基于TableStore的亿级订单管理解决方案
一、方案背景
订单系统存在于各行各业,如电商订单、银行流水、运营商话费账单等,是一个非常广泛、通用的系统。对于这类系统,在过去十几年发展中已经形成了经典的做法。但是随着互联网的发展,以及各企业对数据的重视,需要存储和持久化的订单量越来越大。数据的重视程度与数据规模的膨胀带来了新的挑战。
需求场景
某电商平台A,需要进行持久化所有平台产生的订单数据。同时,基于所有的订单数据,系统又需要向外提供面向多种角色:消费者、店家、平台三类人群的多元化的查询服务。消费者可以查询自己的历史订单,商家可以统计热销产品,平台也可以分析用户行为、平台交易规模等。主要查询方式涵盖订单的多维度检索,以及订单数据的分析、统计等,例如:
面向消费者:【A消费者】*【近1年】*【卖出电脑】订单查询;
面向售货员:【B售货员】*【近1个月】销售订单;
......
技术点
在订单场景中,技术上通常需要考虑的技术点,主要包含如下几个方面:
- 查询能力:需要具备丰富的查询类型,如多维度、范围、模糊查询等,同时具备排序、统计等功能;
- 数据量:存储海量数据的同时,满足强一致、高可用、低成本等要求;
- 服务性能:应对高并发请求高并发的同时,保证低延迟;
实现多维、实时查询功能,是订单管理解决方案的核心功能。
二、方案演进
应对订单场景,电商通常会采用MySQL传统方案。借助关系型数据库强大的查询能力,用户可直接通过SQL语句实现订单数据的多维度查询、数据统计等。所谓数据膨胀,分为横向、纵向两种,横向即不断迭代引入的新字段维度,纵向即总的存储数据量。在面对这两种订单数据膨胀上,单MySql方案逐渐变得吃力。 SQL + NoSQL的组合方案(以下称:组合方案)便应运而生,借助两个数据库各自的优势分别解决不同场景各自的需求。但组合方案同样也带来了新的问题,组合方案牺牲空间成本,同时也增加了开发工作量与运维复杂度。在保证数据一致性上产生额外开销。
