利用Keras使用非常少的数据建立强大的图像分类模型
博客原文
在本教程中,我们将介绍一些简单而有效的方法,您可以使用这些方法来构建强大的图像分类器,仅使用极少数的训练实例 - 只需从您想要识别的每个类别中挑选几百或几千张图片即可。
我们将会涵盖以下内容:
- 从零开始训练一个小网络(作为基准)
- 使用预训练网络的bottleneck features
- 微调预训练模型的顶层
这会涵盖到以下几个Keras特征:
- fit_generator:用于使用Python数据生成器来训练keras模型
- imagedatagenerator:用于实时数据增强
- layer freezing(层冷冻)和fine-tuning(模型微调)
- 其它
注意:2017年3月14日,所有的代码示例已经更新为keras 2.0 api。您需要keras 2.0.0或更高版本才能运行它们。
Our setup: 只有2000个训练样例(1000每类)
我们将从以下设置开始:
- 一台安装了keras,scipy,pil的电脑。如果你有一个可以使用的nvidia
gpu(并且安装了cudnn),那很好,但是因为我们将要处理的图像数目不多,所以不是严格需要的。 - 一个训练数据目录和验证数据目录,每个图像类包含一个子目录,含有.png或.jpg图像:
data/train/dogs/dog001.jpgdog002.jpg...cats/cat001.jpgcat002.jpg...validation/dogs/dog001.jpgdog002.jpg...cats/cat001.jpgcat002.jpg...要获得属于您感兴趣的物体类的数百或数千张的训练图像,一种可能性是使用flickr api在获得许可的情况下下载给定标签的图片。
在我们的例子中,我们将使用两类从kaggle获得的图片集:1000只猫和1000只狗(虽然原始数据集有12,500只猫和12,500只狗,但我们只是取了每个类别的前1000张图像)。我们还使用每个类别的400个额外样本作为验证数据来评估我们的模型。
从非常少的样本中学习对于分类问题来说并不简单。所以这是一个具有挑战性的机器学习问题,但也是一个现实的问题:在很多现实世界的使用案例中,即使是小规模的数据收集也可能是非常昂贵的,或者有时几乎是不可能的(例如在医学成像中)。能够充分利用很少的数据是数据科学家的关键技能。

在Kaggle的cats vs. dogs比赛中(总共有25,000训练图像),结果排在前几位的参赛者通过使用现代深度学习技巧,达到了超过98%的准确率。在我们的例子中,因为我们限制数据规模只有原数据集的8%,所以这个问题是比较难的。
对于小数据问题而言,深度学习的相关性
我常常听到的一个信息是:“深度学习只有当你拥有大量的数据时才有意义”。虽然不完全不正确,但这有些误导。当然,深度学习需要能够从数据中自动学习特征,这通常只有在大量训练数据可用时才可能 - 特别是对于输入样本非常高维的问题,如图像。然而,卷积神经网络 - 深度学习的支柱算法 - 被设计成为可用于大多数“感知”问题(如图像分类)的最佳模型之一,即使只有很少的数据可供学习。在小图像数据集上从头开始构建一个卷积网络仍然可以得到合理的结果,而不需要任何传统的特征工程。卷积网络是非常好的。他们是完成这项工作的合适工具。
更重要的是,深度学习模式在本质上是高度可重复使用的:例如,您可以采用在大规模数据集上训练的图像分类或语音转文本的模型,然后在仅有微小变化的情况下将其用于显著不同的问题,如我们将在这篇文章中看到的。特别是在计算机视觉的领域,许多预先训练过的模型(通常在imagenet数据集上进行训练)现在可以公开下载,并可以用很少的数据来训练得到强大的视觉模型。
数据预处理和数据增强
为了充分利用我们少数的训练实例,我们将通过一系列随机变换来“扩充”它们,这样我们的模型将永远不会看到两次完全相同的图像。这有助于防止过拟合,并帮助模型泛化得更好。
在keras中这可以通过keras.preprocessing.image.ImageDataGenerator类来完成。这个类允许你:
- 在训练期间在您的图像数据上配置随机变换和规范化操作
- 通过.flow(data, labels)或.flow_from_directory(directory)实例化被数据增强的image
batches(及其标签)的生成器。这些生成器可以用于fit_generator,evaluate_generator和predict_generator这些接受数据生成器作为输入的keras模型方法。
让我们来立即看一个例子:
from keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator(rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')这些只是一些可用的选项(更多,请参阅文档)。让我们快速回顾我们刚刚写的:
- rotation_range是一个角度值(0-180),代表随机旋转图像的范围。
- width_shift和height_shift是随机水平或垂直的平移图片的范围(占总宽或高的比例)
- rescale是是我们在其他任何处理之前乘以数据的一个值。我们的原始图像是包含在0-255的RGB像素,但是对于我们的模型来说,这样的数值太高了(给定一个典型的学习速率),所以我们通过一个1./255的缩放因子将目标值设定在0和1之间。
- shear_range用于shearing变换(大致含义是将图形的垂直边(水平边)沿水平(垂直)方向倾斜)
- zoom_range用于在图像中进行随机的缩放
- horizontal_flip 用于随机的水平翻转图像
- fill_mode是用于填充空白的策略,在旋转或宽度/高度平移后会出现
现在让我们开始使用这个工具生成一些图片,并将它们保存到一个临时目录中,这样我们就可以感觉到我们的增强策略正在做什么 - 在这种情况下禁用rescale参数以保持图像的可显示性:
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_imgdatagen = ImageDataGenerator(rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,fill_mode='nearest')img = load_img('data/train/cats/cat.0.jpg') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,save_to_dir='preview', save_prefix='cat', save_format='jpeg'):i += 1if i > 20:break # otherwise the generator would loop indefinitely下面是我们得到的——这就是我们数据增强策略的效果

从零开始训练一个小型卷积网络:仅用40行代码达到80%的准确率
图像分类工作的合适工具是卷积网络,所以让我们试着对我们的数据进行一次训练,作为初始基准。由于我们只有很少的样本,我们的首要关注的应该是过拟合。当只有少数样例的模型学习到不能泛化到新数据的模式时,即当模型开始使用不相关的特征进行预测时,过拟合就会发生。例如,如果你只能看到有三个伐木工人和三个水手的图像,其中只有一个伐木工人戴帽子,你可能会开始觉得戴帽子是伐木工人区别于水手的标志。那么你就变成了一个非常糟糕的伐木工/水手分类器。
数据增强是缓解过拟合的一种方法,但是这还不够,因为我们增加的样本仍然高度相关。解决过拟合的主要焦点应该是你的模型的熵容量(entropy capacity)——你的模型允许存储多少信息。一个可以存储大量信息的模型通过利用更多的特征可能会更加准确,但它也会有更大的风险开始存储不相关的特征。另一方面,一个只能存储少量特征的模型将不得不关注数据中最重要的特征,而这些特征更可能是真正相关的且能泛化得更好。
有不同的方式来调节熵容量。最主要的是你的模型中参数个数的选择,即网络层的数量和每个网络层的大小。另一种方法是使用权重正则化,如L1或L2正则化,它们能迫使模型权重取较小的值。
在我们的例子中,我们将使用一个非常小的卷积网络,每个网络层只有几层和几个滤波器,还有数据增强和dropout。Dropout通过防止一个网络层看到两次完全相同的模式,也有助于减少过拟合,从而以类似于数据增强的方式起作用(可以说,dropout和数据增加往往可以破坏数据中出现的随机相关)。
下面的代码片段是我们的第一个模型,一个简单的带有relu激活,然后跟着max-pooling的三层卷积层。这与yann lecun在20世纪90年代提出的用于图像分类的体系结构(relu除外)非常相似。
这个实验的完整代码可以在这里找到。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Densemodel = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))# the model so far outputs 3D feature maps (height, width, features)在它上面,我们插入两个全连接层。我们用一个单独单元和sigmoid激活函数来结束模型,这对于二元分类是完美的。与它一起,我们也将使用binary_crossentropy损失来训练我们的模型。
