Rocketmq原理最佳实践

一、 MQ背景&选型
消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性。
目前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相比于Rabbitmq、kafka
具有主要优势特性有:
支持事务型消息(消息发送和DB操作保持两方的最终一致性,rabbitmq和kafka不支持)
支持结合rocketmq的多个系统之间数据最终一致性(多方事务,二方事务是前提)
支持18个级别的延迟消息(rabbitmq和kafka不支持)
支持指定次数和时间间隔的失败消息重发(kafka不支持,rabbitmq需要手动确认)
支持consumer端tag过滤,减少不必要的网络传输(rabbitmq和kafka不支持)
支持重复消费(rabbitmq不支持,kafka支持)二、RocketMQ集群概述
1. RocketMQ集群部署结构
1) Name Server
Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。
2) Broker
Broker部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave
只能对应一个Master,Master与Slave的对应关系通过指定相同的Broker Name,不同的Broker Id
来定义,BrokerId为0表示Master,非0表示Slave。Master也可以部署多个。每个Broker与Name Server集群中的所有节点建立长连接,定时(每隔30s)注册Topic信息到所有
Name Server。Name Server定时(每隔10s)扫描所有存活broker的连接,如果Name Server超过2分钟
没有收到心跳,则Name Server断开与Broker的连接。3) Producer
Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由
信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群
部署。
Producer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送
心跳,Broker每隔10s中扫描所有存活的连接,如果Broker在2分钟内没有收到心跳数据,则关闭与Producer
的连接。4) Consumer
Consumer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由
信息,并向提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer
既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
Consumer每隔30s从Name server获取topic的最新队列情况,这意味着Broker不可用时,Consumer最多
需要30s才能感知。
Consumer每隔30s(由ClientConfig中heartbeatBrokerInterval决定)向所有关联的broker发送
心跳,Broker每隔10s扫描所有存活的连接,若某个连接2分钟内没有发送心跳数据,则关闭连接;
并向该Consumer Group的所有Consumer发出通知,Group内的Consumer重新分配队列,然后继续消费。
当Consumer得到master宕机通知后,转向slave消费,slave不能保证master的消息100%都同步过来了,
因此会有少量的消息丢失。但是一旦master恢复,未同步过去的消息会被最终消费掉。三、 Rocketmq如何支持分布式事务消息
场景
A(存在DB操作)、B(存在DB操作)两方需要保证分布式事务一致性,通过引入中间层MQ,A和MQ保持
事务一致性(异常情况下通过MQ反查A接口实现check),B和MQ保证事务一致(通过重试),从而达到
最终事务一致性。
1. MQ与DB一致性原理(两方事务)
MQ消息、DB操作一致性方案:
1)发送消息到MQ服务器,此时消息状态为SEND_OK。此消息为consumer不可见。
2)执行DB操作;DB执行成功Commit DB操作,DB执行失败Rollback DB操作。
3)如果DB执行成功,回复MQ服务器,将状态为COMMIT_MESSAGE;如果DB执行失败,回复MQ服务器,
将状态改为ROLLBACK_MESSAGE。注意此过程有可能失败。
4)MQ内部提供一个名为“事务状态服务”的服务,此服务会检查事务消息的状态,如果发现消息未COMMIT,
则通过Producer启动时注册的TransactionCheckListener来回调业务系统,业务系统
在checkLocalTransactionState方法中检查DB事务状态,如果成功,则回复COMMIT_MESSAGE,
否则回复ROLLBACK_MESSAGE。
以上SEND_OK、COMMIT_MESSAGE、ROLLBACK_MESSAGE均是client jar提供的状态,在MQ服务器内部
是一个数字。
TransactionCheckListener 是在消息的commit或者rollback消息丢失的情况下才会回调。这种消息
丢失只存在于断网或者rocketmq集群挂了的情况下。当rocketmq集群挂了,如果采用异步刷盘,存在1s内
数据丢失风险,异步刷盘场景下保障事务没有意义。所以如果要核心业务用Rocketmq解决分布式事务问题,
建议选择同步刷盘模式。2. 多系统之间数据一致性(多方事务)
当需要保证多方(超过2方)的分布式一致性,上面的两方事务一致性(通过Rocketmq的事务性消息解决)
已经无法支持。这个时候需要引入TCC模式思想(Try-Confirm-Cancel,不清楚的自行百度)。1)交易系统创建订单(往DB插入一条记录),同时发送订单创建消息。通过RocketMq事务性消息保证一致性
2)接着执行完成订单所需的同步核心RPC服务(非核心的系统通过监听MQ消息自行处理,处理结果不会影响
交易状态)。执行成功更改订单状态,同时发送MQ消息。3.案例分析
1) 单机环境下的事务示意图
如下为A给B转账的例子。
步骤 动作
1 锁定A的账户
2 锁定B的账户
3 检查A账户是否有1元
4 A的账户扣减1元
5 给B的账户加1元
6 解锁B的账户
7 解锁A的账户
以上过程在代码层面甚至可以简化到在一个事物中执行两条sql语句。2) 分布式环境下事务
和单机事务不同,A、B账户可能不在同一个DB中,此时无法像在单机情况下使用事物来实现。此时可以
通过一下方式实现,将转账操作分成两个操作。a) A账户
步骤 动作
1 锁定A的账户
2 检查A账户是否有1元
3 A的账户扣减1元
4 解锁A的账户b) MQ消息
A账户数据发生变化时,发送MQ消息,MQ服务器将消息推送给转账系统,转账系统来给B账号加钱。c) B账户
步骤 动作
1 锁定B的账户
2 给B的账户加1元
3 解锁B的账户四、 顺序消息
1. 顺序消息缺陷
发送顺序消息无法利用集群Fail Over特性消费顺序消息的并行度依赖于队列数量队列热点问题,个别队列
由于哈希不均导致消息过多,消费速度跟不上,产生消息堆积问题遇到消息失败的消息,无法跳过,当前
队列消费暂停。2. 原理
produce在发送消息的时候,把消息发到同一个队列(queue)中,消费者注册消息监听器
为MessageListenerOrderly,这样就可以保证消费端只有一个线程去消费消息。注意:把消息发到同一个队列(queue),不是同一个topic,默认情况下一个topic包括4个queue五、 最佳实践
1. Producer
1) Topic
一个应用尽可能用一个Topic,消息子类型用tags来标识,tags可以由应用自由设置。只有发送消息
设置了tags,消费方在订阅消息时,才可以利用tags 在broker做消息过滤。2) key
每个消息在业务层面的唯一标识码,要设置到 keys 字段,方便将来定位消息丢失问题。
//订单Id
String orderId= "20034568923546";
message.setKeys(orderId);3) 日志
消息发送成功或者失败,要打印消息日志,务必要打印 send result 和key 字段。4) send