下面让我们看一下如下几个常规方案:
常规方案
1、MySql分库分表方案
MySql自身拥有强大的数据查询、分析功能,基于MyQql创建订单系统,可以应对订单数据多维查询、统计场景。伴随着订单数据量的增加,用户会采取分库、分表方案应对,通过这种伪分布式方案,解决数据膨胀带来的问题。但数据一旦达到瓶颈,便需要重新创建更大规模的分库+数据的全量迁移,麻烦就会不断出现。数据迭代、膨胀带来的困扰,是MySql方案难于逾越的。仅仅依靠MySql的传统订单方案短板凸显。
1、数据纵向(数据规模)膨胀:采用分库分表方案,MySql在部署时需要预估分库规模,数据量一旦达到上限后,重新部署并做数据全量迁移;
2、数据横向(字段维度)膨胀:schema需预定义,迭代新增新字段变更复杂。而维度到达一定量后影响数据库性能;
2、MySql+HBase方案
引入双数据的方案应运而生,通过实时数据、历史数据分存的方案,可以一定程度解决数据量膨胀问题。该方案将数据归类成两部分存储:实时数据、历史数据。同时通过数据同步服务,将过期数据同步至历史数据。
1、实时订单数据(例如:近3个月的订单):将实时订单存入MySql数据库。实时订单的总量膨胀的速度得到了限制,同时保证了实时数据的多维查询、分析能力;
2、历史订单数据(例如:3个月以前的订单):将历史订单数据存入HBase,借助于HBase这一分布式NoSql数据库,有效应对了订单数据膨胀困扰。也保证了历史订单数据的持久化;
