大数据同步利器: 表格存储全增量一体消费通道
表格存储(Table Store)是阿里云自研的NoSQL多模型数据库,提供海量结构化数据存储以及快速的查询和分析服务,表格存储的分布式存储和强大的索引引擎能够提供PB级存储、千万TPS以及毫秒级延迟的服务能力。
本文会给大家详细介绍表格存储重磅推出的一项新功能--全增量一体数据通道。文章会为大家阐述数据通道的主要使用场景,表格存储数据通道的功能优势,并带大家快速入门如何使用数据通道来消费数据。
什么场景需要数据通道
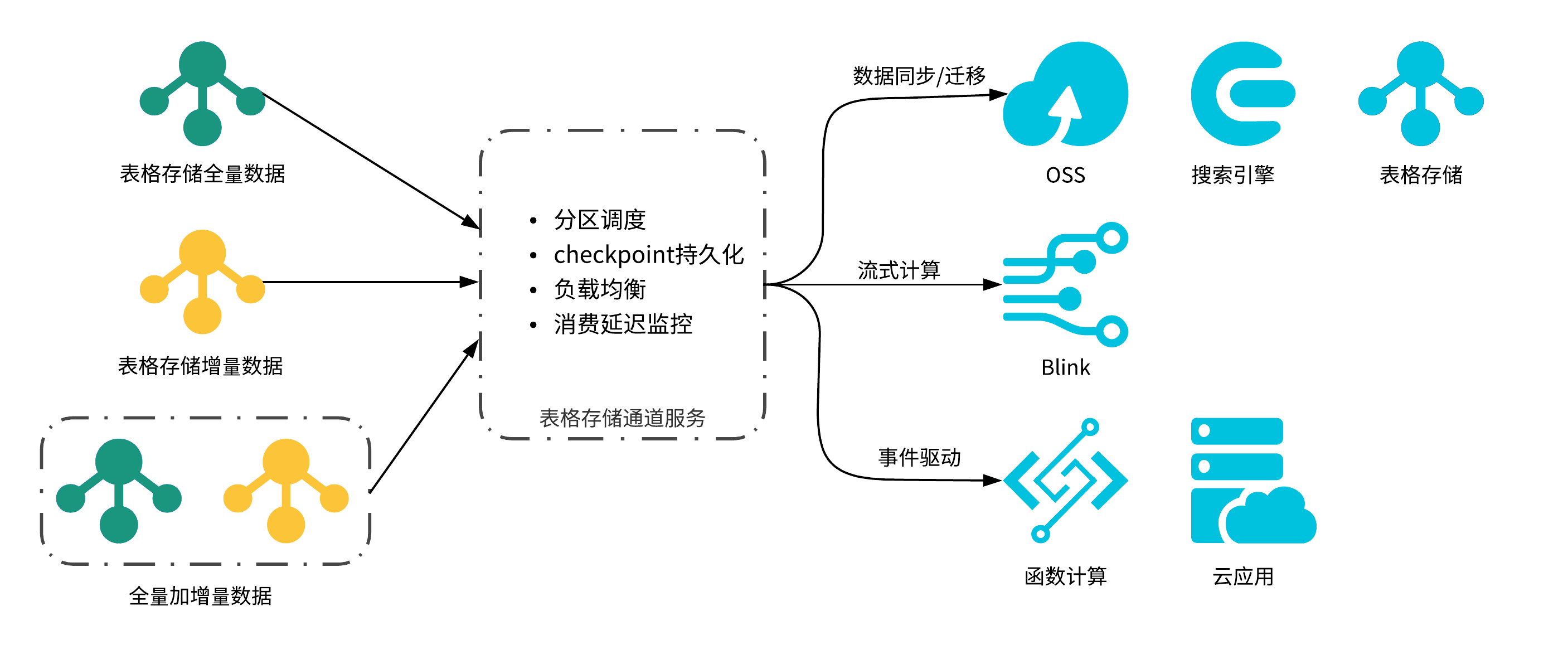
图-1 数据通道的主要应用场景
如图-1展示,数据通道的使用场景主要分为四大类:
- 数据同步场景,很多时候,用户的数据除了存储在表格存储外还需要同步到其他系统,比如把实时写入的数据按顺序同步到Redis做本地cache,同步到自建的elastic search来支持检索,同步到OSS做归档[拓展阅读6],或是同步到容量型表格存储做冷热数据分层[拓展阅读7]等等,通道服务提供了全量、增量、全量加增量三种通道类型来支持不同的同步需求,同时保证数据保序、吞吐速度水平扩展、提供同步延迟监控;
- 数据移动场景,用户也会有很多数据迁移的场景,比如将实例从一个区域迁移到另一个区域,从容量型替换为高性能实例,或是拆表等等,通道服务实现了全量数据消费无缝切换为增量数据消费,不需要业务停写,大大简化迁移任务复杂度;
- 大数据分布式计算架构,常见的大数据场景如爬虫大数据分析系统[扩展阅读9]、舆情风控系统、IOT智能制造场景、画像推荐系统等,其基本架构都是Lambda大数据架构,业务在写入数据库的同时需要将数据同步到消息队列和数仓系统来支持不同的计算引擎,架构依赖多个开源系统,而表格存储通道服务做到了数据存储和数据处理all in one,数据只需写入表格存储,对接blink流批一体处理引擎,极大地降低了大数据系统搭建门槛[利用表格存储和blink的计算架构可见拓展阅读5];