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])让我们准备我们的数据。我们将使用.flow_from_directory()直接从我们的jpeg图像生成批量的图像数据(及其标签)。
batch_size = 16# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)# this is the augmentation configuration we will use for testing:
# only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)# this is a generator that will read pictures found in
# subfolers of 'data/train', and indefinitely generate
# batches of augmented image data
train_generator = train_datagen.flow_from_directory('data/train', # this is the target directorytarget_size=(150, 150), # all images will be resized to 150x150batch_size=batch_size,class_mode='binary') # since we use binary_crossentropy loss, we need binary labels# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory('data/validation',target_size=(150, 150),batch_size=batch_size,class_mode='binary')我们现在可以使用这些生成器来训练我们的模型。每个epoch在GPU上需要20-30s,在CPU上需要300-400s。所以如果你不着急的话,在CPU上运行这个模型肯定也是可行的。
model.fit_generator(train_generator,steps_per_epoch=2000 // batch_size,epochs=50,validation_data=validation_generator,validation_steps=800 // batch_size)
model.save_weights('first_try.h5') # always save your weights after training or during training这个方法使得我们在50个epoches(一个被任意挑选的数字 - 由于模型很小并且使用了dropout,在这点上似乎没有太多过拟合)的验证准确率为0.79-0.81。所以在那时的kaggle比赛发起的时候,我们已经是“最先进的”了 - 有8%的数据,并且还没有怎么去优化我们的体系结构或超参数。事实上,在kaggle的比赛中,这个模型将进入前100名(215名参赛者中)。我想至少有115名参赛者没有使用深度学习;)
请注意,验证准确率的方差相当高,这是因为准确率是一个具有高方差的度量指标,而且我们只使用了800个验证样本。在这种情况下,一个好的验证策略是进行k-折交叉验证,但是这需要在每轮评估中训练k个模型。
使用预训练网络的bottleneck特征:在1分钟内得到90%的准确率
更精细的方法是利用在大型数据集上预训练的网络。这样的网络已经学会了对于大多数计算机视觉问题有用的特征,并且利用这些特征将使得我们能够比仅依赖于可用数据的任何方法获得更好的准确率。
我们将使用vgg16架构,在imagenet数据集上进行预先训练,这是以前在这个博客上讲过的一个模型。因为imagenet数据集在1000个类中包含了几个“猫”类(波斯猫,暹罗猫)和许多“狗”类,所以这个模型已经学到了与我们的分类问题相关的特征。事实上,仅仅在我们的数据上而不是在bottleneck特征上记录模型的softmax预测就足以很好地解决我们的狗与猫的分类问题。然而,我们在这里提出的方法更容易推广到更广泛的问题,包括ImageNet上没有的类。
下图是VGG16的结构:
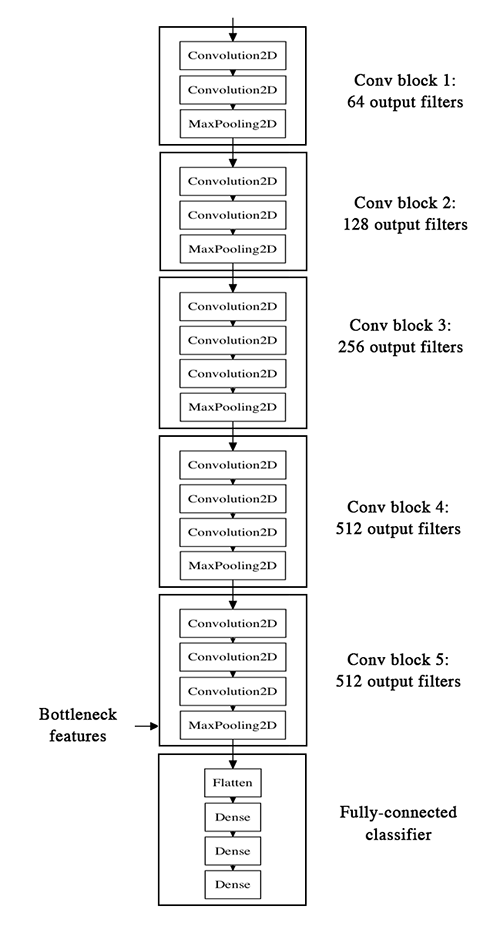
我们的策略将如下:我们将只实例化模型的卷积部分(到全连接层以前为止)。我们将在我们的训练和验证数据上运行这个模型一次,在两个numpy数组中记录输出(vgg16模型的“bottleneck特征”:全连接层之前的最后一个激活层)。然后我们将在存储的特征之上训练一个小的全连接模型。