但是,该方案牺牲了历史订单数据对用户、商家、平台的使用价值,假设了历史数据的需求频率极低。但是一旦有需求,便需要全表扫描,查询速度慢、IO成本很高。而维护数据同步又带来了数据一致性、同步运维成本飙升等难题;
3、MySql+Elasticsearch方案
组合方案还有MySql+Elasticsearch,该方案同样是将数据分两部分存储,可以一定程度解决订单索引维度增长问题。用户自己维护数据同步服务,保证两部分数据的一致性;
1、全量数据:将全量的订单数据存入MySql数据库,订单ID之外的数据整体存为一个字段。该全量数据作为持久化存储,也用于非索引字段的反查;
2、查询数据:仅将需要检索的字段存入Elasticsearch(基于Lucene分布式索引数据库),借助于Elasticsearch的索引能力,提供可以应付维度膨胀的订单数据,然后必要时反查MySql获取订单完整信息;
该方案应付了数据维度膨胀带来的困扰,但是随着订单量的不断膨胀,MySql扩展性差的问题再次暴露出来。同时数据同步至Elasticsearch的方案,开发、运维成本很高,方案选择也存在弊端。
| 能力分析 | MySql | HBase | Elasticsearch | TableStore |
|---|---|---|---|---|
| 存储方式 | 行存储 | 列存储 | 索引存储 | 列存储+索引存储 |
| 扩展性 | 单机、扩展性差 | 水平扩展 | 水平扩展 | (自动)水平扩展 |
| 一致性 | 强一致性 | 强一致性、时序一致性 | 强一致性、时序一致性 | |
| 检索 | 较弱的支持 | 不支持 | 支持 | 支持 |
| 数据量 | ~ 1T,~亿行 | ~10 PB,~万亿行 | ~1 PB,~千亿行 | ~10 PB,~万亿行 |
表格存储(TableStore)方案
