信息量-log2P(莫斯编码使用频繁P大的字符编码段信息量少)、信息熵:期望E=-Plog2P、两点分布交叉熵=KL散度=相对熵=-plnp-(1-p)ln(1-p)不对称、JS散度对称
![]()
![]()
信息熵为什么要定义成-Σp*log§?
信息熵为什么要定义成-Σp*log(p)?
在解释信息熵之前,需要先来说说什么是信息量。
信息量是对信息的度量,单位一般用bit。
信息论之父克劳德·艾尔伍德·香农(Claude Elwood Shannon )对信息量的定义如下:

在解释这个公式之前,先看看下面的例子。
比如一个黑箱里有2个苹果,8个橙子我们把从黑箱里取苹果、橙子看成是一个随机过程,X={苹果,橙子}。
当我们了解到拿出来的是什么的时候,我们就接受到了信息,这个信息的信息量的大小与这个东西出现的概率有关,这里苹果是0.2,橙子是0.8。越小概率的事情发生,其产生的信息量越大,比如我了解到拿出来的是一个苹果所获得的信息量比一个橙子的信息量要大的多。
至于为什么越小概率的事情发生,其产生的信息量越大,可以这样理解,在考虑信息传输的过程中,如何对消息序列进行合理的编码转换成信号序列,才可以节省信道容量?
以英语举例,在电报通信中,要传送的消息由字符序列组成(比如摩尔斯电码,每个摩尔斯电码符号由一系列点和破折号组成)。
如果最常见的英文字母 E 使用最短的信道符号“一个点”来表示;而出现较少的 Q,X,Z 等则使用更多的点和破折号来表示,则可以最大程度上节省信道容量,也就是说同样的一句消息,采用此策略来编码,其传输需要的时间会更少,而事实上的电报通信中,正是这么做的。
那么这里的字母E由于出现概率最大,所以用了一个点来表示,其信息量相对最小。
所以如果我们要寻找一个函数来定义信息,则该函数要满足如下条件:
要符合随着概率的增大而减小的形式;
函数的值不能为负数,因为信息量最小为0。
带负号的对数函数显然符合以上要求,当然,肯定有其他函数也会符合以上要求,对此,香农在《A Mathematical Theory of Communication》(通信的数学理论)这篇论文中有说明选择对数函数的原因:

大意是说:
如果集合中的消息的数量是有限的,而且每条消息被选择的可能性相等,那么这个消息数或者任意这个消息数的单调函数可以用来做为从集合选择一条消息时产生的信息量的度量。而最自然的选择是对数函数。
关于对数函数更便捷的原因,论文中给出了3点:
- 在实践中更有用。
对数函数可以让一些工程上非常重要的参数比如时间、带宽、继电器数量等与可能性的数量的对数成线性关系,例如,增加一个继电器会使继电器的可能状态数加倍,而如果对这一可能状态数求以2为底的对数,结果只是加 1。加倍时间,可能的消息数会近似变成原来的平方(1,2,4,8,...),而其对数则是加倍(log2 1,log2 2,log2 4,log2 8,...)=(0,1,2,3,...) - 更贴近于人类对度量的直觉。
线性比较就是人类的度量直觉。比如,人们认为,两张打孔卡存储信息的容量应当是一张打孔卡的两倍,两个相同信道的信息传输能力应当是一个信道的两倍。 - 更适用数学运算。
许多极限运算很容易用对数表示,如果采用可能性的数目表示,可能会需要进行冗繁笨拙的重新表述。
那么,为什么选择2为底的对数呢,论文中的解释是这样的:


大致意思是说选择什么为底与用什么单位来度量信息是对应的。采用2为底就是用2进制位,英文:binary digit(香农听了J. W. Tukey的建议,将binary digit简称为bit,bit这个词从此问世)。采用10为底就是用10进制位,而在遇到一些积分和微分的分析中,用e为底有时会很有用,这个时候的信息单位称为自然单位。
个人理解就是这里用什么为底都可以,毕竟单位之间可以转换,但是为了计算方便,如果你使用二进制数字来存储信息,还是用2为底更便捷。比如一开始邮件分类的例子中,有{无聊时阅读的邮件、需及时处理的邮件、无需阅读的邮件}三种,在1000封邮件中,每个类别出现的概率分别是1/2,1/4,1/4。
现在打算用二进制位表示分类,那么就直接可以计算出来各个类别的信息量,也就是各个类别至少需要几个二进制位来表示:
无聊时阅读的邮件:-log2 (1/2) = 1,所以用1个二进制位可以表示;
需及时处理的邮件:-log2 (1/4) = 2,所以用2个二进制位可以表示;
无需阅读的邮件:-log2 (1/4) = 2,所以用2个二进制位可以表示。
那么你可能要问了,虽然计算结果是这样,但是怎么理解呢?
