RDD DataFrame DataSet 区别和转换
RDD、DataFrame和DataSet是容易产生混淆的概念,必须对其相互之间对比,才可以知道其中异同。
RDD和DataFrame
RDD-DataFrame
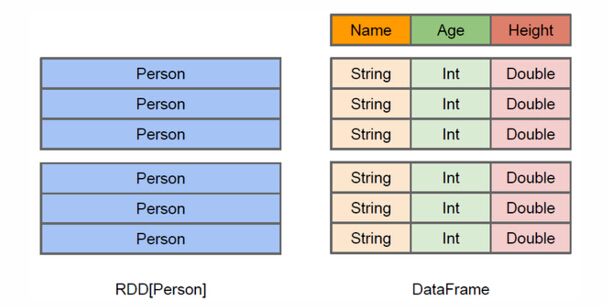
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解 Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即schema。RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
DataFrame和DataSet
Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row。因此具有如下三个特点:
DataSet可以在编译时检查类型
并且是面向对象的编程接口。用wordcount举例:
|
1
2
3
4
5
6
7
8
9
10
11
|
//DataFrame
// Load a text file and interpret each line as a java.lang.String
val ds = sqlContext.read.text("/home/spark/1.6/lines").as[String]
val result = ds
.flatMap(_.split(" ")) // Split on whitespace
.filter(_ != "") // Filter empty words
.toDF() // Convert to DataFrame to perform aggregation / sorting
.groupBy($"value") // Count number of occurences of each word
.agg(count("*") as "numOccurances")
.orderBy($"numOccurances" desc) // Show most common words first
|
后面版本DataFrame会继承DataSet,DataFrame是面向Spark SQL的接口。
|
1
2
3
4
5
6
7
|
//DataSet,完全使用scala编程,不要切换到DataFrame
val wordCount =
ds.flatMap(_.split(" "))
.filter(_ != "")
.groupBy(_.toLowerCase()) // Instead of grouping on a column expression (i.e. $"value") we pass a lambda function
.count()
|
DataFrame和DataSet可以相互转化, df.as[ElementType] 这样可以把DataFrame转化为DataSet, ds.toDF() 这样可以把DataSet转化为DataFrame。
DataFrame是一个组织成命名列的数据集。它在概念上等同于关系数据库中的表或R/Python中的数据框架,但其经过了优化。DataFrames可以从各种各样的源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API 可以被Scala,Java,Python和R调用。在Scala和Java中,DataFrame由Rows的数据集表示。在Scala API中,DataFrame只是一个类型别名Dataset[Row]。而在Java API中,用户需要Dataset<Row>用来表示DataFrame。在本文档中,我们经常将Scala/Java数据集Row称为DataFrames。
那么DataFrame和spark核心数据结构RDD之间怎么进行转换呢?
代码如下:
- # -*- coding: utf-8 -*-
- from __future__ import print_function
- from pyspark.sql import SparkSession
- from pyspark.sql import Row
- if __name__ == "__main__":
- # 初始化SparkSession
- spark = SparkSession \
- .builder \
- .appName("RDD_and_DataFrame") \
- .config("spark.some.config.option", "some-value") \
- .getOrCreate()
- sc = spark.sparkContext
- lines = sc.textFile("employee.txt")
- parts = lines.map(lambda l: l.split(","))
- employee = parts.map(lambda p: Row(name=p[0], salary=int(p[1])))
- #RDD转换成DataFrame
- employee_temp = spark.createDataFrame(employee)
- #显示DataFrame数据
- employee_temp.show()
- #创建视图
- employee_temp.createOrReplaceTempView("employee")
- #过滤数据
- employee_result = spark.sql("SELECT name,salary FROM employee WHERE salary >= 14000 AND salary <= 20000")
- # DataFrame转换成RDD
- result = employee_result.rdd.map(lambda p: "name: " + p.name + " salary: " + str(p.salary)).collect()
- #打印RDD数据
- for n in result:
- print(n)
![]()
RDD DataFrame DataSet 区别和转换相关推荐
- Spark SQL之RDD, DataFrame, DataSet详细使用
前言 Spark Core 中,如果想要执行应用程序,需要首先构建上下文环境对象 SparkContext,Spark SQL 其实可以理解为对 Spark Core 的一种封装,不仅仅在模型上进行了 ...