send消息方法,只要不抛异常,就代表发送成功。但是发送成功会有多个状态,在sendResult里定义。
SEND_OK:消息发送成功
FLUSH_DISK_TIMEOUT:消息发送成功,但是服务器刷盘超时,消息已经进入服务器队列,只有此时服务器
宕机,消息才会丢失
FLUSH_SLAVE_TIMEOUT:消息发送成功,但是服务器同步到Slave时超时,消息已经进入服务器队列,
只有此时服务器宕机,消息才会丢失
SLAVE_NOT_AVAILABLE:消息发送成功,但是此时slave不可用,消息已经进入服务器队列,只有此时
服务器宕机,消息才会丢失2. Consumer
1) 幂等
RocketMQ使用的消息原语是At Least Once,所以consumer可能多次收到同一个消息,此时务必做好幂等。2) 日志
消费时记录日志,以便后续定位问题。3) 批量消费
尽量使用批量方式消费方式,可以很大程度上提高消费吞吐量。
分布式消息中间件-Rocketmq
简述
消息中间件主要是实现分布式系统中解耦、异步消息、流量销锋、日志处理等场景,现在生产中用的
最多的消息队列有Activemq,rabbitmq,kafka,rocketmq等。分享的版本也是基于3.2.6进行的。JMS规范
rocketmq虽然不完全基于jms规范,但是他参考了jms规范和 CORBA Notification 规范等,可以说是
青出于蓝而胜于蓝什么是jms呢jms其实就是类似于jdbc的一套接口规范,但不同的是他是面向的消息服务,提供一套标准API接口,
大部分厂商都会参考jms规范,不过我们后面要讲到的rocketmq却没有严格遵守jms规范,后面我们会讲到。一些常见的jms厂商有:APACHE开源的ActiveMQ。这里面Activemq这个也是我接触到的第一个mq,现在
市场份额也是很大的,京东商城采用的就是这个。基本概念
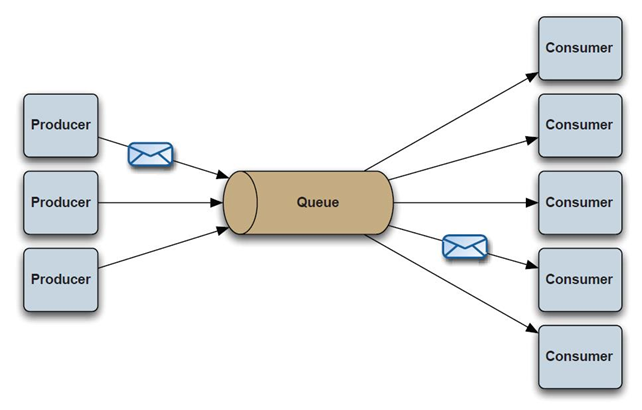
发送者( Sender)也就是消息的生产者,就是创建并发送消息的JMS客户端接收者( Receiver)也就是消息消费者,接收订制消息的并按照相应的业务逻辑进行处理,最终将结果反馈给mq的服务端。点对点( Point-to-Point(P2P) )点对点就是一对一的关系,一个消息发出只有一个接受者所处理。每个消息都被发送到一个特定的队列,
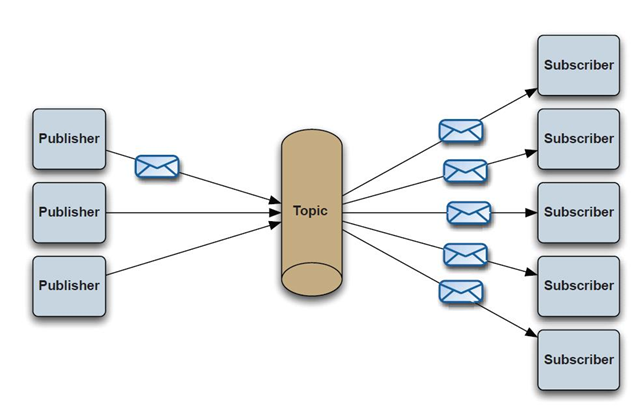
接收者从队列中获取消息。队列保留着消息,直到他们被消费或超时。发布订阅( Publish/Subscribe(Pub/Sub) )1、客户端将消息发送到主题。多个发布者将消息发送到Topic,系统将这些消息传递给多个订阅者。2、如果你希望发送的消息可以不被做任何处理、或者被一个消息者处理、或者可以被多个消费者
处理的话,那么可以采用Pub/Sub模型消息队列(Queue)
与队列名字所暗示的意思不同,消息的接受顺序并不一定要与消息的发送顺序相同。一旦一个消息被阅读,
该消息将被从队列中移走。主题(Topic)
一种支持发送消息给多个订阅者的机制。发布者(Publisher)
同生产者订阅者(Subscriber)针对同一主题的多个消费者点对点
发布订阅
对象模型
(1) ConnectionFactory创建Connection对象的工厂,针对两种不同的jms消息模型,分别有QueueConnectionFactory
和TopicConnectionFactory两种(很显然是基于点对点和和发布订阅的两种方式分别创建连接工厂的)。
可以通过JNDI来查找ConnectionFactory对象。(2) Destination
Destination的意思是消息生产者的消息发送目标或者说消息消费者的消息来源。对于消息生产者来说,
它的Destination是某个队列(Queue)或某个主题(Topic);对于消息消费者来说,它的Destination
也是某个队列或主题(即消息来源)。所以,Destination实际上就是两种类型的对象:Queue、Topic
可以通过JNDI来查找Destination。(3) Connection
Connection表示在客户端和JMS系统之间建立的链接(对TCP/IP socket的包装)。Connection可以产生
一个或多个Session。跟ConnectionFactory一样,Connection也有两种类型:QueueConnection和TopicConnection。(4) SessionSession是我们操作消息的接口。可以通过session创建生产者、消费者、消息等。Session提供了事务
的功能。当我们需要使用session发送/接收多个消息时,可以将这些发送/接收动作放到一个事务中。同样,
也分QueueSession和TopicSession。(5) 消息的生产者消息生产者由Session创建,并用于将消息发送到Destination。同样,消息生产者分两种类型:
QueueSender和TopicPublisher。可以调用消息生产者的方法(send或publish方法)发送消息。(6) 消息消费者
消息消费者由Session创建,用于接收被发送到Destination的消息。两种类型:QueueReceiver
和TopicSubscriber。可分别通过session的createReceiver(Queue)或createSubscriber(Topic)来创建。
当然,也可以session的creatDurableSubscriber方法来创建持久化的订阅者。(7) MessageListener消息监听器。如果注册了消息监听器,一旦消息到达,将自动调用监听器的onMessage方法。我们后面
消息消费还会看到。消息消费
在JMS中,消息的产生和消息是异步的。对于消费来说,JMS的消息者可以通过两种方式来消费消息。○ 同步
订阅者或接收者调用receive方法来接收消息,receive方法在能够接收到消息之前(或超时之前)将一直阻塞○ 异步
订阅者或接收者可以注册为一个消息监听器。当消息到达之后,系统自动调用监听器的onMessage方法。这边通过activemq的部分代码来简单说明一下上面说道的一些JMS规范public void init(){try {//创建一个链接工厂(用户名,密码,broker的url地址)connectionFactory = new ActiveMQConnectionFactory(USERNAME,PASSWORD,BROKEN_URL);//从工厂中创建一个链接connection = connectionFactory.createConnection();//开启链接connection.start();//创建一个会话session = connection.createSession(true,Session.SESSION_TRANSACTED);} catch (JMSException e) {e.printStackTrace();}}公共部分:也就是说不管你是消息的生产者还是消息的消费者都需要这些步骤1.首先我们需要创建一个连接工厂,当然这里我们需要输入用户名和密码还有就是broker的url
2.然后我们根据连接工厂创建了一个连接,此刻这个工厂并没有和broker连接
3.调用start方法就和broker建立了连接,这里我大概解释一下broker
4.broker:消息队列核心,相当于一个控制中心,负责路由消息、保存订阅和连接、消息确认
和控制事务,activemq可以配置多个public void sendMsg(String queueName){try {//创建一个消息队列(此处也就是在创建Destination)Queue queue = session.createQueue(queueName);//消息生产者MessageProducer messageProducer = null;if(threadLocal.get()!=null){messageProducer = threadLocal.get();}else{messageProducer = session.createProducer(queue);threadLocal.set(messageProducer);}while(true){Thread.sleep(1000);int num = count.getAndIncrement();//创建一条消息TextMessage msg