如果使用表格存储(TableStore)研发的多元索引(SearchIndex)方案,则可以完美地解决亿量级订单系统问题。TableStore具有即开即用,按量收费等特点。多元索引随时创建,是海量电商订单元数据管理的优质方案。
TableStore作为阿里云提供的一款全托管、分布式NoSql型数据存储服务,具有【海量数据存储】、【热点数据自动分片】、【海量数据多维检索】等功能,天然地解决了订单数据大爆炸这一挑战;
同时,SearchIndex功能在保证用户数据高可用的基础上,提供了数据多维度搜索、统计等能力。针对多种场景创建多种索引,实现多种模式的检索。用户可以仅在需要的时候创建、开通索引。由TableStore来保证数据同步的一致性,这极大的降低了用户的方案设计、服务运维、代码开发等工作量。
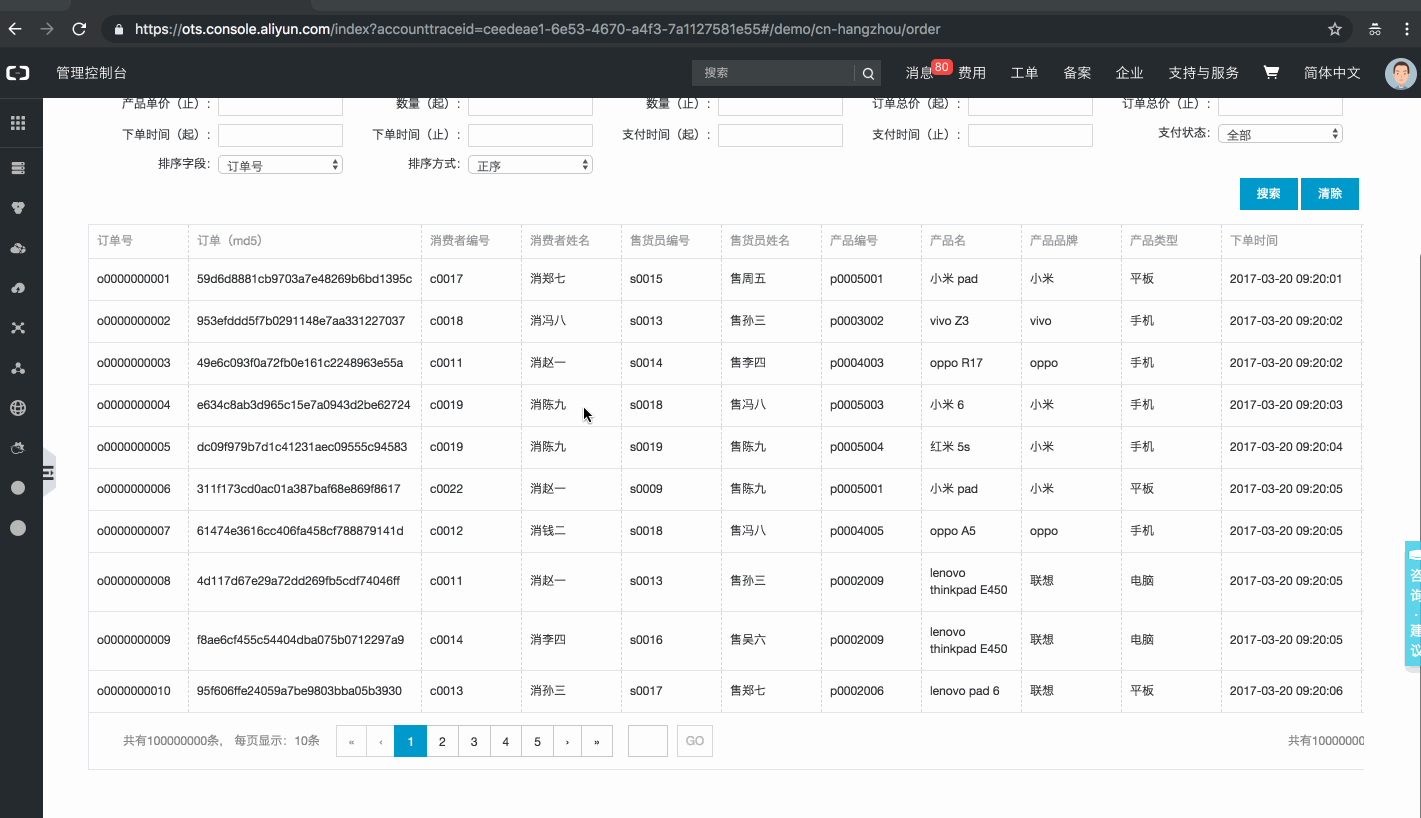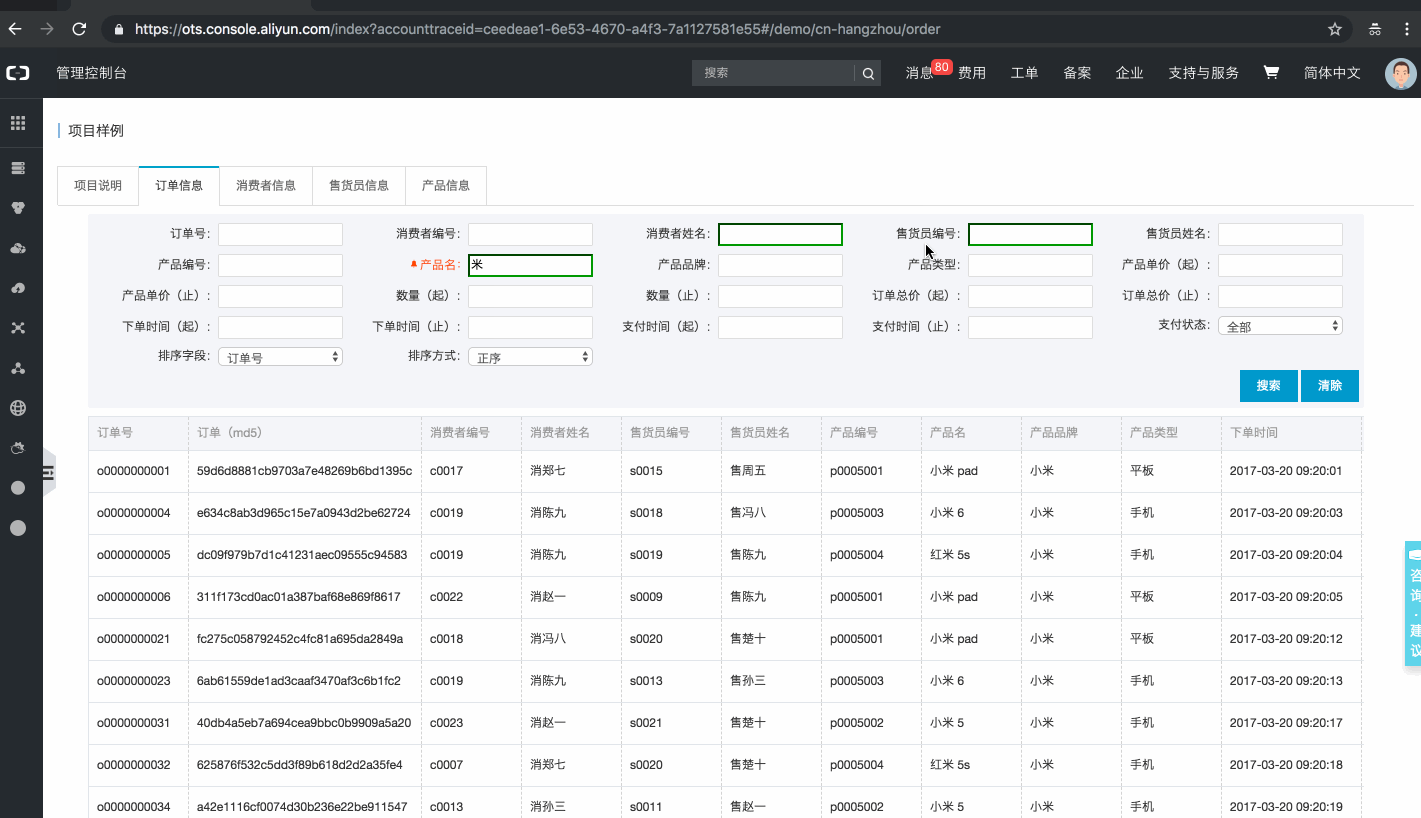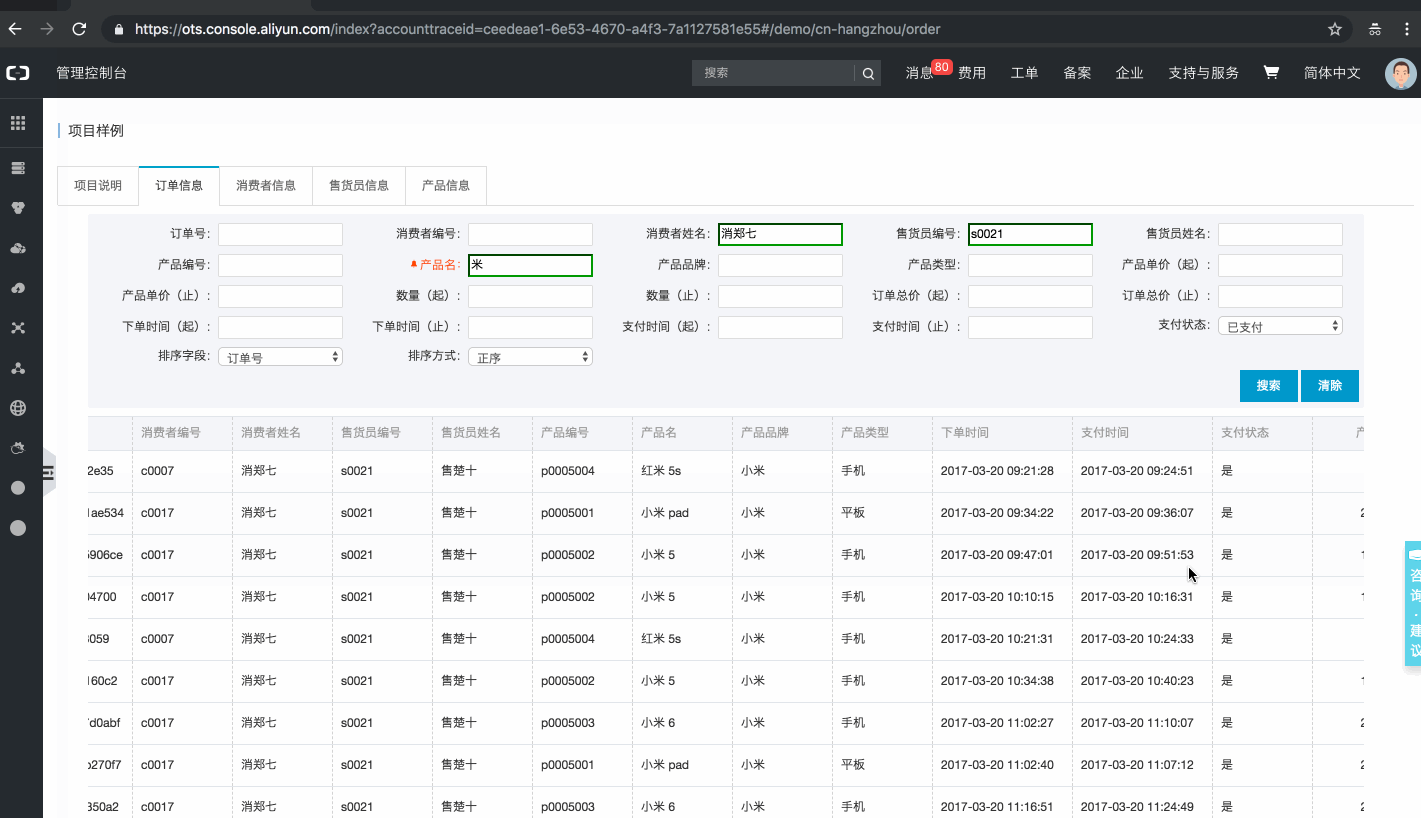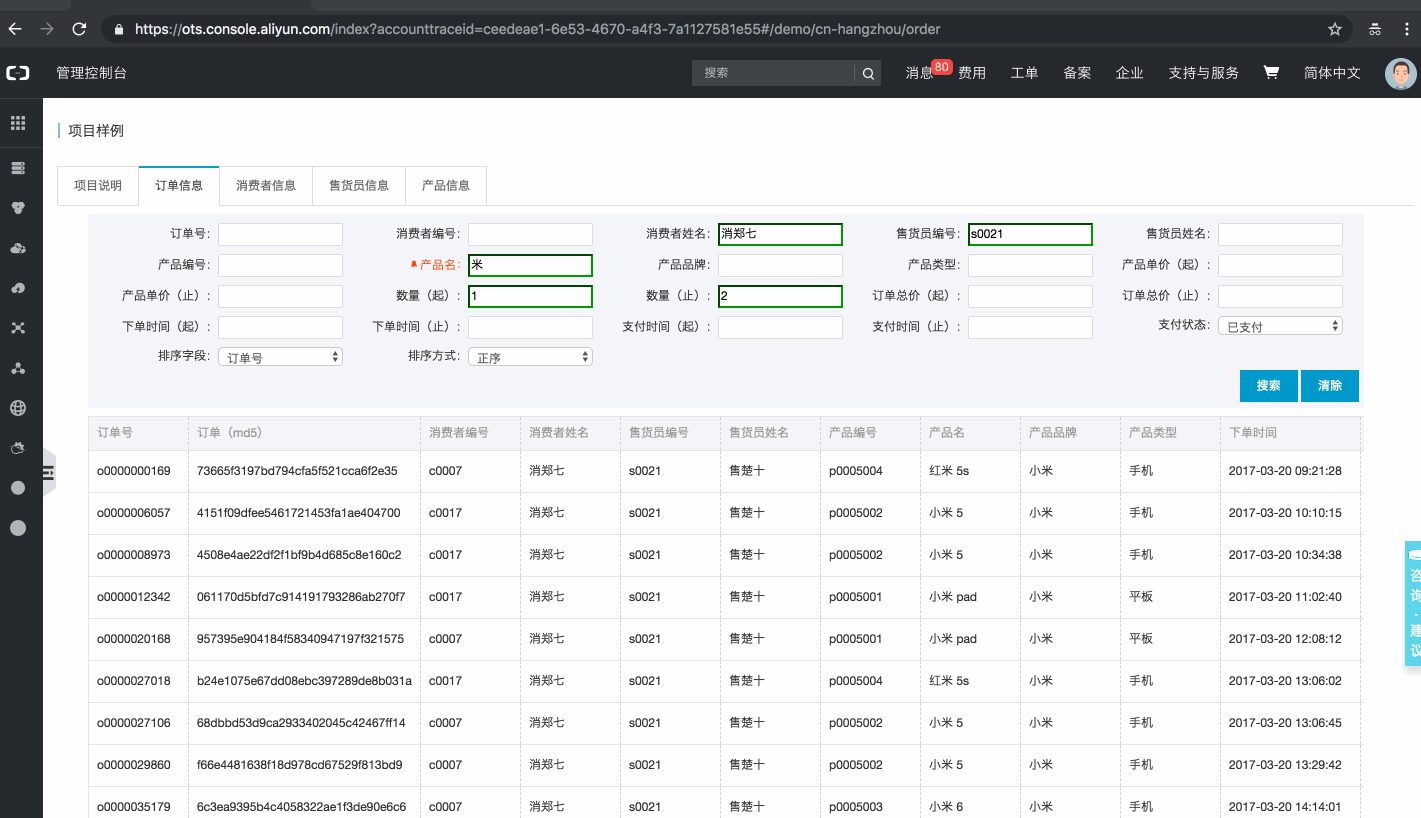
基于表格存储搭建的订单系统页面一览
样例内嵌在表格存储控制台中,用户可登录控制台体验系统(若为表格存储的新用户,需要点击开通服务后体验,开通免费,订单数据存储在公共实例中,体验不消耗用户存储、流量、Cu)。
注:该样例提供了【亿量级】订单数据。
![]()
二、搭建准备
若您对于亿量级订单系统的体验不错,希望开始自己系统的搭建之旅,只需按照如下步骤便可以着手搭建了:
1、开通表格存储
通过控制台开通表格存储服务,表格存储即开即用(后付费),采用按量付费方式,已为用户提供足够功能测试的免费额度。表格存储官网控制台、免费额度说明。
