infogan 生成mnist 手写数字
原文链接: infogan 生成mnist 手写数字
上一篇: teamviewer 远程操控
下一篇: ros 发布订阅模型 自定义消息
InfoGAN介绍
尝试加深生成器网络结构以便于生成更加逼真的信息,结果效果反而很差
生成器中使用relu比leaky_relu效果也好,不知道为什么。。。。
判别器加深后效果也不怎么好,貌似这个结构是 经过多次试验之后才确定的,修改反而效果很差
效果
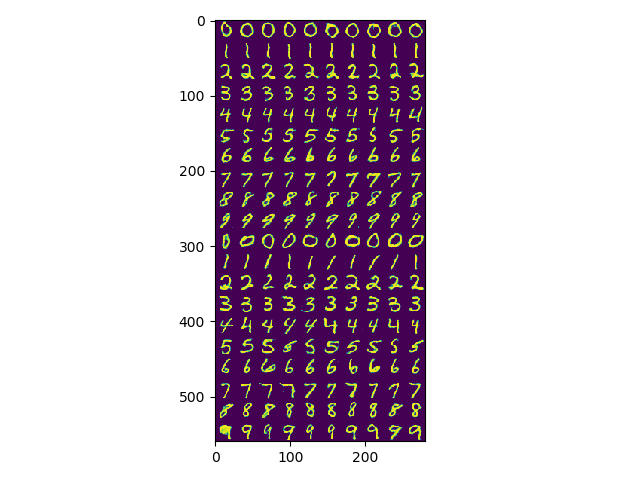
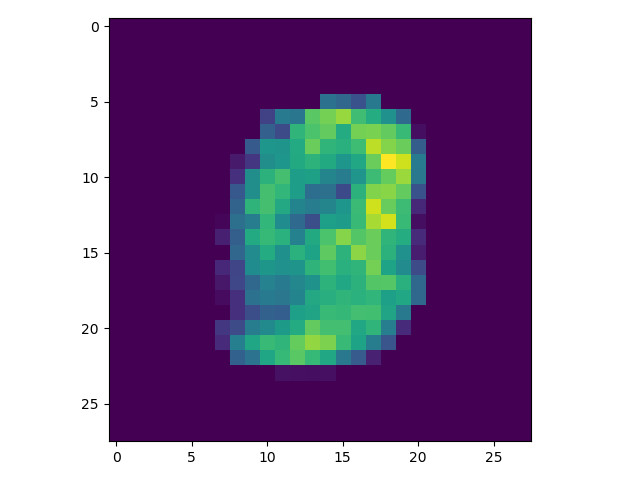
由于其中采用了bn层,所以如果只对一张图片进行可视化操作会出现下面的问题,但是多张图片就没有 问题
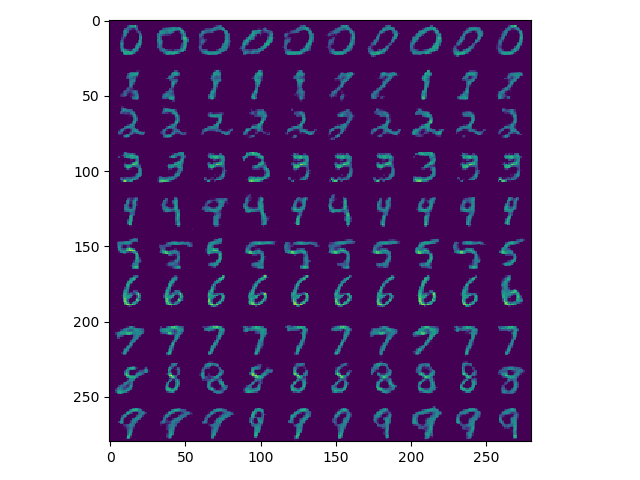
不同的激活函数和网络结构训练得到的结果也不一样
输入,z表示噪声,由两部分组成,一部分蕴含信息,一部分是随机噪声
x = tf.placeholder(tf.float32, [None, n_input])in_y = tf.placeholder(tf.int32, [None])z_con = tf.placeholder(tf.float32, (None, con_dim))z_rand = tf.placeholder(tf.float32, (None, rand_dim))z = tf.concat([tf.one_hot(in_y, n_class), z_con, z_rand], axis=1)print('z ', z.shape) # z (?, 50)生成器和判别器
生成器输入数据,n*(2+38+10) 输出 n*28*28*1
判别器输入图片返回三个结果
1,真实图片概率 0---1.0
2,分类信息n*10
3,隐含信息n*2
def generator(x):reuse = len([t for t in tf.global_variables() if t.name.startswith('generator')]) > 0with tf.variable_scope('generator', reuse=reuse):x = slim.fully_connected(x, 1024)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = slim.fully_connected(x, 7 * 7 * 128)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = tf.reshape(x, [-1, 7, 7, 128])x = slim.conv2d_transpose(x, 64, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.relu)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = slim.conv2d_transpose(x, 1, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.sigmoid)print('x ', x.shape) # x (?, 28, 28, 1)return xdef discriminator(x):reuse = len([t for t in tf.global_variables() if t.name.startswith('discriminator')]) > 0with tf.variable_scope('discriminator', reuse=reuse):x = tf.reshape(x, shape=[-1, 28, 28, 1])x = slim.conv2d(x, num_outputs=64, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.leaky_relu)x = slim.conv2d(x, num_outputs=128, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.leaky_relu)print('x ', x.shape) # x (?, 7, 7, 128)x = slim.flatten(x) # x (?, 6272)print('x ', x.shape)shared_tensor = slim.fully_connected(x, num_outputs=512, activation_fn=tf.nn.leaky_relu)recog_shared = slim.fully_connected(shared_tensor, num_outputs=128, activation_fn=tf.nn.leaky_relu)disc = slim.fully_connected(recog_shared, num_outputs=1, activation_fn=tf.nn.leaky_relu)print('disc ', disc.shape) # disc (?, 1)disc = tf.squeeze(disc, -1)print('disc ', disc.shape) # disc (?,)recog_cat = slim.fully_connected(recog_shared, num_outputs=n_class, activation_fn=tf.nn.leaky_relu)print('recog_cat ', recog_cat.shape) # recog_cat (?, 10)recog_cont = slim.fully_connected(recog_shared, num_outputs=con_dim, activation_fn=tf.nn.sigmoid)print('recog_cont ', recog_cont.shape) # recog_cont (?, 2)return disc, recog_cat, recog_cont
