MapReduce稍微高级编程之PageRank算法的实现
一、概念:
PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度。是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的。PageRank实现了将链接价值概念作为排名因素。
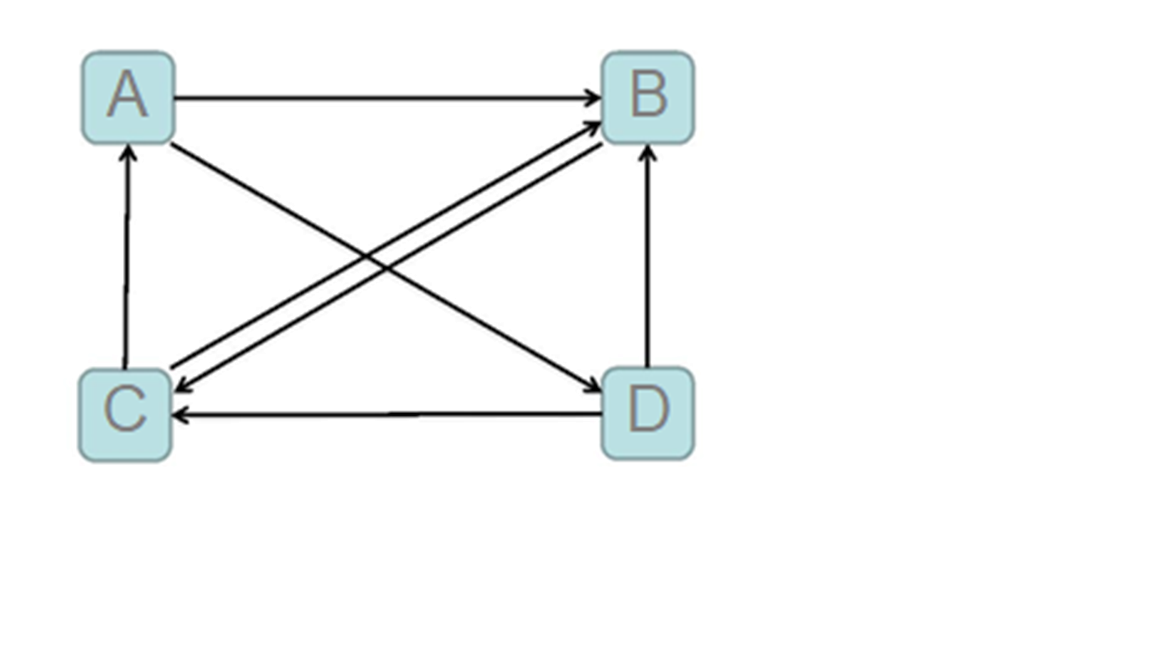
这幅图表示的是一个简单的网络,下面介绍几个名词:
- 入链:指向该页面的链接为入链,入链相当于投票,到一个页面的超链接相当于对该页投一票。
- 入链数量:如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要
- 入链质量:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。质量是指不同网页发出的链接所含的权重是不同的,比如百度百科里面的链接和你自己写的网页里面的链接肯定是不能比的。这么做主要是为了防止别人恶意刷“流量”。
- 出链:从本页面发出的链接为出链。
二、计算过程:
下面我们介绍一下PageRank的算法流程:
- 初始值:
每个页面设置相同的PR值,Google的PageRank算法给每个页面的PR初始值为1,该页面的所有出链均分该页面的值。以上图为例,A页面的初始值为1,然后它每一条出链会均分它的值,即'AB' = 0.5,'AD' = 0.5,以此类推,最后每条链接都有自己的初始值。 - 迭代递归计算:每个页面都会先减去它通过出链输出去的值变成0,然后又会加上它的入链送进来的值得到新的价值。Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。
在具体企业应用中怎么样确定收敛标准?
