论文笔记系列-Efficient Neural Architecture Search via Parameter Sharing
Summary
本文提出超越神经架构搜索(NAS)的高效神经架构搜索(ENAS),这是一种经济的自动化模型设计方法,通过强制所有子模型共享权重从而提升了NAS的效率,克服了NAS算力成本巨大且耗时的缺陷,GPU运算时间缩短了1000倍以上。在Penn Treebank数据集上,ENAS实现了55.8的测试困惑度;在CIFAR-10数据集上,其测试误差达到了2.89%,与NASNet不相上下(2.65%的测试误差)
Research Objective 作者的研究目标
设计一种快速有效且耗费资源低的用于自动化网络模型设计的方法。主要贡献是基于NAS方法提升计算效率,使得各个子网络模型共享权重,从而避免低效率的从头训练。
Problem Statement 问题陈述,要解决什么问题?
本文提出的方法是对NAS的改进。NAS存在的问题是它的计算瓶颈,因为NAS是每次将一个子网络训练到收敛,之后得到相应的reward,再将这个reward反馈给RNN controller。但是在下一轮训练子网络时,是从头开始训练,而上一轮的子网络的训练结果并没有利用起来。
另外NAS虽然在每个节点上的operation设计灵活度较高,但是固定了网络的拓扑结构为二叉树。所以ENAS对于网络拓扑结构的设计做了改进,有了更高的灵活性。
Method(s) 解决问题的方法/算法
ENAS算法核心
回顾NAS,可以知道其本质是在一个大的搜索图中找到合适的子图作为模型,也可以理解为使用单个有向无环图(single directed acyclic graph, DAG)来表示NAS的搜索空间。
基于此,ENAS的DAG其实就是NAS搜索空间中所有可能的子模型的叠加。
下图给出了一个通用的DAG示例
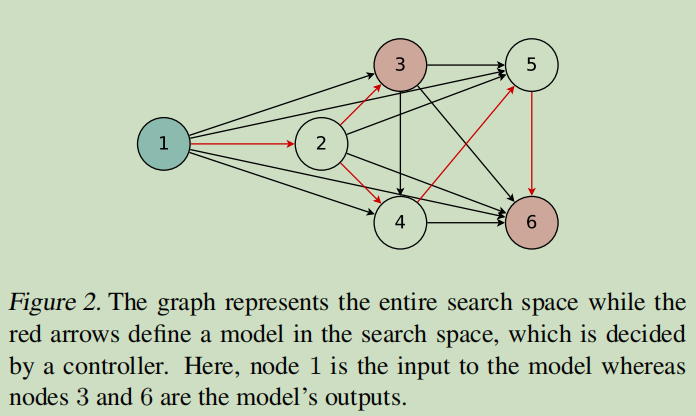
如图示,各个节点表示本地运算,边表示信息的流动方向。图中的6个节点包含有多种单向DAG,而红色线标出的DAG则是所选择的的子图。
以该子图为例,节点1表示输入,而节点3和节点6因为是端节点,所以作为输出,一般是将而二者合并求均值后输出。
在讨论ENAS的搜索空间之前,需要介绍的是ENAS的测试数据集分别是CIFAR-10和Penn Treebank,前者需要通过ENAS生成CNN网络,后者则需要生成RNN网络。
所以下面会从生成RNN和生成CNN两个方面来介绍ENAS算法。
1.Design Recurrent Cells
本小节介绍如何从特定的DAG和controller中设计一个递归神经网络的cell(Section 2.1)?