- 事件驱动,很多微服务架构,都会用事件驱动的方式解耦不通的业务逻辑,比如在线业务把数据写入表格存储后,异步触发其他业务的serverless计算函数或者其他事件订阅系统,订阅系统可以利用通道服务灵活消费表格存储的实时数据,函数计算更是直接将表格存储数据通道作为事件源触发函数[拓展阅读8];
总之,表格存储利用其强大的分布式引擎写入能力和完备的数据通道功能,做到了让用户的数据存储和数据消费All in one! 使用表格存储,缩减了用户系统架构中的外部依赖,也避免引入数据同步和多写一致性问题,大大降低上述四大类场景的技术门槛和人力成本。
表格存储通道服务的优势
从主流传统数据库到NoSQL数据库,从开源产品到云产品,都已经有一些数据通道相关的解决方案了,表格存储数据通道从功能上与主流自建消费通道对比如下:
| 功能 | 表格存储通道服务 | MySQL数据同步 | Hbase replication框架 | AWS Dynamodb stream |
|---|---|---|---|---|
| 同步功能 | 全量加增量数据同步,全量复制到增量同步无缝切换 | 分离的全量复制任务和增量同步任务,需要业务方设计切换方案 | 增量数据同步 | 增量数据同步 |
| 数据一致性 | 支持保序协议 | 支持保序协议 | 无保序协议保证一致性 | 支持保序协议 |
| 扩展性 | 数据规模水平扩展 | 单机数据库同步 | 数据规模水平扩展 | 数据规模水平扩展 |
