spark2.0.1安装部署及使用jdbc连接基于hive的sparksql
2019独角兽企业重金招聘Python工程师标准>>> 
1、安装
如下配置,除了配置spark还配置了spark history服务
#先到http://spark.apache.org/根据自己的环境选择编译好的包,然后获取下载连接
cd /opt
mkdir spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.6.tgz
tar -xvzf spark-2.0.1-bin-hadoop2.6.tgz
cd spark-2.0.1-bin-hadoop2.6/conf
复制一份spark-env.sh.template,改名为spark-env.sh。然后编辑spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
export SPARK_MASTER_HOST=hadoop-n复制一份spark-defaults.conf.template,改成为spark-defaults.conf,然后编辑spark-defaults.conf
#指定master地址,以便在启动的时候不用再添加--master参数来启动集群
spark.master spark://hadoop-n:7077
#对sql查询进行字节码编译,小数据量查询建议关闭
spark.sql.codegen true
#开启任务预测执行机制,当出现比较慢的任务时,尝试在其他节点执行该任务的一个副本,帮助减少大规模集群中个别慢任务的影响
spark.speculation true
#默认序列化比较慢,这个是官方推荐的
spark.serializer org.apache.spark.serializer.KryoSerializer
#自动对内存中的列式存储进行压缩
spark.sql.inMemoryColumnarStorage.compressed true
#是否开启event日志
spark.eventLog.enabled true
#event日志记录目录,必须是全局可见的目录,如果在hdfs需要先建立文件夹
spark.eventLog.dir hdfs://hadoop-n:9000/spark_history_log/spark-events
#是否启动压缩
spark.eventLog.compress true复制一份slaves.template,改成为slaves,然后编辑slaves
hadoop-d1
hadoop-d2从$HIVE_HOME/conf下拷贝一份hive-site.xml到当前目录下。
编辑/etc/下的profile,在末尾处添加
export SPARK_HOME=/opt/spark/spark-2.0.1-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://hadoop-n:9000/spark_history_log/spark-events"为了保证绝对生效,/etc/bashrc也做同样设置,然后刷新设置
source /etc/profile
source /etc/bashrc2、启动
a)首先启动hadoop;
cd $HADOOP_HOME/sbin
./start-dfs.sh访问http://ip:port:50070查看是否启动成功
b)然后启动hive
cd $HIVE_HOME/bin
./hive --service metastore执行beeline或者hive命令查看是否启动成功,默认hive日志在/tmp/${username}/hive.log
c)最后启动spark
cd $SPARK_HOME/sbin
./start-all.shsprark ui :http://hadoop-n:8080
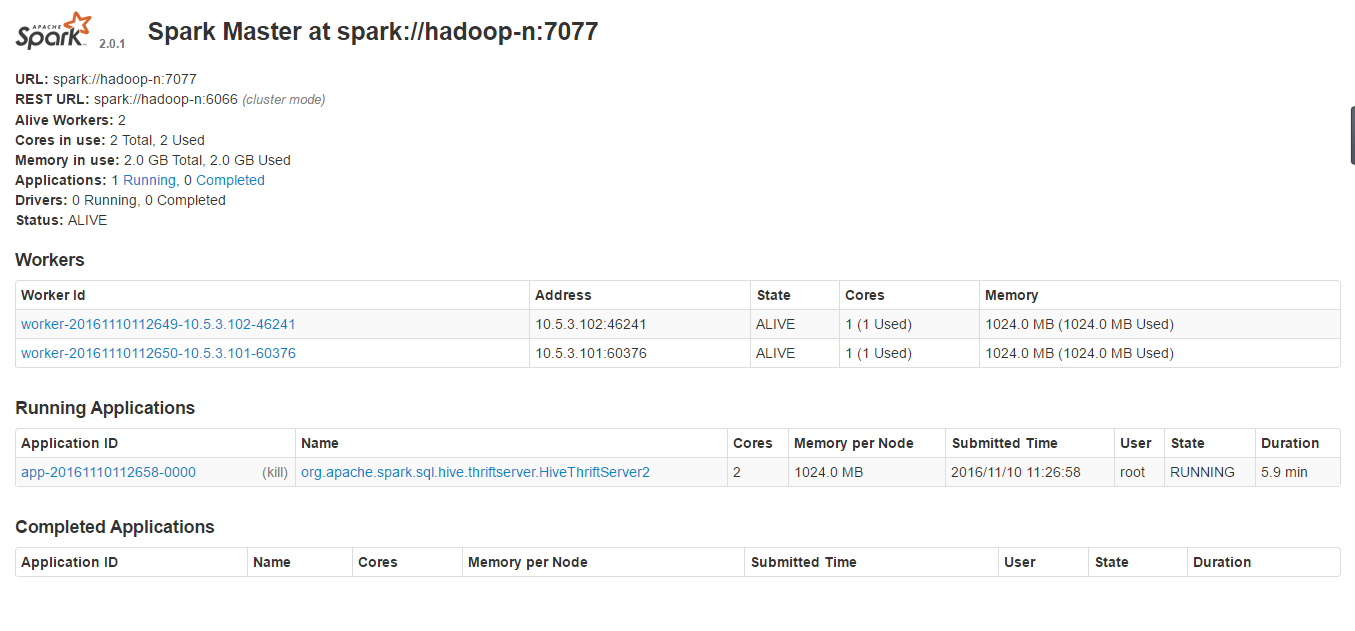
spark客户端
cd $SPARK_HOME/bin
./spark-shellsparksql客户端
cd $SPARK_HOME/bin
./spark-sql注意执行命令后提示的webui的端口号,通过webui可以查询对应监控信息。
启动thriftserver
cd $SPARK_HOME/sbin
./start-thriftserver.sh spark thriftserver ui:http://hadoop-n:4040

启动historyserver
cd $SPARK_HOME/sbin
./start-history-server.shspark histroy ui:http://hadoop-n:18080
3、使用jdbc连接基于hive的sparksql
a)如果hive启动了hiveserver2,关闭
b)执行如下命令启动服务
cd $SPARK_HOME/sbin
./start-thriftserver.sh执行如下命令测试是否启动成功
cd $SPARK_HOME/bin
./beeline -u jdbc:hive2://ip:10000
#如下是实际输出
[root@hadoop-n bin]# ./beeline -u jdbc:hive2://hadoop-n:10000
Connecting to jdbc:hive2://hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.Utils: Supplied authorities: hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.Utils: Resolved authority: hadoop-n:10000
16/11/08 21:03:05 INFO jdbc.HiveConnection: Will try to open client transport with JDBC Uri: jdbc:hive2://hadoop-n:10000
