超标量处理器设计——第二章_Cache
超标量处理器设计——第二章_Cache
参考《超标量处理器》姚永斌著
文章目录
- 超标量处理器设计——第二章_Cache
- Cache的一般设计
- 2.1.1 cache组成方式
- 2.1.2 Cache的写入
- 2.1.3 Cache的替换策略
- 1. LRU (Least Recently Used)
- 2. 随机替换
- 2.2 提高Cache的性能
- 2.2.1 写缓存
- 2.2.2 写D-Cache流水线
- 2.2.3 多级结构
- 2.2.4 Victim Cache
- 2.2.5 Filter Cache
- 2.2.5 预取
- 2.3 多端口Cache
- 2.3.1 True Multi-port
- 2.3.2 Multiple Cache Copies
- 2.3.3 Multi-banking
- 2.3.4 AMD Opteron的多端口Cache
- 2.4 超标量处理器的取指令
Cache的一般设计

- Cache缺失(miss)的3C定理:
- Compulsory , 第一次访问失效
- Capcity, 由于cache满引发的miss
- Conflict, 有多个数据映射到cache同一个位置
2.1.1 cache组成方式
直接映射:

- 对所有index相同的存储地址, 会寻址到同一个cache line
组相连:

对所有index相同的存储地址, 会寻址到多个cache line
n-way的组相连结构一个index对应n个line, 这些line称为一个cache set
可以显著降低cache miss
因为需要从set中比较得到一个line, 延迟较大
tag和data通常分成两个SRAM, 称为tag sram 和data sram
- 并行访问:


- 串行访问:


- 串行访问虽然增加了一拍延时, 但是省掉了way mux ,节省功耗, 可以提升流水频率
- 增加的一拍延时, 在乱序机中可以填充其他指令, 性能影响不大;但是对顺序机而言可能会降低性能
- 全相连

- 没有index, 一个地址的数据可以在cache的任意位置找到
- 将tag与所有cache line比较
- 相当与CAM 内容寻址存储器(Content Address Memory)
- 一般TLB采用这种结构
2.1.2 Cache的写入
一般I-Cache不会直接写入内容, 即使程序有self-modifying自修改的情况, 也是先把改写的指令写入D-Cache, 将D-cache内容写回下级存储器, 之后将I-cache所有内容置为无效, 这样处理器再次执行就会发生miss, 迫使I-cache从下级存储取指令
写D-cache的方式:
- 写通(Write-Through): 数据写到D-Cache的同时, 也写到下级存储器
- 写回(Write-Back): 通过脏位标记D-cache中被修改的line, 当该line要被替换时才将其写到下级存储器
写D-Cache时发生写miss:
- Non-Write Allocate : 直接将要写的内容写到下级存储器, 不写到D-Cache中
- Write Allocate: 先从下级存储器中将发生缺失的地址对应的数据块取出, 与要写入到D-cache中的数据合并后再将该数据写入D-Cache
写通一般配合Non-Write Allocate; 写回则一般配合Write Allocate:

写回+Write Allocate的方法相对而言可以减少对下级存储器的访问频率

2.1.3 Cache的替换策略
- 替换发生在某个Cache set中所有的line都满了的情况
1. LRU (Least Recently Used)
为每个Cache line设置一个年龄部分, 每当way被访问, 年龄部分就会增加, 年龄最小的way就是要被替换的way
实际实现是通常采用PLRU(Pesudo Least Recently Used):

对于8个way的Cache, 需要三级年龄位, 每个年龄位为0表示标号小的那些way最近未被使用, 为1表示编号大的那一组最近未被使用
每次访问某个way都会更新三级年龄位
代码实例[[PLRU-伪LRU的一种优雅实现方式]]
2. 随机替换
- 一般采用时钟算法, 开一个计数器, 计数宽度等于Cache的相关度, 每个时钟周期加一, 需要替换时就用当前的计数值选择替换的way
2.2 提高Cache的性能
2.2.1 写缓存
- 起因: L2-Cache一般只有一个读写端口, 当D-Cache发生缺失, 需要从下级存储读取数据, 并写道Cache line中, 如果这个line是脏的, 需要先将其写回下级存储. 所以对L2-Cache的需要先写再读, 串行完成. 这样增加了从下级存储读入数据到Cache的延迟
- 解决: (写延迟策略) 增加一个write buffer, 当脏的line需要写回时先放到write buffer中, 等到下级存储有空的时候才会将write buffer中的数据写回夏季存储

- 对于写通类型的缓存, 写下级存储的次数较多, 因此写缓存较为重要
- 缺陷: 会增加复杂度, 因为写缓存中也要加入地址比较CAM电路, D-Cache发生缺失时, 不仅要从下级存储器查找,还需要从写缓存中查找最新数据
PS. 写延迟的方法用处很多, 例如可以据此实现单端口SRAM的FIFO:
[[FIFO那些事儿——单端Sram实现的同步FIFO]]
2.2.2 写D-Cache流水线
- 对读Cache来说, 可以实现tag和data的读取并行
- 写Cache需要先比较tag, 通过之后才能写入data, 所以需要串行

