Hadoop简介 (资源)
2019独角兽企业重金招聘Python工程师标准>>> 
Hadoop定义
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
hadoop 就是专注于批量数据处理
Hadoop是一个实现了MapReduce计算模式的能够对大量数据进行分布式处理的软件框架,是以一种可靠、高效、可伸缩的方式进行处理的。
Hadoop计算框架最核心的设计是HDFS(Hadoop Distributed File System)和MapReduce,HDFS单看全称就知道,实现了一个分布式的文件系统,MapReduce则是提供一个计算模型,基于分治策略。
在大数据关键技术中,Hadoop的分布式文件系统HDFS属于大数据 存储技术
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
企业发展到一定规模都会搭建单独的BI平台来做数据分析,即OLAP(联机分析处理),一般都是基于数据库技术来构建,基本都是单机产品。除了业务数据的相关分析外,互联网企业还会对用户行为进行分析,进一步挖掘潜在价值,这时数据就会膨胀得很厉害,一天的数据量可能会成千万或上亿,对基于数据库的传统数据分析平台的数据存储和分析计算带来了很大挑战。
分布式文件系统种类:Google File System. HDFS. TFS. Glus-terFS、Ceph、 MogileFS、MooseFS FastDFS
为了应对随着数据量的增长、数据处理性能的可扩展性,许多企业纷纷转向Hadoop平台来搭建数据分析平台。Hadoop平台具有分布式存储及并行计算的特性,因此可轻松扩展存储结点和计算结点,解决数据增长带来的性能瓶颈。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop主机
Hadoop分别从三个角度将主机划分为两种角色。
(1)、最基本的划分为Master和Slave,即主人和奴隶,Master算是中间节点,而Slave算是其下的控制节点;
(2)、从HDFS的角度,将主机划分为 NameNode和DataNode(在分布式文件系统中,目录的管理很重要,管理目录相当于主人,而NameNode就是目录管理者);
(3)、从 MapReduce的角度,将主机划分JobTracker 和TaskTracker(一个job经常被划分为多个Task,从这个角度不难理解它们之间的关系);

Hadoop运行模式 : 三种模式下运行:单一节点(Standalone)、伪分布式(Pseudo-Distributed)、真分布式(Fully-Distributed)。
前两者都是在单一节点上可以运行的,是不对外开放主机的各个服务、存储、管理端口(TCP Port),最后一个必须在多个节点上同时搭建,即是真正的分布式计算、存储系统。单一节点又叫Hadoop CLI MiniCluster。
优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
高可靠性。因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
高效性,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高扩展性。,能够处理 PB 级数据。在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
此外,Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop核心架构
Hadoop 由许多元素构成。其最底部是HDFS,它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
hadoop安装和配置
本文hadoop的版本为hadoop-2.2.0
一、安装java jdk
1、下载java jdk1.7版本,放在/home/software目录下,
2解压:tar -zxvf java-jdk*****.jar
3、vim /etc/profile
|
1 2 3 4 5 |
|
4、检测是否成功安装:java -version
二、安装hadoop
1、在linux根路径创建目录cloud:sudo mkdir cloud
2、解压hadoop到cloud目录中:tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/
3、进入目录:/cloud/hadoop/etc/hadoop
三、修改配置文件
1、修改hadoop-env.sh,配置java jdk路径,大概在27行配置,如下:
export JAVA_HOME=/home/software/jdk1.7
2、修改core-site.xml,配置内容如下
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
3、修改hdfs-site.xml,修改配置如下
|
1 2 3 4 5 |
|
4、修改mapred-site.xml 由于在配置文件目录下没有,需要修改名称:mv mapred-site.xml.template mapred-site.xml