将输入放入生成器中,然后等到判别器的输出用于计算loss
gen = generator(z)# labels for discriminatory_real = tf.ones(batch_size) # 真y_fake = tf.zeros(batch_size) # 假print('y_real ', y_real.shape) # y_real (64,)# 判别器disc_real, class_real, _ = discriminator(x)disc_fake, class_fake, con_fake = discriminator(gen)loss
判别器中,判别结果的loss有两个:真实输入的结果与模拟输入的结果,将两个结合在一起生成loss_d,生成器的loss为自己输出的模拟数据,让他在判别器中为真,定义为loss_g
定义网络中共有的loss,真实的标签与输入真实样0本判别出的标签,真实的标签与输入模拟样0本判别出的标签,隐含信息的重构误差,然后创建两个优化器,将他们放到对应的优化器中
loss_cf 分类正确,但生成的样本错了
loss_cr 分类与样本正确,但与输入的分类对不上
loss_con 隐含变量的loss
loss_g 生成器的loss目标是判别结果全为真
loss_d 判别器的loss目标是将假的判为假,真的判为真
所谓的AC-GAN就是将loss_cr加入到loss_c中,如果没有loss_cr,令loss_c=loss_cf,对于网络生成的模拟数据是不影响的,但是会损失真实分类与模拟数据间的对应关系。
由于损失函数中的判别为长度为n的数组,所以使用sigmoid交叉熵,softmax用于进行单分类,即一个物体只能归属于一个类别这种情况。
# 判别器 loss 使用sigmoid函数因为判别器输出的是一个数字表示真实的概率# softmax在输出为one hot编码时使用,在这里由于只有一个数字所以计算结果永远为0loss_d_r = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_real, labels=y_real))loss_d_f = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_fake))loss_d = (loss_d_r + loss_d_f) / 2# generator lossloss_g = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_real))loss_cf = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_fake, labels=in_y))loss_cr = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_real, labels=in_y))loss_c = (loss_cf + loss_cr) / 2loss_con = tf.reduce_mean((con_fake - z_con) ** 2)训练
小技巧: 将判别器的学习率设小,将生成器的学习率设大,这么做是为了 让生成器有更快的进化速度来模拟真实数据,优化同样是adam
# 获得各个网络中各自的训练参数t_vars = tf.trainable_variables()d_vars = [var for var in t_vars if 'discriminator' in var.name]g_vars = [var for var in t_vars if 'generator' in var.name]train_disc = tf.train.AdamOptimizer(0.0001).minimize(loss_d + loss_c + loss_con, var_list=d_vars,global_step=disc_global_step)train_gen = tf.train.AdamOptimizer(0.001).minimize(loss_g + loss_c + loss_con, var_list=g_vars,global_step=gen_global_step)
完整代码
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.contrib.slim as slim
from tensorflow.examples.tutorials.mnist import input_data
from scipy.stats import normn_class = 10batch_size = 64 # 获取样本的批次大小64
con_dim = 2 # total continuous factor
n_input = 784
training_epochs = 20000
display_step = 500
rand_dim = 38def generator(x):reuse = len([t for t in tf.global_variables() if t.name.startswith('generator')]) > 0with tf.variable_scope('generator', reuse=reuse):x = slim.fully_connected(x, 1024)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = slim.fully_connected(x, 7 * 7 * 128)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = tf.reshape(x, [-1, 7, 7, 128])x = slim.conv2d_transpose(x, 64, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.relu)x = slim.batch_norm(x, activation_fn=tf.nn.relu)x = slim.conv2d_transpose(x, 1, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.sigmoid)print('x ', x.shape) # x (?, 28, 28, 1)return xdef discriminator(x):reuse = len([t for t in tf.global_variables() if t.name.startswith('discriminator')]) > 0with tf.variable_scope('discriminator', reuse=reuse):x = tf.reshape(x, shape=[-1, 28, 28, 1])x = slim.conv2d(x, num_outputs=64, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.leaky_relu)x = slim.conv2d(x, num_outputs=128, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.leaky_relu)print('x ', x.shape) # x (?, 7, 7, 128)x = slim.flatten(x) # x (?, 6272)print('x ', x.shape)shared_tensor = slim.fully_connected(x, num_outputs=512, activation_fn=tf.nn.leaky_relu)recog_shared = slim.fully_connected(shared_tensor, num_outputs=128, activation_fn=tf.nn.leaky_relu)disc = slim.fully_connected(recog_shared, num_outputs=1, activation_fn=tf.nn.leaky_relu)print('disc ', disc.shape) # disc (?, 1)disc = tf.squeeze(disc, -1)print('disc ', disc.shape) # disc (?,)recog_cat = slim.fully_connected(recog_shared, num_outputs=n_class, activation_fn=tf.nn.leaky_relu)print('recog_cat ', recog_cat.shape) # recog_cat (?, 10)recog_cont = slim.fully_connected(recog_shared, num_outputs=con_dim, activation_fn=tf.nn.sigmoid)print('recog_cont ', recog_cont.shape) # recog_cont (?, 2)return disc, recog_cat, recog_contdef main():x = tf.placeholder(tf.float32, [None, n_input])in_y = tf.placeholder(tf.int32, [None])z_con = tf.placeholder(tf.float32, (None, con_dim))z_rand = tf.placeholder(tf.float32, (None, rand_dim))z = tf.concat([tf.one_hot(in_y, n_class), z_con, z_rand], axis=1)print('z ', z.shape) # z (?, 50)gen = generator(z)# labels for discriminatory_real = tf.ones(batch_size) # 真y_fake = tf.zeros(batch_size) # 假print('y_real ', y_real.shape) # y_real (64,)# 判别器disc_real, class_real, _ = discriminator(x)disc_fake, class_fake, con_fake = discriminator(gen)disc_global_step = tf.Variable(0, trainable=False)gen_global_step = tf.Variable(0, trainable=False)# 判别器 loss 使用sigmoid函数因为判别器输出的是一个数字表示真实的概率# softmax在输出为one hot编码时使用,在这里由于只有一个数字所以计算结果永远为0loss_d_r = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_real, labels=y_real))loss_d_f = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_fake))loss_d = (loss_d_r + loss_d_f) / 2# generator lossloss_g = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_real))loss_cf = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_fake, labels=in_y))loss_cr = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_real, labels=in_y))loss_c = (loss_cf + loss_cr) / 2loss_con = tf.reduce_mean((con_fake - z_con) ** 2)# softmax在输出为one hot编码时使用,在这里由于只有一个数字所以计算结果永远为0# loss_d_r = tf.reduce_mean((disc_real - y_real) ** 2)# loss_d_f = tf.reduce_mean((disc_fake - y_fake) ** 2)# loss_d = (loss_d_r + loss_d_f) / 2# # generator loss# loss_g = tf.reduce_mean((disc_fake - y_real) ** 2)# 获得各个网络中各自的训练参数t_vars = tf.trainable_variables()d_vars = [var for var in t_vars if 'discriminator' in var.name]g_vars = [var for var in t_vars if 'generator' in var.name]train_disc = tf.train.AdamOptimizer(0.0001).minimize(loss_d + loss_c + loss_con, var_list=d_vars,global_step=disc_global_step)train_gen = tf.train.AdamOptimizer(0.001).minimize(loss_g + loss_c + loss_con, var_list=g_vars,global_step=gen_global_step)mnist = input_data.read_data_sets(r"D:\code\python\tf\gandemo\MNIST_data")for i in tf.global_variables():print(i.name, i.shape)with tf.Session() as sess:sess.run(tf.global_variables_initializer())for epoch in range(1, 1 + training_epochs):# 遍历全部数据集batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 取数据# print('batch_xs ys', batch_xs.shape, batch_ys.shape) # batch_xs ys (64, 784) (64,)batch_con = np.random.randn(batch_size, con_dim)batch_rand = np.random.randn(batch_size, rand_dim)feeds = {x: batch_xs, z_con: batch_con, z_rand: batch_rand, in_y: batch_ys}# Fit training using batch datal_disc, _, disc_step = sess.run([loss_d, train_disc, disc_global_step], feeds)l_gen, _, gen_step = sess.run([loss_g, train_gen, gen_global_step], feeds)# 显示训练中的详细信息if not epoch % display_step:batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 取数据batch_con = np.random.randn(batch_size, con_dim)batch_rand = np.random.randn(batch_size, rand_dim)feeds = {x: batch_xs, z_con: batch_con, z_rand: batch_rand, in_y: batch_ys}disc_fake_val, disc_real_val, loss_d_val, loss_g_val = sess.run([disc_fake, disc_real, loss_d, loss_g], feeds)print(epoch, loss_d_val, loss_g_val)col = []for i in range(n_class):t = norm.ppf(np.linspace(.5, .95, n_class))batch_con = np.stack([t] * con_dim).Tbatch_rand = np.random.randn(n_class, rand_dim)feeds = {z_con: batch_con, z_rand: batch_rand, in_y: np.arange(0, n_class)}img_val = sess.run(gen, feeds)img_val = np.reshape(img_val, (-1, 28, 28))col.append(np.concatenate(img_val))col = np.concatenate(col, axis=1)col2 = []for i in range(n_class):batch_con = np.random.randn(n_class, con_dim)batch_rand = np.random.randn(n_class, rand_dim)feeds = {z_con: batch_con, z_rand: batch_rand, in_y: np.arange(0, n_class)}img_val = sess.run(gen, feeds)img_val = np.reshape(img_val, (-1, 28, 28))col2.append(np.concatenate(img_val))col2 = np.concatenate(col2, axis=1)img = np.concatenate([col, col2])plt.imshow(img)plt.show()if __name__ == '__main__':main()
infogan 生成mnist 手写数字相关推荐
- pytorch学习之GAN生成MNIST手写数字
0.简单介绍: 学深度学习的人必然知道,最基本的GAN模型由一个生成器 G 和判别器 D 组成.生成器用于生成假样本,判别器用于判断样本是真实的还是假的. 在整个训练过程中,生成器努力地让生成的图像更 ...