从直觉上理解就是,出现概率越大,信息量越少,比如明天太阳从东边升起,和明天太阳从西边升起,后者的信息量更大是符合直觉判断的;
从存储的角度来理解,对于那些出现概率越大的变量,用越少的位编码的话,就可以节省出越大的空间。
说完了信息量,我们来看看什么是信息熵。
信息量是表达某个事件需要的二进制位数,比如“某个邮件属于需及时处理的邮件”就是一个事件,而所有可能产生的信息量的期望值被定义为信息熵。
根据概率和统计学中对期望值的定义:期望值是指在一个离散性随机变量试验中每次可能结果的概率乘以其结果的总和。可以得到信息熵的公式如下:

这里可能结果的概率是某个分类出现的概率,结果是某个分类产生的信息量,其中的log一般以2为底。
可以看出,某个数据集中包含的分类越多,信息熵就越大,而包含分类多,说明这个数据集越混乱,越不纯。
因此,在一些机器学习算法比如ID3决策树中就常用信息熵来量化数据集的纯度,以选择出更好的特征来划分数据,让划分出的数据子集越来越纯,最终就可以根据多数表决来决定叶子节点的分类,从而构建出完整的分类决策树。

2 信息量、信息熵、交叉熵、KL散度、互信息、JS
首先先强烈推荐一篇外文博客Visual Information Theory这个博客的博主colah是个著名的计算机知识科普达人,之前非常著名的那篇LSTM讲解的文章也是他写的。这篇文章详细讲解了信息论中许多基本概念的来龙去脉,而且非常的直观用了大量的图片,和形象化的解释。
信息量
信息量用一个信息所需要的编码长度来定义,而一个信息的编码长度跟其出现的概率呈负相关,因为一个短编码的代价也是巨大的,因为会放弃所有以其为前缀的编码方式,比如字母”a”用单一个0作为编码的话,那么为了避免歧义,就不能有其他任何0开头的编码词了.所以一个词出现的越频繁,则其编码方式也就越短,同时付出的代价也大.
信息熵
而信息熵则代表一个分布的信息量,或者编码的平均长度
即信息量的均值
交叉熵 cross-entropy
交叉熵本质上可以看成,用一个猜测的分布的编码方式去编码其真实的分布,得到的平均编码长度或者信息量
如上面的式子,用猜的的p分布,去编码原本真是为q的分布,得到的信息量
交叉熵 cross-entropy在机器学习领域的作用
交叉熵cross-entropy在机器学习领域中经常作为最后的损失函数
为什么要用cross-entropy呢,他本质上相当于衡量两个编码方式之间的差值,因为只有当猜测的分布约接近于真实分布,则其值越小。
比如根据自己模型得到的A的概率是80%,得到B的概率是20%,真实的分布是应该得到A,则意味着得到A的概率是100%,所以
在LR中用cross-entry比平方误差方法好在:
- 在LR中,如果用平方损失函数,则损失函数是一个非凸的,而用cross-entropy的话就是一个凸函数
- 用cross-entropy做LR求导的话,得到的导数公式如下
∂L∂θj=−∑i(yi−p(xi))xij∂L∂θj=−∑i(yi−p(xi))xij
而sigmoid函数的导数会出现梯度消失的问题【一些人称之为饱和现象】
KL散度
KL散度/距离是衡量两个分布的距离,KL距离一般用D(q||p)D(q||p)称之为q对p的相对熵
KL散度与cross-entropy的关系
用图像形象化的表示二者之间的关系可以如下图:
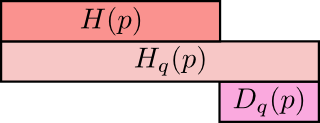
上面是q所含的信息量/平均编码长度H(p)H(p)
第二行是cross-entropy,即用q来编码p所含的信息量/平均编码长度|或者称之为q对p的cross-entropy
第三行是上面两者之间的差值即为q对p的KL距离
非负性证明
根据上图显然其为非负的,但是怎么去证明呢,还是利用琴生不等式
非负性证明完成
联合信息熵和条件信息熵
