【深度学习项目五】:利用LSTM网络进行情感分析(NLP)
相关文章:
【深度学习项目一】全连接神经网络实现mnist数字识别](https://blog.csdn.net/sinat_39620217/article/details/116749255?spm=1001.2014.3001.5501)
【深度学习项目二】卷积神经网络LeNet实现minst数字识别
【深度学习项目三】ResNet50多分类任务【十二生肖分类】
『深度学习项目四』基于ResNet101人脸特征点检测
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/1994431?contributionType=1
1. NLP知识简介
情感分析,是文本分类任务的经典场景:
- 输入:一个自然语言句子。
- 输出:输出这个句子的情感分类,如高兴、伤心
通常看作一个三分类问题: - 正向:表示正面积极的情感,如高兴、喜欢。
- 负向:表示负面消极的情感,如难过、讨厌。
- 中性:其他类型的情感。
![]()
2. NLP原理介绍
数据处理通用流程 以句子分类为例
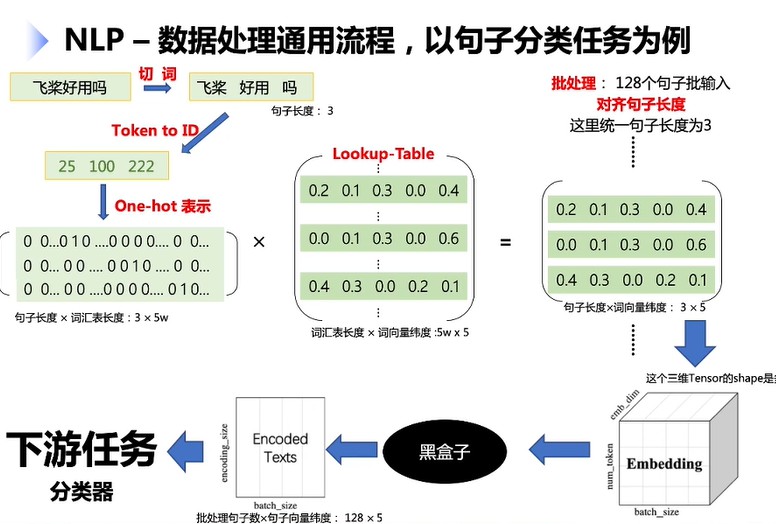
词汇表长度5w
词向量纬度: 500
批处理句子数Batch_ size : 128,
统-句子长度num. token: 3
词向量纬度Emb_ dimension : 500
句子向量纬度Emb. size: 200
首先进行切词,将词通过唯一的one-hot向量表示得到唯一ID,再乘以词向量表得到表示矩阵,进行批处理得到[128,3,5]的词向量.长度统一:短补长截
如何刻画句子的语义信息
![]()
2.1 序列处理法:
2.1.1 循环神经网络RNN
RNN是两种神经网络模型的缩写,一种是递归神经网络(Recursive Neural Network),一种是循环神经网络(Recurrent Neural Network)。虽然这两种神经网络有着千丝万缕的联系,但是本文主要讨论的是第二种神经网络模型——循环神经网络(Recurrent Neural Network)
RNN网络和其他网络最大的不同就在于RNN能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。如同人类能够凭借自己过往的记忆更好地认识这个世界一样。RNN也实现了类似于人脑的这一机制,对所处理过的信息留存有一定的记忆,而不像其他类型的神经网络并不能对处理过的信息留存记忆。
![]()
由上图可以看出:一个典型的RNN网络包含一个输入x,一个输出h和一个神经网络单元A。和普通的神经网络不同的是,RNN网络的神经网络单元A不仅仅与输入和输出存在联系,其与自身也存在一个回路。这种网络结构就揭示了RNN的实质:上一个时刻的网络状态信息将会作用于下一个时刻的网络状态。如果上图的网络结构仍不够清晰,RNN网络还能够以时间序列展开成如下形式:
![]()
等号右边是RNN的展开形式。由于RNN一般用来处理序列信息,因此下文说明时都以时间序列来举例,解释。等号右边的等价RNN网络中最初始的输入是x0,输出是h0,这代表着0时刻RNN网络的输入为x0,输出为h0,网络神经元在0时刻的状态保存在A中。当下一个时刻1到来时,此时网络神经元的状态不仅仅由1时刻的输入x1决定,也由0时刻的神经元状态决定。以后的情况都以此类推,直到时间序列的末尾t时刻。
上面的过程可以用一个简单的例子来论证:假设现在有一句话“I want to play basketball”,由于自然语言本身就是一个时间序列,较早的语言会与较后的语言存在某种联系,例如刚才的句子中“play”这个动词意味着后面一定会有一个名词,而这个名词具体是什么可能需要更遥远的语境来决定,因此一句话也可以作为RNN的输入。回到刚才的那句话,这句话中的5个单词是以时序出现的,我们现在将这五个单词编码后依次输入到RNN中。首先是单词“I”,它作为时序上第一个出现的单词被用作x0输入,拥有一个h0输出,并且改变了初始神经元A的状态。单词“want”作为时序上第二个出现的单词作为x1输入,这时RNN的输出和神经元状态将不仅仅由x1决定,也将由上一时刻的神经元状态或者说上一时刻的输入x0决定。之后的情况以此类推,直到上述句子输入到最后一个单词“basketball”。
RNN的神经元结构:
![]()
上图依然是一个RNN神经网络的时序展开模型,中间t时刻的网络模型揭示了RNN的结构。可以看到,原始的RNN网络的内部结构非常简单。神经元A在t时刻的状态仅仅是t-1时刻神经元状态与t时刻网络输入的双曲正切函数的值,这个值不仅仅作为该时刻网络的输出,也作为该时刻网络的状态被传入到下一个时刻的网络状态中,这个过程叫做RNN的正向传播(forward propagation)。
![]()
2.1.2 长短时记忆网络LSTM
![]()
![]()
2.1.3 全连接层、线性分类器
![]()
# 下载paddlenlp
!pip install --upgrade paddlenlp -i https://pypi.org/simple
import paddle
import paddlenlpprint(paddle.__version__, paddlenlp.__version__)2.2 PaddleNLP和Paddle框架是关系

- Paddle框架是基础底座,提供深度学习任务全流程API。PaddleNLP基于Paddle框架开发,适用于NLP任务。
PaddleNLP中数据处理、数据集、组网单元等API未来会沉淀到框架paddle.text中。
- 代码中继承
class TSVDataset(paddle.io.Dataset)
2.3 使用飞桨完成深度学习任务的通用流程
![]()
import numpy as np
