Python3网络爬虫实战解析——优美壁纸爬取
在上一博客中,我们已经学会了如何使用Python3爬虫抓取文字,那么在本问中,将通过实例来教大家如何使用Python3爬虫批量抓取图片。
(1)实战背景
URL:https://unsplash.com/
![]()
上图的网站的名字叫做Unsplash,免费高清壁纸分享网是一个坚持每天分享高清的摄影图片的站点,每天更新一张高质量的图片素材,全是生活中的景象作品,清新的生活气息图片可以作为桌面壁纸也可以应用于各种需要的环境。
看到这么优美的图片,是不是很想下载做壁纸呢。每张图片我都很喜欢,批量下载吧,不多爬,就下载50张好了。
2)实战进阶
<a>标签存放超链接,图片存放在<img>标签中!既然这样,我们截取就Unsplash网站中的一个<img>标签,分析一下:
<img alt="Snow-capped mountain slopes under blue sky" src="https://images.unsplash.com/photo-1428509774491-cfac96e12253?dpr=1&可以看到,<img>标签有很多属性,有alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。
所以爬取过程为:
- 使用requeusts获取整个网页的HTML信息;
- 使用xpath解析HTML信息,找到所有<img>标签,提取src属性,获取图片存放地址;
- 根据图片存放地址,下载图片。
按这个思路爬取Unsplash试一试,编写代码如下:
import requestsif __name__ == '__main__':url = 'https://unsplash.com/'req = requests.get(url)print(req.text)按照我们的设想,我们应该能找到很多<img>标签。但是我们发现,除了一些<script>标签和一些看不懂的代码之外,我们一无所获,一个<img>标签都没有!
![]()
因为这个网站的所有图片都是动态加载的!网站有静态网站和动态网站之分,上一个实战爬取的网站是静态网站,而这个网站是动态网站,动态加载有一部分的目的就是为了反爬虫。