首先假设共有\(N\)个节点,ENAS的controller其实就是一个RNN结构,它用于决定
- 哪条边需要激活
- DAG中每个节点需要执行什么样的计算
下图以\(N=4\)为例子展示了如何生成RNN。
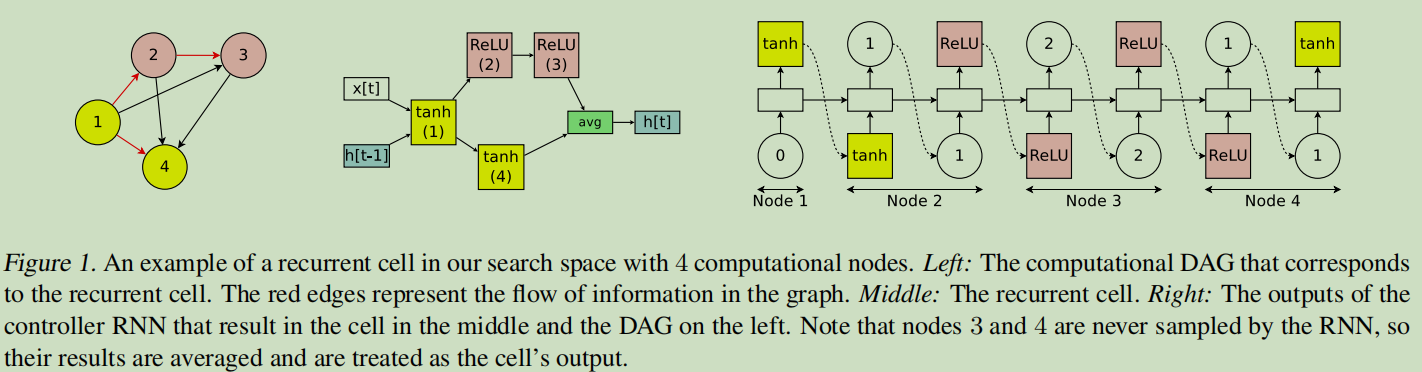
假设\(x[t]\)为输入,\(h[t-1]\)表示上一个时刻的输出状态。
- 节点1:由图可知,controller在节点1上选择的操作是tanh运算,所以有\(h_1=tanh(X_t·W^{(X)}+h_{t-1}·W_1^{(h)})\)
- 节点2:同理有\(h_2 = ReLU(h_1·W_{2,1}^{(h)})\)
- 节点3:\(h_3 = ReLU(h_2·W_{3,2}^{(h)})\)
- 节点4:\(h_4 = ReLU(h_1·W_{4,1}^{(h)})\)
- 节点3和节点4因为不是其他节点的输入,所以二者的平均值作为输出,即\(h_t=\frac{h_3+h_4}{2}\)
由上面的例子可以看到对于每一组节点\((node_i,node_j),i<j\),都会有对应的权重矩阵\(W_{j,i}^{(h)}\)。因此在ENAS中,所有的recurrent cells其实是在搜索空间中共享这样一组权重的。
但是我们可以很容易知道ENAS的搜索空间是非常庞大的,例如假设共有4中激活参数(tanh,identity,sigmoid,ReLU)可以选择,节点数为N,那么搜索空间大小则为\(4^N * N!\),如果N=12,那么就将近有\(10^{15}\)种模型参数。