每个页面的PR值和上一次计算的PR相等
设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。
- 设定一个百分比(99%),当99%的页面和上一次计算的PR相等
三、算法修正:
上面的算法有点小问题,试想一下如果有一个页面它只有入度没有出度,即“孤立网页”。那么经过若干次计算后,该网络的权值会慢慢流向这个只进不出的页面,使得这个页面的价值异常增大。因此我们需要对 PageRank公式进行修正。即在简单公式的基础上增加了阻尼系数(damping factor)q, q一般取值q=0.85。完整的计算公式:
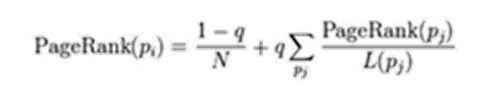
四、代码书写:
切入正题,开始写代码。
mapreduce是M->R单向过程,那么当需要这么做“M->R->M->R....”的时候,则需要设置累加器传参数。
enum Count {my
}这是个累加器定义,后面会获取它。
Map:
假设我们拿到的网页数据是这么表示的:/**按照制表符分割* A 1 B D* B 1 C* C 1 A B* D 1 B C*/第0列为页面名称,第1列表示该页面的价值(初始值为1),其后的每一列表示的是该页面所有的出链指向的页面名称,当然数量是不固定的。下面是Map阶段的代码:
class PageRankMapper extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split("\t");//首先拿到值,返回列表 String page = split[0];//page名称 Double pagerank = Double.parseDouble(split[1]);//初始值是1,但是在随后的计算中会出现小数所以在这里转成Double //获取出链列表 String[] outlist = Arrays.copyOfRange(split, 2, split.length);//用Array里面的方法复制剩下的页面,构成专门的页面数组,方便后面的迭代。//1、平分之后的pr值 Double avgPr = pagerank / outlist.length; //map阶段是要将数据的值发给reduce计算的,下面构造key和value for (String s : outlist) {Text outKey = new Text(s);//key Text outValue = new Text(avgPr.toString() + "\t*");//value值,以 "\t*"结尾是为了区分不同类型的数据//第一种数据:key是页面名称,value是被分到的值(将与来自不同map的value一起计算求和)context.write(outKey, outValue); }//指定分隔符拼接数组,将原有的行数据发过去,保持“A 1 B C”这样的每个网页的出链列表还存在,然后将计算的结果替换1 //加上上一次网页的pr值 String outListStr = split[1] + "\t" + StringUtils.join(outlist, "\t"); Text text = new Text(outListStr + "\t#"); context.write(new Text(page), text);} }Reduce:
拿到map发过来的数据应该是这样的<'A',['0.5 ','0.25 ','1 B D #']>,然后开始处理数据:class PageRankReducer extends Reducer<Text, Text, Text, Text> {@Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //当前网页的pagerank值 Double sum = 0.0; String lastPrAndOutList = ""; for (Text value : values) {String[] split = value.toString().split("\t");//每个value值都是用制表符分割的,且最后一个字符是标记,表示哪种类型的数据String flag = split[split.length - 1];//取标记//出链列表和上一次网页的pr值if ("#".equals(flag)) {//出链列表lastPrAndOutList = value.toString();} else if ("*".equals(flag)) {//pagerank值加和sum = sum + Double.parseDouble(split[0]);} }String[] split = lastPrAndOutList.split("\t");//上一次pr值 Double lastPr = Double.parseDouble(split[0]);String[] outList = Arrays.copyOfRange(split, 1, split.length - 1);//构成输出//加上阻尼系数,计算当前pr值 Double currPr = 0.15 / 4 + 0.85 * sum;//取绝对值 long abs = (long) (Math.abs(currPr - lastPr) * 1000);//获取累加器对象 Counter counter = context.getCounter(Count.my);//累加 /*** 累加所有网页pr值的差值*/ counter.increment(abs);//写入到hdfs /*** A 0.5 B D* B 1.5 C* C 1.5 A B* D 0.5 B C*/ context.write(key, new Text(currPr.toString() + "\t" + StringUtils.join(outList, "\t"))); }}设置job:
public class RunJob {
public static void main(String[] args) throws Exception {
int i = 0;//用来拼接字符串的//收敛阈值 double flag = 0.1;while (true) {i++;Configuration config = new Configuration();FileSystem fs = FileSystem.get(config);Job job = Job.getInstance(config);job.setJarByClass(com.shujia.mr.pagerank.RunJob.class);job.setJobName("pagerank");job.setMapperClass(PageRankMapper.class);job.setReducerClass(PageRankReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);job.setInputFormatClass(TextInputFormat.class);Path inputPath = new Path("E:\\data\\pagerank.txt");
//后一次读取前一次的输出结果if (i > 1) {inputPath = new Path("E:\\data\\out" + (i - 1));}FileInputFormat.addInputPath(job, inputPath);Path outPath = new Path("E:\\data\\out" + i);if (fs.exists(outPath)) {fs.delete(outPath, true);}FileOutputFormat.setOutputPath(job, outPath);boolean f = job.waitForCompletion(true);//计算当前所有网页的pagerank的和上一次pagerank的差值的平均值//当差值的平均值小于设定的阈值之后收敛/*** 累加器* 在map端或者reduce端累加,在主函数里面读取的一个变量**///获取累加器的值Counter counter = job.getCounters().findCounter(Count.my);long value = counter.getValue();
//差值的平均值double l = value / 4000.0;System.out.println(l);//当差值的平均值小于设定的阈值后收敛if (l < flag) {break;}}
}
}结语:
本篇只是简单地实现了pagerank算法,还有很多复杂情况处理,比如说并没有考虑入链质量问题,所以仅供练习。
MapReduce稍微高级编程之PageRank算法的实现相关推荐
- python flask高级编程之restful_('Python Flask高级编程之RESTFul API前后端分离精讲',),全套视频教程学习资料通过百度云网盘下载...
