7. CUDA内存访问(一)提高篇------按部就班 ------GPU的革命
序言:从上一篇《 CUDA编程接口(二)------一十八般武器》到现在,差不多有三个月了,不知道大家在“暑假”里面过得怎么样,又经历了什么?花了两个星期的睡觉前的时间,看完了《明朝那些事儿》的第五本,看看明朝的兵器,再想想自己学习的飞行器设计专业,感慨万千。明朝的兵器已经是当时世界最先进的水平了,可是现在的情况,飞行器设计专业出来的我,看到国外飞机的发展,只是感觉脸庞发热,泱泱大国,经历了几个世纪的创伤,到什么时候才能恢复当年盛世,万国朝拜。看到奥运中国的金牌数飞速的上升,当人们还在关注金牌数的时候,却又多少人真正理解体育的意义?体育精神不只是金牌,看看中国的金牌数和奖牌总数,再看看美国的奖牌总数,或许也只能说,改革开放让一部分人先富起来,体育也不例外。看崔永元主持的奥运节目,更多的关注的都是没拿到金牌的运动员,值得反思……从初中校足球队一员,到高中校田径队一员,大学参加过很多运动会;从小学的每次运动会倒数第一,到高中平校记录,到大学,破学院的记录,又有多少人明白期间多少年的锻炼的过程?又有多少人明白其中坚持的意义?或许只有运动员自己明白。参与、感受、坚持,每一次起跑背后是多少次的磨炼;每次终点过后,还会有多少人关注?用心去体会,用心去感受,用更包容的心去对待别人,也会得到别人更宽容的心。或许是这三个月又经历了一些,感情,金钱,事业……每一个过程,每一个心态,坚持下来,跨过去一个事情的时候,就是一个小case了,坚持~go on!
言归正传:谈到内存的访问,其实也就是几个API函数的调用,感觉也没什么好讲的,知道cudaMalloc,知道cudaMemcpy,还有cudaFree,就应该可以对device上的内存进行分配,然后就可以在device上使用内存。但是就像我们看运动会一样,只看100米的那不到10秒的时间,也许你只会说,他跑得真快。又有多少人能清楚其过程中的磨炼啦?要真正理解device上内存的调度访问,让我们的程序达到更快的速度,就得对内存访问的情况做更深入的了解,明白其中的过程。
我记得大学刚开始上编程语言的课程的时候,都会讲到内存的分配和内存的释放,但是一般都是在书的最后面才会讲内存的对齐,内存的空间布局。就像C++一样,或许你学习了好几年,用了它好多年,但是你是否清楚class的内存布局?知道虚表是怎么一个内存访问过程?就像做网络,当做到一定地步的时候,才会发现数据从一段传递到另一段的时候数据发生了变化,内容不对了,定义的结构体传递到另一边的时候就错位了。当在使用SSE对数据处理加速的时候,是否为内存对齐的问题头疼?说了这么多,或许有人在烦了~~~讲正题吧,这些部分或许只有自己真正在实际运用中遇到问题,才会去考虑的,不过还是希望大家能在遇到问题之前,就能掌握解决问题的能力。不是在遇到美女的时候才开始刮胡子,平时的习惯就要养好。
前面这一段话或许只是生活的一些经历,其实可以跳过,当遇到的时候再回来看看:)我们还是按部就班的来讲解device上内存的访问吧。这么多年的发展,内存的价格是越来越便宜,但是有谁知道当你做编织内存的时候,很多人的眼睛都被弄瞎过啦,为她们当年为计算机作出的贡献bless一下。
还记得小时候经常看枪战片,看到小马哥端着枪一个劲的扫射,哪个帅啊~~不过后来稍微大一些以后,心理面一直有一个疑问,子弹用不完?一次能装多少子弹啊~就那么小的弹夹。8发子弹的左轮手枪在帅哥哥手里可以搞定十几个人~还不装弹- 囧!一般的自动手枪一般都是8发,14发,最多的驳壳枪(毛瑟枪)也才能装20发子弹。你要说人家是《第一滴血4》里面的史泰龙可以开着战车上面的M2HB12.7mm重机枪,子弹不用弹夹,一次可以装几千发的弹;对,人家是DMA直接内存访问,不是通过弹夹访问的,不需要处理器来中转数据。G80支持的内存访问的能力是一次访问4bytes,8byets或者16bytes,G80有三种弹夹,一种可以一次装4发子弹,一种是8发子弹,还有16发的。