| 易用性 | 多语言SDK | 需自建方案或使用开源实现 | 自建Hbase replication log监听 | 使用AWS KCL client |
| 运维监控 | RPO消费监控 | 需自建监控 | 无RPO监控 | 无RPO监控 |
| 计算对接 | 直读对接阿里云流计算(Blink) | 需导出到数仓或消息队列 | 需导出到数仓或消息队列 | 需Kinesis适配器对接 |
| 负载均衡 | 基于RPO自动负载均衡 | 单机数据库同步 | 无负载均衡 | KCL client负载均衡 |
不少的开源数据系统和计算引擎都实现了从MySQL到自身的数据同步方案,以solr的MySQL全量、增量同步方案为例,用户需要建立全量导入任务full import和增量同步任务delta import,并且需要根据自身业务安排两个任务的先后顺序、抑或是否需要业务停写等,同时需要自建同步延迟监控,避免同步滞后和堆积。在对接计算引擎方面,MySQL用户通常通过数据同步把数据导入到数据仓库或者消息队列,进而接入计算引擎,引入了额外的存储依赖和数据冗余,比较复杂。
Hbase上的增量数据可以通过复用Hbase replication框架实现增量数据消费,参照Lily Indexer实现,但是replication会引入离线推送和Hbase在线服务的资源竞争,也需要较高的技术门槛解决传输优化、热点问题。同时HBase的日志顺序通过数据上的时间戳决定,在时钟回退和消费超时时的日志乱序问题难以避免。总体来说,该方案的技术门槛和运维成本都很高,消费场景也需要容忍日志乱序。