为什么我们要离线存储这些特征,而不是直接在一个冻结的卷积网络的基础上增加我们的全连接模型并运行整个网络,这是计算效率的原因。运行vgg16的代价是很昂贵的,特别是如果你在使用cpu,而且我们只想做一次。请注意,这可以防止我们使用数据增强。
你可以在这里找到这个实验的完整代码。你可以从github获得权重文件。我们不会回顾模型是如何构建和加载的 - 这已经被多个keras例子所覆盖。但让我们来看看如何使用图像数据生成器记录bottleneck 特征:
batch_size = 16generator = datagen.flow_from_directory('data/train',target_size=(150, 150),batch_size=batch_size,class_mode=None, # this means our generator will only yield batches of data, no labelsshuffle=False) # our data will be in order, so all first 1000 images will be cats, then 1000 dogs
# the predict_generator method returns the output of a model, given
# a generator that yields batches of numpy data
bottleneck_features_train = model.predict_generator(generator, 2000)
# save the output as a Numpy array
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)generator = datagen.flow_from_directory('data/validation',target_size=(150, 150),batch_size=batch_size,class_mode=None,shuffle=False)
bottleneck_features_validation = model.predict_generator(generator, 800)
np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)然后我们可以加载保存的数据并训练一个小型的全连接模型:
train_data = np.load(open('bottleneck_features_train.npy'))
# the features were saved in order, so recreating the labels is easy
train_labels = np.array([0] * 1000 + [1] * 1000)validation_data = np.load(open('bottleneck_features_validation.npy'))
validation_labels = np.array([0] * 400 + [1] * 400)model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])model.fit(train_data, train_labels,epochs=50,batch_size=batch_size,validation_data=(validation_data, validation_labels))
model.save_weights('bottleneck_fc_model.h5')由于它的小尺寸,即使在CPU上该模型训练起来也非常快(1s每个epoch):
![]()
我们达到了0.90-0.91的验证准确率:一点也不差。这肯定部分是由于基础模型是在一个已经包含了狗和猫的数据集上进行训练的(其他数百个类)。
微调预训练网络的顶层
为了进一步改进我们前面的结果,我们可以尝试在顶层分类器旁边“微调”vgg16模型的最后一个卷积块。微调是指从一个已训练的网络开始,然后在新数据集上使用非常小的权重更新重新训练该网络。在我们的例子中,这可以分三步完成:
- 实例化vgg16的卷积基础模型并加载它的权重
- 将我们先前定义的全连接模型添加到顶部,并加载其权重
- 冻结vgg16模型直到最后一个卷积块之前的层
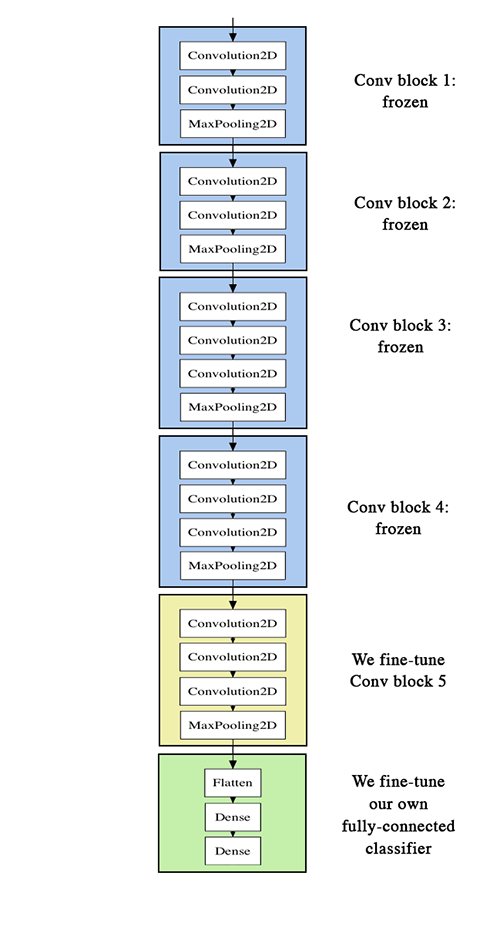