可以使用浏览器自带的Networks,它自然会帮我们分析JavaScript脚本执行的内容。
![]()
然而事实并没有这么简单,仔细看看,我们会发现,网页源码中只有为数不多的几个img标签,也就是说,我们只能获取到几张图片的路径,我们要的可是大量的图片,接下来将页面下滑,会发现img标签多了起来,很显然这是一个Ajax[1]动态加载的网站
3)完整代码如下:
'''
精美图片下载
'''
import requests
import json
import time
import random
from contextlib import closingclass Imgdownloader(object):#初始化def __init__(self):self.headers= {'Referer': 'https://unsplash.com/','User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) \AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36',}self.base_url = 'https://unsplash.com/napi/photos'self.img_urls = []self.page = 0self.per_page =12def get_img_urls(self):'''获取图片链接地址'''for i in range(self.per_page):self.page = self.page+i+1params={"page":self.page,"per_page":self.per_page,}res =requests.get(self.base_url,params = params)#json转换为字典res_dict = json.loads(res.text)for item in res_dict:url = item['urls']['regular']self.img_urls.append(url)#每次获取一页链接,随机休眠time.sleep(random.random())print("图片urls获取成功")def img_download(self,urls):'''下载图片到本地存储'''num = 0for url in urls:num = num + 1res = requests.get(url,headers =self.headers)img_path = str(num) +".jpg"with closing(requests.get(url,headers =self.headers,stream = True)) as res:with open(img_path,'wb') as f:print("正在下载第{}张照片".format(num))for chunk in res.iter_content(chunk_size = 1024):f.write(chunk) print("{}.jpg 下载成功".format(num))if __name__ == '__main__':#图片下载对象imgdl = Imgdownloader()print("获取图片链接中...")#对象获取图片链接imgdl.get_img_urls()print("开始下载图片:")#下载图片imgdl.img_download(imgdl.img_urls)print('所有图片下载完成')下载速度还行,有的图片下载慢是因为图片太大
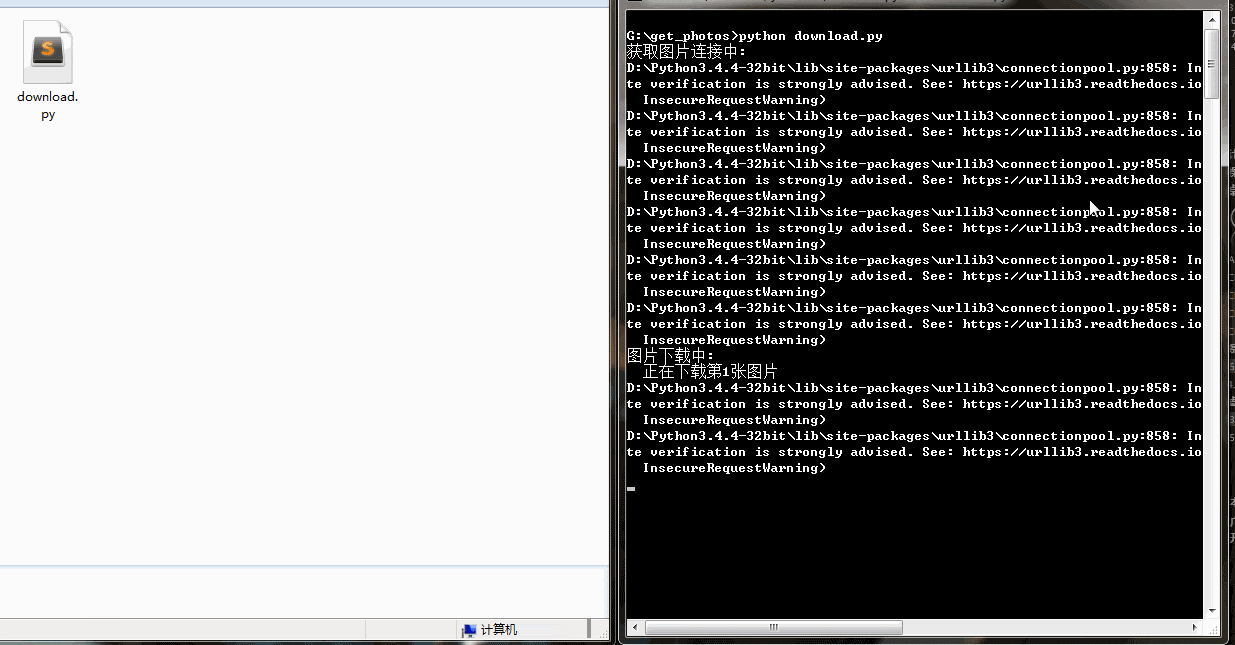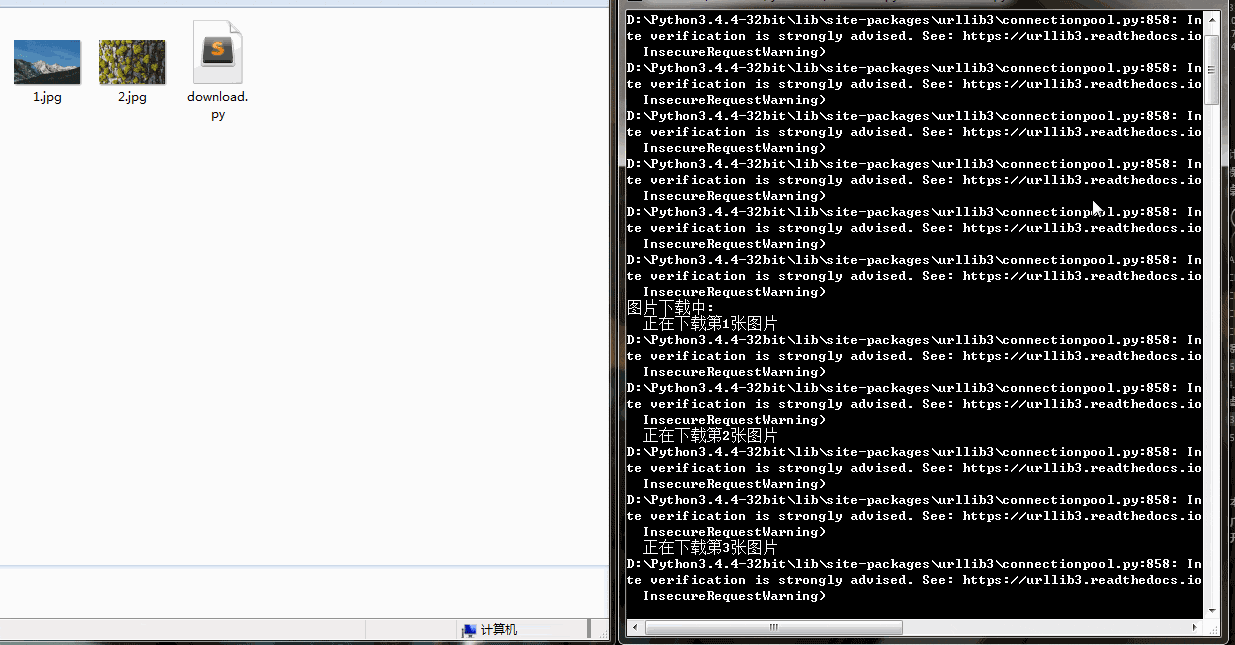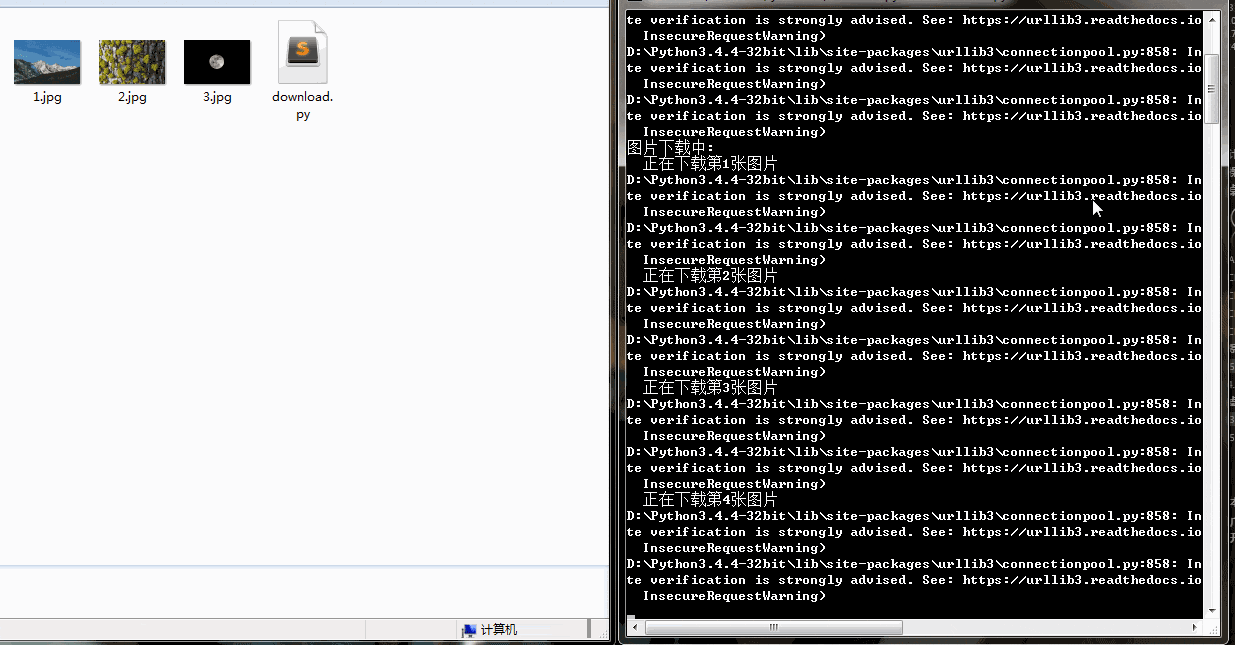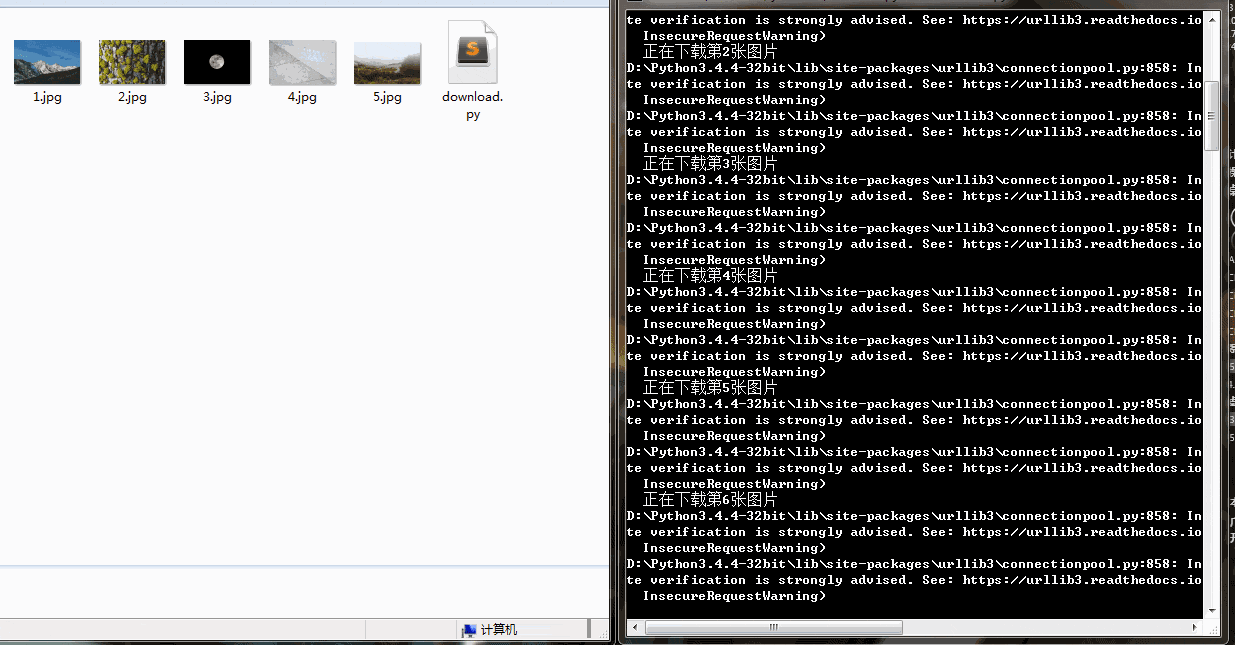
Python3网络爬虫实战解析——优美壁纸爬取相关推荐
- Python3网络爬虫(Fiddler之手机APP爬取)
运行平台: Windows Python版本: Python3.x IDE: Sublime text3 前言 实战背景 准备工作 什么是Fiddler 手机APP抓包设置 Fiddler设置 安 ...
