HashMap源码分析-jdk1.6和jdk1.8的区别
2019独角兽企业重金招聘Python工程师标准>>> 
在java集合中,HashMap是用来存放一组键值对的数,也就是key-value形式的数据,而在jdk1.6和jdk1.8的实现有所不同。
JDK1.6的源码实现:
首先来看一下HashMap的类的定义:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, SerializableHashMap继承了AbstractHashMap,实现了Map,Cloneable和Serializable接口,Map定义了一些公共的接口,而AbstractHashMap也实现了Map接口,并提供了一些默认的实现,如size方法和isEmpty方法等
在HashMap中,定义了几个常量:
static final int DEFAULT_INITIAL_CAPACITY = 16初始容量,如果在创建HashMap的时候没有指定容量,就使用初始容量
static final int MAX_CAPACITY = 1 << 30最大容量,HashMap中存储元素的数组的最大的容量,为2的30次方
static final float DEFAULT_LOAD_FACTOR = 0.75F默认的加载因子,在扩容的时候使用
transient Entry[] table最重要的一个常量,用来存放我们添加的元素,
int threshold阈值,用来判断HashMap是否需要扩容,如果添加的元素超过该值,则需要扩容, 该值等于 capacity * loadFactor,比如 默认的初始容量为16, 默认的加载因子为0.75,则阈值就等于16*0.75=12,在table数组中,如果数组的元素个数超过12,则table数组就需要进行扩容。
HashMap提供了三个构造方法,我们可以指定初始容量和加载因子来构造HashMap
public HashMap(int initialCapacity, float loadFactor)也可以只指定初始容量来构造HashMap
public HashMap(int initialCapacity)也可以都不指定,这时,初始容量和加载因子都是用的默认的值,一般情况下也不会去指定初始容量和加载因子。
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);table = new Entry[DEFAULT_INITIAL_CAPACITY];//该方法是一个钩子方法,是一个空方法init();}如果采用不带参数的构造方法,可以看到存放元素的初始数组的大小为16,阈值为12。
相当于 Entry[] table = new Entry[16],在HashMap内部使用 Entry数组来存放元素的。
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;final int hash;//省略其他的代码}可以看到Entry表示的是一个单向链表的结构,next就是指向下一个节点;也就是说在HashMap内部,使用数组+链表的形式来存放元素,数组的每一项就是一个链表。HashMap的结构图大致如下所示:
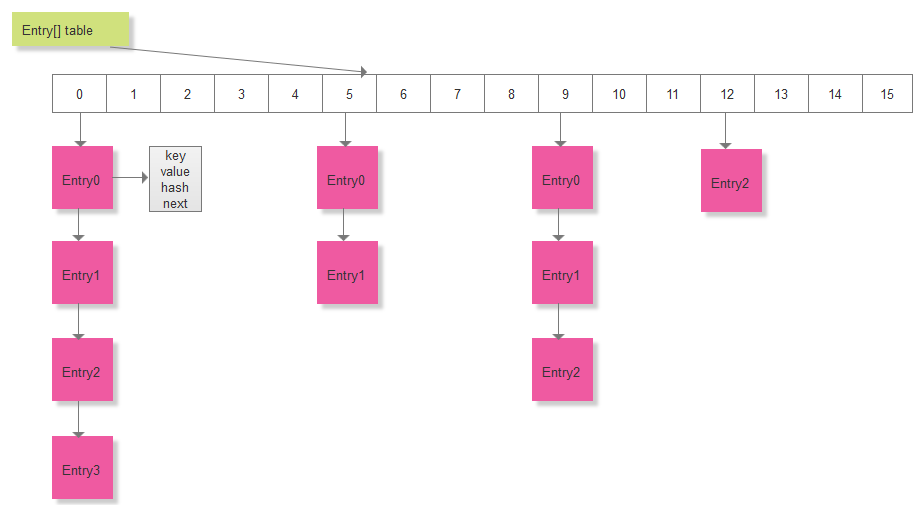
接下来看一下对HashMap的常用操作:
1. put(key, value)操作,向HashMap中添加元素
1)添加的时候,首先要计算key的hash值,找到对应数组的下标
2)找到该下标对应的数组位置的链表,遍历链表,把值添加到该链表上