from functools import partialimport paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as ppnlp
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.datasets import MapDatasetfrom utils import load_vocab, convert_example
3. 数据集和数据处理
3.1 自定义数据集
映射式(map-style)数据集需要继承paddle.io.Dataset
__getitem__: 根据给定索引获取数据集中指定样本,在 paddle.io.DataLoader 中需要使用此函数通过下标获取样本。__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列。
下面分为两种编写方法:
from paddlenlp.datasets import load_datasetdef read(data_path):with open(data_path, 'r', encoding='utf-8') as f:for line in f:l = line.strip('\n').split('\t')if len(l) != 2:print (len(l), line)words, labels = line.strip('\n').split('\t')# words = words.split('\002')# labels = labels.split('\002')yield {'tokens': words, 'labels': labels}# data_path为read()方法的参数
train_ds = load_dataset(read, data_path='train.txt',lazy=False)
dev_ds = load_dataset(read, data_path='dev.txt',lazy=True) #验证数据集
test_ds = load_dataset(read, data_path='test.txt',lazy=True)
# class SelfDefinedDataset(paddle.io.Dataset):
# def __init__(self, data):
# super(SelfDefinedDataset, self).__init__()
# self.data = data# def __getitem__(self, idx):
# return self.data[idx]# def __len__(self):
# return len(self.data)# def get_labels(self):
# return ["0", "1"]# def txt_to_list(file_name):
# res_list = []
# for line in open(file_name):
# res_list.append(line.strip().split('\t'))
# return res_list# trainlst = txt_to_list('train.txt')
# devlst = txt_to_list('dev.txt')
# testlst = txt_to_list('test.txt')# train_ds, dev_ds, test_ds = SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
for i in range(20):print (train_ds[i])
{'tokens': '赢在心理,输在出品!杨枝太酸,三文鱼熟了,酥皮焗杏汁杂果可以换个名(九唔搭八)', 'labels': '0'}
{'tokens': '服务一般,客人多,服务员少,但食品很不错', 'labels': '1'}
{'tokens': '東坡肉竟然有好多毛,問佢地點解,佢地仲話係咁架\ue107\ue107\ue107\ue107\ue107\ue107\ue107冇天理,第一次食東坡肉有毛,波羅包就幾好食', 'labels': '0'}
{'tokens': '父亲节去的,人很多,口味还可以上菜快!但是结账的时候,算错了没有打折,我也忘记拿清单了。说好打8折的,收银员没有打,人太多一时自己也没有想起。不知道收银员忘记,还是故意那钱露入自己钱包。。', 'labels': '0'}
{'tokens': '吃野味,吃个新鲜,你当然一定要来广州吃鹿肉啦*价格便宜,量好足,', 'labels': '1'}
{'tokens': '味道几好服务都五错推荐鹅肝乳鸽飞鱼', 'labels': '1'}
{'tokens': '作为老字号,水准保持算是不错,龟岗分店可能是位置问题,人不算多,基本不用等位,自从抢了券,去过好几次了,每次都可以打85以上的评分,算是可以了~粉丝煲每次必点,哈哈,鱼也不错,还会来帮衬的,楼下还可以免费停车!', 'labels': '1'}
{'tokens': '边到正宗啊?味味都咸死人啦,粤菜讲求鲜甜,五知点解感多人话好吃。', 'labels': '0'}
{'tokens': '环境卫生差,出品垃圾,冇下次,不知所为', 'labels': '0'}
{'tokens': '和苑真是精致粤菜第一家,服务菜品都一流', 'labels': '1'}
{'tokens': '服务不是一般的差,特别是部长那些', 'labels': '0'}
{'tokens': '今天又去了,虽然上次吃完愤愤地说下次再也不去了,可是,今天是客户选被迫就范,两个人最后买单4800元,菜价全广州最贵,部长点菜只建议点最贵,不建议点好吃的,服务态度倒是很好,好态度背后隐藏着一把锋利的刀,出来有种被当水鱼被斩的感觉,有种被侮辱智商的挫败。。。', 'labels': '0'}
