。ReadRender需要引入一个输入流,ScaleRender包裹ReadRender,WriteRender包裹ScaleRender,最后调用最外层的render()方法,处理图像处理,层层进入,
首先ReadRender读取图片数据,ScaleRender进行图片缩略,WriteReneder将处理之后的图片数据写入输出流中,完成一系列操作。

自动化测试任务调度平台 TOAST
TOAST(Toast Open Automation System for Test) 是一淘广告技术测试团队开发的一套自动化测试任务调度平台。
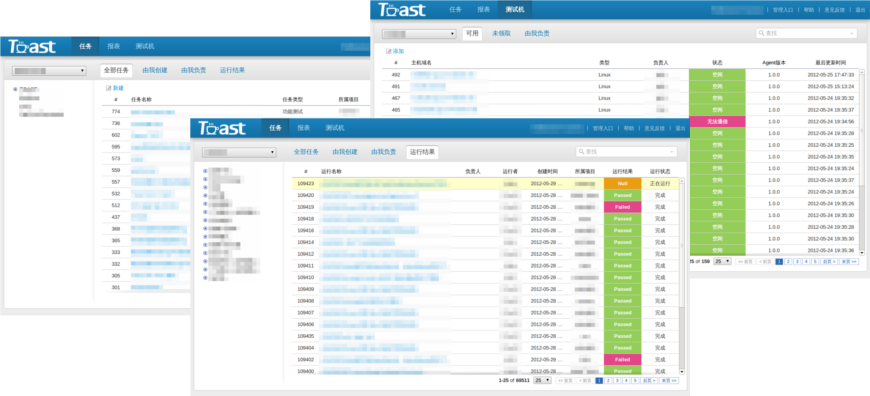
软件版本:v1.0 beta
支持系统:32/64位 Linux
Agent支持系统:32/64位 Win/Linux
自动化任务调度
TOAST提供一套通用的自动化任务调度平台,支持任务的串/并行运行,并且能够收集、分析和统计运行结果。
自动化测试用例管理
TOAST提供了简单的测试用例管理,通过自动化任务运行结果映射,实现测试用例和用例运行结果的关联。同时也可以通过API实现用例和结果的录入。
测试环境管理
TOAST提供了简单的机器监控和管理功能,通过TOAST Agent能够监控机器的CPU、内存、I/O、网络及应用的实时状态,兼容Window和Linux操作系统。
异步文件上传组件 KF/Uploader
目前淘宝网的不少系统正在使用KF/Uploader,V1.2.2后已经稳定。有兴趣使用的朋友请认真看使用指南。
Uploader的特性
支持ajax、flash、iframe三方案,兼容所有浏览器。
配置简单,支持伪属性配置(data-config=’{}’)和配置属性来配置
ajax和flash上传方式,带有上传进度显示
队列上传,批量上传等待中的文件
支持中途取消上传
支持上传验证,整合kissy的validation组件
不错的扩展性,自由定制按钮和队列模板样式


java表达式计算 QLExpress
QLExpress 是一个轻量级的类java语法规则引擎,作为一个嵌入式规则引擎在业务系统中使用。让业务规则定义简便而不失灵活。让业务人员就可以定义业务规则。支持标准的JAVA语法,还可以支持自定义操作符号、操作符号重载、 函数定义、宏定义、数据延迟加载等。
这个表达式相对别的计算工具,优点主要体现在:
A、不需要预先加载可能需要的所有属性值
B、 用户可以根据业务需要自定义操作符号和函数
C、可以同步输出判断错误信息,有利于提高业务系统在规则判断等使用场景下的用户体验。减少业务系统相关的处理代码。
主要用途:一些业务规则的组合判断,同时需要输出相关的错误信息
执行的流程:
1、单词分解
2、语法分析
代码评审工具 Tao-ReviewBoard
ReviewBoard是一款开源的代码review工具,包括服务器端程序(reveiwboard)和客户端命令行(RBTools)。用户可以通过RBTools的一些列命令在客户端提交request,但是使用和安装都有很多不便。Tao-ReviewBoard是淘宝开发的基于eclipse的reviewboard插件,能很好的解决安装和使用的问题。这个插件已经在淘宝使用近一年,现在工具开源了共享给大家。
基于Svg的图表组件库 KCharts
KCharts是基于Svg的图表组件库,兼容IE6+等主流浏览器。基于淘宝js框架KISSY的图表组件库,包含折线图、曲线图、柱状图、散点图、饼图、地图等常用图表。采用kissy的模块加载器,实现按需加载,支持cdn动态合并。KCharts 基于RaphelJs开发,大量的html+css实现了基础grid,流畅的动画,丰富的demo,还有实用的图表在线生成器(Chart Generator),方便初学者实用。

富逻辑的模板引擎 xtemplate.js
xtemplate 是独立的富逻辑模板引擎,基于浏览器和 Node.js 的可扩展的模板引擎库。
xtemplate 支持异步控制和继承,包括逻辑表达式,自定义函数等等。
xtemplate 语法类似 mustache
示例:
<!-- index.xtpl -->{{extend ("./layout1")}}{{#block ("head")}}
<!--index head block-->
<link type="text/css" href="test.css" rev="stylesheet" rel="stylesheet" />
{{/block}}{{#block ("body")}}
<!--index body block-->
<h2>{{title}}</h2>
{{/block}}<!-- layout1.xtpl --><!doctype html>
<html>
<head>
<meta name="charset" content="utf-8" />
<title>{{title}}</title>