下面几条我们要说的是联合分布中(即同一个分布中)的两个变量相互影响的关系,上面说的KL和cross-entropy是两个不同分布之间的距离度量【个人理解是KL距离是对于同一个随机事件的不同分布度量之间的距离,所以是1.同一随机事件*2.不同分布*】。
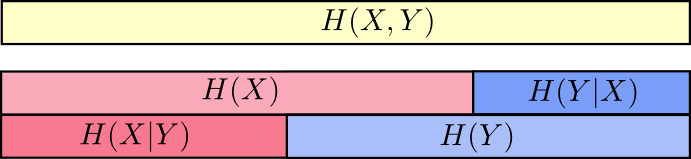
联合信息熵:
根据上面那个图,也可以通俗的理解为已知X的情况下,H(X,Y)剩余的信息量
互信息(信息增益)
互信息就是一个联合分布中的两个信息的纠缠程度/或者叫相互影响那部分的信息量
决策树中的信息增益就是互信息,决策树是采用的上面第二种计算方法,即把分类的不同结果看成不同随机事件Y,然后把当前选择的特征看成X,则信息增益就是当前Y的信息熵减去已知X情况下的信息熵。
通过下图的刻画更为直观一些
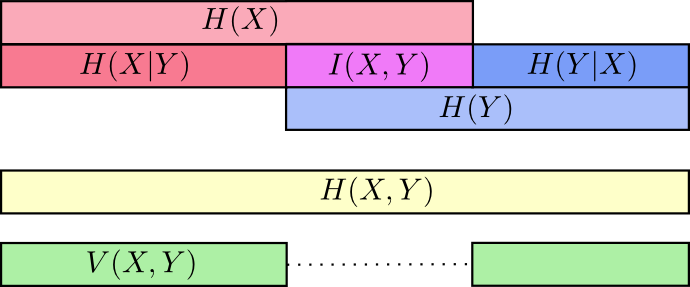
以上图可以清楚的看到互信息I(X,Y)I(X,Y)说明这两个变量是完全一致的,其约大说明两个变量越独立。
这里再注意一下Variation of information和KL距离的差别:
Variation of information是联合分布中(即同一个分布中)的两个变量相互影响的关系
KL和cross-entropy是两个不同分布之间的距离度量
非负性证明
学习参考[https://blog.csdn.net/u011984148/article/details/99439576](https://blog.csdn.net/u011984148/article/details/99439576)
一般情况是D(G)=0.5导致D_loss=-log0.5-log0.5.但是D目的是D(G)=0,进一步D_loss变大=0(分析D(art)=1,D(gan)=0,所以log(D(art)=1)=0, log(1-D(G))=log(1)=0,。。。)
交叉熵loss(二元)
![]()
熵是表示信息的混乱程度
![]()
KL散度相对熵,但不是距离因为Dkl(p-q)不等于Dkl(q-p)
JS散度,优化KL,使距离对称且值域(0,1)
![]()
损失函数分开分析:设伪造的是0,后者是提升G欺骗D的损失,minG梯度下降
信息量−log2P(x)-log_2P(x)−log2P(x)的期望就是熵:Elog(P(x))=−1N∑i=0Nlog(Px)Elog(P(x)) =- \frac{1}{N}\sum_{i=0}^Nlog(P_x)Elog(P(x))=−N1∑i=0Nlog(Px)
![]()
![]()
联合熵H(x,y)H(x,y)H(x,y)
条件熵H(x,y)−H(x)=H(y∣x))H(x,y)-H(x)=H(y|x) )H(x,y)−H(x)=H(y∣x))
互信息:I(x,y)=H(y)−H(y∣x)I(x,y)=H(y)-H(y|x)I(x,y)=H(y)−H(y∣x),带入替换条件熵得到
I(x,y)=H(x)+H(x)−H(x,y)I(x,y)=H(x)+H(x)-H(x,y) I(x,y)=H(x)+H(x)−H(x,y)
Veen图
![]()
交叉熵就是相对熵:两个分布的距离Kullback-Leible(KL散度)
概率=频率(从分布中得出概率)
GAN中D的loss就是交叉熵
![]()
信息量-log2P(莫斯编码使用频繁P大的字符编码段信息量少)、信息熵:期望E=-Plog2P、两点分布交叉熵=KL散度=相对熵=-plnp-(1-p)ln(1-p)不对称、JS散度对称相关推荐
- 【转】刨根究底字符编码之十——Unicode字符集的字符编码方式
一.字符编码方式CEF的选择 1. 由于Unicode字符集非常大(并且作为开放字符集还在不断扩展之中),有些字符的编号(即码点值)需要两个或两个以上字节来表示,而要对这样的编号进行编码,也必须使用两 ...