2.1 Design Convolutional Networks
本小节解释如何设计卷积结构的搜索空间
回顾上面的Recurrent Cell的设计,我们知道controller RNN在每一个节点会做如下两个决定:a)该节点需要连接前面哪一个节点 b)使用何种激活函数。
而在卷积模型的搜索空间中,controller RNN也会做如下两个觉得:a)该节点需要连接前面哪一个节点 b)使用何种计算操作。
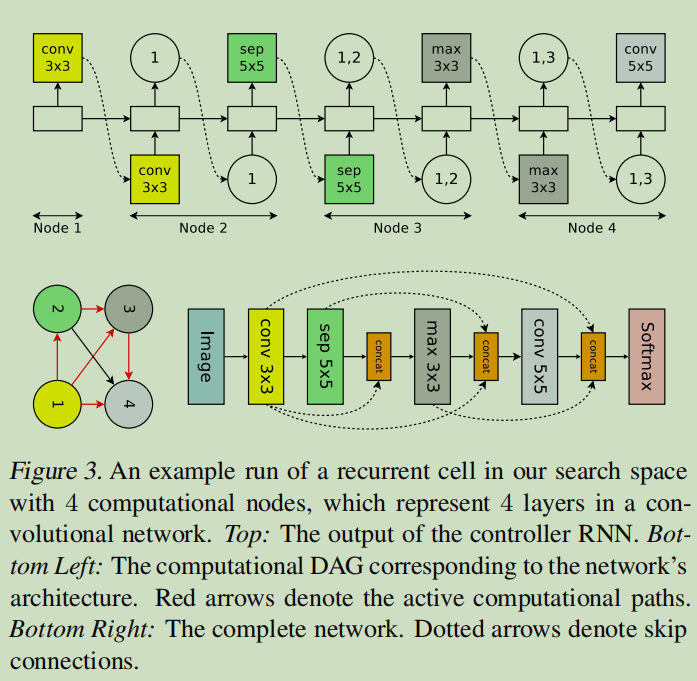
在卷积模型中,(a)决定 (连接哪一个节点) 其实就是skip connections。(b)决定一共有6种选择,分别是3*3和5*5大小的卷积核、3*3和5*5大小的深度可分离卷积核,3*3大小的最大池化和平均池化。
下图展示了卷积网络的生成示意图。
2.2 Design Convolutional Cell
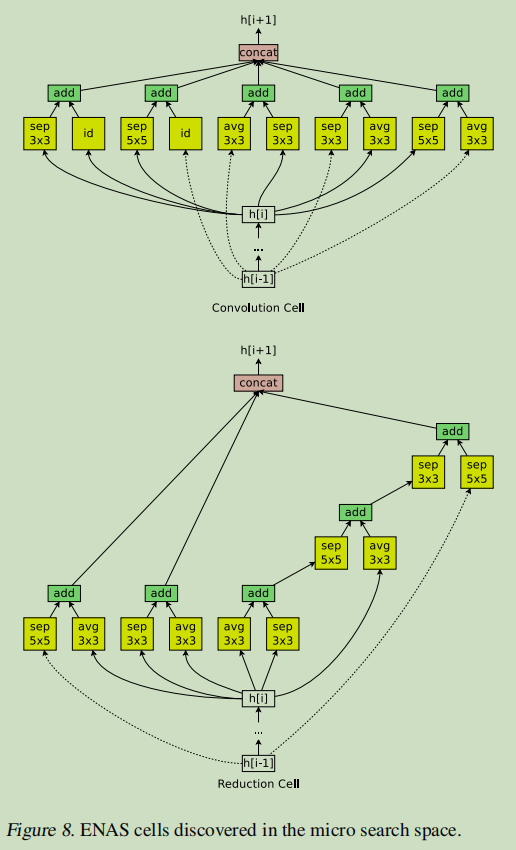
本文并没有采用直接设计完整的卷积网络的方法,而是先设计小型的模块然后将模块连接以构建完整的网络(Zoph et al., 2018)。
下图展示了这种设计的例子,其中设计了卷积单元和 reduction cell。
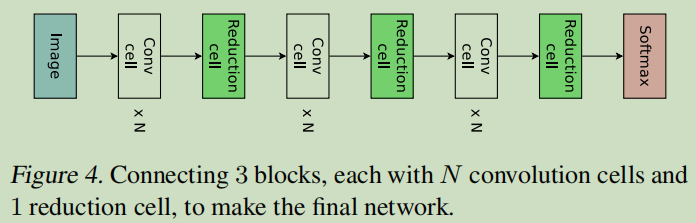
接下来将讨论如何利用 ENAS 搜索由这些单元组成的架构。