{{{block ("head")}}}
</head>
<body>
{{{include ("./header")}}}
{{{block ("body")}}}
{{{include ("./footer")}}}
</body>
</html>具体用法参考: https://github.com/yiminghe/xtemplate-on-browser
实时数据传输平台 TimeTunnel
什么是TimeTunnel
!TimeTunnel(简称TT)是一个基于 thrift 通讯框架搭建的实时数据传输平台,具有高性能、实时性、顺序性、高可靠性、高可用性、可扩展性等特点。
高性能
2k大小的消息,峰值每秒4w TPS的访问。淘宝3台服务器,每天处理2.3T(压缩后)数据,峰值每秒50MByte流入流量、130MByte流出流量
实时性
90%的消息5ms以内送达
顺序性
如果你开启了顺序传输功能,timetunnel保证消息的发布顺序和订阅顺序是一致的
高可靠性
存储方面,我们设计了内存->磁盘->hadoop dfs三级缓存机制,确保数据可靠。 系统方面,我们将服务器节点组织成环,在环里面每一个节点的后续节点是当前节点的备份节点,当某节点故障时,后续节点自动接管故障节点数据,以保证数据可靠性
高可用性
单个节点故障,不影响系统正常运行
可扩展性
可以对系统进行横向和纵向扩展,横向扩展可以向现有的服务环里面增加节点,纵向扩展可以增加服务环
谁使用TimeTunnel
目前TimeTunnel在淘宝广泛的应用于日志收集、数据监控、广告反馈、量子统计、数据库同步等领域。
redis的java客户端 Tedis
Tedis是另一个redis的java客户端,Tedis的目标是打造一个可在生产环境直接使用的高可用Redis解决方案。
特性:
高可用,Tedis使用多写随机读做HA确保redis的高可用
高性能,使用特殊的线程模型,使redis的性能不限制在客户端
多种使用方式,如果你只有一个redis实例,并不需要tedis的HA功能,可以直接使用tedis-atomic;使用tedis的高可用功能需要部署多个redis实例使用tedis-group
两种API,包括针对byte的底层api和面向object的高层api
多种方便使用redis的工具集合,包括mysql数据同步到redis工具,利用redis做搜索工具等
示例代码:
Group tedisGroup = new TedisGroup(appName, version);
tedisGroup.init();
ValueCommands valueCommands = new DefaultValueCommands(tedisGroup.getTedis());
// 写入一条数据
valueCommands.set(1, "test", "test value object");
// 读取一条数据
valueCommands.get(1, "test");Nginx的TFS模块 nginx-tfs
nginx-tfs 是 Nginx 的扩展模块用于访问淘宝的 TFS 文件系统。这个模块实现了TFS的客户端,为TFS提供了RESTful API。TFS的全称是Taobao File System,是淘宝开源的一个分布式文件系统。
编译和安装:
TFS模块使用了一个开源的JSON库来支持JSON,请先安装yajl-2.0.1。
下载nginx或tengine。
./configure --add-module=/path/to/nginx-tfs
make && make install
分布式关系数据库 Alibaba Wasp
Wasp 是类Google MegaStore & F1的分布式关系数据库。
最近几年随之Bigtable和NoSQL的兴起,社区产品HBase逐步走向NoSQL系统的主流产品,优势明显然而缺点也明显,大数据平台下的业务由 SQL向NoSQL的迁移比较复杂而应用人员学习成本颇高,并且无法支持事务和多维索引,使得许多业务无法享用来自NoSQL系统中线性拓展能力。 Google内部MegaStore就作为Bigtable的一个补充而出现,在Bigtable的上层支持了SQL,事务、索引、跨机房灾备,并成为大 名鼎鼎的Gmail、APPEngine、Android Market的底层存储。近期Google在MegaStore的基础上升级了F1的系统,因此我们决定以MegaStore&F1为理论模型进 行探索如何在HBase系统上不牺牲线性拓展能力的同时又能提供跨行事务、索引、SQL的功能。通过简单的用户入口SQL,用户可以不需要关注hbase 的schema设计,极大的简化了用户的数据迁移和学习成本。理论设计详情见MegaStore及F1。
Wasp是分布式的、支持SQL的、事务型数据库:
支持索引类型:本地索引、全局索引
支持分区(分区可再分区、合并、移动部署),可线性拓展
支持数据类型:int64、int32、string、double、float、datetime