Connected to: Spark SQL (version 2.0.1)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 1.2.1.spark2 by Apache Hive
0: jdbc:hive2://hadoop-n:10000> show databases;
+---------------+--+
| databaseName |
+---------------+--+
| default |
| test |
+---------------+--+
2 rows selected (0.829 seconds)
0: jdbc:hive2://hadoop-n:10000>
编写代码连接sparksql
按照自己的环境添加依赖
<dependencies><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.6</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>1.2.1</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.6.0</version></dependency></dependencies>然后编写类
/** ** @Title: HiveJdbcTest.java * @Package com.scc.hive * @Description: TODO(用一句话描述该文件做什么) * @author scc* @date 2016年11月9日 上午10:16:32 */
package com.scc.hive;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;/**** @ClassName: HiveJdbcTest* @Description: TODO(这里用一句话描述这个类的作用)* @author scc* @date 2016年11月9日 上午10:16:32* */
public class HiveJdbcTest {private static String driverName = "org.apache.hive.jdbc.HiveDriver";public static void main(String[] args) throws SQLException {try {Class.forName(driverName);} catch (ClassNotFoundException e) {e.printStackTrace();System.exit(1);}Connection con = DriverManager.getConnection("jdbc:hive2://10.5.3.100:10000", "", "");Statement stmt = con.createStatement();String tableName = "l_access";String sql = "";ResultSet res = null;sql = "describe " + tableName;res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getString(1) + "\t" + res.getString(2));}sql = "select * from " + tableName + " limit 10;";res = stmt.executeQuery(sql);while (res.next()) {System.out.println(res.getObject("id"));}sql = "select count(1) from " + tableName;res = stmt.executeQuery(sql);while (res.next()) {System.out.println("count:" + res.getString(1));}}
}
下面是控制台输出
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
id int
req_name string
req_version string
req_param string
req_no string
req_status string
req_desc string
ret string
excute_time int
req_time date
create_time date
212
213
214
215
216
217
218
219
220
221
count:932
4、注意事项
- 集群要配置ssh免密码登录
- 不要忘记拷贝hive的配置文件,不然spark会在本地创建物理数据库文件
- hive启动时提示ls: cannot access /opt/spark/spark-2.0.1-bin-hadoop2.6/lib/spark-assembly-*.jar: No such file or directory,不影响程序运行,可忽略
转载于:https://my.oschina.net/shyloveliyi/blog/784714
spark2.0.1安装部署及使用jdbc连接基于hive的sparksql相关推荐
- spark2.0 sql java_spark2.0.1安装部署及使用jdbc连接基于hive的sparksql
1.安装 如下配置,除了配置spark还配置了spark history服务 #先到http://spark.apache.org/根据自己的环境选择编译好的包,然后获取下载连接 cd /opt mk ...
