python爬虫教你如何快速搜索信息
很多时候,我们想要百度一个内容,却往往难以获得有用的信息,这时便需要进行必要的筛选,若是每次都点进连接中去查看,未免太过费时间,这里将利用python爬虫,快速帮你下载百度搜索的各条数据。
1.下面的代码使用时有如下条件:
- 安装了火狐浏览器
- 安装了火狐驱动,可前往https://github.com/mozilla/geckodriver/releases下载
- 安装所需要的相关包,运行时会提示的,推荐使用pip安装
2.这里更重要的还是学习相关技术
- selenium的使用(一款自动化测试工具,这里用在爬虫技术中,用于模拟用户行为,可以解决绝大部分的反爬行为)
- xpath解析的学习
3.开始写代码
3.1导包
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
import os
import time
3.2全局配置
save_path = 'D:\\桌面' # 文件路径
filename = "结果集"
3.3主类main函数(selenium相关操作)
if __name__ == "__main__":key_world = input("请输入您想要搜索的内容:")num = int(input("请输入您想要爬取的页数:"))filename = input("请输入您想要存储的文件名:")urls = [] # 页码索引列表for i in range(num):url = "https://www.baidu.com/s?wd=" + key_world + "&pn=" + str(i * 10) + "&oq=" + key_world + "&ie=utf-8&rsv_pq=da6a000c0001b80d&rsv_t=d7f5m3K7D2ij87xFqs1%2FBxTHWIIxqW6xVfayx6TdZRvpTSctGF1ObM1gLKs"urls.append(url)driver = webdriver.Firefox()for u in urls:driver.get(u)myPage = driver.page_source # 获取源码spider(myPage)time.sleep(2)driver.quit()
第一个for循环是根据百度的搜索规律,将搜索内容接入后拼接而成的网址,根据你所需要的页数,把他们放到一个列表中去。随后开启selenium,自动打开火狐浏览器,根据上面的网址列表,分别去遍历,也就是得到每一个网址所对应的以及页面,将该页面的源代码通过page_source方法下载下来,交由spider去解析和存储
3.4爬虫spider
def spider(myPage):results = Page_Level(myPage) # 解析html文档获得结果FileSave(results)# 将结果存储到txt文档中
3.5一级页面,数据解析(xpath的使用)
def Page_Level(myPage): # 一级页面dom = etree.HTML(myPage)results = []channel_names = dom.xpath('//*[@id="content_left"]/div')for channel in channel_names:try:summary = channel.xpath('div[@class="c-abstract"]/text()')title_link = channel.xpath('div[@class="f13"]/div[1]/@data-tools')print(title_link[0])results.append("【" + title_link[0] + "\n" + str(summary) + "】\n\n")except:passreturn results
利用xpath方法提取出文档中的标题,地址,将要概述
3.6数据存储(保存为txt文档)
