python爬虫-Python 爬虫介绍
一、什么是爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
二、Python爬虫架构
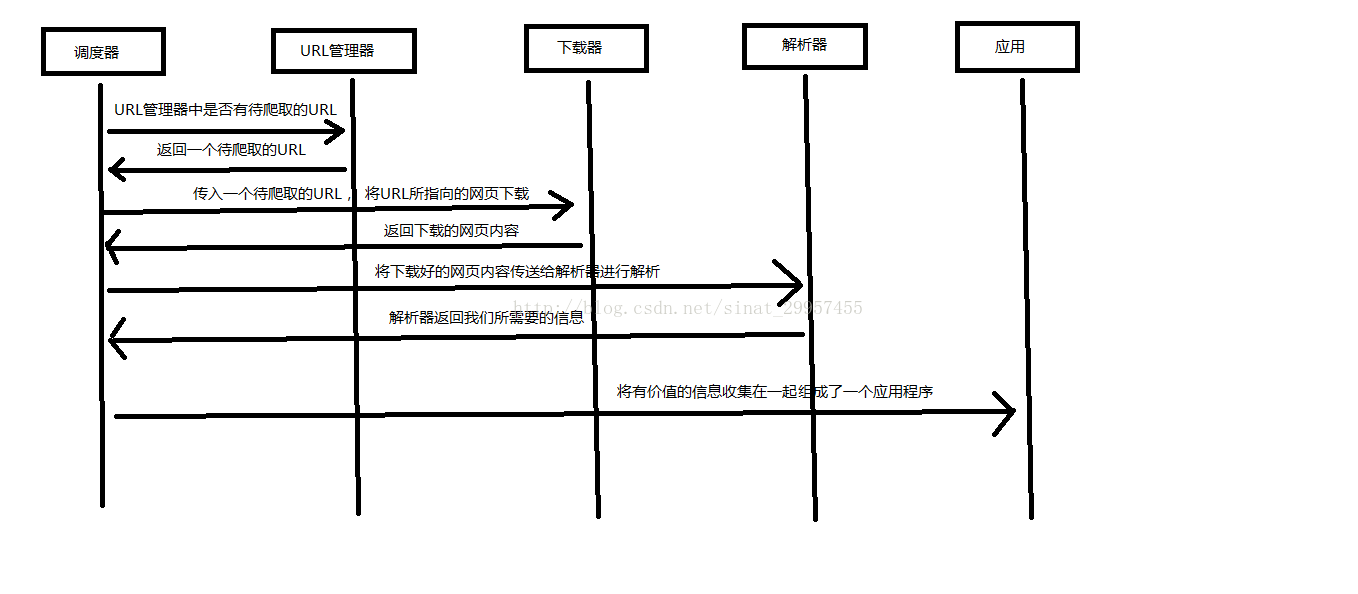
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一个图来解释一下调度器是如何协调工作的:
三、urllib2 实现下载网页的三种方式
#!/usr/bin/python# -*- coding: UTF-8 -*-importcookielibimporturllib2url="http://www.baidu.com"response1=urllib2.urlopen(url)print"第一种方法"#获取状态码,200表示成功printresponse1.getcode()#获取网页内容的长度printlen(response1.read())print"第二种方法"request=urllib2.Request(url)#模拟Mozilla浏览器进行爬虫request.add_header("user-agent","Mozilla/5.0")response2=urllib2.urlopen(request)printresponse2.getcode()printlen(response2.read())print"第三种方法"cookie=cookielib.CookieJar()#加入urllib2处理cookie的能力opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))urllib2.install_opener(opener)response3=urllib2.urlopen(url)printresponse3.getcode()printlen(response3.read())printcookie
四、第三方库 Beautiful Soup 的安装
Beautiful Soup: Python 的第三方插件用来提取 xml 和 HTML 中的数据,官网地址 https://www.crummy.com/software/BeautifulSoup/
1、安装 Beautiful Soup
打开 cmd(命令提示符),进入到 Python(Python2.7版本)安装目录中的 scripts 下,输入 dir 查看是否有 pip.exe, 如果用就可以使用 Python 自带的 pip 命令进行安装,输入以下命令进行安装即可:
pip install beautifulsoup4
2、测试是否安装成功
编写一个 Python 文件,输入:
import bs4
print bs4
运行该文件,如果能够正常输出则安装成功。
五、使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python# -*- coding: UTF-8 -*-importrefrombs4importBeautifulSouphtml_doc="""
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""#创建一个BeautifulSoup解析对象soup=BeautifulSoup(html_doc,"html.parser",from_encoding="utf-8")#获取所有的链接links=soup.find_all('a')print"所有的链接"forlinkinlinks:printlink.name,link['href'],link.get_text()print"获取特定的URL地址"link_node=soup.find('a',href="http://example.com/elsie")printlink_node.name,link_node['href'],link_node['class'],link_node.get_text()print"正则表达式匹配"link_node=soup.find('a',href=re.compile(r"ti"))printlink_node.name,link_node['href'],link_node['class'],link_node.get_text()print"获取P段落的文字"p_node=soup.find('p',class_='story')printp_node.name,p_node['class'],p_node.get_text()
原文地址:https://blog.csdn.net/sinat_29957455/article/details/70846427
python爬虫-Python 爬虫介绍相关推荐
- 「docker实战篇」python的docker爬虫技术-在linux下mitmproxy介绍和安装(四)
原创文章,欢迎转载.转载请注明:转载自IT人故事会,谢谢! 原文链接地址:「docker实战篇」python的docker爬虫技术-在linux下mitmproxy介绍和安装(四) 上次说了fiddl ...