Global Memory 在访问过程中没有Cache,就像以前的火枪一样,打一枪以后,装药,然后才能打下一枪。每次的访问时间是400-600个clock(core 跑的时钟)延迟。所以在CUDA编程中,其中一个瓶颈就是内存访问。利用SDK提供的bandwidthTest可以测试到host到device,device到host,device到device的传输性能。虽然PCIE有3.2G/s的理论值,但实际达不到这么多。Device to Device的传输能达到89G/s(GTX260)左右,理论值是90G/s(GTX260)也达到差不多了。这个地方每个人显卡不一样,主板不一样,设置环境不同,也不一定一样。
Device上active的一个warp有32个线程,但是实际是16个thread同时在运行,就是half warp。当half warp的16个threads访问内存的时候,最好让16个thread依次对着相对应的内存地址,这样的时候才能保证Coalesced Access。如下图http://www.isi.edu/~ddavis/GPU/Course/Slides/GPU+CUDA.pdf:

如果还没明白,看解释,每一个thread一次访问对应的内存地址,不互相交错,这样就不会卡壳了~。如果有交错了,就会出现下面的情况 Uncoalesced Access,
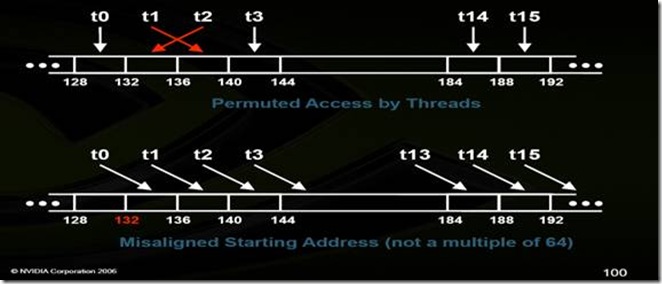
小时候玩过仿照左轮手枪的,自动的转动肯定会很快把子弹打完,没看到谁打完第1颗,再去打第3颗,再回来打第2颗子弹的~……这里也不多做解释了~
下面是一个例子,也是刚才那个连接上的:
把一个Uncoalesced float3 Code的代码优化为Coalesced的代码的过程:
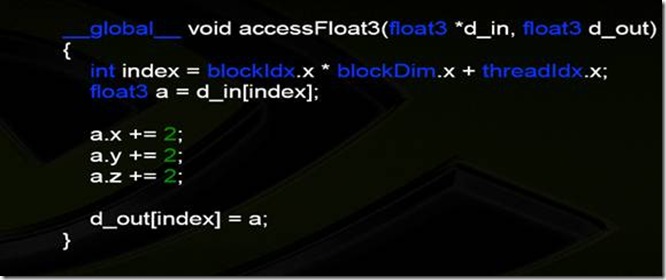
Float3是12bytes,每一个thread就会读取3个float。还记得我们前面说过的每次换一个弹夹是4,8,或者16,但是明显float3不等于这些。还记得active thread是怎么工作的吧?如果不记得了最好参看前面的thread工作的章节。Warp工作的时候是16个threads一起运作的,所以同时就有16个threads访问内存,加起来就是16*3*4(16个threds,float3是3个float,每个float有4个byte), 192个bytes。所以就造成了Uncoalesced Access。
下面怎么来解决这个问题,一个图:
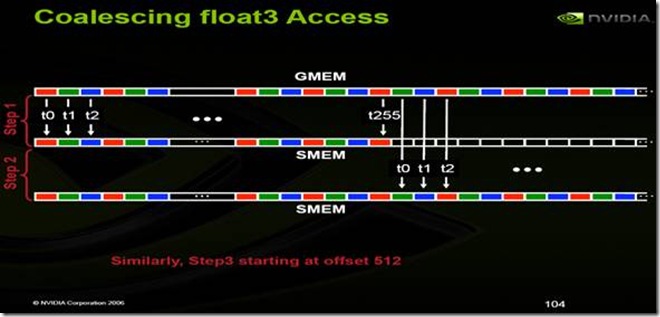
看看这个图,然后再看一段代码:
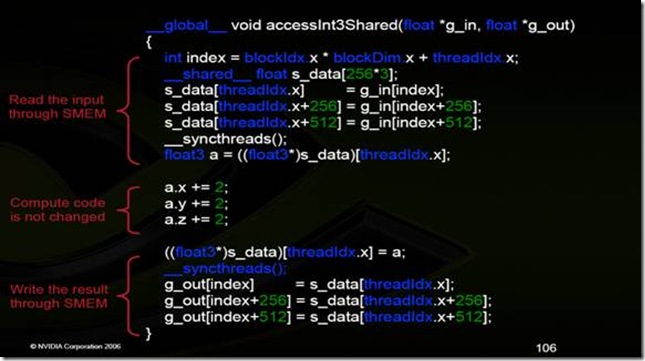
自己先算一下,这里是怎么一个访问过程。
下面解释:我们设置block的thread为256,然后当大家都执行第一条存储命令s_data[threadIdx.x] = g_in[index],还记得block内的thread的执行模型吗?SIMP,一条指令,同时256个threads都要执行完,才会执行下一个指令。
这里其实用到了shared memory来作为中转,避免了global内存访问的Uncoalesced。如果结构体不是size(4,8,16)还有内存强制对齐的方式来使得global访问的coalesced。例如用__align(x)来强制对齐内存,但是这里就会浪费一些空间,如果float3,的结构体,用__align(16),对齐,就会有一个float的空白空间用来做对齐了~。
总结一下,就讲了一个global内存访问对齐的东东,如果访问不能连续,就采用两种方法来使得其对齐~其实看完前面的,理解到最后就这一句管用~
下一章节应该会讲到shared memory里面访问的bank conflict的部分,其实也很简单,画一个图就出来解决了~~
Ps:多画图,不明白的时候就画图出来:)
7. CUDA内存访问(一)提高篇------按部就班 ------GPU的革命相关推荐
- java 编码实现内存拷贝_java提高篇(六)-----使用序列化实现对象的拷贝
我们知道在Java中存在这个接口Cloneable,实现该接口的类都会具备被拷贝的能力,同时拷贝是在内存中进行,在性能方面比我们直接通过new生成对象来的快,特别是在大对象的生成上,使得性能的提升非常 ...