def FileSave(results):if not os.path.exists(save_path): # 判断文件路径是否存在,若不在,则创建os.mkdir(save_path)path = save_path + os.path.sep + filename + ".txt"with open(path, 'a+', encoding='utf-8') as fp:for i in results:fp.write("%s\n" % (i))
最后,附上完整的代码
# -*- coding: utf-8 -*-
from selenium import webdriver
from lxml import etree
import os
import time# 全局配置
save_path = 'D:\\桌面' # 文件路径
filename = "结果集"# 保存为TXT文档
def FileSave(results):if not os.path.exists(save_path): # 判断文件路径是否存在,若不在,则创建os.mkdir(save_path)path = save_path + os.path.sep + filename + ".txt"with open(path, 'a+', encoding='utf-8') as fp:for i in results:fp.write("%s\n" % (i))
# 一级页面爬取
def Page_Level(myPage): # 一级页面dom = etree.HTML(myPage)results = []channel_names = dom.xpath('//*[@id="content_left"]/div')for channel in channel_names:try:summary = channel.xpath('div[@class="c-abstract"]/text()')title_link = channel.xpath('div[@class="f13"]/div[1]/@data-tools')print(title_link[0])results.append("【" + title_link[0] + "\n" + str(summary) + "】\n\n")except:passreturn results
# 爬虫
def spider(myPage):results = Page_Level(myPage) # 解析FileSave(results)#存储
# 运行
if __name__ == "__main__":key_world = input("请输入您想要搜索的内容:")num = int(input("请输入您想要爬取的页数:"))filename = input("请输入您想要存储的文件名:")urls = [] # 页码索引列表for i in range(num):url = "https://www.baidu.com/s?wd=" + key_world + "&pn=" + str(i * 10) + "&oq=" + key_world + "&ie=utf-8&rsv_pq=da6a000c0001b80d&rsv_t=d7f5m3K7D2ij87xFqs1%2FBxTHWIIxqW6xVfayx6TdZRvpTSctGF1ObM1gLKs"urls.append(url)driver = webdriver.Firefox()for u in urls:driver.get(u)myPage = driver.page_source # 获取源码spider(myPage)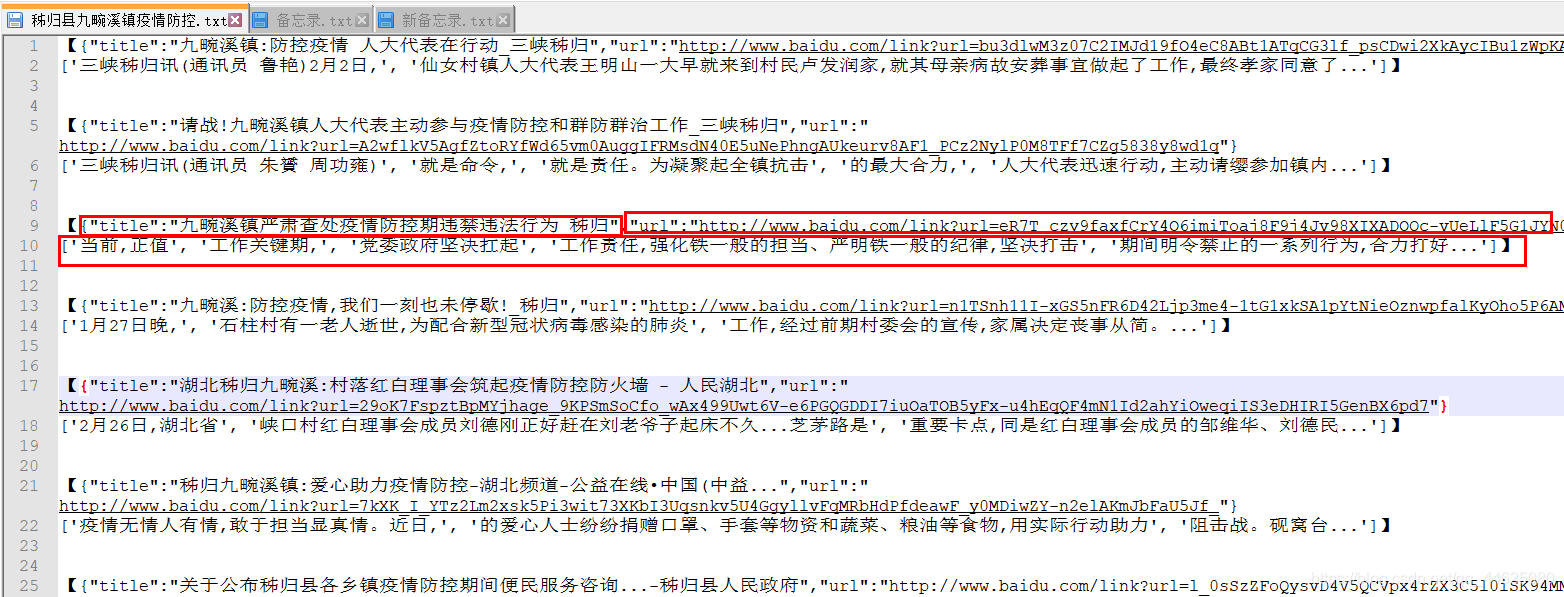time.sleep(2)driver.quit()最终的效果如图
![]()
更多爬虫实例,可前往本人码云仓库
https://gitee.com/lk0423/spider
python爬虫教你如何快速搜索信息相关推荐
- Python爬虫教你爬取视频信息
大家好,我是拉斯,今天分享一个爬取某音视频的一个小案例,大家一起学习 目录 前言 基本环境配置 爬取目标视频 获取视频链接 1.查看网页源代码 2.抓包工具捕捉 下载视频(以mp4格式进行保存) 获取 ...
