SOTON私人定制:利用Python进行数据分析(分组运算)
数据分析比较常见的步骤是将对数据集进行分组然后应用函数,这步也可以称之为分组运算。Hadley Wickham大神为此创造了一个专用术语“split-apply-combine",即拆分-应用-合并。那么当我们谈论分组运算的时候,我们其实在谈论什么呢?
- Splitting:根据标准对数据进行拆分分组
- Applying: 对每组都分别应用一个函数
- Combining: 将结果合并新的数据结构
分组运算一般要求的数据存放格式为“长格式”,所以先介绍“长格式”和“宽格式”的转换,然后是分组运算的具体操作。
“长格式“ VS”宽格式“
数据的常见保存方式有两种,长格式(long format)或是宽格式(wide format)
- wide format
| 基因 | 分生组织 | 根 | 花 |
|---|---|---|---|
| gene1 | 582 | 91 | 495 |
| gene2 | 305 | 3505 | 33 |
在宽格式下,类别型变量单独成列。如上的植物的不同部位分为3列,列中的数据表示为表达量。看起来就非常的直观,而且日常生活中也是按照如此方法记录数据。
- long format
| 基因 | 组织 | 表达量 |
|---|---|---|
| gene1 | 分生组织 | 582 |
| gene2 | 分生组织 | 305 |
| gene1 | 根 | 91 |
| gene2 | 根 | 3503 |
| gene1 | 花 | 492 |
| gene2 | 花 | 33 |
而长结构的数据则是类别型变量定义为专门的一列。通常情况下,关系型数据库(如MySQL)通常以长格式存储数据,这是因为固定架构下随着表中数据的增加或删除, 类别行(如组织)能够增加或减少。
后续的分组操作其实更倾向于数据是以长格式进行保存,所以这里先介绍pandas是如何进行长格式和宽格式之间的转换的。
首先创建一个用于测试的长格式数据,方法如下:
import pandas.util.testing as tm; tm.N = 3
def unpivot(frame):N, K = frame.shapedata = {'value' : frame.values.ravel('F'),'variable' : np.asarray(frame.columns).repeat(N),'date' : np.tile(np.asarray(frame.index), K)}return pd.DataFrame(data, columns=['date', 'variable', 'value'])
ldata = unpivot(tm.makeTimeDataFrame())
然后把长格式变成宽格式,可认为是把数据的列“旋转” 为行
# 第一种方法: pivot
# pd.pivot(index, columns, values), 对应索引,类别列和数值列
pivoted = ldata.pivot('date','variable','value')
# 第二种方法: unstack
## 先用set_index建立层次化索引
unstacked = ldata.set_index(['date','varibale']).unstack('variable')
再把宽格式变为长格式,也可以认为是把数据的行“旋转”成列。
# 先把unstacked数据还原成普通的DataFrame
wdata = nstacked.reset_index()
wdata.columns = ['date','A','B','C','D']
# 第一种方法:melt
pd.melt(wdata, id_vars=['date'])
# 第二种方法: stack
# 如果原始数据没有索引,需要用set_index重建
wdata.set_index('date').stack()
GroupBy
第一步是将数据集根据一定标准,即分组键,拆分多个组,pandas提供了grouby方法,能够根据如下形式的分组键工作:
- 列表和数组(Numpy array),其长度与待分组的轴一致
- DataFrame的某个列名的值
- 字典或Series,提供了待分组轴上的值与分组名(label -> group name)之间的对应关系
- 根据多层次的轴索引
- Python函数,用于轴索引或索引中的各个标签
下面举例说明:
形式一:根据某一列的值,一般是类别型数值
df = DataFrame({'A' : ['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
# 根据A列进行拆分
df.groupby('A')
# 根据A和B列进行拆分
df.groupby(['A','B'])
这会产生一个pandas.core.groupby.DataFrameGroupBy object对象,没有进行实质性的运算操作,只产生了中间信息。你可以查看分组之后每一组的大小
df.groupby(['A','B']).size()
形式二: 根据函数. 下面定义了一个函数根据列名是否属于元音进行拆分
def get_letter_type(letter):if letter.lower() in 'aeiou':return 'vowel'else:return 'consonant'grouped = df.groupby(get_letter_type, axis=1).
