python爬虫爬取视频_python爬虫:爬取网站视频
新建一个py文件,代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib,re,requests
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
url_name = [] #url name
def get():
#获取源码
hd = {"User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}
url = 'http://www.budejie.com/video/'
html = requests.get(url,headers=hd).text
url_content = re.compile(r'(
.*?)',re.S) #编译
url_contents = re.findall(url_content,html) #匹配
for i in url_contents:
#匹配视频
url_reg = r'data-mp4="(.*?)"' #视频地址
url_items = re.findall(url_reg,i)
#print url_items
if url_items: #判断视频是否存在
name_reg = re.compile(r'(.*?)',re.S)
name_items = re.findall(name_reg,i)
#print name_items[0]
for i,k in zip(name_items,url_items):
url_name.append([i,k])
print i,k
for i in url_name: #i[1]=url i[0]=name
urllib.urlretrieve(i[1],'video\\%s.mp4' % (i[0].decode('utf-8')))
if __name__ == "__main__":
get()
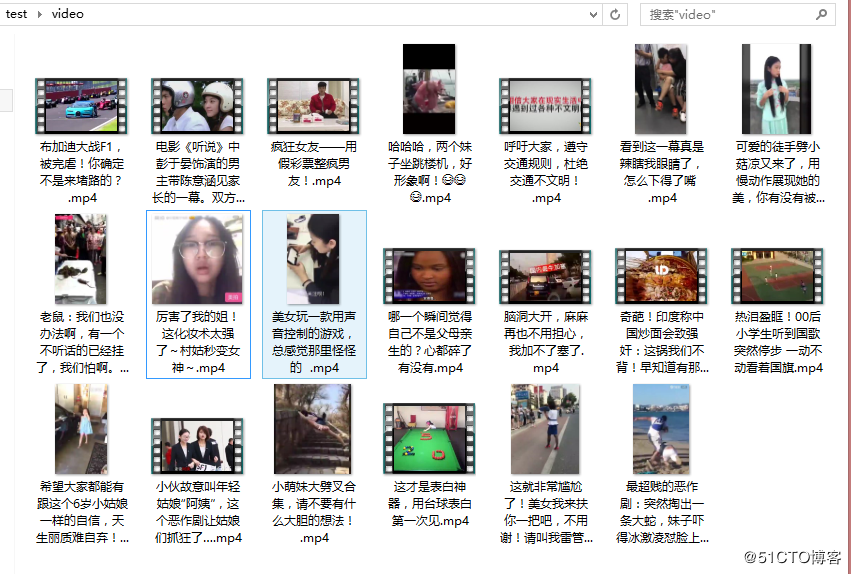
在 py 文件下新建一个 video 文件夹,执行后结果如下:
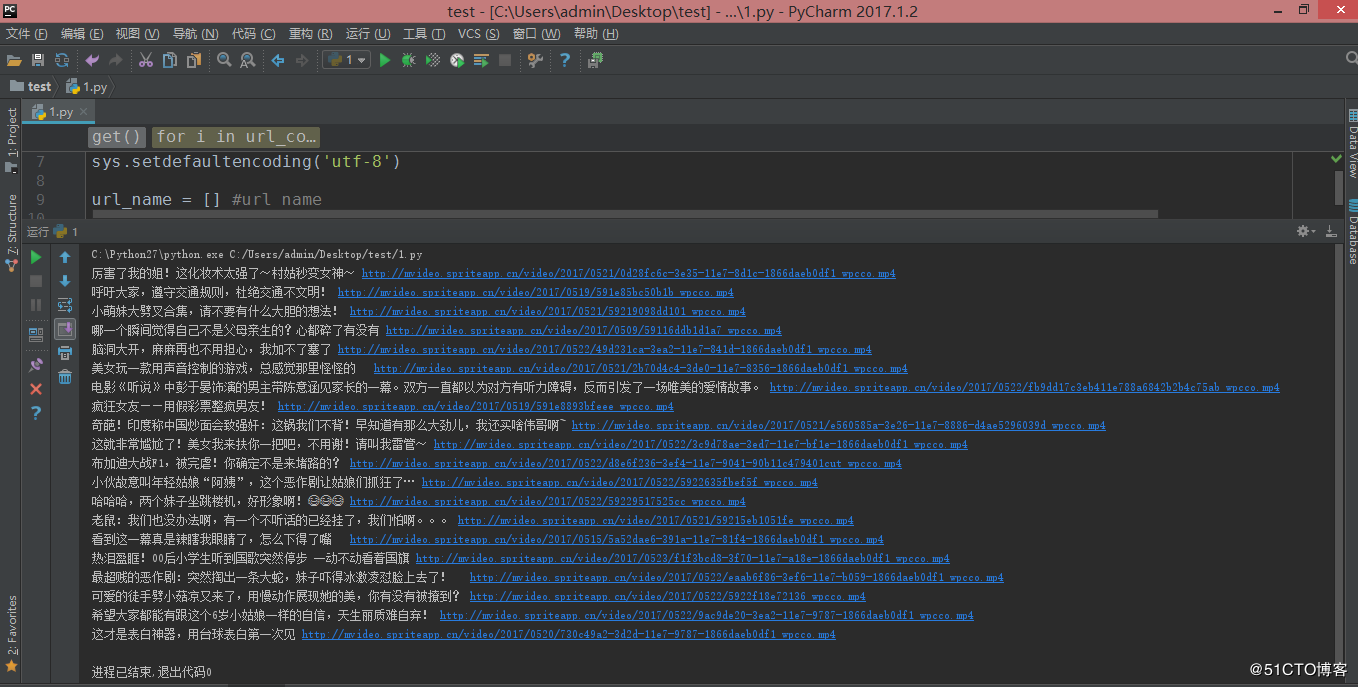
在 video 文件夹可以看到下载好的视频
注意报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-9: ordinal not in range(128)
解决:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
打开App,阅读手记
python爬虫爬取视频_python爬虫:爬取网站视频相关推荐
- python爬电影天堂_python爬虫爬取电影天堂电影
python爬虫爬取电影天堂电影?本项目实现一个简单的爬虫,通过requests和BeautifulSoup爬取电影天堂电影信息,包括片名.年代.产地.类别.语言.海报链接和视频链接等内容.pytho ...