注意到:
- 为了进行微调,所有的网络层都应该以适当的训练权重开始:例如,你不应该在预训练的卷积基础模型上随便加一个随机初始化的全连接网络。这是因为由随机初始化权重触发的大梯度更新会破坏卷积基础模型中学习的权重。在我们的例子中,这就是为什么我们首先要训练顶层分类器,然后才开始微调卷积权重。
- 我们选择只调整最后的卷积块,而不是整个网络,以防止过拟合,因为整个网络将具有非常大的熵容量,并因此具有过度拟合的强烈倾向。由低级卷积块学习的特征更为普遍,抽象性更强,因此保留前几个块是固定的(更一般的特征),并且只调整最后一块(更具体的特征)。
- 微调应该以非常慢的学习速度来完成,并且通常使用sgd优化器而不是诸如rmsprop的自适应学习速率优化器。这是为了确保更新的大小保持非常小,以免破坏以前学到的特征。
你可以在这里找到实验的完整代码。
在实例化vgg基础模型并加载其权重之后,我们将先前训练过的全连接的分类器添加到顶部:
# build a classifier model to put on top of the convolutional model
top_model = Sequential()
top_model.add(Flatten(input_shape=model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))# note that it is necessary to start with a fully-trained
# classifier, including the top classifier,
# in order to successfully do fine-tuning
top_model.load_weights(top_model_weights_path)# add the model on top of the convolutional base
model.add(top_model)然后我们冻结vgg16模型直到最后一个卷积块之前的所有卷积层:
# set the first 25 layers (up to the last conv block)
# to non-trainable (weights will not be updated)
for layer in model.layers[:15]:layer.trainable = False# compile the model with a SGD/momentum optimizer
# and a very slow learning rate.
model.compile(loss='binary_crossentropy',optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=['accuracy'])最后,我们以一个非常小的学习率开始训练整个网络:
batch_size = 16# prepare data augmentation configuration
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')# fine-tune the model
model.fit_generator(train_generator,steps_per_epoch=nb_train_samples // batch_size,epochs=epochs,validation_data=validation_generator,validation_steps=nb_validation_samples // batch_size)这个方法使得我们在50个epoches后达到0.94的验证准确率。巨大的成功!
这里有几个方法可以尝试达到0.95以上:
- 更多的数据增强
- 更多的dropout
- 使用L1和L2正则化(也被叫做“权值衰减”)
- 微调超过一个的卷积块(附带更大的正则化)
这篇文章在这里结束!回顾一下,这里是你可以找到我们的三个实验的代码:
- Convnet trained from scratch
- Bottleneck features
- Fine-tuning
也可参考本人关于该博客的github练习小项目(修正了一些源代码的小错误)。
利用Keras使用非常少的数据建立强大的图像分类模型相关推荐
- Keras快速上手——打造个人的第一个“圣诞老人”图像分类模型
首发地址:https://yq.aliyun.com/articles/288077 2017年已到最后一个月的尾巴,那圣诞节还会远吗?不知道各位对于圣诞节有什么安排或一些美好的回忆,我记得最清楚的还 ...