<configuration> <!-- 通知框架MR使用YARN --> <property><name>mapreduce.framework.name</name><value>yarn</value> </property> </configuration>
5、修改yarn-site.xml,修改内容如下
|
1 2 3 4 5 6 7 8 9 10 11 |
|
6、讲hadoop添加到环境变量,然后更新一下环境变量:source /etc/profile
export JAVA_HOME=//home/software/jdk1.7 export HADOOP_HOME=/cloud/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
四、启动hadoop
1、格式化hadoop,进入目录:/cloud/hadoop/etc/hadoo,执行下列之一命令即可
hadoop namenode -format (过时)hdfs namenode -format
2、启动hdfs和yarn
先启动HDFS sbin/start-dfs.sh再启动YARN sbin/start-yarn.sh
3、验证是否成功,使用命令:jps,输出如下即表示配置成功。
|
1 2 3 4 5 6 7 |
|
4、可以在浏览器中查看hdfs和mr的状态.hdfs管理界面:http://localhost:50070 MR的管理界面:http://localhost:8088
五、hdfs基本操作和wordcount程序
1、进入hadoop安装目录中的share:/cloud/hadoop/share/hadoop/mapreduce
2、ls列出当前路径下的文件,内容如下,其中带有example字样的为样例程序
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
3、新建words文件,内容输入如下,然后使用命令上传到hdfs目录下:hadoop fs -put words hdfs://localhost:9000/words
|
1 2 3 4 |
|
4、在命令行中敲入:hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcounthdfs://localhost:9000/wordshdfs://localhost:9000/out
5、打开页面:http://localhost:50070/dfshealth.jsp

6、点击上图中的Browse the filesystem,跳转到文件系统界面,如下所示:
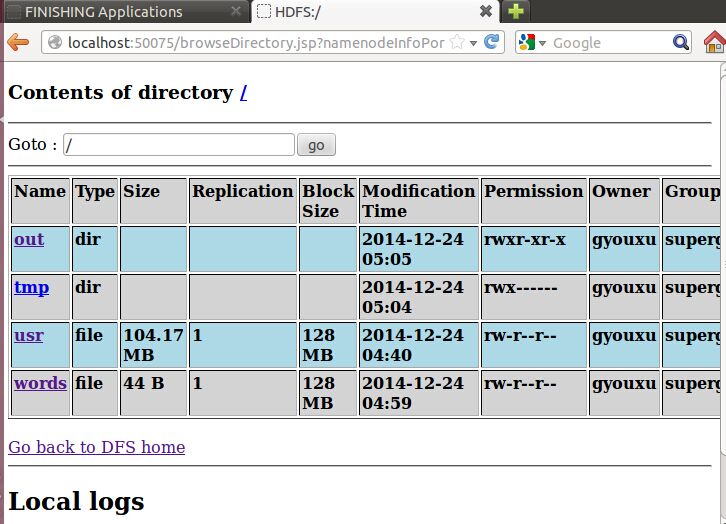
7、继续点击上图的out/part-r-00000,wordcount程序最终运行的结果如图所示:

常见问题 :
1、hadoop主要是用来存储的,怎么做数据分析,它在数据处理上的优势是什么?当初选hadoop的理由是什么?有没有和其他的系统做一个比较?为什么选择这个?
2、hadoop的mapreduce是怎样一个过程?(简历上写着了解一些hadoop技术。。。)map是怎么切分数据的?
答:回答了下整个处理过程,最后我说数据处理好后返回给用户(返回个毛啊,直接存HDFS里),结果面试官非常惊讶,然后我又说每个结点处理好后还要经过排序、分组等再返回结果(真是悲剧,又说了次返回)。
3、master单点失效问题,yarn是什么,最新版是怎么解决单点失效问题的?
答:《hadoop技术内幕:深入解析YARN架构设计与实现原理》
4、链表和数组的区别?
5、
参考链接 :
https://blog.csdn.net/u012842205/article/details/52267291
链接:
大数据系列零基础由入门到实战 : https://blog.csdn.net/Sky786905664/article/details/51819759
hadoop常用服务管理命令 : http://blog.51cto.com/caiguangguang/1579849
Hadoop集群配置(最全面总结):https://blog.csdn.net/hguisu/article/details/7237395
Hadoop教程 : https://www.w3cschool.cn/hadoop/index.html
Hadoop : http://www.voidcn.com/course/project/owcegi

史上最详细的Hadoop环境搭建:http://gitbook.cn/books/5954c9600326c7705af8a92a/index.html
Cloudera Manager 5.13.1 Hadoop群集离线安装 : https://www.azurew.com/7019.html
Hadoop 指南 : https://wdxtub.com/2016/03/20/hadoop-guide/