AWS Dynamodb stream是Dynamodb的实时数据处理解决方案,DynamoDb会为用户保存最近24小时的数据操作日志,支持用户以partition粒度并发消费,同时保证增量日志有序。Dynamodb stream不支持导出全量数据,但很多同步场景需要先处理全量的历史数据随后在开始消费后续的增量数据,另外其复用了KCL实现partition的消费租约、管理partition拓扑关系、持久化每个partition的checkpoint,逻辑很重,没有对应语言KCL client时使用难度比较大。
相对于以上方案,表格存储通道服务的主要功能优势有:
- 全增量一体,不仅提供增量数据消费,还提供可并行的全量数据消费和全量加增量数据消费,并实现全量复制到增量同步状态无缝切换;
- 增量数据保序,通道服务会为用户数据划分一到多个可并行消费的逻辑分区,每个逻辑分区的增量数据保序,不同逻辑分区的数据可以并行消费;
- 消费延迟监控,通道服务通过DescribeTunnel API提供了客户端消费数据RPO(恢复点目标,recovery point objective)信息,并在控制台提供了通道数据消费监控;
- 水平扩展,通道服务会平均分配可消费的分区,用通过增加消费端数量,扩展自身实时处理能力;
- 自动负载均衡,合理消费速度的通道用户,在其RPO消费延迟增大时,通道服务会自动触发分区分裂,增大用户通道的消费并发;
快速入门
通道服务可以在控制台即开即用,计费上同其他数据读API一样仅按读取数据CU计费(按量、预留以及资源包),并可以在控制台管理和监控通道消费进度和状态。接下来就带大家快速体验一下通道服务的开通、数据消费、消费延迟监控和水平扩展。
- 首先,我们在控制台选择已经已有部分数据的表,建立全量加增量数据通道,目的是通过通道先消费完所有存量数据,再按顺序实时消费后续新写入的数据;
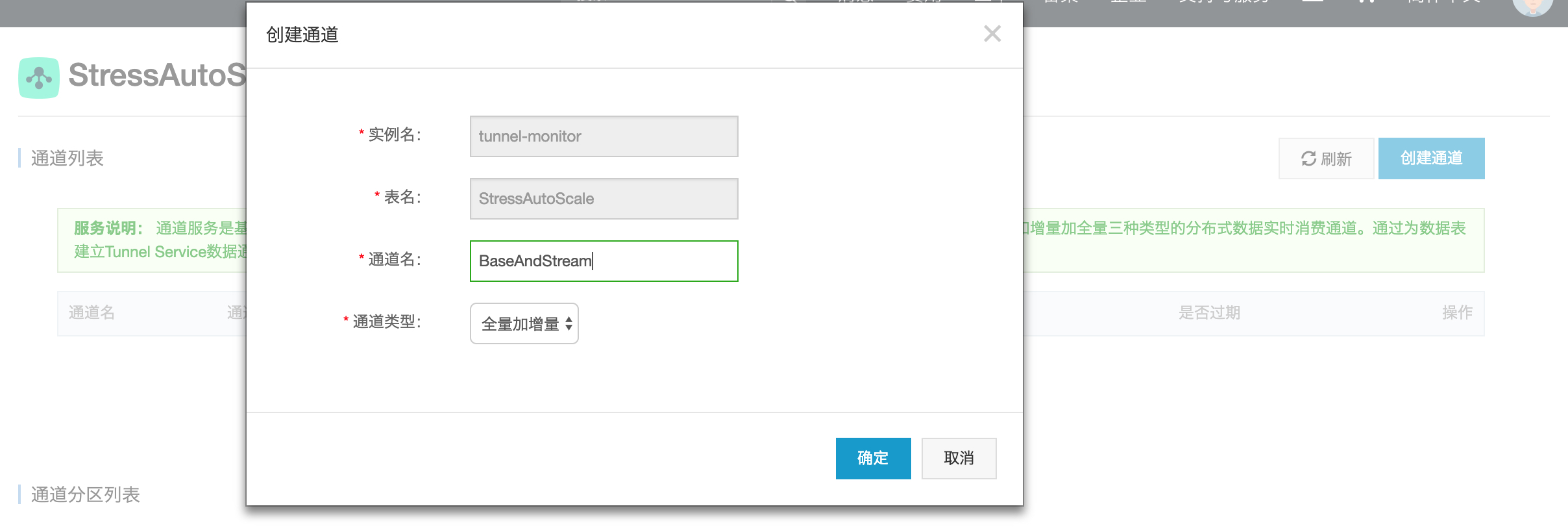
图-2 创建一个全量加增量类型的通道