public V put(K key, V value) {if (key == null)return putForNullKey(value); // 对key为null的处理,HashMap的key可以为null,但只有一个int hash = hash(key.hashCode()); //根据key计算出hash值int i = indexFor(hash, table.length); // 根据hash值和数组长度计算数组的下标,添加的元素就在该位置上//之后,取得该数组位置上的链表//遍历链表,如果key已经存在了,则用新的值替换旧的值并返回旧的值for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;// 如果key不存在,则会在该链表上添加一个新的Entry节点addEntry(hash, key, value, i);return null;}addEntry()方法如下:
void addEntry(int hash, K key, V value, int bucketIndex) {//把该位置上的链表赋给一个临时变量,Entry<K,V> e = table[bucketIndex];//之后,用新添加的key和value来创建一个新的Entry节点,把该节点的下一个节点指向这个临时变量table[bucketIndex] = new Entry<K,V>(hash, key, value, e);//判断数组是否需要扩容,resize方法是对数组进行扩容if (size++ >= threshold)resize(2 * table.length);}用图来说明:
1. 初始化一个空的HashMap,此时还没有元素,结构如下:

假设要添加一对数据:key="zs", value="zhangsan"
首先对 key进行hash,比如 hash之后的值为5,之后在用hash和table.length来求数组的索引,
比如索引 i = 4,此时,这对元素就应该在 table[i] 即 table[4] 的位置处,取得该处的Entry链表,此时,链表为空,创建一个Entry节点,加入到该空链表中:
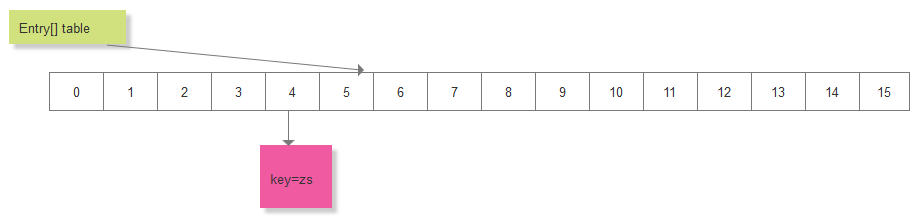
此时,在添加一对元素:key="ls", value="lisi",假如计算的索引 i 恰好等于4,此时,取得 table[4] 处的链表 Entry<K, V> = table[4], 用key = "ls"在这个链表上进行遍历,看看是否该key已存在:
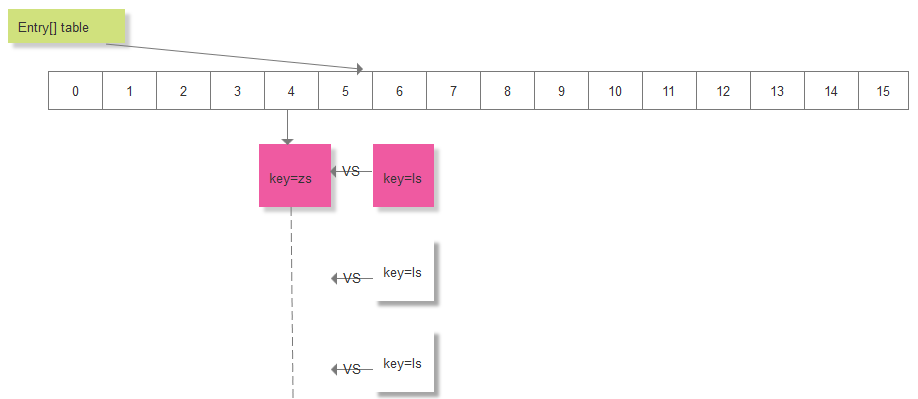
此时,key="ls"并不存在,又会创建一个Entry节点,加入到该列表中:
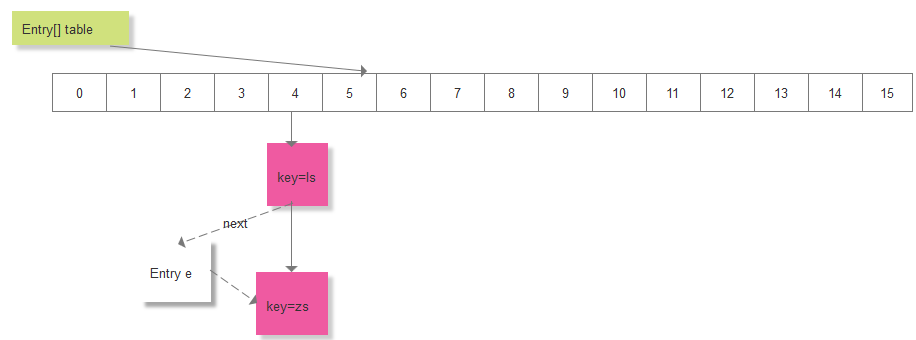
如果此时,又添加 key="zs", value="zhangsan222",根据key计算到的索引为4,取出 table[4]处的链表,遍历链表,然后检查对应的key是否存在,检查到key已经存在了,所以会把新的值替换旧的值即可,不用创建新的节点。
2.get(key)操作
1)根据key计算hash值,根据hash值和数组长度计算数组的下标索引
2)取得该下标对应的链表,遍历链表,找到key对应的value
public V get(Object key) {if (key == null)return getForNullKey(); //key为null的键,单独处理,返回对应的值int hash = hash(key.hashCode());//计算hash值for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k)))return e.value;}return null;}3.remove()操作,
1)根据key计算hash值,根据hash值和数组长度计算数组的下标索引
2)取得该下标对应的链表,遍历链表,删除key对应的Entry节点