- 使用Python+OpenCV+Keras创建自己的图像分类模型
介绍 你是否曾经偶然发现一个数据集或图像,并想知道是否可以创建一个能够区分或识别图像的系统? 图像分类的概念将帮助我们解决这个问题.图像分类是计算机视觉最热门的应用之一,是任何想在这个领域工作的人都必 ...
- 【TensorFlow-windows】keras接口——利用tensorflow的方法加载数据
前言 之前使用tensorflow和keras的时候,都各自有一套数据读取方法,但是遇到一个问题就是,在训练的时候,GPU的利用率忽高忽低,极大可能是由于训练过程中读取每个batch数据造成的,所以又 ...
- Keras之DNN:利用DNN【Input(8)→(12+8)(relu)→O(sigmoid)】模型实现预测新数据(利用糖尿病数据集的八个特征进行二分类预测
Keras之DNN:利用DNN[Input(8)→(12+8)(relu)→O(sigmoid)]模型实现预测新数据(利用糖尿病数据集的八个特征进行二分类预测 目录 输出结果 设计思路 实现代码 输出 ...
- 利用训练数据建立一个简单的分类器
利用训练数据建立一个简单的分类器 在机器学习领域中,分类指的是利用数据的特性将其分成若干类型的过程.分类器则可以是实现分类功能的任意算法,最简单的分类器就是简单的数字函数.在真实世界中,分类器可以是非 ...
- python实现人脸检测及识别(2)---- 利用keras库训练人脸识别模型
前面已经采集好数据集boss文件夹存放需要识别的对象照片,other存放其他人的训练集照片,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的tensorflo ...
- Keras: 多输入及混合数据输入的神经网络模型
目录 摘要 正文 什么是混合数据? Keras如何接受多个输入? 房价数据集 获取房价数据集 项目结构 加载数值和分类数据 加载图像数据集 定义多层感知器(MLP)和卷积神经网络(CNN) 使用Ker ...
- 深度学习数据驱动_利用深度学习实现手绘数据可视化的生成
前一段时间,我开发了Sketchify, 该工具可以把任何以SVG为渲染技术的可视化转化为手绘风格.(参考手绘风格的数据可视化实现 Sketchify) 那么问题来了,很多的chart是以Canvas ...
- 浪潮王洪添 :让数据“多跑路”,让群众“少跑腿”数据融合是核心
就在今年1月27日,国务院办公厅关于印发了"互联网+政务服务"技术体系建设指南的通知.(下称<通知>),<通知>指出,到2020年底前,建成覆盖全国的整体联 ...
最新文章
- Oracle 的两种工作模式Dedicated Server 和 Shared Server
- python PyQt5 adjustSize()(根据内容自适应大小)
- WebService部署时提示:HTTP错误 404.3-Not Found,如果该页面是脚本,请添加处理程序,如果应下载文件,请添加MIME映射
- 【数学基础】算法工程师必备的机器学习--线性模型(上)
- 200924阶段一C++STL
- oracle数据库图书,基于oracle数据库,创建图书表(一)
- spring整合atomikos实现分布式事务的方法示例_分布式-分布式事务处理
- python读写pdf_Python读写PDF
- 微信小程序 实现提示弹窗
- html5 电子白板 直播,HTML5 canvas教程 如何实现电子白板
- CSDN博客上传的图片水印去除
- nohup命令解决SpringBoot/java -jar命令启动项目运行一段时间自动停止问题
- 【BUCTOJ训练:字符串最大跨距(Python)】
- 乔布斯的斯坦福演讲(双语)
- 使用Redis缓存优化
- 用了十年竟然都不对,Java、Rust、Go主流编程语言的哈希表比较
- python精彩编程200例 pdf-Python创意编程200例turtle篇
- oracle简单序列,oracle序列生成器(sequence)使用的一点小注意
- 工程图学及计算机绘图第3版答案,工程制图习题集孙培先主编答案求电子版
- 前端性能优化(二)01-页面性能优化之浏览器——浏览器的主要作用 浏览器的组成结构