- sql能查到数据 dataset对象里面没有值_spark系列:RDD、DataSet、DataFrame的区别
RDD与DataSet的区别 二者都是由元素构成的分布式数据集合 1. 对于spark来说,并不知道RDD元素的内部结构,仅仅知道元素本身的类型,只有用户才了解元素的内部结构,才可以进行处理.分析:但 ...
- RDD 与 DataFrame原理-区别-操作详解
1. RDD原理及操作 RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用.RDD内 ...
- RDD, DataFrame or Dataset
RDD, DataFrame or Dataset @(SPARK)[spark] 文章主要内容来自: https://databricks.com/blog/2016/05/11/apache-sp ...
- dataframe 切片_NumPy中的ndarray与Pandas的Series和DataFrame之间的区别与转换
在数据分析中,经常涉及numpy中的ndarray对象与pandas的Series和DataFrame对象之间的转换,让一些开发者产生了困惑.本文将简单介绍这三种数据类型,并以金融市场数据为例,给出相 ...
- python dataframe的某一列变为list_NumPy中的ndarray与Pandas的Series和DataFrame之间的区别与转换...
在数据分析中,经常涉及numpy中的ndarray对象与pandas的Series和DataFrame对象之间的转换,让一些开发者产生了困惑.本文将简单介绍这三种数据类型,并以金融市场数据为例,给出相 ...
- spark DataSet与DataFrame的区别
一句话概括,二者的关系就是 DataFrame = Dataset[Row] 就是说 DataFrame是 Dataset泛型为Row的一种特例,而Dataset的泛型还可以是其他东西,比如自定义类P ...
- RDD、DataSet与DataFream
1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合. ...
- Spark _25.plus _使用idea读取Hive中的数据加载成DataFrame/DataSet(四)
对Spark _25 _读取Hive中的数据加载成DataFrame/DataSet(四) https://georgedage.blog.csdn.net/article/details/10309 ...
- pyspark 数据类型转换_PySpark之DataFrame的创建与转换
简介 DataFrame结构代表的是数据的一个不可变分布式集合,其数据都被组织到有名字的列中,就像关系型数据库中的表一样.DataFrame 的目的就是要让对大型数据集的处理变得更简单,它让开发者可以 ...
最新文章
- silverlight中的socket编程注意事项
- js 事件流的事件冒泡和事件捕获与阻止事件传播
- 【ABAP】模式(Pattern)创建与使用
- 恒驰机器人_机器人如何造恒驰?探秘最牛汽车生产基地
- stm32中spi可以随便接吗_stm32之SPI通信协议实例详解
- notepad++与ISE/Vivado关联
- python需要背的英语单词怎么写_学Python必须背的42个常见单词,看看你都会吗?...
- zigbee是什么,为什么说它最适合智能家居设备
- 为什么Flink会成为下一代大数据处理框架的标准?
- JEPLUS之特殊字段类型的使用——JEPLUS软件快速开发平台
- Json与List的相互转换 [谷歌的Gson.jar和阿里的fastJson.jar]
- 【图像分割】基于马尔可夫随机场实现图像分割附matlab代码
- 如何修改域名DNS服务器?修改DNS服务器常见问题汇总
- 笔记本电脑上html怎样运行,手提电脑如何进入BIOS|笔记本电脑进入BIOS按哪个键...
- Wincc报表案例_设备运行报表
- ROS资料----工业机器人 ROS-I Kinetic 培训课程
- 关于关于高博3d2d程序报错的改动
- Meta AI:让手绘小人动起来
- 儿童磁铁玩具,磁性积木片CPC认证,ASTM F963、CPSIA测试
- MX Player Pro 1.16.5 去广告版 — 安卓视频播放器