可以看到创建后通道的通道ID和分区信息:
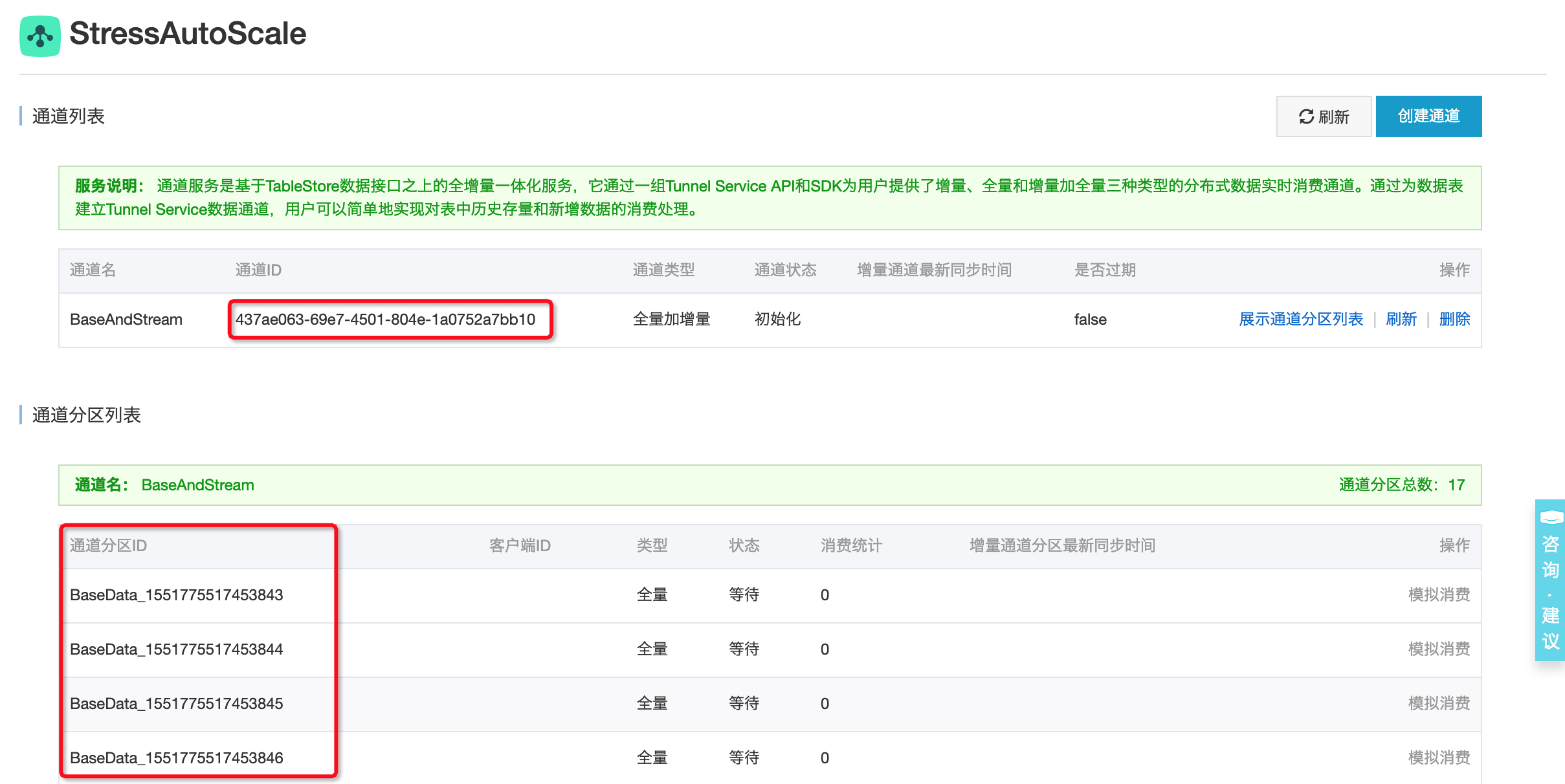
图-3 通道的ID和分区信息
复制通道ID,通过Java SDK实现通道服务IProcessor接口的消费函数,打印从通道读取的数据,体验从通道开始数据消费;
// 用户自定义数据消费 Callback,即实现IChannelProcessor 接口(process和shutdown)。 private static class SimpleProcessor implements IChannelProcessor {@Override// ProcessRecordsInput 中包含拉取到的数据。public void process(ProcessRecordsInput input) {System.out.println("Default record processor, would print records count");System.out.println(String.format("Process %d records, NextToken: %s", input.getRecords().size(), input.getNextToken()));try {// Mock Record Process.Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}@Overridepublic void shutdown() {System.out.println("Mock shutdown");} }public static void main() throws Exception {// 1. 