= session.createTextMessage(Thread.currentThread().getName()+"productor:生产消息,count:"+num);//发送消息messageProducer.send(msg);//提交事务session.commit();}} catch (JMSException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}生产:配置完上面的公共部分我们就迫不及待的把消息生产出来吧,我这边说的是点对点的方式
1.通过session创建一个Destination,我这边直接就用了queue了
2.接下来我们需要创建一个消息的生产者
3.我这边就循环每1s发送一条消息
4.这边看到我们的消息也是用session来创建的,这里面我们用的是文本的消息类型
5.发送消息
6.提交这次发送,至此我们的消息就发送到了broker上了,用过activemq的同学都知道,
activemq提供了一个很好用的界面可以查到你的消息的状态,包括是否消费等消费:消费我们上面也提到了两种方式,同步和异步,我这边准备了两份代码分别说明了一下public void doMessage(String queueName){try {//创建DestinationQueue queue = session.createQueue(queueName);MessageConsumer consumer = null;while(true){Thread.sleep(1000);TextMessage msg = (TextMessage) consumer.receive();if(msg!=null) {msg.acknowledge();System.out.println(Thread.currentThread().getName()+
": Consumer:我是消费者,我正在消费Msg"+msg.getText()+"--->"+count.getAndIncrement());}else {break;}}} catch (JMSException e) {e.printStackTrace();} catch (InterruptedException e) {e.printStackTrace();}同步:可以看到消息会一直阻塞到有消息才会继续1.通过session创建一个Destination,我这边直接就用了queue了
2.创建了一个Consumer
3.做了一个死循环,类似于ServerSocket的accept方法,我们的receive会阻塞到这里,直到有消息
4.如果消息不为空告知消息消费成功consumer.setMessageListener(MessageListener { public void onMessage(Message msg) { try { String message = ((TextMessage) msg).getText(); if(msg != null){msg.acknowledgeSystem.out.println("成功消费消息:"+message);} } catch (JMSException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
);异步:前两部和上面是一样的,注册了一个监听接口的实现,当有消息时就调用onMessage的实现,
后面就一样了
RocketMQ介绍
简介
rocketmq是阿里巴巴开源的一款分布式的消息中间件,他源于jms规范但是不遵守jms规范。如果你了用过
其他mq并且了解过rocketmq,就知道rocketmq天生就是分布式的,可以说是broker、provider、consumer
等各种分布式。
1.能够保证严格的消息顺序(需要集群的支持)
2.提供丰富的消息拉取模式
3.高效的订阅者水平扩展能力(通过一个consumerGroup的方式做到consumer的方便扩容)
4.实时的消息订阅机制(消息的实时推送,类似于上面咱们的异步消费的方式)
5.亿级消息堆积能力(轻松完成系统销锋)发展历史
一、 Metaq(Metamorphosis) 1.x
由开源社区 killme2008 维护,开源社区非常活跃。
https://github.com/killme2008/Metamorphosis二、 Metaq 2.x
于 2012 年 10 月份上线,在淘宝内部被广泛使用三、改名为RocketMQ
公司内部开源共建的原则,rocketmq只维护了核心功能,可以方面每个SUB(业务单元)定制,当然阿里内部
之所以提供高效的新能出了rocketmq本身之外还依赖于另外一个产品(oceanbase阳振坤)
https://github.com/apache/rocketmq
当前版本为4.2.0-SNAPSHOT选择的理由1.强调集群无单点,可扩展,任意一点高可用,水平可扩展
方便集群配置,而且容易扩展(横向和纵向),通过slave的方式每一点都可以实现高可用2.支持上万个队列,顺序消息顺序消费是实现在同一队列的,如果高并发的情况就需要队列的支持,rocketmq可以满足上万个队列
同时存在3.任性定制你的消息过滤rocketmq提供了两种类型的消息过滤,也可以说三种可以通过topic进行消息过滤、可以通过tag进行
消息过滤、还可以通过filter的方式任意定制过滤4.消息的可靠性(无Buffer,持久化,容错,回溯消费)
rocketmq的所有消息都是持久化的,生产者本身可以进行错误重试,发送者也会按照时间阶梯的方式进行
消息重发,5.海量消息堆积能力,消息堆积后,写入低延迟
对于consumer,如果是集群方式一旦master返现消息堆积会向consumer下发一个重定向指令,
此时consumer就可以从slave进行数据消费了6.消息失败重试机制7.定时消费
出了上面的配置,在发送消息是也可以针对message设置setDelayTimeLevel8.活跃的开源社区
现在rocketmq成为了apache的一款开源产品,活跃度也是不容怀疑的9.成熟度(经过双十一考验)
针对本身的成熟度,我们看看这么多年的双十一就可想而知了专有术语NameServer
这里我们可以理解成类似于zk的一个注册中心,而且rocketmq最初也是基于zk作为注册中心的,现在相当于
为rocketmq自定义了一个注册中心,代码不超过1000行。RocketMQ 有多种配置方式可以令客户端找到
Name Server, 然后通过 Name Server 再找到 Broker,客户端提供http和ip+端口号的两种方式,推荐
使用http的方式可以实现nameserver的热部署Push ConsumerConsumer 的一种,应用通常通过 Consumer 对象注册一个 Listener 接口,一旦收到消息,
Consumer 对象立刻回调 Listener 接口方法,类似于activemq的方式Pull Consumer
Consumer 的一种,应用通常主动调用 Consumer 的拉消息方法从 Broker 拉消息,主动权由应用控制Producer Group
一类producer的集合名称,这类producer通常发送一类消息,且发送逻辑一致Consumer Group同上,consumer的集合名称Broker
消息中转的角色,负责存储消息(实际的存储是调用的store组件完成的),转发消息,一般也成为server,
通jms中的providerMessage Filter
可以实现高级的自定义的消息过滤,java编写Master/Slave
集群的主从关系,broker的name相同,brokerid=0的为主,大于0的为从部署方式NameServer :类似云zk的集群,主要是维护了broker的相关内容,进行存取;节点之间无任何数据同步
1、接收broker的注册
2、Producer获取topic下所有的BrokerQueue,put消息
3、Consumer获取topic下所有的BrokerQueue,get消息Broker :
部署相对复杂,Broker分为Master与Slave,一个Master可以对应多个Slave,但是一个Slave只能
对应Master,Master和Slave的对应关系通过制定相同的BrokerName来确定,通过制定BrokerId来区分
主从,如果是0则为Master,如果大于0则为Slave。Master也可以部署多个。每个Broker与Name Server