Hadoop的讲解专栏 : https://blog.csdn.net/column/details/18130.html

大数据 系列: http://club.topsage.com/forum-743-1.html
浅析Hadoop分布式文件系统 : https://mp.weixin.qq.com/s?src=3×tamp=1535268492&ver=1&signature=IzeGJ7px3Y0KdbFXBDhwEsWrPHqHStK8FY-VE2NWOz*U4WaESnCAKMJYr2dIyNGxn6yq285KAe8KPnyc-iAR7E9UqPYMKO2pX4hLAOSPyE6NeReb1IJiMoQAy7QqGkjknGrwILvUFXhjEZ71Nd3Sn24Mc-l1qJFwOG-L69DB8xY=
Hadoop分布式文件系统HDFS的工作原理详述 : https://mp.weixin.qq.com/s?src=3×tamp=1535268492&ver=1&signature=9f4rYV9MBZ2kbADkjAGQaHVrpS8WOUrpbzC12pflTBGTjaZ57*FRl06bgr8MrbCUCtGOwc3An13Udc0zKmrjvM9iCiOj3jUrfZqetf1h*3Wc7GlaU4Nz64koANv6*ABI1HsWpA3N7xljH4Cn2k1Z4Q==
Hadoop分布式文件系统HDFS的工作原理 :http://www.jizhuomi.com/software/455.html
Hadoop分布式文件系统:架构和设计要点 : https://mp.weixin.qq.com/s?src=3×tamp=1535268492&ver=1&signature=cOaIC8LeZ7x1h-8*nR35Gib7vU*ibCzA8SSURam4gu3T7p2I-P3Ue5GPsQ5gvK*je3AONpFoToNoG-3fGw*H2RPeuTYFTFeZkCrqswkuJ6Vfbpa0sfZnrTvwStnAtPWej750SsmLgDR1dUY1ZcFbsA==
Hadoop分布式文件系统3-HDFS应用 :https://mp.weixin.qq.com/s?src=11×tamp=1535268492&ver=1083&signature=vh2TIbN4laRGYmFjm0YjUC*V3p7jJNn*y5jRorgB4DojePHD4qdf7yW2D-9b2ujOndcLIJTpVUJGUWpmbKe0DrX7EiL14eqFvl24dDer-I-XR7IZLovBw7Io-S31P-E*&new=1
Hadoop分布式文件系统-从RAID说起 : https://mp.weixin.qq.com/s?src=11×tamp=1535268492&ver=1083&signature=0WeQe5IIK7M40bOO4tFi*eX3lgMVGP4GiOa6bVM7Yrro4UwaTYLY0QpYBtv9LF4yGdqlrqsZQKfiOmWLnnVRepd8*69LhXuhHI6MCAn5vjNdFkzXACh0H94iccqOYIkZ&new=1
Hadoop分布式文件系统1-从RAID说起 : https://mp.weixin.qq.com/s?src=11×tamp=1535268492&ver=1083&signature=vh2TIbN4laRGYmFjm0YjUC*V3p7jJNn*y5jRorgB4DouDr5U9eiErTFgKVC2Nx-BphbKFtatgSHasxXiNGwBhpBAUmLoAheJxpUBE7LfAet9aDUYvsPNM9eFxTnYIao1&new=1
Hadoop RPC 源码解析 : https://blog.csdn.net/paul_wei2008/article/details/19556053
【转载】Hadoop FS Shell命令大全 : https://blog.csdn.net/SMCwwh/article/details/7489502
Hadoop SafeModeException: xxxxxxx. Name node is in safe mode解决办法 : https://blog.csdn.net/SMCwwh/article/details/7490685
用 Hadoop 统计词频并存入 HBase 中 : https://ericfu.me/hadoop-word-count-save-to-hbase/
hadoop (5篇) : https://blog.csdn.net/qq_28893679/article/category/7712341