假设下图的DAG共有\(B\)个节点,其中节点1和节点2是输入,所以controller只需要对剩下的\(B-2\)个节点都要做如下两个决定:a)当前节点需要与那两个节点相连 b)所选择的两个节点需要采用什么样的操作。(可选择的操作有5种:identity(id,相等),大小为3*3或者5*5的separate conv(sep),大小为3*3的最大池化。)
可以看到对于节点3而言,controller采样的需要连接的两个节点都是节点2,两个节点预测的操作分别是sep 5*5和identity。
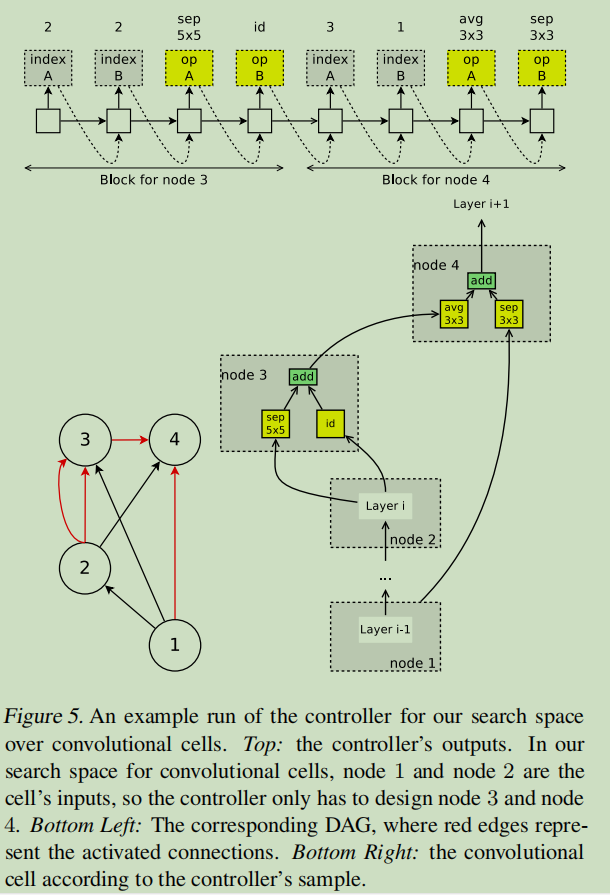
3.Training ENAS and Deriving Architectures
本小节介绍如何训练ENAS以及如何从ENAS的controller中生成框架结构。(Section 2.2)
controller网络是含有100个隐藏节点的LSTM。LSTM通过softmax分类器做出选择。另外在第一步时controller会接收一个空的embedding作为输入。
在ENAS中共有两组可学习的参数:
- 子网络模型的共享参数,用\(w\)表示。
- controller网络(即LSTM网络参数),用\(θ\)表示。
而训练ENAS的步骤主要包含两个交叉阶段:第一部训练子网络的共享参数\(w\);第二个阶段是训练controller的参数\(θ\)。这两个阶段在ENAS的训练过程中交替进行,具体介绍如下:
子网络模型共享参数\(w\)的训练
在这个步骤中,首先固定controller的policy network,即\(π(m;θ)\)。之后对\(w\)使用SGD算法来最小化期望损失函数\(E_{m~π}[L(m;w)]\)。