{'tokens': '第二次来了,味道不错!!分量还可以', 'labels': '1'}
{'tokens': '上菜慢,价钱偏贵,细路太多不适合情侣!无下次!', 'labels': '0'}
{'tokens': '茶没喝,人已被气饱,谁还会再来!昨晚8:10分,我们一行2人上到二楼,带位领班安排我们就坐窗边位置,周围的几张台都坐满了客人,随后一位服务生对我们说该区域九点结束营业,我们明确表示9点前一定离开,他也同意了;过了5分钟另一位服务生又跟我们说9点要搞卫生(脸色很难看),我们再次强调会按时离开;又过了5分钟,再来了一位服务生语气很不客气的要我们去其他区域,我们一听就来气了,我们从进店开始已整整坐了十几分钟,不但茶没喝,还在受气,说实在话这个时间我要点的东西都已上齐,位置是你们安排的,这是你们内部的管理问题,该区域也没有任何9点停止营业的告示,大厅的营业时间是到22:30分的。喝茶本是愉悦的,但遇上这样的服务态度,这样的管理水平,实在无法忍受,气愤的离开了,以后也不会光顾了。本人从事旅游行业多年,也安排了很多国外入境客人品尝各种广东风味小吃,但像这样的服务态度和服务水平实在不敢恭维,那敢再带国外客人光顾呢?', 'labels': '0'}
{'tokens': '对这次服务满意坏境不错,服务周到。', 'labels': '0'}
{'tokens': '两点来的,说是两点半就不能点点心,催着点了。直接带到25元一位的大厅,坐下开始点菜才知道楼上有几块钱的。先后点的四种点心,都是点完半天来告诉我们没有,实在太扫兴,太扫兴,太扫兴。服务员也很冷淡,冷淡到不行。如果有无星,我一颗星都不给。', 'labels': '0'}
{'tokens': '服务态度超差,真系以后都唔会再去', 'labels': '0'}
{'tokens': '口味不错,消费不贵,可以和朋友们一起来', 'labels': '1'}
{'tokens': '出发前查过点评网营业到04:00,到店00:00左右,见门口写营业到02:00,见里面仲有几台客,就入去坐低,服务员过嚟话开到01:30,都算,坐低咗就快快翠食完走,点知一话要点起片打边炉,服务员就话肯定赶唔切…差在未赶我地走,无语…果断转场…口味五星纯粹就评俾印象中嘅口味', 'labels': '0'}
3.2 数据处理
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
- 首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。
![]()
- 使用
paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
| API | 简介 |
|---|---|
paddlenlp.data.Stack
|
堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。 |
paddlenlp.data.Pad
|
堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
paddlenlp.data.Tuple
|
将多个组batch的函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
# 下载词汇表文件word_dict.txt,用于构造词-id映射关系。
!wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt# 加载词表
vocab = load_vocab('./senta_word_dict.txt')for k, v in vocab.items():print(k, v)break
https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txt
Resolving paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)... 100.64.253.37, 100.64.253.38
Connecting to paddlenlp.bj.bcebos.com (paddlenlp.bj.bcebos.com)|100.64.253.37|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 14600150 (14M) [text/plain]
Saving to: ‘senta_word_dict.txt.1’senta_word_dict.txt 100%[===================>] 13.92M 73.9MB/s in 0.2s 2021-05-25 18:51:53 (73.9 MB/s) - ‘senta_word_dict.txt.1’ saved [14600150/14600150][PAD] 0
## 3.3构造dataloder下面的`create_data_loader`函数用于创建运行和预测时所需要的`DataLoader`对象。* `paddle.io.DataLoader`返回一个迭代器,该迭代器根据`batch_sampler`指定的顺序迭代返回dataset数据。异步加载数据。* `batch_sampler`:DataLoader通过 batch_sampler 产生的mini-batch索引列表来 dataset 中索引样本并组成mini-batch* `collate_fn`:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