SQL语法特性:select、update、delete、insert、create table、delete table、create index、drop index等
支持跨行事务,支持NoSQl之上的索引与实体的ACID
支持MVCC
JDBC访问接口
易用的监控:Ganglia - metrics
未来的规划
SQL分析性统计型函数
资源隔离
权限
简化 velocity 模板引擎 min-velocity
min-velocity 是一个专为代码生成而定制的简化 velocity 模板引擎。
目标:
以 velocity 1.7 为基础, 裁剪出适合用作代码生成的模板引擎
裁剪:
没有event机制
没有macro
没有stop
没有evaluate
没有define
没有break
改动:
requires jdk1.5+
默认情况下,不打印任何日志
默认采用classpath模板加载器而非文件系统模板加载器
default I/O encoding changed to UTF-8(from iso-8859-1)
对于#set指令,默认允许设置null值
默认打开resource cache
去掉了parser pool
#parse和#include标签支持相对路径
新增$ParseUtil.recParsing("xxx.vm").addParam("key", val)模板调用形式;相当于带调用栈的#parse标签,能用在当你需要每层递归的context都相互隔离的递归#parse的时候;也能支持相对路径
可放置min-velocity.properties文件(可选)在classpath根路径下,用于覆盖velocity的各种默认属性
min-velocity.properties可使用default.static.util.mappings属性配置默认的静态工具类,这 些工具类将被默认放入模板context中,可配置多个,如:default.static.util.mappings = ClassUtils:org.apache.commons.lang.ClassUtils
设置'stream.reference.rendering'开关(true/false),默认关闭; 开启后,遇到reference是stream或reader的时候, 将读取stream或reader中的内容做渲染而非简单地toString渲染; 其中读取stream或reader的buffer可通过'stream.reference.rendering.buffer.size'配置大小 (默认为1024个字符); 亦可通过'stream.reference.rendering.limit'选项设置能够从流中读取的最大字符数限制(默认为100000)
支持String模板渲染,即直接将模板内容以String形式传入api进行渲染而不是只能选择传入一个模板路径
新增index.out.of.bounds.exception.suppress选项,当设置为true时,模板中对数组或list进行的取值或设置操作将忽略index out of bounds异常
For English speakers, see below:
No event mechanism
No macro
No '#stop'
No '#evaluate'
No '#define'
No '#break'
requires jdk1.5+
By default no logs rather than log to velocity.log
defaults to use classapth resource loader
I/O encoding defaults to UTF-8
#set directive defaults to allow null value
resource cache on by default
parser pool removed
relative path support for #parse and #include directives
$ParseUtil.recParsing("xxx.vm").addParam("key", val) template parsing util added. You can see it as a '#parse' directive with invocation stack frame,
which could easily do recursive parsing with isolated context in each round of recursion. This also supports relative path.could place an optional 'min-velocity.properties' file in classpath root to configure velocity runtime.
