十大经典数据挖掘算法:SVM
作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
SVM(Support Vector Machines)是分类算法中应用广泛、效果不错的一类。《统计学习方法》对SVM的数学原理做了详细推导与论述,本文仅做整理。由简至繁SVM可分类为三类:线性可分(linear SVM in linearly separable case)的线性SVM、线性不可分的线性SVM、非线性(nonlinear)SVM。
1.线性可分
对于二类分类问题,训练集
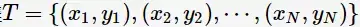
,其类别
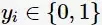
,线性SVM通过学习得到分离超平面(hyperplane):
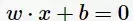
以及相应的分类决策函数:
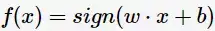
有如下图所示的分离超平面,哪一个超平面的分类效果更好呢?
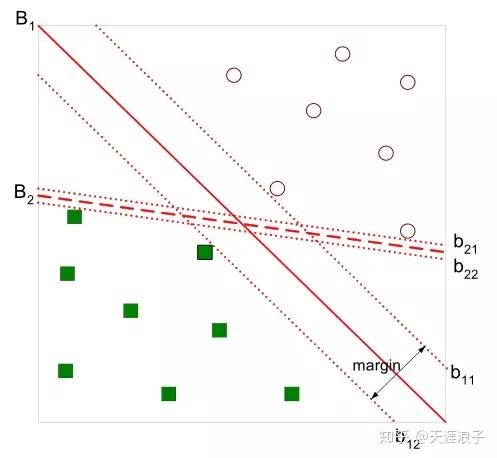
直观上,超平面
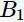
的分类效果更好一些。将距离分离超平面最近的两个不同类别的样本点称为支持向量(support vector)的,构成了两条平行于分离超平面的长带,二者之间的距离称之为margin。显然,margin更大,则分类正确的确信度更高(与超平面的距离表示分类的确信度,距离越远则分类正确的确信度越高)。通过计算容易得到:
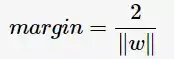
从上图中可观察到:margin以外的样本点对于确定分离超平面没有贡献,换句话说,SVM是有很重要的训练样本(支持向量)所确定的。至此,SVM分类问题可描述为在全部分类正确的情况下,最大化
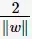
(等价于最小化
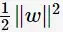
);线性分类的约束最优化问题

对每一个不等式约束引进拉格朗日乘子(Lagrange multiplier)
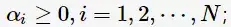
构造拉格朗日函数(Lagrange function):
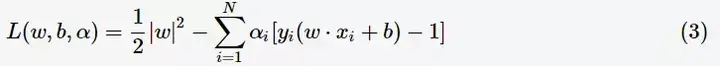
根据拉格朗日对偶性,原始的约束最优化问题可等价于极大极小的对偶问题:
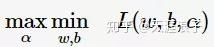
将
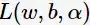
对
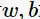
求偏导并令其等于0,则
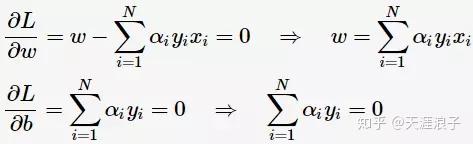
将上述式子代入拉格朗日函数(3)中,对偶问题转为
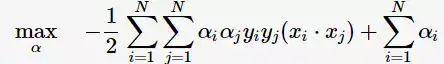
等价于最优化问
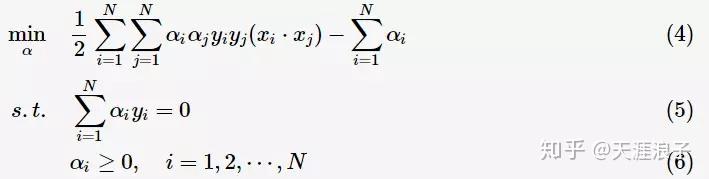
线性可分是理想情形,大多数情况下,由于噪声或特异点等各种原因,训练样本是线性不可分的。因此,需要更一般化的学习算法。
2.线性不可分
线性不可分意味着有样本点不满足约束条件(2),为了解决这个问题,对每个样本引入一个松弛变量

这样约束条件变为:
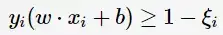
目标函数则变为
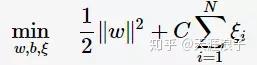
其中,
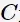
为惩罚函数,目标函数有两层含义:
- margin尽量大,
- 误分类的样本点计量少
为调节二者的参数。通过构造拉格朗日函数并求解偏导(具体推导略去),可得到等价的对偶问题:
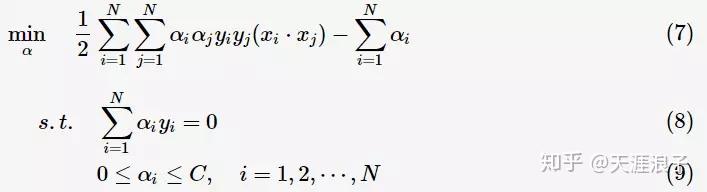
与上一节中线性可分的对偶问题相比,只是约束条件
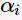
发生变化,问题求解思路与之类似。
3.非线性
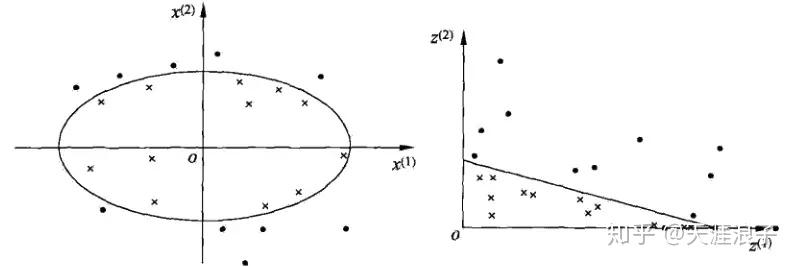
对于非线性问题,线性SVM不再适用了,需要非线性SVM来解决了。解决非线性分类问题的思路,通过空间变换ϕ(一般是低维空间映射到高维空间
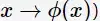
后实现线性可分,在下图所示的例子中,通过空间变换,将左图中的椭圆分离面变换成了右图中直线。
在SVM的等价对偶问题中的目标函数中有样本点的内积
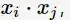
在空间变换后则是
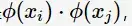
由于维数增加导致内积计算成本增加,这时核函数(kernel function)便派上用场了,将映射后的高维空间内积转换成低维空间的函数:
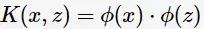
将其代入一般化的SVM学习算法的目标函数(7)中,可得非线性SVM的最优化问题:
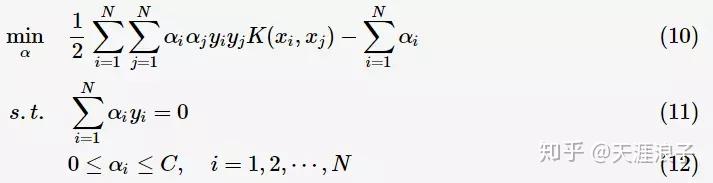
4.参考资料
[1] 李航,《统计学习方法》.