资源详情 r n t某课网好评度100%的Python Flask高级编程之RESTFul API前后端分离精讲 r n t t t第1章 随便聊聊 r n t t t聊聊Flask与Django,聊 ...
- unix环境高级编程之 read与write 函数详解
学习记录:unix环境高级编程之 read 与write 函数详解 备注:本博文非本人所写,本人觉得此文讲的非常地道通俗易懂,所以摘录在此以方便以后再次查看 read函数从打开的设备或文件中读取数据 ...
- QT高级编程之QT基本概览
QT高级编程 主要从以下几个方面来介绍QT高级编程,并介绍QT相关的概念. 1. QT部件Widget: 2. QT信号与槽机制: 3. 对象树关系: 4. 布局管理: 5.标准对话框以及自定义对话框 ...
- Qt高级编程之MVC框架
目录 前言 一.MVC简介 二.MVC架构 2.1 MVC层级关系图 2.2 MVC类结构图 三.模型/视图表格 3.1 标准表格模型 3.1.1 应用场景 3.1.2 数据过滤 3.1.3 QSta ...
- 程序员炫技:探索高级编程之美
程序员常常被视为具有超强技术能力的人才,他们的代码充满了令普通人惊叹的炫技操作.在这篇文章中,我们将一起探讨程序员的炫技代码写法,分享一些高级编程技巧,同时提供一些学习建议,让你也能成为编程高手. 一 ...
- c# socket接收字符串_Python高级编程之 Socket 编程
目录 1. Socket 编程简介2. 基于 Socket 的简单聊天程序2.1 服务器端2.2 客户端3. 使用 Socket 模拟 Http 请求 1. Socket 编程简介 注意,Socket ...
- python flask restful入门_Python Flask高级编程之RESTFul API前后端分离精讲
第1章 随便聊聊 聊聊Flask与Django,聊聊代码的创造性1-1 Flask VS Django 1-2 课程更新维护说明 第2章 起步与红图 本章我们初始化项目,探讨与研究Flask的默认层级 ...
- Spring5参考指南:AspectJ高级编程之Configurable
文章目录 遇到的问题 @Configurable 原理 重要配置 遇到的问题 前面的文章我们讲到了在Spring中使用Aspect.但是Aspect的都是Spring管理的Bean. 现在有一个问题, ...
- IOS高级编程之二:IOS的数据存储与IO
一.应用程序沙盒 IOS应用程序职能在系统为该应用所分配的文件区域下读写文件,这个文件区域就是应用程序沙盒.所有的非代码文件如:图片.声音.映象等等都存放在此. 在mac中command+shift+ ...
最新文章
- python3 matlabplot 和numpy 简单绘图
- java native方法体在哪_java中native方法的使用
- 全面解析并实现逻辑回归(Python)
- python调用函数示例_python 动态调用函数实例解析
- Centos7作为VNCserver,本地使用VNCViewer连接
- Linux dmidecode备忘
- 这个阿里程序员,干了件很轴的事儿
- 触漫机器人_触触+机器人=???
- RedHat7 Git 安装使用
- 学习戴铭博文《从 ReactiveCocoa 中能学到什么?不用此库也能学以致用》的总结...
- hive on tez集成完整采坑指南(含tez-ui及安全环境)
- 连接远程hbase长时间等待问题
- MINIST手写数字数据集–神经网络(mini-batch)
- 计数器—verilog
- Android 应用FPS测试方法介绍
- android 同屏 软件,同屏助手安卓版
- python 数据挖掘_Python数据挖掘框架scikit数据集之iris
- 关于微信小程序常见的运算符
- access百度翻译 get_PowerShell调用百度翻译API
- python语言主要用途有哪些?这五个一定要知道!
热门文章
- fsck-磁盘修复工具
- rtmp支持h265推流
- 信息学奥赛一本通:1168:大整数加法
- 轮回dj 佛教音乐_童音watmp3.com
- oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
- 向sdcard中添加文件为什么总是提示Failed to push the item(s)Failed to push XXXXX.txt on emulato...
- ST-GCN/AS-GCN报错cannot import name “import_class“
- csr8510对应win10即插即用驱动
- linux如何添加360网站卫士ip,使用加速乐、360网站卫士PHP无法获取用户IP的解决方法...
- NVIDIA显卡,显卡驱动和CUDA版本之间的关系