# Reads data and generates mini-batches.
def create_dataloader(dataset,trans_function=None, #数据集转换例如:词转换成idmode='train',batch_size=1,pad_token_id=0, #padding的特殊符号的idbatchify_fn=None): #读batch的函数if trans_function:dataset_map = dataset.map(trans_function)# return_list 数据是否以list形式返回# collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。dataloader = paddle.io.DataLoader(dataset_map,return_list=True,batch_size=batch_size,collate_fn=batchify_fn)return dataloader# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
#转换成id序列
trans_function = partial(convert_example,vocab=vocab,unk_token_id=vocab.get('[UNK]', 1),is_test=False)# 将读入的数据batch化处理,便于模型batch化运算。
# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
#pad pai将句子统一到一定长度
batchify_fn = lambda samples, fn=Tuple(Pad(axis=0, pad_val=vocab['[PAD]']), # input_idsStack(dtype="int64"), # seq lenStack(dtype="int64") # label
): [data for data in fn(samples)]#调用三次dataloader
train_loader = create_dataloader(train_ds,trans_function=trans_function,batch_size=128,mode='train',batchify_fn=batchify_fn)
dev_loader = create_dataloader(dev_ds,trans_function=trans_function,batch_size=128,mode='validation',batchify_fn=batchify_fn)
test_loader = create_dataloader(test_ds,trans_function=trans_function,batch_size=128,mode='test',batchify_fn=batchify_fn)for i in train_loader:print(i)break
[Tensor(shape=[128, 434], dtype=int64, place=CPUPlace, stop_gradient=True,[[656582 , 666970 , 646434 , ..., 0 , 0 , 0 ],[724601 , 1250380, 1106339, ..., 0 , 0 , 0 ],[1 , 1232128, 389886 , ..., 0 , 0 , 0 ],...,[653811 , 1225884, 952595 , ..., 0 , 0 , 0 ],[137984 , 261577 , 850865 , ..., 0 , 0 , 0 ],[115700 , 364716 , 509081 , ..., 0 , 0 , 0 ]]), Tensor(shape=[128], dtype=int64, place=CPUPlace, stop_gradient=True,[27 , 13 , 40 , 60 , 22 , 11 , 67 , 20 , 12 , 11 , 10 , 85 , 11 , 15 , 261, 8 , 81 , 10 , 13 , 96 , 32 , 169, 20 , 16 , 25 , 29 , 26 , 107, 12 , 65 , 20 , 20 , 22 , 74 , 124, 207, 16 , 13 , 31 , 205, 28 , 12 , 46 , 68 , 434, 10 , 12 , 61 , 17 , 14 , 19 , 34 , 141, 44 , 135, 293, 39 , 10 , 22 , 41 , 14 , 16 , 185, 24 , 8 , 42 , 36 , 19 , 13 , 9 , 29 , 12 , 61 , 151, 11 , 11 , 20 , 16 , 24 , 104, 12 , 9 , 11 , 72 , 48 , 16 , 317, 57 , 91 , 11 , 278, 37 , 97 , 11 , 12 , 12 , 25 , 58 , 27 , 12 , 205, 23 , 22 , 17 , 10 , 107, 40 , 34 , 9 , 59 , 9 , 26 , 25 , 93 , 14 , 13 , 14 , 20 , 21 , 25 , 13 , 32 , 11 , 24 , 16 , 117, 43 , 11 ]), Tensor(shape=[128], dtype=int64, place=CPUPlace, stop_gradient=True,[0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1])]4.模型搭建
使用LSTMencoder搭建一个BiLSTM模型用于进行句子建模,得到句子的向量表示。
然后接一个线性变换层,完成二分类任务。
paddle.nn.Embedding组建word-embedding层ppnlp.seq2vec.LSTMEncoder组建句子建模层paddle.nn.Linear构造二分类器
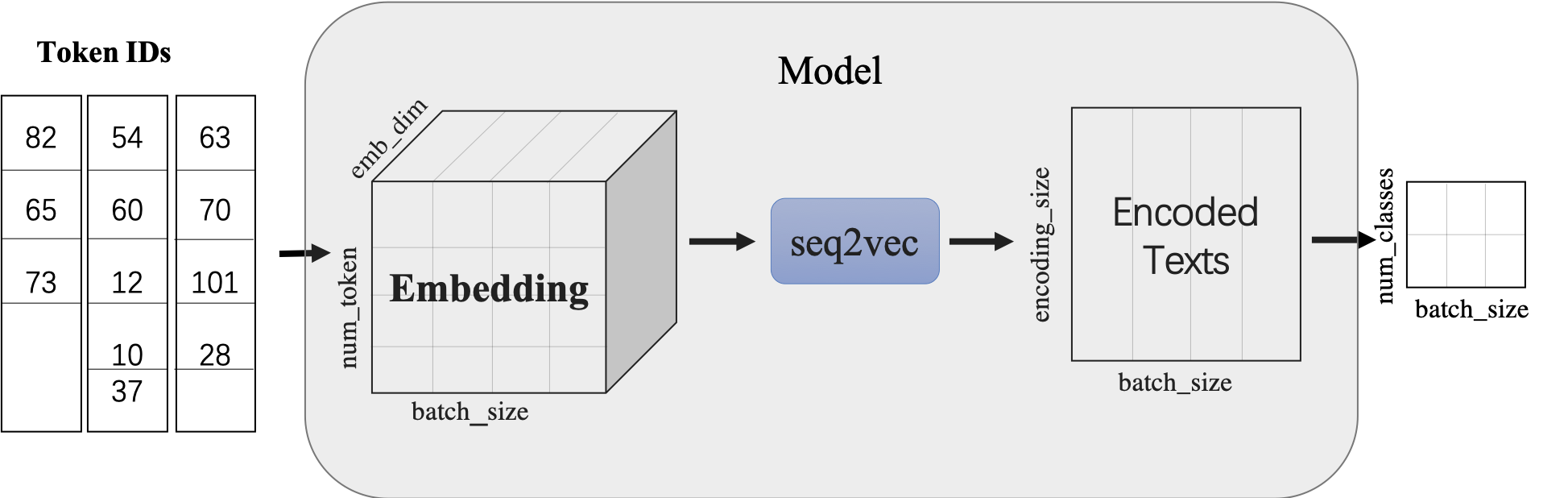
- 除LSTM外,
seq2vec还提供了许多语义表征方法,详细可参考:seq2vec介绍