- python爬取方式_Python 爬虫入门(三)—— 寻找合适的爬取策略
写爬虫之前,首先要明确爬取的数据.然后,思考从哪些地方可以获取这些数据.下面以一个实际案例来说明,怎么寻找一个好的爬虫策略.(代码仅供学习交流,切勿用作商业或其他有害行为) 1).方式一:直接爬取网站 ...
- python爬虫微博评论图片_python爬虫爬取微博评论
原标题:python爬虫爬取微博评论 python爬虫是程序员们一定会掌握的知识,练习python爬虫时,很多人会选择爬取微博练手.python爬虫微博根据微博存在于不同媒介上,所爬取的难度有差异,无 ...
- python爬虫爬取歌曲_python爬虫实战:爬取全站小说排行榜
喜欢看小说的骚年们都知道,总是有一些小说让人耳目一新,不管是仙侠还是玄幻,前面更了几十章就成功圈了一大波粉丝,成功攀上飙升榜,热门榜等各种榜,扔几个栗子出来: 新笔趣阁是广大书友最值得收藏的网络小说阅 ...
- python爬虫爬取图片代码_Python爬虫入门:批量爬取网上图片的两种简单实现方式——基于urllib与requests...
Python到底多强大,绝对超乎菜鸟们(当然也包括我了)的想象.近期我接触到了爬虫,被小小地震撼一下.总体的感觉就两个词--"强大"和"有趣".今天就跟大家分享 ...
- python访问多个网页_Python 爬虫 2 爬取多页网页
本文内容: Requests.get 爬取多个页码的网页 例:爬取极客学院课程列表 爬虫步骤 打开目标网页,先查看网页源代码 get网页源码 找到想要的内容,找到规律,用正则表达式匹配,存储结果 Re ...
- python爬虫快速下载图片_Python爬虫入门:批量爬取网上图片的两种简单实现方式——基于urllib与requests...
Python到底多强大,绝对超乎菜鸟们(当然也包括我了)的想象.近期我接触到了爬虫,被小小地震撼一下.总体的感觉就两个词--"强大"和"有趣".今天就跟大家分享 ...
- python爬虫爬图片教程_Python爬虫入门教程 5-100 27270图片爬取
获取待爬取页面 今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥 ...
- python爬虫分析大学排名_Python爬虫之爬取中国大学排名(BeautifulSoup库)
image.png 我们需要打开网页源代码,查看此网页的信息是写在html代码中,还是由js文件动态生成的,如果是后者,那么我们目前仅仅采用requests和BeautifulSoup还很难爬取到排名 ...
- python爬虫爬取京东_Python爬虫学习 爬取京东商品
1. 本节目标 以抓取京东 App 的商品信息和评论为例,实现 Appium 和 mitmdump 二者结合的抓取.抓取的数据分为两部分:一部分是商品信息,我们需要获取商品的 ID.名称和图片,将它们 ...
最新文章
- Android5.0如何正确启用isLoggable(二) 理分析
- xp java配置_WinXP系统Java配置环境变量的方法
- python flask跨域_Flask配置Cors跨域的实现
- [pytorch、学习] - 4.5 读取和存储
- [SNOI2017]遗失的答案 (FWT)
- 浅析Java内存模型
- flash人物原地走路,Flash制作小人走路简单动画图文教程
- 零基础如何学前端,如何规划?
- SQL2005数据库连接
- 今日头条成锤子“接盘侠”?“是真的!”
- Humble Numbers(丑数) 超详解!
- python和c 的区别-Python和c语言的主要区别在哪
- Svn安装与整合Apache
- stat /bin/bash: no such file or directory“: unknown.
- ubuntu 16.04 gogs git 环境搭建
- echarts实现平面3D柱状图
- 解决win10没Wifi功能了,无线网卡驱动异常代码56的问题
- Access仿Excel的RoundUp函数向上取整的方法。
- 阿里云STMP邮箱验证
- 爱奇艺真的有1亿付费会员?十五扒了扒用户数据告诉你更多真相