初始化Tunnel Client。// endPoint 为表格存储实例 endPoint,如https://instance.cn-hangzhou.ots.aliyuncs.com。// accessKeyId 和 accessKeySecret 分别为访问表格存储服务的 AccessKey 的 Id 和 Secret。TunnelClient tunnelClient = new TunnelClient(endPoint, accessKeyId, accessKeySecret, instanceName);// 2. 填入创建好的tunnelId,开始数据消费// TunnelWorkerConfig里面还有更多的高级参数,这里不做展开,会有专门的文档介绍。TunnelWorkerConfig config = new TunnelWorkerConfig(new SimpleProcessor());TunnelWorker worker = new TunnelWorker(tunnelId, tunnelClient, config);try {worker.connectAndWorking();} catch (Exception e) {e.printStackTrace();worker.shutdown();tunnelClient.shutdown();}}- 执行上述代码,可以看到读出每个批次通道数据的数据行数输出;
- 从控制台的通道服务页面(也可以直接调用describeTunnel API),可以看到通道的消费延迟和分区消费数据量;
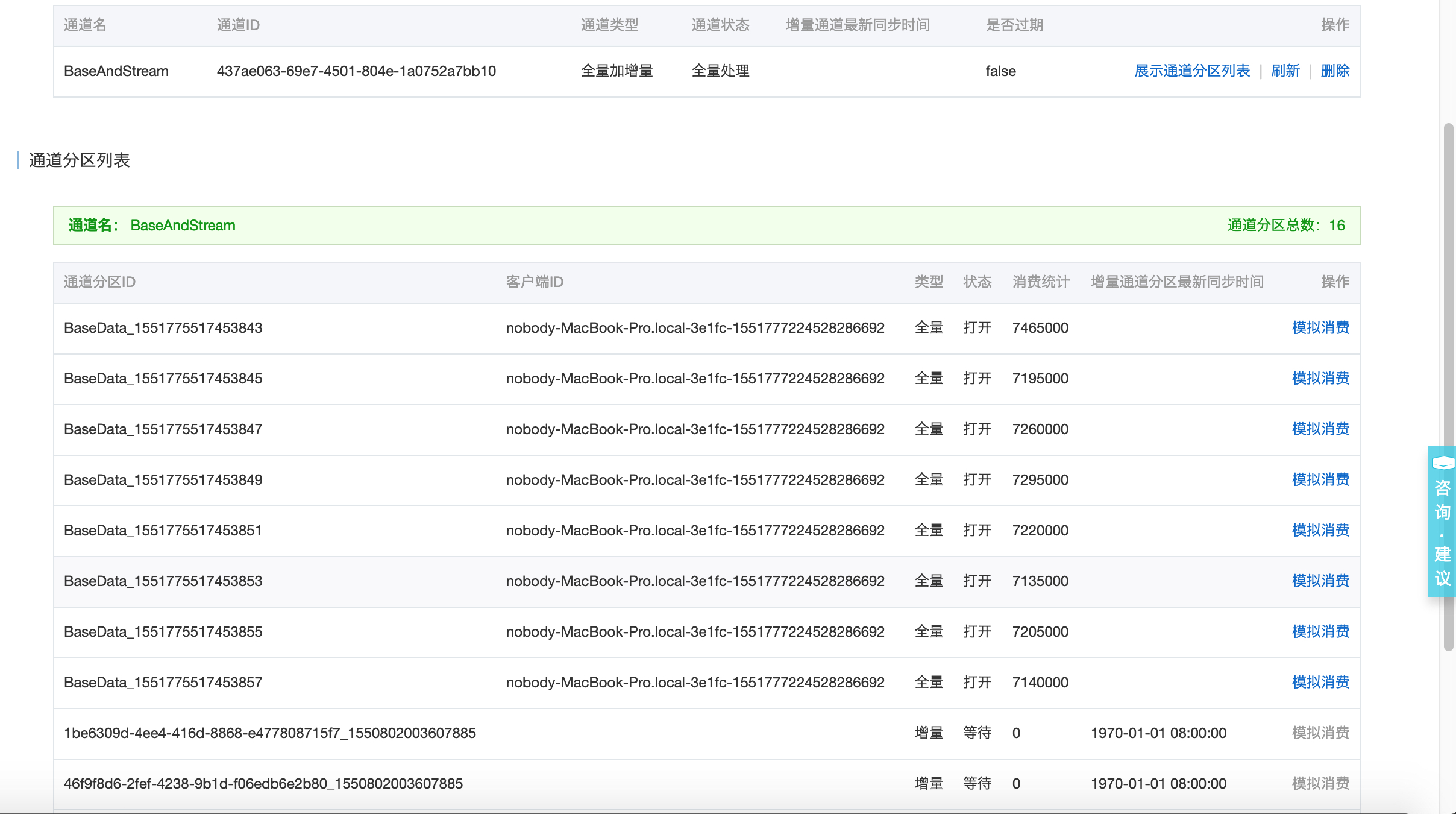
图-4 全量阶段的分区消费数据量