min-velocity could contain zero or more 'default.static.util.mappings' property configs to expose static utility classes in template contexts, for example: default.static.util.mappings = ClassUtils:org.apache.commons.lang.ClassUtils, with this config you can reference to org.apache.commons.lang.ClassUtils class with key 'ClassUtils' anywhere.
stream/reader reference rendering supported. If you set 'stream.reference.rendering'(default false) to 'true', min-velocity will dump the contents of a stream/reader reference rather than just invoking 'toString' on them while rendering. And the stream/reader reading buffer size could be specified by configuration 'stream.reference.rendering.buffer.size', measured in number of characters(default 1024). And further more, the maximum number of characters read from a stream could be limited by configuration 'stream.reference.rendering.limit'(default 100000).
String literal templates rendering supported. Just specify template contents in a in-memory-String value to render, other than always specify a template path.
When 'index.out.of.bounds.exception.suppress' option is setting to be 'true',any 'IndexOutOfBoundsException' will be ignored when accessing or setting elements of arrays and lists.
Maven Central Repo:
<dependency><groupId>com.github.pfmiles</groupId><artifactId>min-velocity</artifactId><version>1.0</version>
</dependency>代码样例参见单元测试:
package com.github.pfmiles.minvelocity;import java.io.StringReader;
import java.io.StringWriter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;import junit.framework.TestCase;import com.github.pfmiles.org.apache.velocity.Template;public class TemplateUtilTest extends TestCase {public void testRenderStringTemp() {String templateString = "#foreach($i in $list)\n$i\n#end";Map<String, Object> ctxPojo = new HashMap<String, Object>();List<String> list = new ArrayList<String>();list.add("one");list.add("two");list.add("three");ctxPojo.put("list", list);StringWriter out = new StringWriter();TemplateUtil.renderString(templateString, ctxPojo, out);// System.out.println(out.toString());assertTrue("one\ntwo\nthree\n".equals(out.toString()));}public void testRenderTemplate() {Template temp = TemplateUtil.parseStringTemplate("#foreach($i in $list)\n$i\n#end");Map<String, Object> ctxPojo = new HashMap<String, Object>();List<String> list = new ArrayList<String>();list.add("one");list.add("two");list.add("three");ctxPojo.put("list", list);StringWriter out = new StringWriter();TemplateUtil.renderTemplate(temp, ctxPojo, out);// System.out.println(out.toString());assertTrue("one\ntwo\nthree\n".equals(out.toString()));}public void testRefRendering() {Template temp = TemplateUtil.parseStringTemplate("hello $ref world");Map<String, Object> ctxPojo = new HashMap<String, Object>();StringReader stream = new StringReader("1234567890");ctxPojo.put("ref", stream);StringWriter writer = new StringWriter();TemplateUtil.renderTemplate(temp, ctxPojo, writer);assertTrue("hello 1234567890 world".equals(writer.toString()));}
}CSS 解决方案 thx Cube
Cube 是一套跨终端、响应式、低设计耦合的CSS解决方案。包含全新基础重置、布局、按钮、工具类、字体图标等相对独立的模块。此外还提供专为中文排版优化的type.css,可以快速美化文章的排版。
Cube 取自电影 《Cube》。电影里的 Cube 是个构造错综复杂的立方体,我们取这个名字,则是希望此项目能回归立方体的本意,和电影的愿景, 即项目应简单,一横一竖,自成一体。
模块
Neat 全新的样式重置
Layout 更加丰富的布局
Iconfont 海量图标字体
Button 自适应按钮
Type 照顾中文的版式设计
开源公司黄页 关于/ 阿里巴巴的50款开源软件[大部分为Java语言]相关推荐
- 2016年开源软件排名TOP50,最受IT公司欢迎的50款开源软件
2016年开源软件排名TOP50,最受IT公司欢迎的50款开源软件 过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自己的 IT 基础设施和网站,一些提供与开源工具相关的产品和服 ...