- GAN实战之Pytorch 使用CGAN生成指定MNIST手写数字
有关条件GAN(cgan)的相关原理,可以参考: GAN系列之CGAN原理简介以及pytorch项目代码实现 其他类型的GAN原理介绍以及应用,可以查看我的GANs专栏 一.数据集介绍,加载数据 依旧 ...
- TF之DNN:利用DNN【784→500→10】对MNIST手写数字图片识别数据集(TF自带函数下载)预测(98%)+案例理解DNN过程
TF之DNN:利用DNN[784→500→10]对MNIST手写数字图片识别数据集(TF自带函数下载)预测(98%)+案例理解DNN过程 目录 输出结果 案例理解DNN过程思路 代码设计 输出结果 案 ...
- TensorFlow高阶 API: keras教程-使用tf.keras搭建mnist手写数字识别网络
TensorFlow高阶 API:keras教程-使用tf.keras搭建mnist手写数字识别网络 目录 TensorFlow高阶 API:keras教程-使用tf.keras搭建mnist手写数字 ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- tensorflow saver_机器学习入门(6):Tensorflow项目Mnist手写数字识别-分析详解
本文主要内容:Ubuntu下基于Tensorflow的Mnist手写数字识别的实现 训练数据和测试数据资料:http://yann.lecun.com/exdb/mnist/ 前面环境都搭建好了,直接 ...
- 卷积神经网络(CNN)之MNIST手写数字数据集的实现
MNIST数据集是一个非常经典的手写数字识别的数据集,本人很多文章都是拿这个数据集来做示例,MNIST的具体介绍与用法可以参阅: MNIST数据集手写数字识别(一)https://blog.csdn. ...
- 深度学习21天——卷积神经网络(CNN):实现mnist手写数字识别(第1天)
目录 一.前期准备 1.1 环境配置 1.2 CPU和GPU 1.2.1 CPU 1.2.2 GPU 1.2.3 CPU和GPU的区别 第一步:设置GPU 1.3 MNIST 手写数字数据集 第二步: ...
- 基于K210的MNIST手写数字识别
基于K210的MNIST手写数字识别 项目已开源链接: Github. 硬件平台 采用Maixduino开发板 在sipeed官方有售 软件平台 使用MaixPy环境进行单片机的编程 官方资源可在这里 ...
- Caffe MNIST 手写数字识别(全面流程)
目录 1.下载MNIST数据集 2.生成MNIST图片训练.验证.测试数据集 3.制作LMDB数据库文件 4.准备LeNet-5网络结构定义模型.prototxt文件 5.准备模型求解配置文件_sol ...
最新文章
- tensorflow学习笔记(四十五):sess.run(tf.global_variables_initializer()) 做了什么?
- linux c select 设置超时
- sql server datetime格式_为什么你SQL Server中SQL日期转换出错了呢?
- go grpc测试_Grpc — 整体性能测试
- 【Linux】一步一步学Linux——gdb命令(258)
- angular 模块构建_我如何在Angular 4和Magento上构建人力资源门户
- 推荐一个国外SaaS产品-Olark
- python创建新进程_Python:创建新进程
- 一篇博客读懂设计模式之-----策略模式
- 年薪十万的王者荣耀,LOL游戏模型师的工作是这样的|附50G资料
- ubuntu面板的图标混乱
- 深度学习(二)神经网络中的卷积和反卷积原理
- epson r1900 清零软件_EPSON R2000清零软件 R3000 R1800 R1900 R2880 R3880 4880打印机
- Mysql primary key主键冲突的可能性与解决方案
- Milvus 揭秘| 向量索引算法HNSW和NSG的比较
- 漫画:什么是服务熔断
- 【TA-霜狼_may-《百人计划》】图形3.7.2 command buffer简
- android sharedpreferences 存储对象,android中SharedPreferences实现存储用户名功能
- 如何办理护照(zt)
- 面试 -- 字节跳动(视频面)