理论与实践:如何从Hadoop迁移到MaxCompute
直播视频回看,传送门!
分享资料下载,传送门!
更多精彩内容传送门:大数据计算技术共享计划 — MaxCompute技术公开课第二季
以下内容根据演讲视频以及PPT整理而成。
通常而言,将Hadoop迁移到MaxCompute会分为两个主要部分:数据迁移和任务迁移。首先,对于数据迁移而言,可以通过Datax、数据集成以及DataxOnHadoop这几种工具实现。Datax是阿里云开源的一款数据传输工具;而数据集成的底层就是由Datax实现的。如果在数据迁移的过程中要使用Datax,那么需要用户来自定义调度,这对于gateway资源具有一定的要求。Datax在做数据传输的时候需要有一个管道机,通常就称之为gateway,数据的传输都是通过这个gateway来实现的,因此在使用Datax的时候对于gateway的资源是具有一定的要求的。此外,数据集成是在DataWorks里面集成化的数据传输工具。如果想要应用数据集成,那么其调度就是在DataWorks里面完成的,设置完数据周期等一些属性,DataWorks就可以自动实现任务的调度。如果使用数据集成,在网络允许的情况下,可以使用DataWorks的gateway公共网络资源,如果网络不允许则可以使用自定义的调度资源。
除了上述两种方式之外,还有DataxOnHadoop。DataxOnHadoop运行在客户端,用户自己进行调度,与前面的两种方式最大的不同,就是DataxOnHadoop使用的是Hadoop集群的资源,这就相当于提交MapReduce任务,通过MapReduce任务进行数据传输,因此对于网络的要求比较高。因为需要提交MapReduce任务,这就要求Hadoop集群的每个Worker或者DataNode Manager节点和MaxCompute的Tunnel网络打通,这也是这种方案的应用难点。
除此之外,还有一些因素会影响我们在进行数据迁移时做出方案的选择,分别是网络、数据量和迁移周期。对于网络而言,通常分为这样的几种类型,混合云VPC,也就是客户本地机房与阿里云打通在一个VPC里面,还有客户本地机房,一般而言客户的本地机房会有一部分主机具有公网IP,这时候在进行数据迁移的时候就倾向于使用Datax,这是因为客户的集群没有办法直接与MaxCompute打通,还可能使用数据集成,通过使用自定义调度资源来完成这个事情。此外,还有一种情况就是客户集群位于阿里云上,对于经典网络集群,可以通过数据集成直接将数据迁移过来;而对于VPC网络而言,数据集成可能无法直接深入VPC内部,这时候也需要自定义调度资源。当然对于VPC集群而言,也可以DataxOnHadoop,每个节点正常情况下会与MaxCompute的Tunnel可以打通。对于混合云VPC而言,其选项会比多,数据集成以及DataxOnHadoop都可以使用。而对于数据量而言,可以和迁移周期综合起来考虑,线下机房需要迁移的数据有多大以及要求的工期有多长也会影响我们选择的数据迁移方式,并且对于需要准备的网络带宽等资源也是有影响的。
Datax
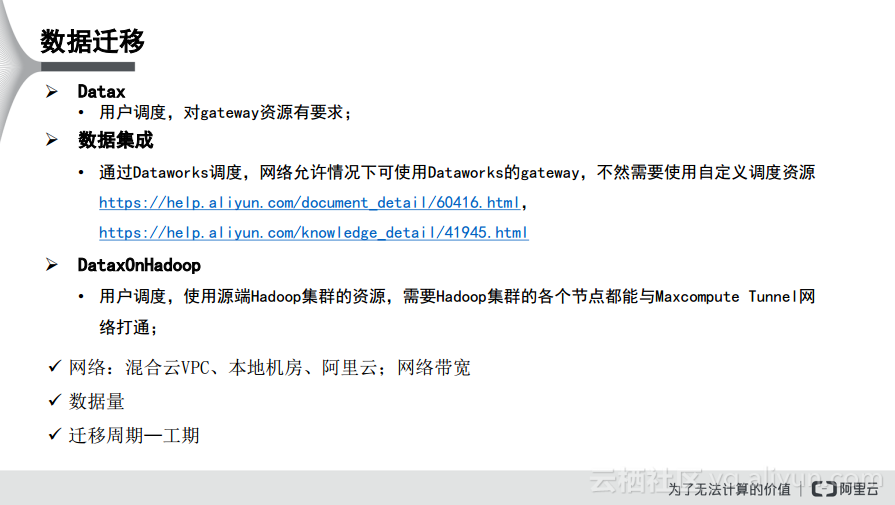
从总体上而言,Datax改变了一种模式,就是数据的导入和导出,比如MySQL到Oracle或者MySQL到ODPS都是单点的,每一种导入和导出都会有单独的工具作为支持。而Datax就实现了各种插件,无论是各个数据库之间如何导入导出,都是通过Datax的gateway实现中转的,首先到Datax,然后再到ODPS,这样就从原来的网状模式变成了星型模式。