class LSTMModel(nn.Layer):def __init__(self,vocab_size, #词汇长度num_classes,emb_dim=128, #词向量纬度padding_idx=0, #补齐句子特殊符号lstm_hidden_size=198, #隐藏层direction='forward', #从前往后读句子lstm_layers=1,dropout_rate=0, #随机丢弃一下网络,增强网络泛化能力pooling_type=None,fc_hidden_size=96):super().__init__()# 首先将输入word id 查表后映射成 word embeddingself.embedder = nn.Embedding(num_embeddings=vocab_size,embedding_dim=emb_dim,padding_idx=padding_idx)# 将word embedding经过LSTMEncoder变换到文本语义表征空间中self.lstm_encoder = ppnlp.seq2vec.LSTMEncoder(emb_dim,lstm_hidden_size,num_layers=lstm_layers,direction=direction,dropout=dropout_rate,pooling_type=pooling_type)# LSTMEncoder.get_output_dim()方法可以获取经过encoder之后的文本表示hidden_sizeself.fc = nn.Linear(self.lstm_encoder.get_output_dim(), fc_hidden_size)# 最后的分类器self.output_layer = nn.Linear(fc_hidden_size, num_classes)def forward(self, text, seq_len):# text shape: (batch_size, num_tokens)# print('input :', text.shape)# Shape: (batch_size, num_tokens, embedding_dim)embedded_text = self.embedder(text) # print('after word-embeding:', embedded_text.shape)# Shape: (batch_size, num_tokens, num_directions*lstm_hidden_size)# num_directions = 2 if direction is 'bidirectional' else 1text_repr = self.lstm_encoder(embedded_text, sequence_length=seq_len)# print('after lstm:', text_repr.shape)# Shape: (batch_size, fc_hidden_size)fc_out = paddle.tanh(self.fc(text_repr))# print('after Linear classifier:', fc_out.shape)# Shape: (batch_size, num_classes)logits = self.output_layer(fc_out)# print('output:', logits.shape)# probs 分类概率值probs = F.softmax(logits, axis=-1)# print('output probability:', probs.shape)return probsmodel= LSTMModel(len(vocab),2,direction='bidirectional',padding_idx=vocab['[PAD]'])
model = paddle.Model(model)
5.模型配置和训练
5.1模型配置
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=5e-5)loss = paddle.nn.CrossEntropyLoss()
metric = paddle.metric.Accuracy()model.prepare(optimizer, loss, metric)
# 设置visualdl路径
log_dir = './visualdl'
callback = paddle.callbacks.VisualDL(log_dir=log_dir)
5.2模型训练
训练过程中会输出loss、acc等信息。这里设置了10个epoch,在训练集上准确率约97%。
![]()
model.fit(train_loader, dev_loader, epochs=10, save_dir='./checkpoints', save_freq=5, callbacks=callback)
5.3 启动VisualDL查看训练过程可视化结果
启动步骤:
- 1、切换到本界面左侧「可视化」
- 2、日志文件路径选择 ‘visualdl’
- 3、点击「启动VisualDL」后点击「打开VisualDL」,即可查看可视化结果:
Accuracy和Loss的实时变化趋势如下:

results = model.evaluate(dev_loader)
print("Finally test acc: %.5f" % results['acc'])
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 10 - loss: 0.3913 - acc: 0.9414 - 90ms/step
step 20 - loss: 0.3812 - acc: 0.9445 - 74ms/step
step 30 - loss: 0.3584 - acc: 0.9464 - 72ms/step
step 40 - loss: 0.3487 - acc: 0.9480 - 71ms/step
step 50 - loss: 0.3882 - acc: 0.9473 - 70ms/step
step 60 - loss: 0.3747 - acc: 0.9478 - 70ms/step
step 70 - loss: 0.3802 - acc: 0.9467 - 69ms/step
step 80 - loss: 0.3563 - acc: 0.9471 - 67ms/step
Finally test acc: 0.94776
6.预测结果
print(type(test_ds))
label_map = {0: 'negative', 1: 'positive'}
results = model.predict(test_loader, batch_size=128)[0]
predictions = []for batch_probs in results:# 映射分类labelidx = np.argmax(batch_probs, axis=-1)idx = idx.tolist()labels = [label_map[i] for i in idx]predictions.extend(labels)