集群中的所有节点建立长连接,定时注册Topic信息到所有的NameServerProducer:
与Name sever集群中的其中一个节点(随意选择)建立长连接,定期的从Name Server取Topic路由信息,
并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可以集群部署。Consumer:
与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息,并向
提供Topic的Master、Slave简历长连接,且定时向Master、Slave发送心跳,Consumer既可以从Master
订阅消息,也可以从Slave订阅消息,订阅规则有Broker配置决定。逻辑部署Producer Group:用来表示一个发送消息应用,一个Producer Group下办好多个Producer实例,可是多台机器,也可以是
一台机器的多个线程,或者一个进程的多个Producer对象,一个Producer Group可以发送多个Topic
消息,Producer Group的作用如下:
1、标识一类Producer(分布式)
2、可以通过运维工具查询这个发送消息应用有多少个Producer
3、发送分布式事务消息时,如果Producer中途意外当即,Broker会主动回调Producer Group内的
任意一台机器来确认事务状态。
Consumer Group:
用来表示一个消费消息应用,一个Consumer Group下包含多个Consumer实例,可以是多台机器,也可以是
多个进程,或者是一个进程的多个Consumer对象。一个Consumer Group下的多个Consumer以均摊方式
消费消息。如果设置为广播方式,那么这个Consumer Group下的每个实例都消费全量数据。单Master模式
只有一个 Master节点
优点:配置简单,方便部署
缺点:这种方式风险较大,一旦Broker重启或者宕机时,会导致整个服务不可用,不建议线上环境使用多Master模式
一个集群无 Slave,全是 Master,例如 2 个 Master 或者 3 个 Master
优点:配置简单,单个Master 宕机或重启维护对应用无影响,在磁盘配置为RAID10 时,即使机器宕机
不可恢复情况下,由与 RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消息,同步刷盘一条
不丢)。性能最高。多 Master 多 Slave 模式,异步复制缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到
受到影响多Master多Slave模式(异步复制)每个 Master 配置一个 Slave,有多对Master-Slave, HA,采用异步复制方式,主备有短暂消息延迟,
毫秒级。
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master 宕机后,消费者仍然可以
从 Slave消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样。
缺点: Master 宕机,磁盘损坏情况,会丢失少量消息。多Master多Slave模式(同步双写)每个 Master 配置一个 Slave,有多对Master-Slave, HA采用同步双写方式,主备都写成功,
向应用返回成功。
优点:数据与服务都无单点, Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高
缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT会略高。目前主宕机后,备机不能
自动切换为主机,后续会支持自动切换功能特性使用
Quick start
Producer:/*** Producer,发送消息* */
public class Producer {public static void main(String[] args) throws MQClientException, InterruptedException {DefaultMQProducer producer = new DefaultMQProducer("pay_topic_01");producer.setNamesrvAddr("100.8.8.88:9876");producer.start();for (int i = 0; i < 1000; i++) {try {Message msg = new Message("TopicTest",// topic"TagA",// tag("Hello RocketMQ " + i).getBytes()// body);SendResult sendResult = producer.send(msg);System.out.println(sendResult);}catch (Exception e) {e.printStackTrace();Thread.sleep(1000);}}producer.shutdown();}1、创建一个Producer的,这里我们看到rocketmq的创建producer很简单只输入一个Group Name名字就
可以,不向activemq那么复杂
2、第二步就是制定Name Server的地址,这里注意两点,一个就是nameserver的默认端口是9876,另一个
就是多个nameserver集群用分号来分割
3、我这边循环发送了1000个消息
4、消息创建也很简单,第一个参数是topic,第二个就是tags(多个tag用||连接),第三个参数是消息内容
5、调用send方法就能发送成功了,不用想actimemq那样需要commitConsumer:/*** Consumer,订阅消息*/
public class Consumer {public static void main(String[] args) throws InterruptedException, MQClientException {DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");consumer.setNamesrvAddr("100.8.8.88:9876");/*** 设置Consumer第一次启动是从队列头部开始消费还是队列尾部开始消费<br>* 如果非第一次启动,那么按照上次消费的位置继续消费*/consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);consumer.subscribe("TopicTest", "*");consumer.registerMessageListener(new MessageListenerConcurrently() {@Overridepublic ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;}});consumer.start();System.out.println("Consumer Started.");}1、前两步和Producer是一样的
2、这里可以设置从那个位置开始读取消息,一般我们会从头部开始读取消费,系统中注意去重,也就是幂等
3、订阅topic,第一个参数是topic名字,第二个是tag,如果为*的就是全部消息
4、注册一个监听,如果有消息就会实时的推送到Consumer,调用consumeMessage进行消费,这里我们
看到msgs是一个List,默认每次推送的是一条消息。
5、进行消息的消费逻辑,消费成功后会返回CONSUME_SUCCESS状态消息过滤
RocketMq的消息过滤是从订阅的时候开始的,我们看到刚才的例子都是通过topic的tags进行的过滤,这个
要求Producer发送的事后指定tags,Consumer在订阅消费的时候指定的tags才会对消息进行过滤,这种是
简单的过滤方式,不过也可以满足我们大部分的消息过滤。顺序消息
因为一些消息可以需要按照顺序消费才有意义,比如某例子现在是异步去执行的当然现在是采用的定时的
方式,比如我们把现在的模式套上来,看看顺序消费是一个什么样子。订单创建》分批》打包》外发。。。
。,rocketmq实现的方式也很简单,只要我们把这些消息都放到一个队列中就能够做到顺序消费了,实际