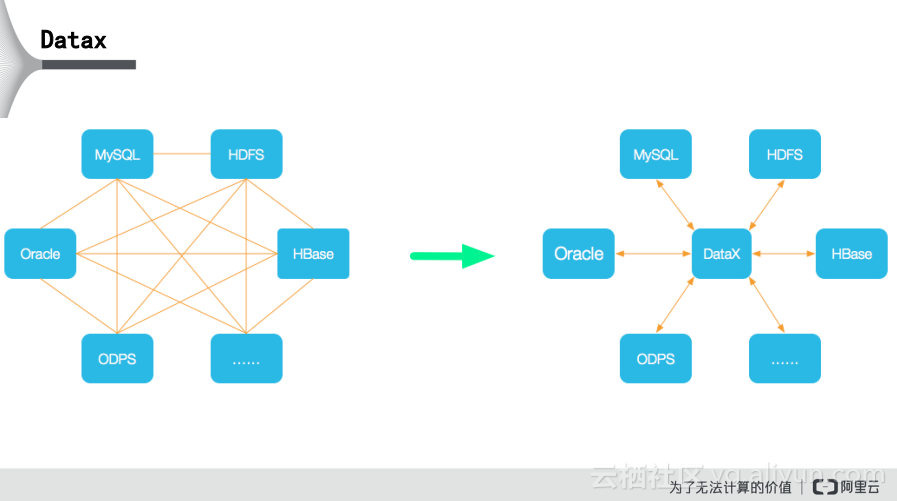
下图较好地解释了Datax的应用,可以看到前面有一个ReadPlugin,无论是从哪个源端到哪个目标端,都是有一个Reader。对于MySQL而言就有一个MySQLReader,对于HDFS,就有一个HDFSWriter,这样结合MySQLReader和HDFSWriter就能形成MySQL到HDFS的传输。再设想一下,下面还有一个ODPSWriter,那么也就能够通过MySQLReader到ODPSWriter,形成这样的链路,从而能够形成各种组合,打通各条链路。而之前提到的Reader和Writer都是在gateway上运行的,需要从源端读取数据,向目标端写入数据,所以gateway需要占用带宽资源以及CPU内存资源,这也就是为何需要考虑gateway以及其资源的原因。
任务迁移
除了数据迁移之外,还需要关注任务迁移。这部分也分为两部分,一部分是任务本身的迁移,另外一部分是调度平台的迁移。对于任务本身的迁移而言,比如原来使用的Hive SQL,想要迁移到MaxCompute的SQL,这样在迁移的匹配上可能会有一些迁移的工作量。原来在Hive上定义的UDF,写的MaxCompute程序或者Spark任务这些也都需要进行迁移。除此之外,还有一类就是调度平台的迁移,原来的Hive SQL以及MaxCompute程序是通过某些调度工作进行周期性的任务运行,当迁移到MaxCompute之后,这些任务也需要进行相应的迁移。这里列举了两类,一类是迁移之后裸用MaxCompute,就相当于还作为原来的Hive来使用或者还是使用命令行或者API的方式做调用,此时原来的调度系统基本上不用变化,只需要将原来对Hive的接口改为对MaxCompute的接口就可以了。还有一类就是在迁移之后需要通过DataWorks进行调用,这个时候任务迁移的工作量就会大一些,首先需要将原来的任务迁移到DataWorks里面去,其次还要将原来的调度属性也配置到DataWorks里面去。

接下来具体说明任务迁移需要做哪些具体工作,首先Hive SQL到MaxCompute SQL的兼容度非常高,目前而言,Hive的数据类型基本上直接可以对接到MaxCompute中,MaxCompute对于Hive语法而言也是基本上兼容的,仅需要简单调试即可。如果UDF不涉及到磁盘读写或者网络IO,也可以直接拿到ODPS来使用的,原来的Jar包不需要修改。MapReduce的改造量相对大一些,这是因为MaxCompute沙箱限制比较严重,那么一些文件读写以及网络IO操作是被禁止掉的。而对于MaxCompute而言,输出输出都是表,而MapReduce主要针对的是HDFS的文件系统,因此需要做映射,对此MaxCompute也提供了相应的工具,只不过相对于UDF而言会略微麻烦一点。除此之外,还有Spark任务,这在原来的HDFS上相对会多一些,之后会有一个SparkOnMaxCompute,可以支持用户将Spark程序无缝地迁移到MaxCompute上。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
理论与实践:如何从Hadoop迁移到MaxCompute相关推荐
- 【阿里云】企业自建 Hadoop 迁移至 MaxCompute 最佳实践学习
文章目录 一.前言 二.适用场景 三.技术架构 四.方案优势 五.自建Hadoop集群规划 5.1 Hadoop集群安装规划 5.2 创建 VPC 网络 5.3 批量创建 ECS 实例 5.4 初始化 ...