# 看看预测数据前5个样例分类结果
for i in test_ds:print(i)breakfor idx, data in enumerate(test_ds):if idx < 10:print(type(data))print('Data: {} \t Label: {}'.format(data[0], predictions[idx]))([440695, 768730, 810400, 371677, 1106339, 995733, 237834, 891203, 1211275, 686770, 1106339, 440695, 117037, 830171, 475327, 1093154], array(16), array(0))
<class 'tuple'>
Data: [440695, 768730, 810400, 371677, 1106339, 995733, 237834, 891203, 1211275, 686770, 1106339, 440695, 117037, 830171, 475327, 1093154] Label: negative
<class 'tuple'>
Data: [471791, 807117, 823116, 1, 891564, 1057229, 1, 1106326, 653811, 176187, 877695, 958129, 173188, 986608, 1106339, 781255, 830165, 213378, 1211275, 1057229, 36026, 1106326, 1106328, 1033199, 877695, 749968, 1106339, 147848, 830171, 489131, 958129, 1106339, 898857, 1131492, 930707, 173188, 399212, 1, 1222901, 508478, 823066, 1106326, 1106328, 651025, 781255, 252859, 860530, 681075, 1106339, 453143, 1, 650296, 173188, 681075, 173401, 830171, 997375, 819627, 283810, 1106326, 1106328] Label: negative
<class 'tuple'>
Data: [451938, 696658, 940533, 1150076, 936106, 308649, 157793, 718272, 660347, 40882, 86562, 510099, 1106339, 1050713, 1188905, 711114, 69882, 686776, 961609, 1, 1106339, 178687, 1106328, 1057229, 511894, 1103825, 1106328, 606478, 703976, 823066, 1113416, 1152575, 1211275, 364716, 1092505, 877695, 1106339, 979319, 1106326, 1175853, 4783, 267842, 173188, 297759, 1106339, 786065, 1106339, 795996, 270281, 797371, 179568, 974589, 974589, 1, 1093512, 578978, 420194, 668761, 4783, 738354, 836929, 52172, 1106328, 713424, 830171, 35393, 898857, 472344, 1106339, 157793, 47104, 1191873, 718272, 389733, 738354, 952595, 1106339, 306239, 898857, 616980, 1106326, 1106328, 1106326, 1106328, 789340, 696658, 711103, 859353, 202379, 472344, 179582, 1106326, 26156, 1093873, 830171, 8885, 395173, 1106339, 592501, 202370, 1107855, 823066, 974589, 974589, 940533, 254014, 145550, 453139, 1193342, 940533, 1050739, 1106339, 1135123, 1, 602020, 179568] Label: negative
<class 'tuple'>
Data: [1086178, 173188, 1188905, 650296, 389733, 1188905, 823116, 669226, 1106339, 669226, 604466, 836929, 52172, 1106339, 311074, 881196, 1044637, 690740, 1, 1106339, 766694, 1050713, 823066, 511894, 1, 1, 173188, 690740, 224268, 257857, 240658, 1106339, 874019, 1238094, 1057229, 220620, 173188, 1106339, 1238700, 758560, 1208182, 823066, 1106339, 975313, 1232128, 836929, 567563, 936106, 237795, 282921, 282921, 282921, 282921, 282921, 282921] Label: negative
<class 'tuple'>
Data: [365921, 932416, 663024, 388662, 1106328, 1106328, 1106328, 1083318, 823066, 1216915, 819627, 453139, 1216915, 960087, 159950, 173188, 753452, 1106328] Label: positive
<class 'tuple'>
Data: [384261, 305803, 173188, 1183540, 823116, 1106339, 847645, 389733, 563178, 1053035, 666970, 81913, 475331, 1203115, 991057, 1106339, 479740, 88185, 859353, 1111556, 347427, 283810, 169379, 769807, 305838, 322845, 218407, 955960, 1106339, 693836, 686770, 4782, 724601, 686770, 4782, 107509, 553338, 1, 1042186, 1110722, 544943, 4782, 881173, 1183540, 823116, 173188, 1173300, 4782, 881173, 1183540, 769807, 173188, 1173300, 4783] Label: negative