- CUDA Pro:通过向量化内存访问提高性能
CUDA Pro:通过向量化内存访问提高性能 许多CUDA内核受带宽限制,而新硬件中触发器与带宽的比率不断提高,导致带宽受限制的内核更多.这使得采取措施减轻代码中的带宽瓶颈非常重要.本文将展示如何在C ...
- cuda合并访问的要求_【CUDA 基础】4.3 内存访问模式
Abstract: 本文介绍内存的访问过程,也就是从应用发起请求到硬件实现的完整操作过程,这里是优化内存瓶颈的关键之处,也是CUDA程序优化的基础.Keywords: 内存访问模式,对齐,合并,缓存, ...
- cuda合并访问的要求_在 CUDA C / C ++ 中使用共享内存
在 上一篇文章 中,我研究了如何将一组线程访问的全局内存合并到一个事务中,以及对齐和跨步如何影响 CUDA 各代硬件的合并.对于最新版本的 CUDA 硬件,未对齐的数据访问不是一个大问题.然而,不管 ...
- CUDA的global内存访问的问题
http://blog.csdn.net/OpenHero/article/details/3520578 关于CUDA的global内存访问的问题,怎么是访问的冲突,怎样才能更好的访问内存,达到更高 ...
- CUDA 内存统一分析
CUDA 内存统一分析 关于CUDA 编程的基本知识,如何编写一个简单的程序,在内存中分配两个可供 GPU 访问的数字数组,然后将它们加在 GPU 上. 本文介绍内存统一,这使得分配和访问系统中任何处 ...
- [网络安全提高篇] 一一五.Powershell恶意代码检测 (3)Token关键词自动提取
"网络安全提高班"新的100篇文章即将开启,包括Web渗透.内网渗透.靶场搭建.CVE复现.攻击溯源.实战及CTF总结,它将更加聚焦,更加深入,也是作者的慢慢成长史.换专业确实挺难 ...
- GNU C - 关于8086的内存访问机制以及内存对齐(memory alignment)
接着前面的文章,这篇文章就来说说menory alignment -- 内存对齐. 一.为什么需要内存对齐? 无论做什么事情,我都习惯性的问自己:为什么我要去做这件事情? 是啊,这可能也是个大家都会去 ...
- 0x00000000指令引用的内存不能为written_变量和内存访问
计算机世界有一个常识--所有的数据和指令必须经由内存才能进入CPU的寄存器进而被CPU使用,那么我们程序操作的主战场就是内存,内存操作也就顺理成章成为了程序中最高频的操作. 为了节目的效果,我们先来看 ...
最新文章
- Javascript基础知识篇(5): 面向对象之链式调用
- Python数据集可视化:抽取数据集的两个特征进行二维可视化、主成分分析PCA对数据集降维进行三维可视化(更好地理解维度之间的相互作用)
- 【童年回忆】【FC模拟器 + ROM大合集下载】
- java中volatile关键字的含义
- 非root用户加入docker用户组省去sudo
- 通过一段简单的代码,介绍 ABAP 的预定义类型 c
- .Net Core3.0依赖注入DI
- 8、oracle数据库下的索引
- Java创新型模式_java设计模式--创建型模式(一)
- JSONObject 自定义过滤配置
- ubuntu下的jdk环境变量配置(解决sun jdk和open jdk的问题)
- 想学习Java编程,看书还是看视频更合适?
- DiskFileUpload类
- 安装Rational Rose所踩得坑
- 地图学(何宗宜版)知识点整理
- POP3、SMTP和IMAP 协议
- R语言hist作直方图
- 【微服务】Nacos 注册中心的设计原理
- Conditional Generative Adversarial Nets(CGAN)
- 彻底关闭Win10自动更新(Win10企业版或专业版)