形式三: 根据层次索引。 不同于R语言data.frame只有一个行或列名,pandas的DataFrame允许多个层次结构的行或列名。
# 构建多层次索引的数据
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
s = pd.Series(np.random.randn(8), index=index)
# 根据不同层次的索引进行分组
level1 = s.groupby(level='first') # 第一层
level2 = s.groupby(level=1) # 第二层
形式四: 根据字典或Series进行分组
可以通过字典定义分组信息的映射。
mapping = {'A':'str','B':'str','C':'values','D':'values','E':'values'}
df.groupby(mapping, axis=1)
形式四: 同时根据行索引和列数值进行分组
df.index = index
df.groupby([pd.Grouper(level='first'),'A']).mean()
分组对象迭代: 上面产生的GroupBy分组对象都是可以进行迭代,会产生一个一组二元元组。
# 对于单键值
for name, group in df.groupby(['A']):print(name)print(group)
# 对于多个键值
for (k1,k2), group in df.groupby(['A']):print(k1,k2)print(group)
选择分组:我们可以在分组结束后用get_group()提取某个特定的组
df.groupby('A').get_group('foo')
# 下面是结果A B C D E
first second
bar one foo one 0.709603 -1.023657 -0.321730
baz one foo two 1.495328 -0.279928 -0.297983
foo one foo two 0.495288 -0.563845 -1.774453
qux one foo one 1.649135 -0.274208 1.194536two foo three -2.194127 3.440418 -0.023144
# 多个组
df.groupby(['A', 'B']).get_group(('bar', 'one'))
Apply
分组步骤较为直接,而应用函数步骤则变化较多。这一步,我们可能会做如下操作:
- 数据聚合(Aggregation):分别计算各组的统计信息,如均值,大小等
- 转换(Transformation): 对每一组进行特异性的计算,如标准化,缺失值插值等
- 过滤(Filtration): 根据统计信息进行筛选,舍弃部分组。
数据聚合:Aggregation
所谓的聚合,也就是数组产生标量值的数据转换过程。我们可以使用mean, count, min, sum等一般性方法,也可以用GroupBy对象创建后的aggregate或等价的agg方法。
grouped = df.groupby('A')
grouped.mean()
# 等价于
grouped.agg(np.mean)
对于多个分组而言,会产生层次索引的结果,如果希望层次索引成为单独一列的话,需要在groupby用到as_index选项。或者最后使用reset_index方法
# as_index
grouped = df.groupby(['A','B'], as_index=False)
grouped.agg(np.mean)
# reset_index
df.groupby(['A','B']).sum().reset_index()
aggregate或等价的agg还允许对每一列使用多个统计函数
df.groupby('A').agg([np.sum,np.mean,np.std])
# 语法糖 df.groupby('A').C 等价于
# grouped=df.groupby(['A'])
# grouped['C']
df.groupby('A').C.agg([np.sum,np.mean,np.std])
或者是不同列使用不同函数,比如说对D列计算标准差,对列求平均
grouped=df.groupby(['A'])
grouped.agg({'D': np.std , 'C': np.mean})
注:目前sum, mean, std和sem方法对Cython进行了优化。
转换: Transformation
transform返回的对象和原来分组数据具有相同的大小。转换所用的函数必须满足如下条件:
- 返回的结果大小要与原先的组块(group chunk)一致
- 在组块中逐列操作
- 并非在组块上原位运算。原先的组块被认为是不可修改的,任何对原来组块的修改可能会导致意想不到的结果。如果你用到了
fillna,必须是grouped.transform(lambda x: x.fillna(inplace=False))
举例说明,比如说我们相对每一组数据进行标准化。当然我们先得有一组数据, 随机生成一组从1999年到2002年,然后以100天为一个滑窗(window),计算每一个滑窗的均值(rolling)。
# date_range产生日期索引
index = pd.date_range('10/1/1999', periods=1100)
ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
ts = ts.rolling(window=100,min_periods=100).mean().dropna()
然后要根据年份进行分组,对各组中的数据进行标准化,计算zscore.