上rocketmq的顺序消费有两种方式,一种是普通的顺序消费(多Master多Slave的异步复制),一种是严格
的顺序消费(多Master多Slave的同步双写)。/*** Producer,发送顺序消息*/
public class Producer {public static void main(String[] args) {try {MQProducer producer =
new DefaultMQProducer("please_rename_unique_group_name");producer.setNamesrvAddr("100.8.8.88:9876");producer.start();String[] tags = new String[] { "TagA", "TagB", "TagC", "TagD", "TagE" };for (int i = 0; i < 100; i++) {// 订单ID相同的消息要有序int orderId = i % 10;Message msg = new Message("TopicTestjjj", tags[i % tags.length],
"KEY" + i,("Hello RocketMQ " + i).getBytes());SendResult sendResult = producer.send(msg, new MessageQueueSelector() {@Overridepublic MessageQueue select(List<MessageQueue> mqs, Message
msg, Object arg) {Integer id = (Integer) arg;int index = id % mqs.size();return mqs.get(index);}}, orderId);System.out.println(sendResult);}producer.shutdown();}catch (MQClientException e) {e.printStackTrace();}catch (RemotingException e) {e.printStackTrace();}catch (MQBrokerException e) {e.printStackTrace();}catch (InterruptedException e) {e.printStackTrace();}}1、首先要保障消息要同时在一个topic中
2、要保障要发送的消息有相同的tag
3、在发送时要保障将数据发送到同一个队列(queue),我们这里采用的取模的方式
rocketmq可以同时支持上完个队列,这个也是为了顺序消费来考虑的事务消息
比如有两个账户张三、李四,张三要给李四转10块钱,以下都在同一个事务中进行,锁定是通过事务中完成的1、锁定张三和李四的账户
2、判断张三的账户是否大于等于10块钱,如果大于等于则继续,小于则返回,我们这里只讨论大于等于的
3、从张三的账户上减去10块
4、向李四的账户增加10块
5、解锁账户完成交易update account set amount = amount - 100 where userNo='zhangsan' and amount >=10
update account set amount = amount + 100 where userNo='lisi'如果是分布式事务就要考虑到两个用户账户的一致性,我们就从分布式的角度来分析一下
1、锁定张三的账户,同时通过网络锁定李四的账户(可以理解成冻结金额)
2、判断张三的账户是否大于等于10块钱,如果大于等于则继续,小于则返回,我们这里只讨论大于等于的
3、从张三的账户上减去10块
4、通过网络向李四的账户增加10块
5、解锁张三账户完成交易,通过网络解锁李四的账户,时间基本上是累计的通过rocketmq怎么做这个事儿呢,首先通过rocketmq做这个事儿我们就要分清一下角色,张三为
事务的发起者也就是消息的发送者,相对李四就是消息的消费者了,rocketmq可以理解成中间账户,
默认Consumer都会成功,如果不成功官方推荐人工介入。1、判断张三的账户金额大于10
2、同时张三的账户减去10
3、同时丢出一个mq消息给rocketmq,两个要确保放在一个db事务中(此时的消息只是处于prapared阶段,
不会被Consumer所消费)
4、如果本地事务执行成功则向rocketmq发送commit
5、如果第四部出现了本Consumer宕机,也就是rocketmq没有收到commit,此刻消息是是未知,所以
他会向任意一台Producer来确认当前消息的状态
5、如果第四部出现了本Consumer宕机,也就是rocketmq没有收到commit,此刻消息是是未知,所以他会
向任意一台Producer来确认当前消息的状态
6、从此保障了本地账户和rocketmq的一致性/*** 发送事务消息例子* */
public class TransactionProducer {public static void main(String[] args) throws MQClientException, InterruptedException {TransactionCheckListener transactionCheckListener = new TransactionCheckListenerImpl();TransactionMQProducer producer = new TransactionMQProducer("please_rename_unique_group_name");producer.setNamesrvAddr("100.8.8.88:9876");// 事务回查最小并发数producer.setCheckThreadPoolMinSize(2);// 事务回查最大并发数producer.setCheckThreadPoolMaxSize(2);// 队列数producer.setCheckRequestHoldMax(2000);producer.setTransactionCheckListener(transactionCheckListener);producer.start();String[] tags = new String[] { "TagA", "TagB", "TagC", "TagD", "TagE" };TransactionExecuterImpl tranExecuter = new TransactionExecuterImpl();for (int i = 0; i < 100; i++) {try {Message msg =new Message("TopicTest", tags[i % tags.length], "KEY" + i,("Hello RocketMQ " + i).getBytes());SendResult sendResult = producer.sendMessageInTransaction(msg, tranExecuter, null);System.out.println(sendResult);}catch (MQClientException e) {e.printStackTrace();}}for (int i = 0; i < 100000; i++) {Thread.sleep(1000);}producer.shutdown();}
}本地事务:/*** 执行本地事务*/
public class TransactionExecuterImpl implements LocalTransactionExecuter {private AtomicInteger transactionIndex = new AtomicInteger(1);@Overridepublic LocalTransactionState executeLocalTransactionBranch(final Message msg, final Object arg) {int value = transactionIndex.getAndIncrement();if (value == 0) {throw new RuntimeException("Could not find db");}else if ((value % 5) == 0) {return LocalTransactionState.ROLLBACK_MESSAGE;}else if ((value % 4) == 0) {return LocalTransactionState.COMMIT_MESSAGE;}return LocalTransactionState.UNKNOW;}