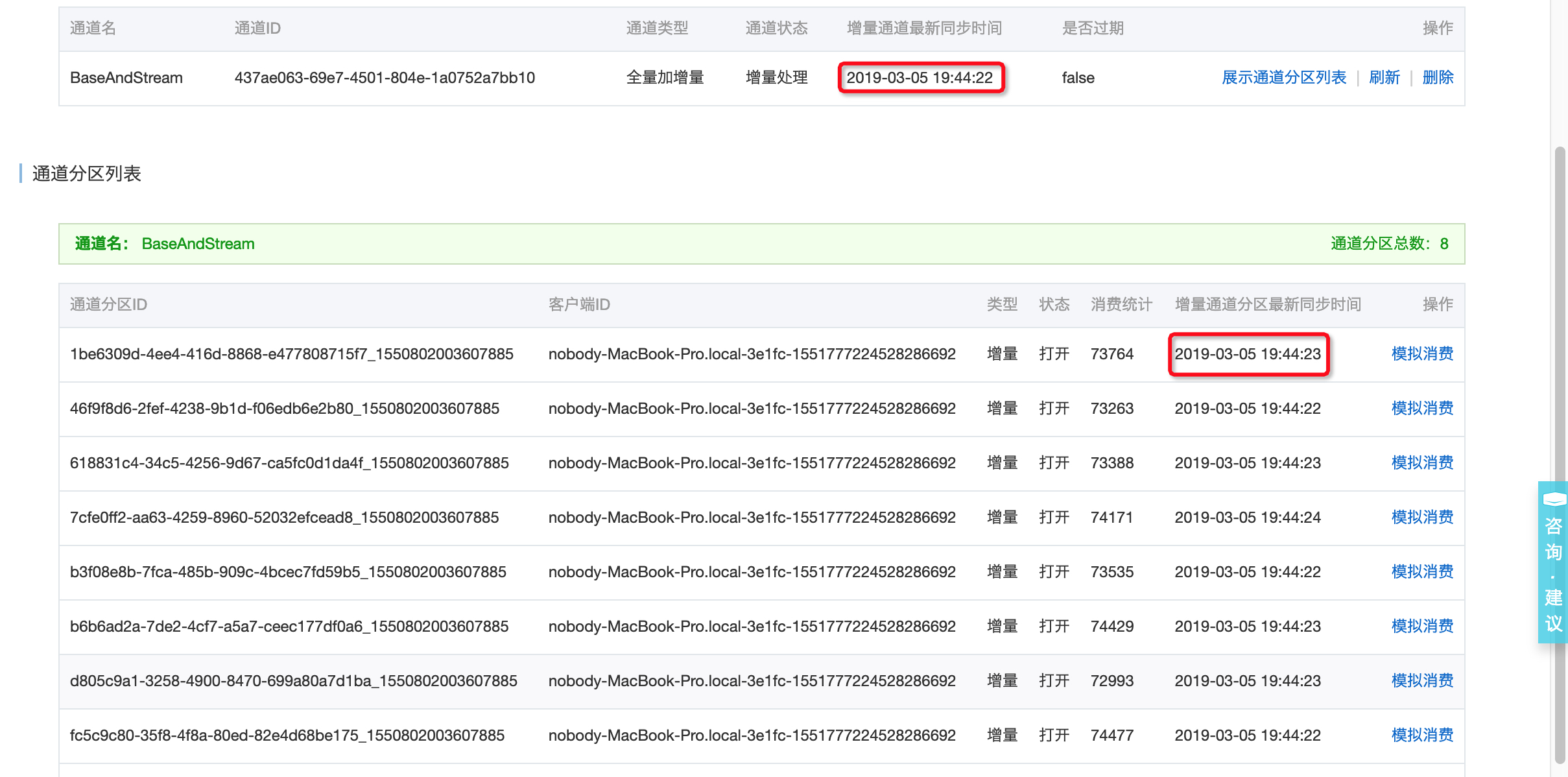
图-5 增量阶段的消费延迟和分区消费数据量
- 如果数据表有多个数据分区(数据量比较大时),从控制台可以看到多个channel均在同一个clientID下消费,再启动一个进程运行上述消费代码,稍等片刻(一分钟内),可以看到部分channel被负载均衡到两个clientID下,实现消费端水平扩展;
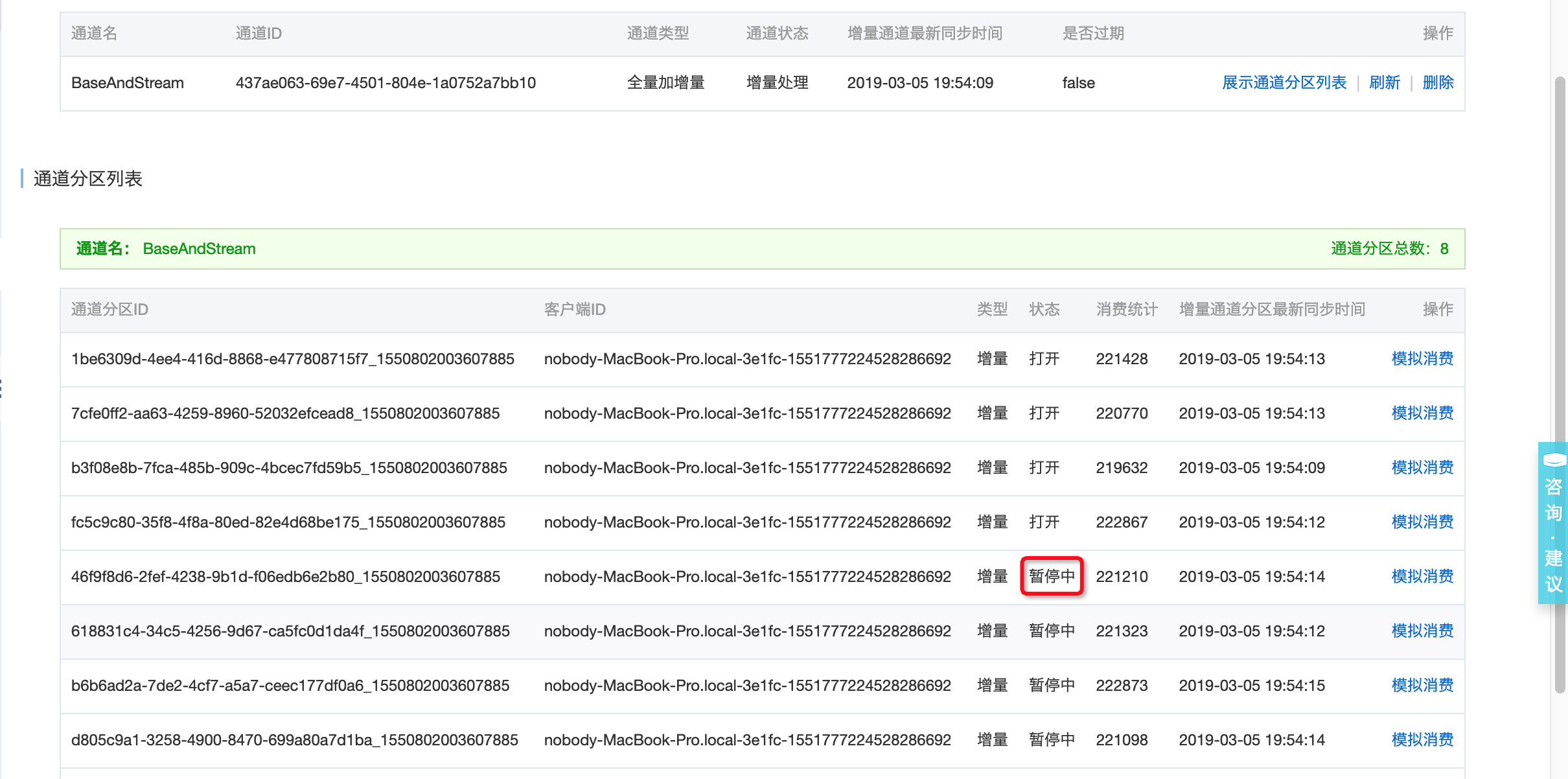
图-6 数据通道负载均衡中
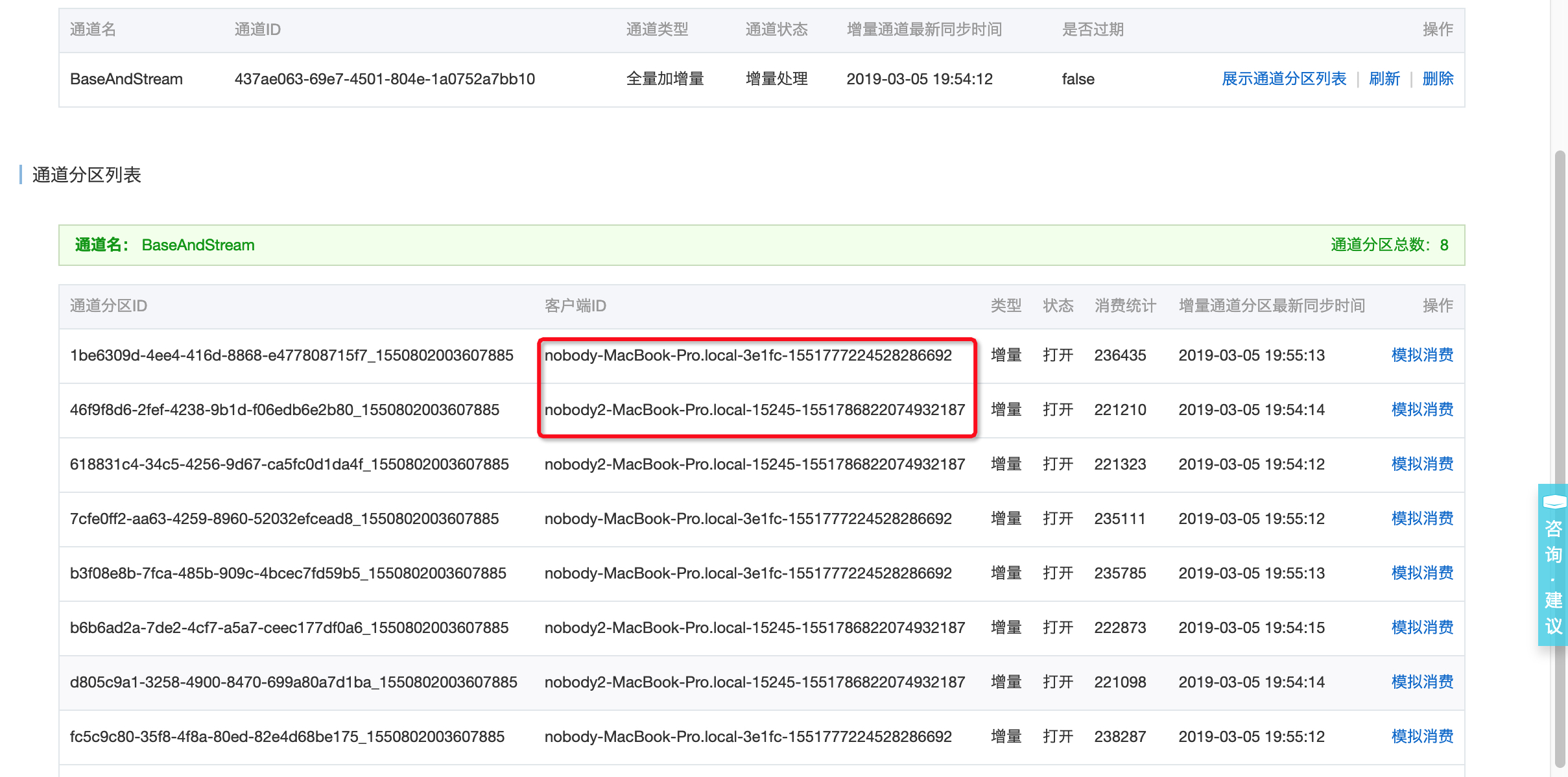
图-7 数据通道负载均衡完毕
扩展阅读
[1] 表格存储通道服务官网文档
[2] 表格存储通道服务Java SDK
[3] 表格存储通道服务Golang SDK
[4] 表格存储通道服务性能白皮书
[5] 实时计算的最佳实践:基于表格存储和Blink的大数据实时计算
[6] 使用表格存储通道服务实现到OSS的数据归档
[7] 使用表格存储通道服务实现冷热数据分层
[8] 函数计算使用表格存储触发器
[9] TableStore:爬虫数据存储和查询利器
参考文献
- Solr Data Import Handler
- Hbase replication
- AWS Dynamodb stream
- Lambda大数据架构
- blink流批一体处理引擎
大数据同步利器: 表格存储全增量一体消费通道相关推荐
- 大数据同步利器: 表格存储全增量一体消费通道 1
表格存储(Table Store)是阿里云自研的NoSQL多模型数据库,提供海量结构化数据存储以及快速的查询和分析服务,表格存储的分布式存储和强大的索引引擎能够提供PB级存储.千万TPS以及毫秒级延迟 ...