# 两个匿名函数,用于分组和计算zscore
key = lambda x : x.year
zscore = lambda x : (x - x.mean())/x.std()
transformed = ts.groupby(key).transform(zscore)
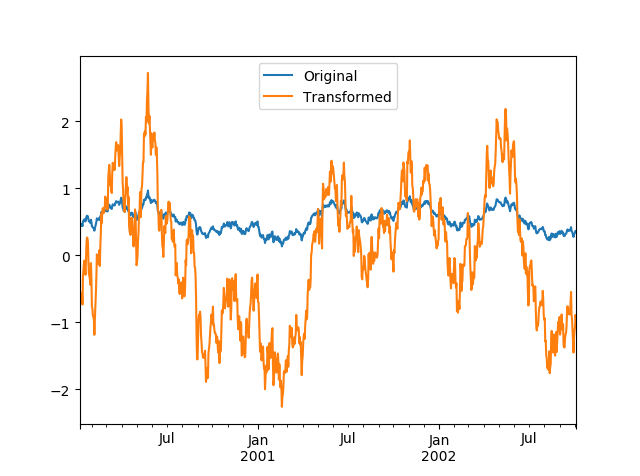
应用zscore的过程中使用了广播(broadcast)技术。让我们可视化一下转换前后数据形状
compare = pd.DataFrame({'Original': ts, 'Transformed': transformed})
compare.plot()
过滤:Filtration
过滤返回原先数据的子集。比如说上面时间周期数据,过滤掉均值小于0.55的年份。
ts.groupby(key).filter(lambda x : x.mean() > 0.55)
Apply: 更加灵活的“拆分-应用-合并”
上述的aggregate和transform都有一定的局限性,传入的函数只能有两个结果,要么是产生一个可以广播的标量值,要么是产生相同大小的数组。apply是一个更加一般化的函数,能完成上面所描述的所有任务,还能做得更好。
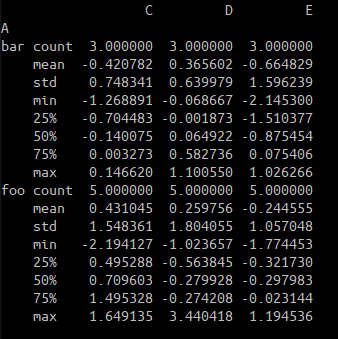
- 分组返回描述性统计结果
df.groupby('A').apply(lambda x : x.describe())
# 效果等价于df.groupby('A').describe()
- 修改返回的分组名
def f(group):return pd.DataFrame({'original' : group,'demeaned' : group - group.mean()})
df.groupby('A')['C'].apply(f)demeaned original
first second
bar one 0.278558 0.709603two 0.280707 -0.140075
baz one 1.064283 1.495328two -0.848109 -1.268891
foo one 0.064243 0.495288two 0.567402 0.146620
qux one 1.218089 1.649135two -2.625172 -2.194127
更多有用的技巧如获取每一组的第n行,见官方文档
SOTON私人定制:利用Python进行数据分析(分组运算)相关推荐
- 利用Python进行数据分析--数据聚合与分组运算
转载自:http://blog.csdn.net/ssw_1990/article/details/22422971 1.quantile计算Series或DataFrame列的样本分位数: [pyt ...