2、创建实例
通过控制台创建表格存储实例,选择支持多元索引的Region。(当前阶段SearchIndex功能尚未商业化,暂时开放北京、上海、深圳、杭州四地,后续逐渐开放)
![]()
创建实例后,提交工单申请多元索引功能邀测(商业化后默认打开,不使用不收费)。
- 邀测地址:提工单,选择【表格存储】>【产品功能、特性咨询】>【创建工单】,申请内容如下:
- 问题描述:请填写【申请SearchIndex邀测】
- 机密信息:请填写【地域+实例名】,例:上海+myInstanceName
![]()
3、SDK下载
使用具有多元索引(SearchIndex)的SDK,官网地址,暂时java、go、node.js三种SDK增加了新功能
java-SDK
<dependency><groupId>com.aliyun.openservices</groupId><artifactId>tablestore</artifactId><version>4.7.4</version>
</dependency>go-SDK
$ go get github.com/aliyun/aliyun-tablestore-go-sdk4、表设计
订单系统不仅仅是订单一张数据表,它应包含:消费者表、售货员表、产品表、供货商表、交易订单表、支付订单表等。在本样例中,猪腰使用最基本的四张表(消费者表、售货员表、产品表、交易订单表),仅以订单表举例如下:
表名:order_contract
| 列名 | 数据类型 | 索引类型 | 字段说明 |
|---|---|---|---|
| _id(主键列) | String | MD5(oId)避免热点 | |