<class 'tuple'>
Data: [376180, 639231, 261577, 656622, 894574, 1106328, 977151, 905376, 137984, 1057229, 250355, 173188, 629586, 876228, 1106339, 418471, 283810, 1211275, 799171, 1106339, 724601, 261577, 165869, 935402, 1106339, 860985, 261577, 1093154, 1106339, 820003, 543370, 894574, 1106328, 7215, 690740] Label: positive
<class 'tuple'>
Data: [1066901, 1083318, 877695, 979812, 1173329, 173188, 514629, 1106321, 1083318, 859353, 1083318, 1096990, 1083318, 263393, 818554, 1110721, 475371, 1192261, 173188, 326984, 837335, 659913, 832658, 832658, 491743, 1106328, 1173329, 1106328, 1106328, 1106328, 1066901, 1083318, 877695, 979812, 1, 173188, 514629, 68233, 1106321, 473329, 1, 1, 1106339, 957006, 823153, 930660, 794154, 183395, 382678, 1, 105959, 173188, 726352, 1106339, 166181, 473329, 928384, 453139, 4777, 1053978, 4778, 1, 1106339, 1093157, 645827, 224268, 534222, 1, 1022416, 1, 1084561, 1, 1106339, 1, 668587, 457118, 1, 1204878, 651025, 1, 656594, 696404, 66941, 742636, 416380, 832658, 832658, 1, 1106328, 1, 1106328, 1106328, 876258, 1106328, 1106328, 1106328, 386946, 1, 353572, 400234, 173188, 709767, 1106321, 1066901, 1083318, 877695, 396639, 173188, 514629, 1106321, 453971, 1121397, 522245, 1211275, 1, 823066, 1106339, 684489, 802932, 1, 1106339, 767021, 69882, 823066, 768905, 1, 1152574, 1106322, 1, 686770, 1106328, 1106328, 1066901, 1083318, 877695, 396639, 173188, 514629, 1106321, 917345, 1, 4782, 917345, 726358, 1140069, 976571, 312864, 4782, 917345, 726358, 1, 4782, 917345, 726358, 1095073, 1, 173188, 560962, 1034586, 4782, 917345, 726358, 1, 173188, 1, 1087481, 853920, 938841, 961609, 743669, 107691, 1106322, 1, 244170, 1106328, 1106328, 1155475, 599615, 890242, 954040, 1, 242649, 173188, 298309, 1057229, 803636, 4782, 1, 173188, 298309, 1106339, 177893, 4782, 1, 173188, 1211275, 1084488, 602020, 1093154, 881196, 1, 1106328, 1106328, 242649, 173188, 298309, 1057229, 453148, 881196, 803636, 173188, 1071540, 1106328, 1106328, 1106328] Label: negative
<class 'tuple'>
Data: [401981, 738738, 884754, 881187, 261577, 237795, 1106339, 497327, 690740, 297759, 261577, 1250380, 1106328, 810400, 429786, 686770, 1106328, 323771, 518954, 173188, 230599, 4782] Label: negative
<class 'tuple'>
Data: [169379, 52794, 173188, 504130, 440821, 977875, 552526, 282092, 823066, 1106339, 867512, 163653, 768547, 436269, 25065, 4783, 178053, 1057229, 261577, 1250380, 1106339, 1121661, 663813, 898857, 254013, 40261, 173188, 650322, 179568, 4783, 860985, 237834, 693836, 806474, 1057229, 759049, 560962, 231110, 283810, 833337, 389733, 830171, 939335, 1106339, 312183, 284408, 453172, 1006966, 231110, 173188, 284408, 1106339, 830172, 389733, 261577, 1225280, 823066, 4783, 4783, 724601, 224268, 1057229, 23432, 318302, 4783] Label: negative这里只采用了一个基础的模型,就得到了较高的的准确率。
可以试试预训练模型,能得到更好的效果!参考如何通过预训练模型Fine-tune下游任务
【深度学习项目五】:利用LSTM网络进行情感分析(NLP)相关推荐
- [深度学习]理解RNN, GRU, LSTM 网络
Recurrent Neural Networks(RNN) 人类并不是每时每刻都从一片空白的大脑开始他们的思考.在你阅读这篇文章时候,你都是基于自己已经拥有的对先前所见词的理解来推断当前词的真实含义 ...
