python爬取网页上的特定链接_python 用bs4解析网页后,如何循环打开爬取出来的网址链接?...
请问,用beautiful soup爬取特定网页后提取tag ‘a’,抓取里面的网址,打开特定的网址,循环特定次数,最后打印出想要的网址,如何操作?
详细的要求如下图:
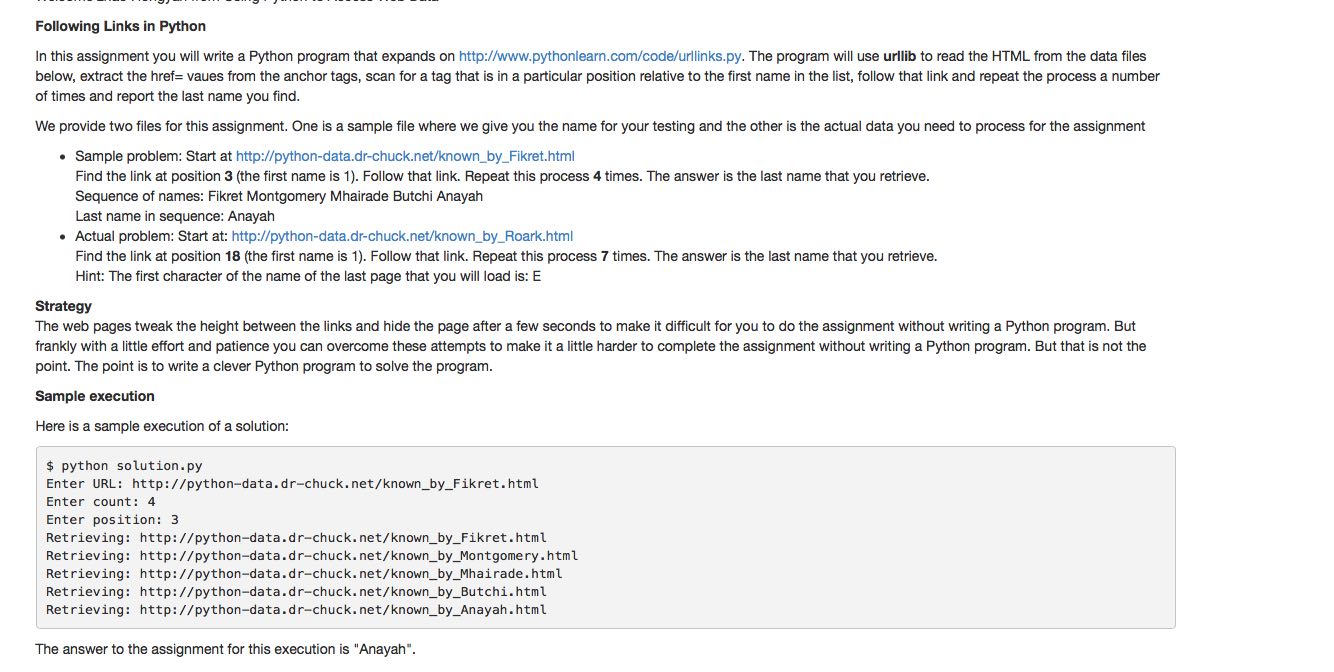
我的代码如下:
import urllib.request, urllib.parse, urllib.error
from bs4 import BeautifulSoup
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter - ')
def crawl(url):
html = urllib.request.urlopen(url, context=ctx).read()
soup = BeautifulSoup(html, 'html.parser')
position=0
count=0
tags = soup('a')
for tag in tags:
x=tag.get('href',None)
position=position+1
if position==3:break
crawl(x)
count=count+1
if count==4:break
print(x)
目前遇到的瓶颈就是,我知道如何抓取第一次输入的网址,然后也能提取出tag里面要求的内容。
但是如何打开特定的网址,然后循环特定的次数,最后打印出最终想要的网址我就不会了。求各位大牛指教。
sample problem 链接:http://python-data.dr-chuck.net/known_by_Fikret.html 打开之后是一个表格,每个表格里面的人名都是超链接,点进去每个超链接还是一个表格,也是每个人名都是超链接。
运行以上代码,结果如图: 没有任何数据,也没有报错。研究了一下午了,实在不知道哪里出了问题,请求赐教。万分感谢!