}回调检查点:/*** 未决事务,服务器回查客户端*/
public class TransactionCheckListenerImpl implements TransactionCheckListener {private AtomicInteger transactionIndex = new AtomicInteger(0);@Overridepublic LocalTransactionState checkLocalTransactionState(MessageExt msg) {System.out.println("server checking TrMsg " + msg.toString());int value = transactionIndex.getAndIncrement();if ((value % 6) == 0) {throw new RuntimeException("Could not find db");}else if ((value % 5) == 0) {return LocalTransactionState.ROLLBACK_MESSAGE;}else if ((value % 4) == 0) {return LocalTransactionState.COMMIT_MESSAGE;}return LocalTransactionState.UNKNOW;}点对点/广播
点对点和发布订阅的两种模式上面我们已经说了很多,这里只要我们在consumer里面配置MessageModel就
可以做到两种模式的消费,//发布订阅consumer.setMessageModel(MessageModel.BROADCASTING);//集群消费(默认)//consumer.setMessageModel(MessageModel.CLUSTERING);推送/拉取
采用消息推送的模式,注册监听,当有消息产生时就会实时的推送到Consumer进行消费,
import java.util.HashMap;
import java.util.Map;
import java.util.Set;import com.alibaba.rocketmq.client.consumer.DefaultMQPullConsumer;
import com.alibaba.rocketmq.client.consumer.PullResult;
import com.alibaba.rocketmq.client.exception.MQClientException;
import com.alibaba.rocketmq.common.message.MessageQueue;/*** PullConsumer,订阅消息*/
public class PullConsumer {private static final Map<MessageQueue, Long> offseTable = new HashMap<MessageQueue, Long>();public static void main(String[] args) throws MQClientException {DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("please_rename_unique_group_name_5");consumer.start();Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("TopicTest");for (MessageQueue mq : mqs) {System.out.println("Consume from the queue: " + mq);SINGLE_MQ: while (true) {try {PullResult pullResult =consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);System.out.println(pullResult);putMessageQueueOffset(mq, pullResult.getNextBeginOffset());switch (pullResult.getPullStatus()) {case FOUND:// TODObreak;case NO_MATCHED_MSG:break;case NO_NEW_MSG:break SINGLE_MQ;case OFFSET_ILLEGAL:break;default:break;}}catch (Exception e) {e.printStackTrace();}}}consumer.shutdown();}private static void putMessageQueueOffset(MessageQueue mq, long offset) {offseTable.put(mq, offset);}private static long getMessageQueueOffset(MessageQueue mq) {Long offset = offseTable.get(mq);if (offset != null)return offset;return 0;}}消息回溯
回溯消费是指 Consumer 已经消费成功的消息,由于业务上需求需要重新消费,Broker 在Consumer 投递
成功消息后,消息仍然需要保留。并且重新消费一般是按照时间维度,例如由于 Consumer 系统故障,恢复
后需要重新消费 1 小时前的数据,那举 Broker 要提供一种机制,可以按照时间维度来回退消费进度
RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯
操作: mqadmin resetOffsetByTimeKafka、RabbitMQ、RocketMQ消息中间件的对比
分布式系统中,我们广泛运用消息中间件进行系统间的数据交换,便于异步解耦。产品 RocketMQ (MetaQ的内核) 那么,消息中间件性能究竟哪家强?中间件测试组对常见的三类消息产品(Kafka、RabbitMQ、RocketMQ)做了性能比较。Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。Kafka主要特点是基于Pull
的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,
不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、
队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、
稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用
的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,
目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。在同步发送场景中,三个消息中间件的表现区分明显:Kafka的吞吐量高达17.3w/s,不愧是高吞吐量消息中间件的行业老大。这主要取决于它的队列模式保证了
写磁盘的过程是线性IO。此时broker磁盘IO已达瓶颈。RocketMQ也表现不俗,吞吐量在11.6w/s,磁盘IO %util已接近100%。RocketMQ的消息写入内存后即
返回ack,由单独的线程专门做刷盘的操作,所有的消息均是顺序写文件。RabbitMQ的吞吐量5.95w/s,CPU资源消耗较高。它支持AMQP协议,实现非常重量级,为了保证消息的可靠性
在吞吐量上做了取舍。我们还做了RabbitMQ在消息持久化场景下的性能测试,吞吐量在2.6w/s左右。测试结论
在服务端处理同步发送的性能上,Kafka>RocketMQ>RabbitMQ。但是,作为经受过历次双十一洗礼的RocketMQ,在互联网应用场景中更有它优越的一面。rocketmq详解