其中\(L(m;w)\)是标准的交叉熵损失函数:\(m\)表示根据policy network \(π(m;θ)\)生成的模型,然后用这个模型在一组训练数据集上计算得到的损失值。
根据Monte Carlo估计计算梯度公式如下:
\[\nabla_w E_{m-~π}(m;θ)[L(m;w)] ≈ \frac{1}{M} \sum_i^M \nabla_wL(m_i;w) \]
其中上式中的\(m_i\)表示由\(π(m;θ)\)生成的M个模型中的某一个模型。
虽然上式给出了梯度的无偏估计,但是方差比使用SGD得到的梯度的方差大。但是当\(M=1\)时,上式效果还可以。
训练controller参数θ
在这个步骤中,首先固定\(w\),之后通过求解最大化期望奖励\(E_{m~π}[R(m;w)]\)来更新\(θ\)。其中在语言模型实验中\(R(m;w)=\frac{c}{valid\_ppl}\),perplexity是基于小批量验证集计算得到的;在分类模型试验中,\(R(m;w)\)等于基于小批量验证集的准确率。
导出模型架构
首先使用\(π(m,θ)\)生成若干模型。
之后对于每一个采样得到的模型,直接计算其在验证集上得到的奖励。
最后选择奖励最高的模型再次从头训练。
当然如果像NAS那样把所有采样得到的子模型都先从头训练一边,也许会对实验结果有所提升。但是ENAS之所以Efficient,就是因为它不用这么做,原理继续看下文。
Evaluation 评估方法
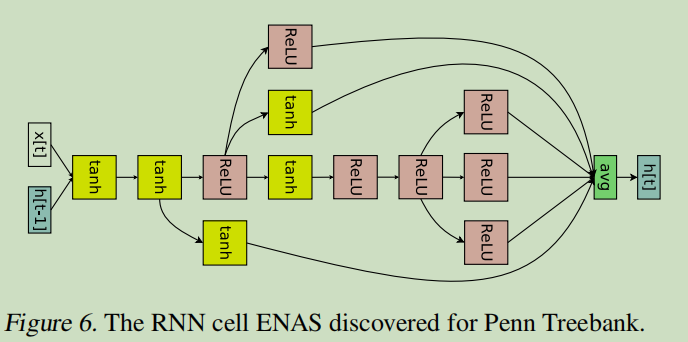