- 【硬刚大数据】大数据同步工具之FlinkCDC/Canal/Debezium对比
欢迎关注博客主页:微信搜:import_bigdata,大数据领域硬核原创作者_王知无(import_bigdata)_CSDN博客 欢迎点赞.收藏.留言 ,欢迎留言交流! 本文由[王知无]原创,首发 ...
- “云+大数据”时代 中端存储如何选择
云计算.大数据,随着这两个技术词汇在越来越多的映入我们眼帘的同时,一方面企业级IT基础架构也在随之在潜移默化的改变着."云+大数据"时代,在很多人看来,首先想到的是,大数据和私有云 ...
- 富士通大数据架构解决方案闪耀存储峰会
文章讲的是富士通大数据架构解决方案闪耀存储峰会,世界领先的ICT综合服务商富士通(Fujitsu)近日亮相2013(第九届)中国存储峰会.作为目前国内存储界规模最大和历史最长的存储大会,本届存储峰会以 ...
- 数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体
作者 |关涛.李睿博.孙莉莉.张良模.贾扬清(from 阿里云智能计算平台) 黄波.金玉梅.于茜.刘子正(from 新浪微博机器学习研发部) 编者按 随着近几年数据湖概念的兴起,业界对于数据仓库和数据 ...
- 基于 Apache Flink Table Store 的全增量一体实时入湖
摘要:本文简要回顾了数据入湖(仓)的发展阶段,针对在数据库数据入湖中面临的问题,提出了使用 Flink Table Store 作为全增量一体入湖的解决方案,并辅以开源 Demo 的测试结果作为展示. ...
- 在百度地图大数据下,看后疫情时代的消费变化
文|曾响铃 来源|科技向令说(xiangling0815) 五一假期成为了后疫情时代的一个焦点. 原因无他,作为疫情以来的第一个小长假,不管是从社会的角度,还是从市场的方向,人们都希望能在这个节点上看 ...
- Elasticsearch和MySQL数据同步(logstash-input-jdbc)全量增量方式同步近千万数据
同步方案: 同步读写:最为简单的方式在将数据写到mysql时,同时将数据写到ES,实现数据的双写. 异步双写(MQ方式):MQ的性能基本比mysql高出一个数量级,所以性能可以得到显著的提高. 定时器 ...
- 大数据中台架构以及建设全流程一(Paas层设计)
目录 设计背景 问题点 中台目标 复用,赋能,降本增效 中台整体架构 Pass层技术选型 实时存储平台----------->KAFKA(未来pulsar也不错) 离线存储平台(Hadoop系列 ...
最新文章
- 国内 Java 开发者必备的两个神器:Maven国内镜像和Spring国内脚手架
- VTK:图片之ImageWarp
- 'SVN更新' has encountered a problem :An internal error occurred during: svn错误
- 一个有用的Chrome扩展应用:SAP UI5 Inspector
- 苹果CMS的V10版本后台登录一直提示验证码错误的解决方案
- Project: 项目经理新建资源预订
- Recoverit for Mac专业的数据恢复工具
- ubuntu窗口排列和分屏工具
- 模拟实现透明网桥的自学习与过滤功能
- 中首清算:“股神”很闹心,巴菲特曾割肉的航空股竟连续领涨?
- dxf解析python_Python 读取DXF文件
- 阿里easyexcel读取excel流程初探
- c语言c4700错误,C编译错误,运行错误以及常见问题。
- AttributeError: module ‘scipy.signal‘ has no attribute ‘correlation_lags‘
- CDA数据分析师认证辅导课
- Win10清理鼠标右键新建菜单
- linux 进程流量统计,Linux进程网络流量统计方法及实现
- Marktext语法——Emoji表情大全
- 《新概念英语》英语的学习方法(完整版)
- Qt中QPainter的使用