简介
官方简介:RocketMQ是一款分布式、队列模型的消息中间件,具有以下特点:
1.能够保证严格的消息顺序
2.提供丰富的消息拉取模式
3.高效的订阅者水平扩展能力
4.实时的消息订阅机制
5.亿级消息堆积能力![]()
三、特性
1. nameserver
相对来说,nameserver的稳定性非常高。原因有二:
1 、nameserver互相独立,彼此没有通信关系,单台nameserver挂掉,不影响其他nameserver,即使
全部挂掉,也不影响业务系统使用。无状态
2 、nameserver不会有频繁的读写,所以性能开销非常小,稳定性很高。2. broker
与nameserver关系
连接单个broker和所有nameserver保持长连接
心跳心跳间隔:每隔30秒(此时间无法更改)向所有nameserver发送心跳,心跳包含了自身的topic配置信息。心跳超时:nameserver每隔10秒钟(此时间无法更改),扫描所有还存活的broker连接,若某个连接2分钟内(当前时间与最后更新时间差值超过2分钟,此时间无法更改)没有发送心跳数据,则断开连接。断开时机:broker挂掉;心跳超时导致nameserver主动关闭连接动作:一旦连接断开,nameserver会立即感知,更新topc与队列的对应关系,但不会通知生产者和消费者负载均衡一个topic分布在多个broker上,一个broker可以配置多个topic,它们是多对多的关系。 如果某个topic消息量很大,应该给它多配置几个队列,并且尽量多分布在不同broker上,减轻某个broker的压力。topic消息量都比较均匀的情况下,如果某个broker上的队列越多,则该broker压力越大。可用性由于消息分布在各个broker上,一旦某个broker宕机,则该broker上的消息读写都会受到影响。所以rocketmq提供了master/slave的结构,salve定时从master同步数据,如果master宕机,则slave提供消费服务,但是不能写入消息,此过程对应用透明,由rocketmq内部解决。这里有两个关键点:1.一旦某个broker master宕机,生产者和消费者多久才能发现?受限于rocketmq的网络连接机制,默认情况下,最多需要30秒,但这个时间可由应用设定参数来缩短时间。这个时间段内,发往该broker的消息都是失败的,而且该broker的消息无法消费,因为此时消费者不知道该broker已经挂掉。2.消费者得到master宕机通知后,转向slave消费(重定向,对于2次开发者透明),但是slave不能保证master的消息100%都同步过来了,因此会有少量的消息丢失。但是消息最终不会丢的,一旦master恢复,未同步过去的消息会被消费掉。可靠性1.所有发往broker的消息,有同步刷盘和异步刷盘机制,总的来说,可靠性非常高2.同步刷盘时,消息写入物理文件才会返回成功,因此非常可靠3. 异步刷盘时,只有机器宕机,才会产生消息丢失,broker挂掉可能会发生,但是机器宕机崩溃是很少发生的,除非突然断电消息清理
1.扫描间隔默认10秒,由broker配置参数cleanResourceInterval决定
2.空间阈值物理文件不能无限制的一直存储在磁盘,当磁盘空间达到阈值时,不再接受消息,broker打印出日志,消息发送失败,阈值为固定值85%
3.清理时机默认每天凌晨4点,由broker配置参数deleteWhen决定;或者磁盘空间达到阈值
4. 文件保留时长默认72小时,由broker配置参数fileReservedTime决定读写性能
1.文件内存映射方式操作文件,避免read/write系统调用和实时文件读写,性能非常高
2.永远一个文件在写,其他文件在读
3.顺序写,随机读
4.将消息内容直接输出到socket管道,避免系统调用系统特性
1.大内存,内存越大性能越高,否则系统swap会成为性能瓶颈
2.IO密集
3.cpu load高,使用率低,因为cpu占用后,大部分时间在IO WAIT
4.磁盘可靠性要求高,为了兼顾安全和性能,采用RAID10阵列
5.磁盘读取速度要求快,要求高转速大容量磁盘3. 消费者
与nameserver关系
1.连接单个消费者和一台nameserver保持长连接,定时查询topic配置信息,如果该nameserver挂掉,消费者会自动连接下一个nameserver,直到有可用连接为止,并能自动重连。
2.心跳与nameserver没有心跳
3.轮询时间消费者每隔30秒从nameserver获取所有topic的最新队列情况,这意味着某个broker如果宕机,客户端最多要30秒才能感知。该时间由DefaultMQPushConsumer的pollNameServerInteval参数决定,可手动配置。与broker关系
1.连接单个消费者和该消费者关联的所有broker保持长连接。
2.心跳默认情况下,消费者每隔30秒向所有broker发送心跳,该时间由DefaultMQPushConsumer的heartbeatBrokerInterval参数决定,可手动配置。broker每隔10秒钟(此时间无法更改),扫描所有还存活的连接,若某个连接2分钟内(当前时间与最后更新时间差值超过2分钟,此时间无法更改)没有发送心跳数据,则关闭连接,并向该消费者分组的所有消费者发出通知,分组内消费者重新分配队列继续消费
3. 断开时机:消费者挂掉;心跳超时导致broker主动关闭连接动作:一旦连接断开,broker会立即感知到,并向该消费者分组的所有消费者发出通知,分组内消费者重新分配队列继续消费负载均衡集群消费模式下,一个消费者集群多台机器共同消费一个topic的多个队列,一个队列只会被一个消费者消费。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。消费机制
1.本地队列
消费者不间断的从broker拉取消息,消息拉取到本地队列,然后本地消费线程消费本地消息队列,只是一个
异步过程,拉取线程不会等待本地消费线程,这种模式实时性非常高(本地消息队列达到解耦的效果,响应
时间减少)。对消费者对本地队列有一个保护,因此本地消息队列不能无限大,否则可能会占用大量内存,
本地队列大小由DefaultMQPushConsumer的pullThresholdForQueue属性控制,默认1000,可手动设置。
2.轮询间隔消息拉取线程每隔多久拉取一次?间隔时间由DefaultMQPushConsumer的pullInterval属性控制,默认
为0,可手动设置。
3.消息消费数量
监听器每次接受本地队列的消息是多少条?这个参数由DefaultMQPushConsumer
的consumeMessageBatchMaxSize属性控制,默认为1,可手动设置。消费进度存储
每隔一段时间将各个队列的消费进度存储到对应的broker上,该时间由DefaultMQPushConsumer
的persistConsumerOffsetInterval属性控制,默认为5秒,可手动设置。如果一个topic在某broker上有3个队列,一个消费者消费这3个队列,那么该消费者和这个broker有
几个连接?一个连接,消费单位与队列相关,消费连接只跟broker相关,事实上,消费者将所有队列的消息拉取任务
放到本地的队列,挨个拉取,拉取完毕后,又将拉取任务放到队尾,然后执行下一个拉取任务4. 生产者与nameserver关系
1.连接
单个生产者者和一台nameserver保持长连接,定时查询topic配置信息,如果该nameserver挂掉,生产者会
自动连接下一个nameserver,直到有可用连接为止,并能自动重连。
2.轮询时间
默认情况下,生产者每隔30秒从nameserver获取所有topic的最新队列情况,这意味着某个broker
如果宕机,生产者最多要30秒才能感知,在此期间,发往该broker的消息发送失败。该时间
由DefaultMQProducer的pollNameServerInteval参数决定,可手动配置。
3.心跳
与nameserver没有心跳与broker关系
1.连接
单个生产者和该生产者关联的所有broker保持长连接。
2.心跳
默认情况下,生产者每隔30秒向所有broker发送心跳,该时间由DefaultMQProducer
的heartbeatBrokerInterval参数决定,可手动配置。broker每隔10秒钟(此时间无法更改),扫描所有
还存活的连接,若某个连接2分钟内(当前时间与最后更新时间差值超过2分钟,此时间无法更改)没有发送