- python爬虫实践——零基础快速入门(四)爬取小猪租房信息
上篇文章我们讲到python爬虫实践--零基础快速入门(三)爬取豆瓣电影 接下来我们爬取小猪短租租房信息.进入主页后选择深圳地区的位置.地址如下: http://sz.xiaozhu.com/ 一,标 ...
- python爬虫怎么挣钱?快速赚钱渠道有哪些?
Python 语言这几年非常的火,大家学习 Python 除去为了获取新知识,很多朋友也想知道我学会了 Python 到底怎么转换成经济上的收益呢?那么W3Cschool小编今天就和大家分析一下 Py ...
- python爬虫代码房-Python爬虫一步步抓取房产信息
原标题:Python爬虫一步步抓取房产信息 前言 嗯,这一篇文章更多是想分享一下我的网页分析方法.玩爬虫也快有一年了,基本代码熟悉之后,我感觉写一个爬虫最有意思的莫过于研究其网页背后的加载过程了,也就 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- python爬虫实现爬取网页主页信息(html代码)
python爬虫实现爬取网页主页信息(html代码) 1.爬取网站源码 urllib整体介绍: urllib是一个包,收集几个模块来处理网址 urllib.request打开和浏览url中内容 url ...
- python爬虫--小猪短租的租房信息
python爬虫--小猪短租的租房信息 利用requests获取网页 利用Beautifulsoup4和lxml解析网页 具体代码如下 from bs4 import BeautifulSoup im ...
- Python爬虫:Xpath爬取网页信息(附代码)
Python爬虫:Xpath爬取网页信息(附代码) 上一次分享了使用Python简单爬取网页信息的方法.但是仅仅对于单一网页的信息爬取一般无法满足我们的数据需求.对于一般的数据需求,我们通常需要从一个 ...
- python爬虫实战之图灵社区图书信息的爬取(找了久,才找到一个比较好爬取的网站)
python爬虫实战之图灵社区图书信息的爬取 程序的描述 目标 获取图灵社区(https://www.ituring.com.cn/book)中40本图书的书名 将获取的信息以列表的形式输出到屏幕上, ...
最新文章
- 基于点云强度的3D激光雷达与相机的外参标定
- 阿里云应用性能管理(APM)产品-应用实时监控服务(ARMS)技术解密 资料下载...
- 使用命令导入sql文件到mysql数据库时报Failed to open file错误的解决方案
- keras系列︱keras是如何指定显卡且限制显存用量
- 剑指offer java 博客_Java--剑指offer(10)
- 计算机系统字的描述性定义,CTCS系统11CTCS系统描述定义
- oracle创建表空间 扩展表空间文件 修改表空间自动增长
- Sphinx编译docs文档
- wordpress 添加小工具分类
- 详细解析Java中抽象类和接口的区别(很容易理解错)
- linux下iconv编码转换的用法
- 不依赖浏览器控制台的JavaScript断点调试方法
- JAVA中获取工程路径的方法
- DOM—外部插入.after()、.before()、.insertAfter()和.insertBefore()与内部插入.prepend()和.prependTo()...
- 高通模式9008模式linux,学会小米9008高通模式_原来刷机如此简单
- 数字信号处理笔记02:离散时间傅里叶变换(DTFT)
- 计算机便签中字的大小,Windows便签字体怎么调整?电脑便签怎么改字体大小
- win10无限蓝屏_升级 Win10 后系统蓝屏或无限重启的解决方法之一
- linux查看最后几行命令,linux查看文件的后几行(文件查看 如何显示最后几行 ,某几行)...
- Tomcat文件服务器上传文件出错