脚本之家 hadoop 系列 : https://www.jb51.net/list/list_267_1.htm#

原 SSH免密码登陆 : https://blog.csdn.net/Sky786905664/article/details/52067398
转 Linux下开启Hadoop的9000端口方法 : https://blog.csdn.net/Sky786905664/article/details/52062899
转 Hadoop启动时提示的:$HADOOP_HOME is deprecated. : https://blog.csdn.net/Sky786905664/article/details/52061662
转 《Hadoop基础教程》之初识Hadoop : https://blog.csdn.net/Sky786905664/article/details/51819599
原 hadoop入门(hadoop安装-hdfs简单介绍) : https://blog.csdn.net/ioy84737634/article/details/46761983
Hadoop学习---Zookeeper+Hbase配置学习 : https://www.cnblogs.com/ftl1012/p/9350554.html
Hadoop学习---Hadoop的HBase的学习 : https://www.cnblogs.com/ftl1012/p/9350518.html
Hadoop学习---Hadoop的MapReduce的原理 : https://www.cnblogs.com/ftl1012/p/9350459.html
Hadoop学习---Hadoop的深入学习 : https://www.cnblogs.com/ftl1012/p/9350261.html
Hadoop学习---Eclipse中hadoop环境的搭建 : https://www.cnblogs.com/ftl1012/p/9350238.html
Hadoop学习---CentOS中hadoop伪分布式集群安装 : https://www.cnblogs.com/ftl1012/p/9350180.html
Hadoop学习---Ubuntu中hadoop完全分布式安装教程 : https://www.cnblogs.com/ftl1012/p/9350035.html
Windows下搭建hadoop 搭建本地hadoop开发环境 : https://www.jianshu.com/p/ea9682377090
Hadoop、Storm、Samza、Spark和Flink大数据框架对比 : https://www.ixdba.net/archives/2017/03/585.htm
集群环境下Hadoop2.5.2+Zookeeper3.4.6+Hbase0.98+Hive1.0.0安装目录总汇 : http://blog.51cto.com/vekergu/p5
hadoop分布式集群搭建 ; https://www.cnblogs.com/ityouknow/p/7343995.html
史上最详细、最全面的Hadoop环境搭建 : https://mp.weixin.qq.com/s/cJ8BeApMW1KGAsZgHBCgog
Hadoop运维必须知道的10个运维技能 : https://www.ixdba.net/archives/2017/03/580.htm
Hadoop/Yarn/MapReduce内存分配(配置)方案 : https://www.ixdba.net/archives/2017/03/536.htm
Hadoop YARN配置参数剖析—Fair Scheduler相关参数 : https://www.ixdba.net/archives/2017/03/528.htm
Hadoop入门扫盲:hadoop发行版介绍与选择 : https://www.ixdba.net/archives/2016/11/437.htm
Hadoop HA 安装、布署 : https://mp.weixin.qq.com/s/47esMUkKqzVPzbTfL1PCuw
Hadoop : https://www.cnblogs.com/atomicbomb/tag/Hadoophadoop
Hadoop (34) : https://blog.csdn.net/qq_20545159/article/category/5784915
Hadoop集群搭建总结及Hadoop2.5集群伪分布、完全分布搭建总结 :https://mp.weixin.qq.com/s/llSziXPnNgwO6sn6EoX1WA
Hadoop3.0: YARN Resource配置说明 : https://mp.weixin.qq.com/s/zG1C4c5Hz4UVoME0tfRpqQ
hadoop3.0 Yarn支持网络资源:network原理设计文档说明【中文】: https://mp.weixin.qq.com/s/Lfy7eovk-3mbBWaOkvLp8Q
Hadoop3.0集群安装知识 : https://mp.weixin.qq.com/s/UGuQcQJR1fnw5mp8dbB9Ow
Hadoop3.0通用版集群安装高可靠详细教程【包括零基础】 : https://mp.weixin.qq.com/s/vtNvIQzRtfbEzpjinZlGGA
扩展Yarn资源模型详解1 : https://mp.weixin.qq.com/s/_p1Pa5PzajJPsMdbkpAvNA
Hadoop3.0扩展Yarn资源模型详解2:资源Profiles说明 : https://mp.weixin.qq.com/s/BEsAFw4sbRzwS6shcqAYbg
Hadoop3.0Yarn添加网络、磁盘IO等资源资料汇总及实战配置遇到的问题和解决办法 : https://mp.weixin.qq.com/s/U0pAPMWgow9mJ0rzjs-p-Q
【性能优化的秘密】Hadoop如何将TB级大文件的上传性能优化上百倍?【石杉的架构笔记】 : https://mp.weixin.qq.com/s/2HM9NMRHizKTJoYjg8lZ1Q
hadoop (22篇) : https://www.cnblogs.com/duanxz/category/691548.html