public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);return (e == null ? null : e.value);}removeEntryForKey()方法如下:
final Entry<K,V> removeEntryForKey(Object key) {int hash = (key == null) ? 0 : hash(key.hashCode());int i = indexFor(hash, table.length);Entry<K,V> prev = table[i];Entry<K,V> e = prev;while (e != null) {Entry<K,V> next = e.next;Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {modCount++;size--;if (prev == e) // 表示删除的是第一个Entry节点table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}// 如果为null,直接返回return e;}假设现在HashMap中元素的分布如下:
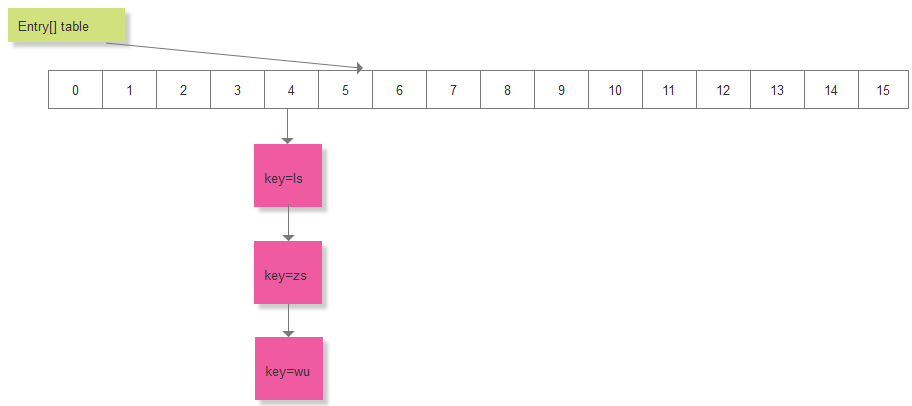
要删除 key="ls"的元素,假如计算的索引 i=4,要去遍历 table[4]处的链表,删除对应的节点,key="ls"为链表的第一个节点:
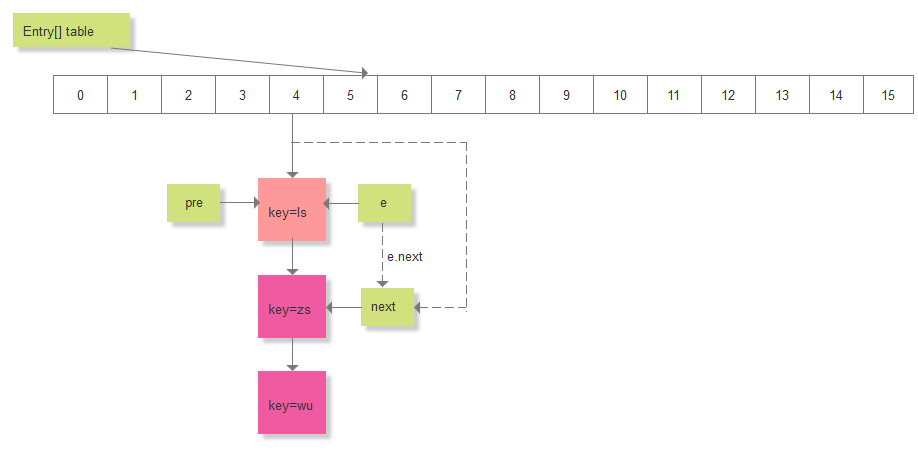
以上就是jdk1.6中HashMap的实现,是基于数组+链表的形式来存放数据的。
JDK1.8的源码实现:
在JDK1.8中,HashMap的实现比1.6的实现要复杂得多,1.8中引入了红黑树的数据结构;
除了上面列出来的常量外,新增加了几个常量:
static final int TREEIFY_THRESHOLD = 8;表示的是,如果数组中链表的元素大于该值,则需要把该链表转化为红黑树,
static final int UNTREEIFY_THRESHOLD = 6;如果链表中的元素个数小于该值,则把红黑树转换为链表
在JDK1.6中,使用一个Entry数组来存放元素,而在JDK1.8中,使用的Node数组和TreeNode来存放元素,
Node:其实,Node和Entry没有什么区别,
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}TreeNode:表示的是一个红黑树结构
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {TreeNode<K,V> parent; // red-black tree linksTreeNode<K,V> left;TreeNode<K,V> right;TreeNode<K,V> prev; // needed to unlink next upon deletionboolean red;TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}}
转载于:https://my.oschina.net/mengyuankan/blog/1618077
HashMap源码分析-jdk1.6和jdk1.8的区别相关推荐
- 查询已有链表的hashmap_源码分析系列1:HashMap源码分析(基于JDK1.8)
1.HashMap的底层实现图示 如上图所示: HashMap底层是由 数组+(链表)=(红黑树) 组成,每个存储在HashMap中的键值对都存放在一个Node节点之中,其中包含了Key-Value ...