- python windows自动化 爬虫_Python体系(网络爬虫、人工智能、WEB开发、自动化运维)详细介绍...
不论你是对Python初出茅庐,还是如指诸掌,这篇文章对你的收获总归还是有的啦,可能只是程度的问题.好了不扯远了,来说正题,下面在分享这套体系前还是要让Python做一下"自我介绍" ...
- python爬取大众点评数据_python爬虫实例详细介绍之爬取大众点评的数据
python 爬虫实例详细介绍之爬取大众点评的数据 一. Python作为一种语法简洁.面向对象的解释性语言,其便捷性.容易上手性受到众多程序员的青睐,基于python的包也越来越多,使得python ...
- Python爬虫神器简单介绍与使用(requests、Beautiful Soup、selenium等)
目录 一.requests 1.1.介绍 1.2.requests案例 二.BeautifulSoup 2.1.介绍 2.2.安装 2.3.BeautifulSoup案例 三.selenium 3.1 ...
- python爬虫面试自我介绍范文_走过路过不容错过,Python爬虫面试总结
Python爬虫面试总结 1. 写一个邮箱地址的正则表达式?[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$ 2. 谈一谈你对 ...
- python爬虫的原理介绍
一.爬虫与数据 (一)为什么要做爬虫 都说现在是大数据时代,但是与之相对应的问题是,大数据中的数据从何而来.可以人工收集数据,但是人工收集数据的效率却免不了太过低下.也可以找一些专门从事数据服务的公司 ...
- Python爬虫——scrapy框架介绍
一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等) ...
- python免费自学爬虫_这套Python爬虫学习教程,不到一天即可新手到进阶!免费领...
想用Python做爬虫,而你却还不会Python的话,那么这些入门基础知识必不可少.很多小伙伴,特别是在学校的学生,接触到爬虫之后就感觉这个好厉害的样子,我要学.但是却完全不知道从何开始,很迷茫,学的 ...
- python爬虫数据提取,Python 信息提取-爬虫,爬虫提取数据, import re
Python 信息提取-爬虫,爬虫提取数据, import re import requestsimport refrom bs4 import BeautifulSoupurl = "ht ...
- scrapy爬虫储存到mysql_详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # S ...
最新文章
- ARP欺骗防御工具arpon
- 今天微软的office 2010终于发布了!
- echarts自定义提示框数据
- Unity网格合并_材质合并[转]
- 网管菜鸟第一步:两年后必须跳槽『博客之星访谈』
- 写一个算法统计在输入字符串中各个字符出现的频度
- cmd52命令发送 mmc_乾坤合一~Linux SD/MMC/SDIO驱动分析(上)
- 关于Android定制Launcher
- Deep Learning for Brain MRI Segmentation: State of the Art and Future Directions
- 鲁汶大学提出可端到端学习的车道线检测算法
- 推荐一门免费提升开发效率的课程,非广告。
- 访问受限 诺基亚禁止Navifirm获取固件(图)
- hiveserver2启动不起来_125踏板车电启动发不着时,为什么很少用户使用脚启动?...
- 安卓版有道词典的离线词库-《21世纪大英汉词典》等
- java有序的Map-LinkedHashMap
- CMD命令创建文件夹快捷方式
- linux scl软件包下载,Centos7升级gcc版本方法之一使用scl软件集
- 显示器的bit是什么意思,8bit和10bit到底谁好
- 瀚高数据库和mysql区别,瀚高数据库----select用法
- Setting语言与输入法列表客制化
热门文章
- 微服务的隔离和熔断机制
- Stanford机器学习---第九讲. 聚类
- win10 + bazel-0.20.0 + tensorflow-1.13.1 编译tensorflow GPU版本的C++库
- ArrayList相关方法介绍及源码分析
- 创建私有 Gems 源
- 决策树-剪枝算法(二)
- java 防止sql注入的方法(非原创)
- undefined reference to '__android_log_print'解决方案
- C语言系列(二):最近重拾C语言的想法,谈到C中易错点,难点;以及开源代码中C语言的一些常用技巧,以及如何利用define、typedef、const等写健壮的C程序...
- 信息反馈-邮件(数据库是XML) (收集)