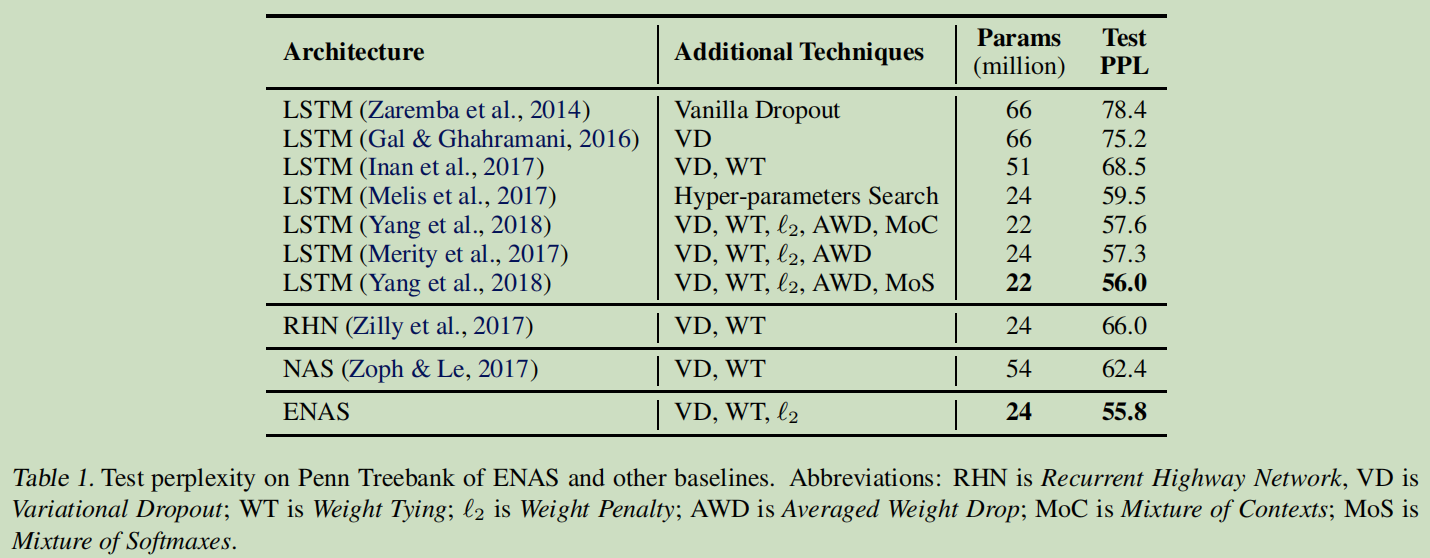
1.在 Penn Treebank 数据集上训练的语言模型
2.在 CIFAR-10 数据集上的图像分类实验
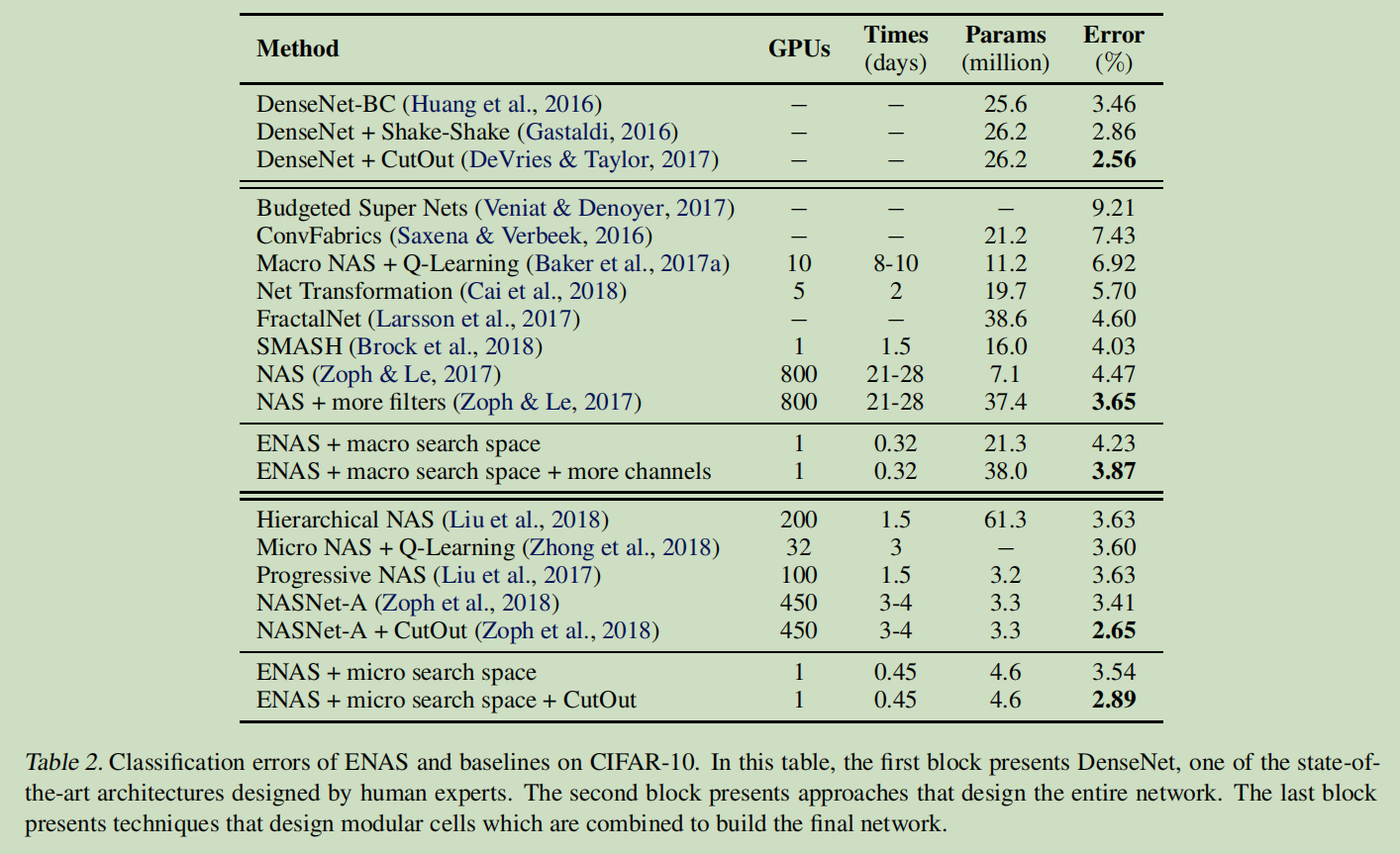
由上表可以看出,ENAS的最终结果不如NAS,这是因为ENAS没有像NAS那样从训练后的controller中采样多个模型架构,然后从中选出在验证集上表现最好的一个。但是即便效果不如NAS,但是ENAS效果并不差太多,而且训练效率大幅提升。
下图是生成的宏观搜索空间。

ENAS 用了 11.5 个小时来发现合适的卷积单元和 reduction 单元,如下图所示。
Conclusion
ENAS能在Penn Treebank和CIFAR-10两个数据集上得到和NAS差不多的效果,而且训练时间大幅缩短,效率大大提升。
MARSGGBO原创
2018-8-7
论文笔记系列-Efficient Neural Architecture Search via Parameter Sharing相关推荐
- ENAS:通过参数共享实现高效的神经架构搜索《EfficientNet Neural Architecture Search via Parameter Sharing》
本文总结多篇相关博客:https://www.sohu.com/a/222705024_129720.https://zhuanlan.zhihu.com/p/60592822.https://blo ...