python爬取网页上的特定链接_python 用bs4解析网页后,如何循环打开爬取出来的网址链接?...相关推荐
- Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
前言 在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取.今天就教大家如何爬取手机APP上面的数据. 很多人学习python,不知道从何学起. 很多人学习python,掌握了基本语法过 ...
- 利用Python爬取爬取APP上面的数据
前言 在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取.今天就教大家如何爬取手机APP上面的数据. 环境配置 1.Fidder的安装和配置 下载Fidder软件地址:https: ...
- python爬取软件数据_利用Python爬取爬取APP上面的数据
前言 在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取.今天就教大家如何爬取手机APP上面的数据. 环境配置 1.Fidder的安装和配置 下载Fidder软件地址:https:// ...
- 手机抓包app_Python爬取网站上面的数据很简单,但是如何爬取APP上面的数据呢
前言 在我们在爬取手机APP上面的数据的时候,都会借助Fidder来爬取.今天就教大家如何爬取手机APP上面的数据. 环境配置 1.Fidder的安装和配置 下载Fidder软件地址:https:// ...
- 【Python爬虫】从零开始爬取Sci-Hub上的论文(串行爬取)
[Python爬虫]从零开始爬取Sci-Hub上的论文(串行爬取) 维护日志 项目简介 步骤与实践 STEP1 获取目标内容的列表 STEP2 利用开发者工具进行网页调研 2.1 提取文章链接和分页链 ...
- python爬取电影评分_用Python爬取猫眼上的top100评分电影
代码如下: # 注意encoding = 'utf-8'和ensure_ascii = False,不写的话不能输出汉字 import requests from requests.exception ...
- Python爬虫利用18行代码爬取虎牙上百张小姐姐图片
Python爬虫利用18行代码爬取虎牙上百张小姐姐图片 下面开始上代码 需要用到的库 import request #页面请求 import time #用于时间延迟 import re #正则表达式 ...
- python爬取文献代码_使用python爬取MedSci上的影响因子排名靠前的文献
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
最新文章
- 【汇总】一大波CVPR2020开源项目重磅来袭!
- 分解原理_基于矩阵分解原理的推荐系统
- packet tracer使用心得(二)
- 逻辑分析仪上位机DSview的简单触发设置
- 怎么查看python是多少位_python+位数
- MacOS 升级后出现 xcrun: error: invalid active developer path, missing xcrun
- android 获取phone实例,android – 可以通过sdk来实例化一个telephony.Phone对象吗?
- CADD课程学习(2)-- 靶点晶体结构信息
- MEMS传感器的下一轮技术变革
- 计算机网络2021题库
- 红帽rhce考试自带补考吗_红帽RHCE 7月考试时间通知及注意事项
- 笔顺、拼音查询小工具推介
- 安装mysql数据库和mysql客户端
- Java生成名片式的二维码源码分享
- 经验分享丨计算机专业的女孩子比较合适做什么工作?
- snprintf与_snprintf区别
- 汽车尾灯控制电路(数电课设)
- pygame实现百变魔方
- Html5新增标签总结
- python爬虫解决频繁访问_python3拉钩网爬虫之(您操作太频繁,请稍后访问)
热门文章
- php接口三结构,grape动态PHP结构(三)——API接口
- artcore html5,值得收藏的25款免费响应式网页模板_CSS_网页制作
- 10.傅里叶变换——达利画家、基集(Basis Set)、傅里叶级数(Fourier Series)_1
- c语言操作目录,c语言中目录及文件操作.doc
- 2017.9.24 三色二叉树 思考记录
- 华为公布鸿蒙2.0内测清单,华为鸿蒙操作系统2.0版支持的设备清单流出,荣耀30s...
- 【英语学习】【Level 07】U02 Live Work L5 This is where we work
- 【英语学习】【English L06】U02 Food L3 Peking roast duck
- group by很多字段是不是会很慢_3分钟短文 | MySQL在分组时,把多列合并为一个字段!
- 求最大和 java_三种算法求最大子段和问题——Java实现