- 当sw后紧接着一条ld, 此时ld的地址可能正好在Delayed Store Data寄存器中, 因此上述流水线添加了一个旁路, 可以将load data直连到Delayed store data寄存器上
2.2.3 多级结构

一般L2 Cache会采用Write Back
对于多核处理器, L1 Cache采用Write Through可以简化流水线
Inclusive和Exclusive:
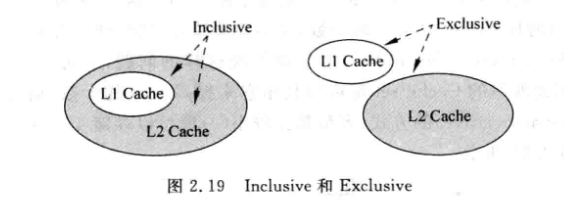
Exclusive : 避免浪费, 可以获得更大的Cache可用容量, 提高处理器性能
Inclusive : 写数据时可以直接写入L1 Cache, 不需要再读下级存储出来合并后再写入, 且一致性管理更简单
2.2.4 Victim Cache

如果cache中被踢出的数据马上又要被用, 又不能增加cache的way数, 可以采用VC
VC用于保存最近被踢出的数据, 本质是相当与增加了way数:

一般VC是全相连的, 容量较小(4-16)
VC相当于是L1-cache的一个Exclusive Cache
2.2.5 Filter Cache
VC是在L1 Cache之后, 而FC是在L1 Cache之前, 当一个数据第一次被使用, 不会放到L1 中,而是放到FC中, 再次被使用才会放入Cache

可以过滤一些偶然使用的数据
2.2.5 预取
- 硬件预取:
指令是很容易预取的(顺序特性), 通常可以将指令预取一部分到一个buffer

对于数据的预取, 通常是将要访问的数据的下一个数据快也预取出来
- 软件预取:
- 编译器知道程序的细节, 所以可以通过编译器控制程序进行预取
2.3 多端口Cache
- 超标量处理器一次可以取出多条指令, 因此需要多端口的Cache
2.3.1 True Multi-port
SRAM中的每个Cell都需要支持两个读端口

面积, 延时, 功耗都会增大, 一般不会这么使用
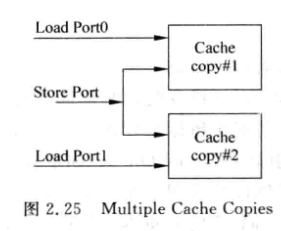
2.3.2 Multiple Cache Copies
- 直接复制一份, 相当于pingpong
- 面积和功耗浪费都更大
2.3.3 Multi-banking
将Cache分成多个bank, 每个bank都只有一个端口, 只要保证一个周期内Cache的访问地址们不在同一个bank中即可

可以增加bank数来减少bank冲突
2.3.4 AMD Opteron的多端口Cache

- 数据块分成8个bank
- 2-way, 两路的电路采用复制的方法
- Virtually-indexed, Physicaly-tagged, 直接使用VA寻址Cache

2.4 超标量处理器的取指令

- 对于一个32位n-way的超标量处理器(一个周期可以取n条指令),如果取指令地址是n字对齐的, 那么就可以一个周期取出n条指令
- 实际情况是取指令很可能不是n个字对齐的,例如分支跳转到一个非n字对齐的地址。此时一次只能从cache line中读出一部分fetch group:

- 通常取指会将取出来的指令放到指令缓存(Instruction Buffer)中, 这样可以保证即使某一次没有取出一个完整fetch group的指令, 仍能保证后续流水线能被取到足够的指令
- 当第一条指令位于00位置, 一次可以取4条;当位于01, 一次可以取3条…可以推算出这种类型的cache每个周期可以取指的个数是1/4*4+1/4*3+1/4*2+1/4*1 = 2.5, 对于一个4-way的处理器来说就不太够了
- 当然上面的分析是基于四种情况都是等概率事件发生的,而实际上过于悲观, 因为某次不对齐取指后,下一次就是对齐的了;也就是说实际每周期取指个数>2.5
- 如何提升每周期取指个数?
- 一种方式是增加每个line的数据量,例如一个拥有8字的line的cache,它的每周期平均指令个数是3.25
- 仍然采用4个字的line, 但让每个tag管两行line,通过一个重排逻辑得到正确顺序的4条指令(处理跨行的情况):