- python转换字符编码_转:Python常见字符编码及其之间的转换
一.Python常见字符编码 字符编码的常用种类介绍 第一种:ASCII码 ASCII(American Standard Code for Information Interchange,美国信息交 ...
- python字符编码使用的是什么编码_不可不知的Python字符编码使用技巧(上)
Python语言在网络爬虫领域应用的十分广泛.在爬虫的应用程序中,我们需要对网页上获取的数据进行处理,其中字符的编码.解码常常让人感到困惑:ASCII码.Unicode.字符编码什么的,很多朋友一直为 ...
- 【转】刨根究底字符编码之四——EASCII及ISO 8859字符编码方案
1. 计算机出现之后,首先逐渐从美国发展到了欧洲.由于欧洲很多国家所用到的字符中,除了基本的.美国也用的那128个ASCII字符之外,还有很多衍生的拉丁字母等字符.比如,在法语中,字母上方有注音符号: ...
- mysql修改客户端编码命令_mysql命令行修改字符编码
1.修改数据库字符编码 mysql> alter database mydb character set utf8 ; 2.创建数据库时,指定数据库的字符编码 mysql> create ...
- java修改默认字符编码_设置默认的Java字符编码?
如何以编程方式正确设置JVM(1.5.x)使用的默认字符编码? 我已经读过-Dfile.encoding =以前是以往的方式去为旧的JVM -我没有那么奢侈的原因,我不会进入. 我努力了: Sys ...
- 关于python字符编码_关于python文件的字符编码
# -*- coding: utf-8 -*-字符编码是啥? 在弄清楚字符编码是啥之前我们要先考虑一个问题.如果计算机最基础的就是0和1,那么他们是如何识别我们输入的英文字母和数字的. 下面是数学知识 ...
- mysql编码修改utf8_修改数据库mysql字符编码为UTF8
MySQL会出现中文乱码的原因不外乎下列几点: 1.server本身设定问题,例如还停留在latin1 2.table的语系设定问题(包含character与collation) 3.客户端程式(例如 ...
- mysql 导入设置编码_MySQL导入或导出数据库字符编码集设置
解决方法: 开始-->运行-->cmd -->进入dos命令窗体:(如果命令无法执行,请将mysql的安装路径放到系统变量path的最前面) 1. 数据库表中字段的字符集设置 .sh ...
最新文章
- linux 并行计算命令,Linux下的并行神器——parallel
- 面试官,求你了别再问我TCP三次握手和四次挥手了(含面试题)
- 机器学习实战的P264中代码对应的公式推导
- C语言。自定义函数简单版
- decimal转为string sql_PHP+Mysql防止SQL注入的方法
- python的回收机制_Python的垃圾回收机制深入分析
- [eZ publish] fetch_alias() and fetch()
- C++中两个类中互相包含对方对象的指针问题
- 手机安装python3.5_CentOS 7安装Python3.5
- android(安卓)开源框架——六款【转】
- html邮件签名制作,制作自己的个性化电子邮件签名
- 华为手机如何安装Goole play教程及安装包
- 杰理之ifi_camera跑sfc的启动时间【篇】
- 小红书怎么看关键词排名?如何提升笔记自然搜索排名
- cocos2dx win32修改鼠标指针图案
- 大数据实际案例系列一
- linux中安装mysql无法启动不了_Linux中安装mysql之后 mysql服务不能启动是怎么回事?...
- 美颜SDK全身美颜是基于什么技术实现的?
- 双足竞走机器人的意义_双足步行机器人
- 【独行秀才】macOS Monterey 12.2.1正式版(21D62)原版镜像