- Python3网络爬虫:使用Beautiful Soup爬取小说
本文是http://blog.csdn.net/c406495762/article/details/71158264的学习笔记 作者:Jack-Cui 博主链接:http://blog.csdn.n ...
- 【天善学院】自己动手,丰衣足食!Python3网络爬虫实战案例 附讲义与代码 6 A+所属分类:Python教程
自己动手,丰衣足食!Python3网络爬虫实战案例 适宜人群: 萌新小白:我连爬虫也不知道是什么 入门菜鸟:我对一些爬虫的用法还不是很熟练 老司机:我想学习更高级的框架及分布式 从环境基础到进阶分布式 ...
- python基础实例 韦玮 pdf_韦玮:Python网络爬虫实战解析
2016年12月27日晚8点半,CSDN特邀IT专家.<Python系列实战教程>系列图书作者韦玮带来了主题为"Python网络爬虫反爬破解策略实战"的Chat交流.以 ...
- Python 爬虫实战,模拟登陆爬取数据
Python 爬虫实战,模拟登陆爬取数据 从0记录爬取某网站上的资源连接: 模拟登陆 爬取数据 保存到本地 结果演示: 源网站展示: 爬到的本地文件展示: 环境准备: python环境安装 略 安装r ...
- Python爬虫实战系列(一)-request爬取网站资源
Python爬虫实战系列(一)-request爬取网站资源 python爬虫实战系列第一期 文章目录 Python爬虫实战系列(一)-request爬取网站资源 前言 一.request库是什么? 二 ...
- python爬虫实战(一)--爬取知乎话题图片
原文链接python爬虫实战(一)–爬取知乎话题图片 前言 在学习了python基础之后,该尝试用python做一些有趣的事情了–爬虫. 知识准备: 1.python基础知识 2.urllib库使用 ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- Python爬虫实战之一 - 基于Requests爬取拉勾网招聘信息,并保存至本地csv文件
Python爬虫实战之二 - 基于Requests抓取拉勾网招聘信息 ---------------readme--------------- 简介:本人产品汪一枚,Python自学数月,对于小白,本 ...
最新文章
- 【linux】ARM开发板上设置RTC时间,断电重启后,设置失效的原因分析
- 工资8000与80000的区别:这个能力值得你重视!
- VMware 下扩展linux硬盘空间
- jQuery父级以及同级元素查找
- Python3不用str自带lower转换位小写字母
- hdu 1874(Dijkstra + Floyd)
- Python 算法之递归与尾递归,斐波那契数列以及汉诺塔的实现
- 王爽 汇编语言第三版 课程设计 1
- DataGridView使用技巧二:设置单元格只读
- Harmony OS — RoundProgressBar圆形进度条
- 统计叶子结点c语言,统计二叉树中叶子结点个数
- php微信开发计数,总结一个微信开发的过程实例
- 管理后台界面基本框架设计
- JavaScript:Promise进阶知识
- 微信抢红包的方案_微信抢红包怎样才能抢到最大的告诉你一个方法
- 虚拟机双硬盘安装ubuntu固态+机械
- 致爱丽丝用计算机怎么弹,致爱丽丝电子琴谱应该怎么弹
- 容联AI获AIIA智能客服最高等级认证
- 分享一些数据库使用的心得
- 中大计算机考研复试刷人太狠,为何考研初试分数很高的人在复试中被刷?这4个致命失误你犯了?...