- python 数据分析学什么-利用Python做数据分析 需要学习哪些知识
根据调查结果,十大最常用的数据工具中有八个来自或利用Python.Python广泛应用于所有数据科学领域,包括数据分析.机器学习.深度学习和数据可视化.不过你知道如何利用Python做数据分析吗?需要 ...
- 541页《利用Python进行数据分析》分享(附源码下载)
1 前言 今天,StrongerTang 给大家分享一下 <利用Python进行数据分析>第二版,分享给有需要的小伙伴,也希望有更多的朋友能在StrongerTang相遇. 2 简介 &l ...
- 利用python进行数据分析——第十四章_数据分析案例
文章目录 本章中的数据文件可从下面的github仓库中下载 利用python进行数据分析(第二版) 一.从Bitli获取 1.USA.gov数据 1.1纯python时区计数 1.2使用pandas进 ...
- 利用python进行数据分析——第13章 python建模库介绍
文章目录 一.pandas与建模代码的结合 二.使用patsy创建模型描述 2.1Patsy公式中的数据转换 2.2分类数据与Patsy 三.statsmodels介绍 3.1评估线性模型 3.2评估 ...
- 数据基础---《利用Python进行数据分析·第2版》第8章 数据规整:聚合、合并和重塑
之前自己对于numpy和pandas是要用的时候东学一点西一点,直到看到<利用Python进行数据分析·第2版>,觉得只看这一篇就够了.非常感谢原博主的翻译和分享. 在许多应用中,数据可能 ...
- 数据基础---《利用Python进行数据分析·第2版》第12章 pandas高级应用
之前自己对于numpy和pandas是要用的时候东学一点西一点,直到看到<利用Python进行数据分析·第2版>,觉得只看这一篇就够了.非常感谢原博主的翻译和分享. 前面的章节关注于不同类 ...
- 数据基础---《利用Python进行数据分析·第2版》第11章 时间序列
之前自己对于numpy和pandas是要用的时候东学一点西一点,直到看到<利用Python进行数据分析·第2版>,觉得只看这一篇就够了.非常感谢原博主的翻译和分享. 时间序列(time s ...
- 数据基础---《利用Python进行数据分析·第2版》第7章 数据清洗和准备
之前自己对于numpy和pandas是要用的时候东学一点西一点,直到看到<利用Python进行数据分析·第2版>,觉得只看这一篇就够了.非常感谢原博主的翻译和分享. 在数据分析和建模的过程 ...
- 用python进行数据分析举例说明_《利用python进行数据分析》读书笔记 --第一、二章 准备与例子...
第一章 准备工作 今天开始码这本书--<利用python进行数据分析>.R和python都得会用才行,这是码这本书的原因.首先按照书上说的进行安装,google下载了epd_free-7. ...
最新文章
- Linux下golang开发环境搭建
- maven 常用插件3
- 如何通过编程方式添加Native Client服务器别名
- android 北斗定位代码_大牛三步教你解决,BAT资深APP性能优化系列-卡顿定位问题,收藏哦
- 直接输出代码_php代码:实时输出缩小的图像
- 【转】DICOM通信 - PDU数据包(2)
- Tips--解决BeatsX开机白灯闪三下无法连接问题(附拆机教程)
- Spring Cloud与微服务学习总结(9)——Spring Cloud面试题汇总
- MQTT工作笔记0009---订阅主题和订阅确认
- DOS批处理全面教程
- 扇贝和不背单词_你还没找到中意的背单词APP?我都试过,我来帮你盘点盘点
- Etcd分布式存储系统
- Java笔试通关_Java面试通关宝典
- html在手机显示时间,手机北京时间校准
- 牛客网 2018校招真题 吉比特 直线上的点
- 思科 终端服务器的配置
- matlab 还原内部函数,matlab内部函数
- 瑞星发布可防未知勒索病毒工具 将逐月公布更多漏洞
- T4M插件放入unity后怎么找不到_Unity动画系统详解4:如何用代码控制动画?
- C语言关系运算符详解