- 科技公司最常用的50款开源工具,提升你的逼格~
点击关注上方"视学算法",设为"置顶或星标",第一时间送达技术干货. 本文介绍了多款知名的开源应用软件,科技公司可以用它们来管理自己的 IT 基础设施.开发产品 ...
- 科技公司最爱的 50 款开源工具,你都用过吗?
来源 | GitHubDaily 本文介绍了多款知名的开源应用软件,科技公司可以用它们来管理自己的 IT 基础设施.开发产品. 过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自 ...
- 最受IT公司欢迎的50款开源软件
过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自己的 IT 基础设施和网站,一些提供与开源工具相关的产品和服务,或基于开源工具而建的产品和服务,还有一些在为开源代码贡献代码或支 ...
- 科技公司钟爱的50款开源工具
过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自己的IT基础设施和网站,一些提供与开源工具相关的产品和服务,或基于开源工具而建的产品和服务,还有一些在为开源代码贡献代码或支持开 ...
- 科技公司钟爱的50款开源工具--转载
本文介绍了多款知名的开源应用软件,科技公司可以用它们来管理自己的 IT 基础设施.开发产品. 过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自己的 IT 基础设施和网站,一些提 ...
- 大公司青睐的50款开源工具
过去十年间,许多科技公司已开始畅怀拥抱开源.许多公司使用开源工具来运行自己的IT基础设施和网站,一些提供与开源工具相关的产品和服务,或基于开源工具而建的产品和服务,还有一些在为开源代码贡献代码或支持开 ...
- 开源公司黄页之阿里巴巴开源软件推荐(一)
Dubbo--服务框架 Dubbo 是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和Spring框架无缝集成. 主要核心部件: Remot ...
- 阿里巴巴的73款开源项目
一.框架 react-web:Readt Web是为那些使用React Native兼容的API构建的Web应用而提供的一个框架.React Web的目的及意义非常明确: 让React Native代 ...
最新文章
- oracle多种导入导出数据方法
- 4 拼接_解析,地漏与瓷砖的4种拼接方法及安装工艺
- c++ extern “C”
- 保护模式下的80386及其编程02:机器状态和存储寻址
- U-boot.lds文件分析
- 通过wifi上网,桥接模式下virtualBox虚拟机无法连上网的解决办法
- hdu 1686(标准的kmp,可当模板)
- mybatis代码自动生成工具-MyBatis Generator
- 移动通信发展史与5G技术的探索
- 一文看懂数字孪生,工信部权威白皮书
- fft和freqz的区别
- 龙芯3号处理器-龙芯3A1000,龙芯3A2000/3B2000,龙芯3A1500I,龙芯3A3000/3B3000
- 批量生成条形码并且使用压缩包的方式下载
- 华东师范大学计算机组成原理教材,华东师范大学计算机组成原理.ppt
- ERP财务管理系统有哪些特点
- 胡昌泽 day3笔记
- 如何让固定资产管理不再一地鸡毛
- 最简单的SpringCloudStream集成Kafka教程
- mac苹果系统数据恢复软件恢复苹果电脑硬盘数据教程
- 港科夜闻|香港科大新任校长叶玉如教授回应施政报告
热门文章
- 陈鸽:正统或异端_异端的制作:环境艺术
- SFC发布时间基本确定
- Ruoyi-Vue 自定义跳转页面
- 基于W801和Helix解码库的MP3播放器(W801单片机学习笔记)热血沸腾,流畅播放
- 【Unity2D好项目分享】用全是好活制作横版卷轴射击游戏④制作敌人管理器以及播数显示和音效以及场景加载器
- 《迷人的8051单片机》----第2章 神秘的半导体 2.1 二极管
- luogu P2047 社交网络
- matlab的quiver函数的用法
- Android设计应用图标不用愁---Asset Studio Integration来帮你
- 判断 Android rom是不是 EMUI(Emotion UI)