[2] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
十大经典数据挖掘算法:SVM相关推荐
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】PageRank
作者简介: Treant 人工智能爱好者社区专栏作者 博客专栏:https://www.cnblogs.com/en-heng 引言 PageRank是Sergey Brin与Larry Page于1 ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]k-means https://mp.weixin.qq.com/s/SWlE-KBJ4mVza92nJFX1hg 作者简介: Treant 人工智能爱好者社区专栏作者 博客 ...
- k均值例子 数据挖掘_【十大经典数据挖掘算法】k-means
作者简介: Treant 人工智能爱好者社区专栏作者 博客专栏:https://www.cnblogs.com/en-heng 1.引言 k-means与kNN虽然都是以k打头,但却是两类算法--kN ...
- 技术08期:十大经典数据挖掘算法【PageRank篇】
PageRank可以较为直观的理解为是对网页重要性排序的一种算法. Googel 能在全球互联网搜索引擎中处于较高地位,该算法功不可没. 导 读 早期的搜索引擎通过计算用户查询关键词与网页内容的相关程 ...
- 十大经典数据挖掘算法之k-means
kmeans聚类理论篇 前言 kmeans是最简单的聚类算法之一,但是运用十分广泛.最近在工作中也经常遇到这个算法.kmeans一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类 ...
- 【十大经典数据挖掘算法】EM
作者简介: Treant 人工智能爱好者社区专栏作者 博客专栏:https://www.cnblogs.com/en-heng 1.极大似然 极大似然(Maximum Likelihood)估计为用于 ...
- 十大经典数据挖掘算法:EM
作者简介: Treant 人工智能爱好者社区专栏作者 博客专栏:https://www.cnblogs.com/en-heng 1.极大似然 极大似然(Maximum Likelihood)估计为用于 ...
最新文章
- python第三方库之学习flask-restful
- 数值分析第三次作业-常微分方程的数值解法
- 安装了但是报错找不到_安装MySQL时由于找不到vcruntime140_1.dll,无法继续安装
- 【图像处理】——Python霍夫变换之直线检测(主要是两个函数HoughlinesHoughlinesP)
- 我是服务的执政官-服务发现和注册工具consul简介
- WordPress 不用插件实现对长文章进行分页
- 【英语学习】【WOTD】trivial 释义/词源/示例
- IOS NSNotification 通知
- 如何避免ASP.NET网页初次加载缓慢
- 118、杨辉三角(python)
- 国密 SM4 高并发服务 加压测服务 加生成秘钥 结合上篇一起使用 国密 SM2 SM3 SM4 后续升级版本,内容丰富单独写一篇百万压测4000毫秒加解密
- 电子商务网站的购物流程设计(简述)
- GitHub上广受欢迎的下载神器:youtube-dl
- 关于初学者对于二级菜单制作的小结
- CAD导入卫星地图几种方式
- C语言函数大全-- s 开头的函数(1)
- 初识TradingView脚本语言PineScrpt 5
- 打印100-200以内的素数
- swoft 协程 的使用
- 计算机类本科专业国家质量标准,计算机专业国家职业标准
热门文章
- python爬虫插件_Python使用Chrome插件实现爬虫过程图解
- linux驱动导出文件属性,将Linux配置文件和设置备份到USB闪存驱动器的方法
- ngixn+tomcat负载均衡 动静分离配置 (nginx反向代理)
- Oracle打开虚拟机闪退,虚拟机上启动Oracle服务为什么自动停止,怎么处理?
- asp.net mysql打包_Asp.net与SQL一起打包部署安装
- js function如何传入参数未字符串_JavaScript 学习之路- JS 小测验
- kpmg java_【毕马威(KPMG)工资】java开发工程师待遇-看准网
- python导入模块教程_Python教程——导入自定义模块
- 点石关键词排名优化软件_重庆关键词优化排名
- wmm开启和关闭的区别_【解读】排烟风机应由哪些排烟防火阀连锁关闭