Hadoop进阶之路 : https://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/


转载于:https://my.oschina.net/u/3803405/blog/1821368
Hadoop简介 (资源)相关推荐
- Hadoop简介与分布式安装
Hadoop的基本概念和分布式安装: Hadoop 简介 Hadoop 是Apache Lucene创始人道格·卡丁(Doug Cutting)创建的,Lucene是一个应用广泛的文本搜索库,Hado ...
- 什么是Hadoop?大数据与Hadoop简介
要了解什么是Hadoop,我们必须首先了解与大数据和传统处理系统有关的问题.前进,我们将讨论什么是Hadoop,以及Hadoop如何解决与大数据相关的问题.我们还将研究CERN案例研究,以突出使用Ha ...
- Hadoop简介和体系架构
目录 2.1 Hadoop简介 2.1.1 Hadoop由来 2.1.2 Hadoop发展历程 2.1.3 Hadoop生态系统 2.2 Hadoop的体系架构 2.2.1 分布式文件系统HDFS 2 ...
- hadoop使用mapreduce统计词频_深圳嘉华学校之Hadoop简介(什么是Map-Reduce-Mapreduce-about云开发)...
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- Hadoop简介(1):什么是Map/Reduce
看这篇文章请出去跑两圈,然后泡一壶茶,边喝茶,边看,看完你就对hadoop整体有所了解了. Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Red ...
- Hadoop简介和家族成员介绍
本文为博主原创,允许转载,但请声明原文地址:http://www.coselding.cn/article/2016/05/31/Hadoop简介和家族成员介绍/ 1. HDFS:分布式文件系统实现, ...
- StirMarkBenchmark——图像攻击软件简介资源
文章目录 StirMarkBenchmark工具简介 资源分享 使用方法 1.图像准备 2.参数配置 3.攻击实现 攻击效果展示 后记 StirMarkBenchmark工具简介 StirMarkBe ...
- hadoop基础一:Hadoop简介、安装
你的点赞与评论是我最大的创作动力! hadoop简介: hadoop平台是一个可靠的.可扩展的.可分布式计算的开源软件. Apache Hadoop平台是一个框架,允许使用简单的编程模型.该平台被设计 ...
- Hadoop简介和集群搭建
文章目录 Hadoop简介和集群搭建 Hadoop介绍 Hadoop的发行版本和三大公司 hadoop的架构 安装Hadoop 第一步:上传编译后的apache hadoop包并解压 第二步:修改配置 ...
最新文章
- js路由在php上面使用,React中路由使用详解
- linux java ocr_Linux环境如何支持使用tess4j进行ORC
- html返回滚动按钮,如何通过滚动显示按钮返回TOP
- 远方 vs How did I fall in love with you
- spring配置详解-scope属性
- python 队列与栈的实现
- 从0到1 | 滴滴DB自动化运维实践了解一下
- 如何杀掉服务器的进程
- 现代 C++ 救不了程序员!
- yii2搭建完美后台并实现rbac权限控制实例教程
- 安利几个优质nlp开源项目
- fukk _GNU_SOURCE __USE_GNU
- chrome下方的copeascURL(cmd) 复制的内容,在windows的cmd中不可用的原因
- Js坐标转换器-百度地图坐标转腾讯地图坐标
- 带你逐步深入了解SSM框架——淘淘商城项目之redis缓存
- 数据仓库上云那些事儿
- Python for Data Analysis | Names
- 在线教育凛冬将至!强敌环伺的尚德机构,能否突出重围?
- java向上转型与向下转型
- CODING 敏捷实战系列加餐课:CODING 做敏捷这一年 - 理解一站式 DevOps 产品思想