心跳数据,则关闭连接。
3.连接断开
移除broker上的生产者信息负载均衡生产者时间没有关系,每个生产者向队列轮流发送消息四、Broker集群配置方式及优缺点
### 先启动 NameServer,例如机器 IP 为:172.16.8.106:9876
nohup sh mqnamesrv &
### 在机器 A,启动第一个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-noslave/
broker-a.properties &
### 在机器 B,启动第二个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-noslave/
broker-b.properties &3. 多 Master 多 Slave 模式,异步复制每个 Master 配置一个 Slave,有多对Master-Slave,HA 采用异步复制方式,主备有短暂消息延迟,
毫秒级优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为 Master 宕机后,消费者
仍然可以从 Slave 消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式几乎一样。缺点:Master 宕机,磁盘损坏情况,会丢失少量消息。### 先启动 NameServer,例如机器 IP 为:172.16.8.106:9876
nohup sh mqnamesrv &### 在机器 A,启动第一个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-async/
broker-a.properties &### 在机器 B,启动第二个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-async/
broker-b.properties &
### 在机器 C,启动第一个 Slave
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-async/
broker-a-s.properties &### 在机器 D,启动第二个 Slave
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-async/
broker-b-s.properties &4. 多 Master 多 Slave 模式,同步双写每个 Master 配置一个 Slave,有多对Master-Slave,HA 采用同步双写方式,主备都写成功,
向应用返回成功。优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT 会略高。目前主宕机后,
备机不能自动切换为主机,后续会支持自动切换功能。### 先启动 NameServer,例如机器 IP 为:172.16.8.106:9876
nohup sh mqnamesrv &### 在机器 A,启动第一个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-sync/
broker-a.properties &### 在机器 B,启动第二个 Master
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-sync/
broker-b.properties &### 在机器 C,启动第一个 Slave
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-sync/
broker-a-s.properties &### 在机器 D,启动第二个 Slave
nohup sh mqbroker -n 172.16.8.106:9876 -c$ROCKETMQ_HOME/conf/2m-2s-sync/
broker-b-s.properties &
Rocketmq原理最佳实践相关推荐
- RocketMq namesvr 最佳实践
RocketMq namesvr 最佳实践 翻译自RocketMQ官方文档 Apache RocketMQ中,name servers被设计用来协调分布式系统的每个部分,协调主要是完成topic路由信 ...
- RocketMq Consumer 最佳实践
RocketMq Consumer 最佳实践 翻译自RocketMQ官方文档 Consumer Group and Subscriptions 消费集群和订阅 第一件你应该关心的是不同的消费集群能独立 ...
- RocketMq Producer最佳实践
RocketMq Producer最佳实践 翻译自RocketMQ官方文档 SendStatus 发送消息时,你会得到一个包含SendStatus的SendResult.首先,我们认为消息的isWai ...
- 从零到一构建完整知识体系,阿里最新SpringBoot原理最佳实践真香
Spring Boot不用多说,是咱们Java程序员必须熟练掌握的基本技能.工作上它让配置.代码编写.部署和监控都更简单,面试时互联网企业招聘对于Spring Boot这个系统开发的首选框架也是考察的 ...
- Rocketmq原理与实践
一. MQ背景&选型 消息队列作为高并发系统的核心组件之一,能够帮助业务系统解构提升开发效率和系统稳定性.主要具有以下优势: 削峰填谷(主要解决瞬时写压力大于应用服务能力导致消息丢失.系统奔溃 ...
- Schedulerx2.0分布式计算原理最佳实践
1. 前言 Schedulerx2.0的客户端提供分布式执行.多种任务类型.统一日志等框架,用户只要依赖schedulerx-worker这个jar包,通过schedulerx2.0提供的编程模型,简 ...
- RocketMq 的最佳实践
1 生产者 1.1 发送消息注意事项 1 Tags的使用 一个应用尽可能用一个Topic,而消息子类型则可以用tags来标识.tags可以由应用自由设置,只有生产者在发送消息设置了tags,消费方在订 ...
- rocketmq存储结构_阿里专家分享内部绝密RocketMQ核心原理与最佳实践笔记
本文源码以RocketMQ 4.2.0 和 RocketMQ 4.3.0 为 基 础 , 从RocketMQ的实际使用到RocketMQ的源码分析,再到RocketMQ企业落地实践方案,逐步讲解.使读 ...
- clickhouse原理解析与应用实践 pdf_阿里专家分享内部绝密RocketMQ核心原理与最佳实践PDF...
前言 本文源码以RocketMQ 4.2.0 和 RocketMQ 4.3.0 为 基 础 , 从RocketMQ的实际使用到RocketMQ的源码分析,再到RocketMQ企业落地实践方案,逐步讲解 ...
最新文章
- android优雅私有方法注释,带有注释参数的私有方法的Android java.lang.VerifyError
- c#截取字符串指定符号,在.NET中,C#字符串是可截取的,可从指定位置截取,也可指定数量...
- 虚拟串口工具Virtual Serial Port Driver(VSPD)
- 第二十一章流 5 多种打开文件的方式 文件存在,文件不存在
- python缺失值处理 fillna能否用scala来处理_数据清洗(一)丨处理缺失数据
- Hexo 入门指南(二) - 安装、初始化和配置
- 开滦二中2021高考成绩查询,2021年唐山查询中考成绩
- 一行 Python 实现并行化 -- 日常多线程操作的新思路
- Mac 电脑如何对文件进行批量重命名?
- 同时读取两个文件进行while循环
- SQL Server 2008 存储结构之DCM、BCM
- 在eclipse-oxygen-sts中,关于快捷键[CTRL + SHIFT + O]失效的问题
- python在文本添加超链接_在Markdown中快速插入超链接的Workflow
- 爬取京东某商品评论并存入csv
- 虚无缥缈的自信,一落千丈的打击
- 【TouchDesigner学习笔记与资料】
- 如何解密pdf加密文件
- 数据治理与数据安全研读开篇
- 深圳软件测试培训:简述关系型数据库和非关系型数据库
- 【 2021 MathorCup杯大数据挑战赛 A题 二手车估价】初赛复赛总结、方案代码及论文