- 大数据理论与实践6 分布式ETL工具Sqoop
ETL是指数据收集层,指的是数据抽取(Extract).转换(Transform).加载(Load),在真正的大数据工作中,很大的工作量都在做这一块的内容. Sqoop简介 只要用于在Hadoop和关 ...
- 高盛发布区块链报告:从理论到实践(中文版)
投资组合经理之摘要 现在硅谷和华尔街都为了区块链着迷,逐渐忘记了作为其技术源头的比特币.但对其潜在应用的讨论仍十分抽象和深奥.焦点在于使用分布式账本建立去中心化市场,并削弱现有中间商的控制权. 但区块 ...
- Kubernetes 集群升级指南:从理论到实践
作者 | 高相林(禅鸣) **导读:**集群升级是 Kubernetes 集群生命周期中最为重要的一环,也是众多使用者最为谨慎对待的操作之一.为了更好地理解集群升级这件事情的内涵外延,我们首先会对集群 ...
- 在线公开课 | 从理论走向实践,多角度详解Cloud Native
戳蓝字"CSDN云计算"关注我们哦! 本次直播课程是由京东云产品研发部中间件负责人李道兵从Cloud Native概念入手到实践出发,深度解析了Cloud Native年度热词背后 ...
- 【系统架构设计师】软考高级职称,来自订阅者真实反馈,从理论、实践、技巧让你掌握论文写作秘诀
[系统架构设计师]软考高级职称,来自订阅者真实反馈,从理论.实践.技巧让你掌握论文写作秘诀. 目录 对于系统架构设计师的论文写作几点建议 论文摘要 论文正文 论文结尾 关于[系统架构设计师]备战,我想 ...
- 高可用的Redis主从复制集群,从理论到实践
作者:Sicimike blog.csdn.net/Baisitao_/article/details/105545410 前言 我们都知道,服务如果只部署一个节点,很容易出现单点故障,从而导致服务不 ...
- 手动搭建高可用的Redis5.0分片集群,从理论到实践,超详细
前言 前一篇 高可用的Redis主从复制集群,从理论到实践 发布后,反响非常热烈.所以今天继续深入讲解redis集群的搭建和相关理论. 好吧,其实是因为上篇搭建的主从复制集群,还有一个实际问题不能解决 ...
- 彻底了解C++异步从理论到实践
1. 纠结的开篇 之前设计我们游戏用的c++框架的时候, 刚好c++20的coroutine已经发布, 又因为是专门 给game server用的c++ framework, 对多线程的诉求相对有限, ...
最新文章
- Ubuntu终端Terminal常用快捷键
- html lineheight div,html – Chrome上的文本输入:line-height似乎有最小值
- 直击平昌!2天40位大咖的平昌区块链论坛精华都在这了!
- 面试题·HashMap和Hashtable的区别(转载再整理)
- 自定义头文件之二------hlib.h(慢慢更新)
- JAVA编译器的作用
- maven配置时报错NB: JAVA_HOME should point to a JDK not a JRE**解决方法
- 除了深度学习,机器翻译还需要啥?
- 网站被攻击怎么办如何解决
- verilog实现N分频电路
- 一起来回忆一些经典的台词吧~~
- 如何软著办理,软著申请步骤,软著办理流程
- 第15章-4~6 装配体静力学分析经验技巧总结篇 (工作原理的简化、约束、预紧力、载荷、后处理)高效修改接触对、suppress(抑制)、多工位(多步计算)的螺栓预紧力设置
- 如何用Python进行数据分析
- 推荐下Python的IDE:PyScripter,Spyder以及使用心得分享
- 我用 python 做了款可开淘宝店赚钱的工具!
- 局部自适应阈值分割方法
- fenix3 hr 中文说明书_Fenix3HR中英文菜单对照.pdf
- 青少年机器人等级考试四级考什么
- 活动星投票国潮大秀东方网络评选投票怎么做的免费微信投票活动
热门文章
- snmp 获得硬件信息_信息系统项目管理师(三)
- 加载中图片 转圈_对话洛可可平面设计师:平面设计中的效率瓶颈
- HTML列表内容自动排序,JS实现HTML表格排序功能
- 6-7 使用函数输出水仙花数_学习C语言居然对printf函数不理解???
- linux lvm lv扩充--虚拟机,虚拟机新增磁盘后lvm下的lv扩容
- java 数据结构 迷宫_JAVA数据结构与算法之递归(一)~ 迷宫问题
- fastapi 传输文件存文件_揭秘|国内影视文件传输的真相,跨境文件传输更不简单...
- memcpy函数实现_等比例缩放c++ opencv 实现
- 破格晋升!一批高校教师脱颖而出
- 9511王锋刘婧捐100万元,支持中国科大计算机学院