- 【读点论文】FBNetV2:Differentiable Neural Architecture Search for Spatial and Channel D扩大搜索空间,复用featuremap
FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions Abstract 可微分神经 ...
- AutoML论文笔记(九)CARS Continuous Evolution for Efficient Neural Architecture Search:连续进化神经网络搜索
文章题目:CARS: Continuous Evolution for Efficient Neural Architecture Search 链接:link https://arxiv.org/a ...
- 【读点论文】MnasNet: Platform-Aware Neural Architecture Search for Mobile,用神经网络搜索的方式来设计网络平衡精度与速度
MnasNet: Platform-Aware Neural Architecture Search for Mobile Abstract 为移动设备设计卷积神经网络(CNN)模型具有挑战性,因为移 ...
- AutoST: Efficient Neural Architecture Search for Spatio-Temporal Prediction
摘要:时空(ST)预测(如人群流动预测)在城市规划.智能交通和公共安全等智能城市的广泛应用中具有重要意义.近年来,人们提出了许多深度神经网络模型来进行准确的预测.然而,人工设计神经网络需要大量的专家努 ...
- 【读点论文】FBNet:Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search可微分
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search Abstrac ...
- 神经网络架构搜索(Neural Architecture Search, NAS)笔记
目录 (一)背景 (二)NAS流程 2.1 定义搜索空间 2.2 搜索策略 (三)加速 (四)变体及扩展 4.1 扩展到其他任务 4.2 扩展到其他超参数 (一)背景 机器学习从业者被戏称为" ...
- 神经网络架构搜索(Neural Architecture Search)杂谈
一.背景 机器学习从业者被戏称为"调参工"已经不是一天两天了.我们知道,机器学习算法的效果好坏不仅取决于参数,而且很大程度上取决于各种超参数.有些paper的结果很难重现原因之一就 ...
- Neural Architecture Search: A survey
文章目录 1. Introduction 2. Search Space 2.1搜索空间定义: 2.2 常见的搜索空间举例: 2.2.1 简单链式搜索空间: 2.2.2 复杂多分支搜索空间 2.2.3 ...
最新文章
- 计算机教室网络安全应急预案,北京科技大学计算机与通信工程学院-计算机与通信工程学院实验室安全应急预案...
- win7构建成功helloworld驱动、WDF驱动中KMDF与UMDF区别
- Nginx通过域名配置虚拟机
- 即插即用的轻量注意力机制ECA--Net
- javascript事件之:jQuery事件中实例对象和拓展对象之间的通信
- day19_java基础加强_动态代理+注解+类加载器
- 我眼中的分布式系统可观测性
- Java中字符串的全部知识_java基础教程之字符串的介绍,比较重要的一个知识点「中」...
- C语言数组和指针的区别
- Python制作翻译软件(中英文互译)
- 社区网格员计算机考试考什么,网格员考试内容是什么,网格员考试科目有哪些...
- DBSCAN聚类算法详解
- 2018.8.2课堂笔记
- Chrome浏览器控制网速
- eclipse设置pom.xml打开方式,显示dependences视图
- k8s学习-持久化存储(Volumes、hostPath、emptyDir、PV、PVC)详解与实战
- Android:ViewPager详细解释(异步网络负载图片,有图片缓存,)并与导航点
- 百度编辑器抓取微信图片并替换内容
- 纯CSS3实现常见的时间进度线(竖立方向)
- 用CSS定义每段首行缩进2个字符