公众号已开通,想了解更多相关内容可以扫一扫下方二维码~

超标量处理器设计——第二章_Cache相关推荐
- 超标量处理器设计——第七章_寄存器重命名
超标量处理器设计--第七章_寄存器重命名 参考<超标量处理器>姚永斌著 文章目录 超标量处理器设计--第七章_寄存器重命名 7.1 简述 7.2 寄存器重命名方式 7.2.1 用ROB进行 ...
- 超标量处理器设计——第四章_分支预测
超标量处理器设计--第四章_分支预测 参考<超标量处理器>姚永斌著 4.1 简述 分支预测主要与预测两个内容, 一个是分支方向, 还有一个是跳转的目标地址 首先需要识别出取出的指令是否是分 ...
- 超标量处理器设计——第十章_提交
参考<超标量处理器>姚永斌著 文章目录 超标量处理器设计--第十章_提交 10.1 概述 10.2 重排序缓存 10.2.1 一般结构 10.2.2 端口需求 10.3 管理处理器的状态 ...
- linux系统管理设计ppt,操作系统原理与Linux实例设计--第二章.ppt
操作系统原理与Linux实例设计--第二章.ppt 2.5.4 实时系统与实时任务调度 实时系统与实时任务 实时系统:能及时响应外部请求,并作出反应的系统. 是一个相对的概念. 是否周期执行来划分: ...
- 超标量处理器设计——第八章_发射
超标量处理器设计--第八章_发射 参考<超标量处理器>姚永斌著 文章目录 超标量处理器设计--第八章_发射 8.1 简述 8.1.1 集中式 VS. 分布式 8.1.2 数据捕捉 VS. ...
- 超标量处理器设计 姚永斌 第8章 指令发射 摘录
8.1 概述 何为发射?它就是将符合一定条件的指令从发射队列issue queue中选出来,并送到FU中执行的过程.发射队列页可以叫做保留站reservation station. 发射队列会按照一定 ...
- 超标量处理器设计 姚永斌 第9章 指令执行 摘录
9.1 概述 执行阶段负责指令的执行,在流水线的之前阶段做了那么多的事情,就是为了将指令送到这个阶段进行执行.在执行阶段,接受指令的源操作数,对其进行规定的操作,例如加减法.访问存储器.判断条件等,然 ...
- 单片机原理与应用设计第二章(AT89S51)
目录 目录 一.硬件组成 AT89S51单片机片内结构 AT89S51引脚功能 3.并行I/O口引脚 P0口 P0口:地址/数据总线 数据输出 数据输入 P0口:通用输入输出功能 P1口 P2组I/O ...
- 思科—计算机网络课程设计—第二章静态路由概念测试
题目一 哪条 IPv6 静态路由将作为通过 OSPF 学习的动态路由的备份路由? 选择一项: Router1(config)# ipv6 route 2001:db8:acad:1::/32 2001 ...
最新文章
- 使用kuberbuilder创建工程示例
- 北京活动:4月20号《科技媒体、SEO与PM》主题活动
- 什么是长期存储在计算机外存上的有结构,数据库是长期存储在计算机主存内
- php angular使用,如何使用angular.js PHP从mysql显示数据?
- python中通过pip安装套件
- 在 TableLayoutPanel 控件中对齐和拉伸控件
- 测试基础-01-软件测试的定义与分类
- 安装sphinx的心得和错误处理
- 思科室外AP无法注册到WLC
- ## 数据结构之单向链表的基本操作详细总结 爆肝总结超详细万字长文C语言版
- 企业信息安全整体架构
- Linux tcpdump命令实战
- Alcor(安国)AU6983量产工具(100421)量产成功教程
- imu 里程计融合_视觉里程计IMU辅助GPS融合定位算法研究
- android手机控制家用电器,手机遥控电脑!教你用手机控制家里电脑
- 二叉树、满二叉树、完全二叉树、平衡二叉树、二叉排序树、线索二叉树
- 超有爱的并查集 6666
- 工作笔记:如何用Django连接Kerberized甲骨文(Oracle)数据库
- MTK6735 竖屏横用、旋转90度、MTK_LCM_PHYSICAL_ROTATION
- 最小生成树(普里姆算法)
热门文章
- stm32 软件怎么设置写保护_STM32F407 读保护,写保护,解锁过程【芯片已设置读保护,无法读取更多信息】...
- QQ概念版试用体会(转)
- 如何在本地搭建一个EasyPlayer的H5 demo 播放H265视频流?
- Jenkins的简单使用,小白式教程
- 《操作系统真象还原》第二章 ---- 编写MBR主引导记录 初尝编写的快乐 雏形已显!
- 嵌入式SQL数据库连接简便操作
- Ubuntu配置git的比较工具-Meld
- 邮件推广遇到每天只能发100封的限制,已解决,看这一篇就够了!
- 中年百度,舒适又失落的前半生
- php页面表格导出excel表格数据类型,php页面表格导出excel表格数据类型-php导出excel是不是导出整个表的?可不可以导出指......