- Python吴恩达深度学习作业20 -- 用LSTM网络创作一首爵士小歌
用LSTM网络创作一首爵士小歌 在本次作业中,你将使用LSTM实现乐曲生成模型.你可以在作业结束时试听自己创作的音乐. 你将学习: 将LSTM应用于音乐生成. 通过深度学习生成自己的爵士乐曲. fro ...
- 使用深度学习模型在 Java 中执行文本情感分析
积极的? 消极的? 中性的? 使用斯坦福 CoreNLP 组件以及几行代码便可对句子进行分析. 本文介绍如何使用集成到斯坦福 CoreNLP(一个用于自然语言处理的开源库)中的情感工具在 Java 中 ...
- 基于深度学习的汽车行业评论文本的情感分析
使用卷积神经网络对汽车行业评论文本进行情感分析. dateset 爬取汽车之家车主口碑评论文本,抽取口碑中最满意以及最不满意评论文本,分别作为正向情感语料库和负向情感语料库. 爬虫技术视频链接:htt ...
- [深度学习] Pytorch中RNN/LSTM 模型小结
目录 一 Liner 二 RNN 三 LSTM 四 LSTM 代码例子 概念介绍可以参考:[深度学习]理解RNN, GRU, LSTM 网络 Pytorch中所有模型分为构造参数和输入和输出构造参数两 ...
- 浅谈深度学习:基于对LSTM项目`LSTM Neural Network for Time Series Prediction`的理解与回顾
浅谈深度学习:基于对LSTM项目LSTM Neural Network for Time Series Prediction的理解与回顾#### 总包含文章: 一个完整的机器学习模型的流程 浅谈深度学 ...
- 【深度学习】——利用pytorch搭建一个完整的深度学习项目(构建模型、加载数据集、参数配置、训练、模型保存、预测)
目录 一.深度学习项目的基本构成 二.实战(猫狗分类) 1.数据集下载 2.dataset.py文件 3.model.py 4.config.py 5.predict.py 一.深度学习项目的基本构成 ...
- 手把手教你从零到一搭建深度学习项目(附PDF下载)
来源:机器之心 作者:Jonathan Hui 本文约14000字,建议阅读10+分钟. 本文将会从第一步开始,告诉你如何解决深度学习项目开发中会遇到的各类问题. 在学习了有关深度学习的理论之后,很多 ...
- 手把手教你从零搭建深度学习项目(附链接)
简介: 在学习了有关深度学习的理论之后,很多人都会有兴趣尝试构建一个属于自己的项目.本文将会从第一步开始,告诉你如何解决项目开发中会遇到的各类问题. 本文由六大部分组成,涵盖深度学习 ( DL ) 项 ...
最新文章
- HtmlUnit、httpclient、jsoup爬取网页信息并解析
- 用ASP.NET上传图片并生成带版权信息的缩略图
- 有你认识的么?新鲜出炉!云+社区2020年度优秀讲师TOP作者榜单!
- 混合APP开发框架资料汇总
- Linux流量监控工具 (实时)-适用于centos 当然也兼容RHEL
- 前端学习(2826):数据绑定
- 更改Docker默认的images存储位置
- ESP8266调试-P2P(AP模块与STA模块通信)
- java List和数组转换
- 朋友易得 ,知已难求
- Instagram新推两款AI过滤工具,没错!背后功臣就是Deep Text
- 7-ELEVEn 便利店 EDI 概览
- 微信公众号开发——java后台开发(一)
- 我java启蒙老师 郝斌老师
- 飞鸽传书2011下载(飞鸽传书)
- 导航和路径规划-论文心得
- C语言自然数各自出现的次数,2010年计算机等考二级C语言上机考试练习(1)
- 小型的代码管理仓库Gitea安装指南
- 使用python动手爬取智联招聘信息并简单分析
- H5 canvas 画圆 画圆角