- linux redis-4.0,Linux Redis 4.0.2 安装部署
Linux Redis 4.0.2 安装部署 01 安装GCC yum -y install gcc gcc-c++ libstdc++-devel tcl -y 02 下载安装包 cd /expor ...
- Dynamic CRM9.0 环境安装部署手册步骤和遇到的一些问题解决方案(包含ADFS部署)
Dynamic CRM9.0 环境安装部署手册 Dynamic 365和ADFS配置安装过程踩了一些坑,拿出来和大家记录分享一下. 目录 Dynamic CRM9.0 环境安装部署手册 一.Activ ...
- Postgresql 12.2 + PostGIS 3.0.1 安装部署手册
Postgresql 12.2 + PostGIS 3.0.1 安装部署手册 文章目录 Postgresql 12.2 + PostGIS 3.0.1 安装部署手册 环境说明 注意事项 Postgre ...
- Zabbix 6.0 图文安装部署讲解---LNMP环境
Zabbix 6.0 图文安装部署讲解---LNMP环境 简介 环境需求 部署环境 关闭系统防火墙 一.Mysql8.0.30 部署 二.nginx 部署 三.PHP 部署 四.zabbix-serv ...
- Tez 0.9安装部署+hive on tez配置 + Tez-UI
Tez说明 将xyz替换为您正在使用的tez发行版号.例如0.5.0.对于Tez版本0.8.3和更高版本,Tez需要Apache Hadoop版本为2.6.0或更高版本.对于Tez版本0.9.0及更高 ...
- Rocky 9.1操作系统实现zabbix6.0的安装部署实战
文章目录 前言 一. 实验环境 二. 安装zabbix过程 2.1. 安装zabbix源 2.2 安装zabbix相关的软件 2.3 安装数据库并启动 2.4 开始初始化数据库: 2.5 创建数据库实 ...
- spark2.0.1 安装配置
1. 官网下载 wget http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz 2. 解压 tar -zxvf spar ...
- zabbix-3.0.4安装部署
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案,由一个国外的团队持续维护更新,软件可以自由下载使用,运作团队靠提供收费的技术支持赢利,官方网站:http:/ ...
最新文章
- webpack+vue实践
- Linux 基础——查看文件内容的命令
- 使用优化器提示(Optimizer Hints)
- VMWare ubuntu虚拟机每次开机要等待1分30秒解决方案(A start job is running for dev-disk-by\x2duui...)(修改真实swap UUID)
- mysql主要有什么问题_mysql问题
- 清楚浮动的方法和原理
- SpringBoot热部署环境搭建和原理分析
- fetch jsonp连接mysql_fetch跨域浏览器请求头待研究
- 拼接字符串时的引号嵌套
- 不敌 Java、C/C++、Python,28 岁 VB 究竟输在了哪?
- 计算机等级考试网络数据,全国计算机等级考试三级信息、网络、数据库上机编程题15道...
- 造价120万人民币,日本这款美女机器人是你梦寐以求的机器人老婆吗?
- 【SpringBoot系列】最详细demo-- 集成Swagger2
- wps 单元格跳动_WPS文字在表格中打字自动跳动
- 编码技巧——全局异常捕获统一的返回体业务异常
- 核典型关联分析(KCCA)算法原理
- 滑块逃脱_逃脱测试的丛林:从夹具到断言的捷径
- 测试语文水平的软件,语文试卷质量分析
- mysql的id生成uuid
- 最新kali之sslyze