- 源码分析系列1:HashMap源码分析(基于JDK1.8)
1.HashMap的底层实现图示 如上图所示: HashMap底层是由 数组+(链表)+(红黑树) 组成,每个存储在HashMap中的键值对都存放在一个Node节点之中,其中包含了Key-Value ...
- Java类集框架 —— HashMap源码分析
HashMap是基于Map的键值对映射表,底层是通过数组.链表.红黑树(JDK1.8加入)来实现的. HashMap结构 HashMap中存储元素,是将key和value封装成了一个Node,先以一个 ...
- 在参考了众多博客之后,我写出了多达三万字的HashMap源码分析,比我本科毕业论文都要精彩
HashMap源码分析 以下代码都是基于java8的版本 HashMap简介 源码: public class HashMap<K,V> extends AbstractMap<K, ...
- hashmap源码分析及常用方法测试_一点课堂(多岸学院)
HashMap 简介 底层数据结构分析 JDK1.8之前 JDK1.8之后 HashMap源码分析 构造方法 put方法 get方法 resize方法 HashMap常用方法测试 感谢 changfu ...
- HashMap 源码分析与常见面试题
文章目录 HashMap 源码分析 jdk 1.7 内部常量 静态内部类 Holder 类 构造方法 put 过程 put 整体流程图 jdk 1.8 增加的常量 Node 类 Hash 值计算的变化 ...
- HashMap源码分析
文章目录 简介 继承关系 存储结构 源码分析 属性 Node节点 TreeNode HashMap 构造方法 put 添加方法 待更新 简介 在我们使用数据存储的时候都会有数据结构这种东西,但是传统的 ...
- 【Java源码分析】Java8的HashMap源码分析
Java8中的HashMap源码分析 源码分析 HashMap的定义 字段属性 构造函数 hash函数 comparableClassFor,compareComparables函数 tableSiz ...
- HashMap源码分析(转载)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- Map接口总结与HashMap源码分析
Map接口 1.Map,用于保存K-V(双列元素) 2.Map中的Key Value可以是任意引用分类型的数据,会封装到HashMap的Node对象中 3.Map的key不允许重复.原因和HashSe ...
最新文章
- FuzzyCMeans算法
- 智能计算机和智能化网络结论,人工智能技术中计算机网络技术的应用
- JavaScript-语法、关键保留字及变量
- Qt Linguist 发行管理Release Manager
- 阿里P8架构师谈:Web前端、应用服务器、数据库SQL等性能优化总结
- php 简单日志搜索
- Codeforces Round #Pi (Div. 2) B. Berland National Library 模拟
- 夏天这四件事会耗干你的阳气,尤其是第三件!
- Linux 命令完全手册
- 高负载高并发网站架构分析
- MFC分析工具—Resource Hacker
- vue 3 开发环境搭建
- ARM:ARM体系结构与编程、ARM指令流水线、ARM编程模型基础
- 阳振坤:OceanBase 数据库七亿 tpmC 的关键技术
- 皮肤测试小软件有哪些,【皮肤测试小程序】皮肤测试小程序有什么功能呢?
- 自监督论文阅读笔记 Urban feature analysis from aerial remote sensing imagery using self-supervised and semi-s
- GIT 中如何打标签(git tag)
- 情侣间常犯的7个沟通问题
- 安卓课程设计之记账本_基于Android个人用户记账本系统课程设计报告
- 使用GOOGLE API做了个简繁英互译小工具
热门文章
- esxi 5.5运行linux拯救模式,启用Esxi 5.5 SSH 功能
- mysql where 大小写_java – 使用select where where Mysql在Mysql中区分大小写
- python实现不重复排列组合_python之itertools的排列组合相关
- php 和风天气,【原创】彩云/和风天气插件
- php 递归实现无限极分类和排序_无限极分类的两种方式,递归和引用
- hfss仿真时间过长怎么解决_一文详解相控阵天线仿真技术
- java和php哪个开发网站好,网站开发,Java和php两种开发语言,应该选哪一种,你知道吗?...
- 安卓案例:利用帧动画实现游戏特效
- PHP学习笔记02:自然数列求和
- 无心剑中译杰克•谢弗《当默多克遇到撒旦》