| oId | String | KEYWORD | 订单编号 |
| pName | String | TEXT | 产品名,TEXT类型索引可模糊查询,但不能排序 |
| totalPrice | double | DOUBLE | 订单总价 |
| orderTime | long | LONG | 下单时间(时间戳) |
| ... | ... | ... | ... |
三、开始搭建(核心代码)
1、创建数据表
四张表:订单表、消费者表、售货员表、产品表
用户仅需维护一个实例,按如下方式创建:通过控制台创建、管理数据表(用户也可以通过SDK直接创建):
![]()
2、创建数据表索引
TableStore自动做全量、增量的索引数据同步:用户可以通过控制台创建、管理SearchIndex(用户也可通过SDK创建):
![]()
3、数据导入
插入部分测试数据(控制台样例中插入了1亿条数据,用户自己可以通过控制台插入少量测试数据);
| 订单号 | 订单(md5)(主键) | 消费者编号 | 消费者姓名 | 售货员编号 | 售货员姓名 | 产品编号 | 产品名 | 产品品牌 | 产品类型 | 下单时间 | 支付时间 | 支付状态 | 产品单价 | 数量 | 总价钱 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| o0000000000 | c49f5fd5aba33159accae0d3ecd749a7 | c0019 | 消陈九 | s0020 | 售楚十 | p0003004 | vivo x21 | vivo | 手机 | 2018-07-17 21:00:00 | 否 | 2498.99 | 2 | 4997.98 |
| 消费者编号(主键) | 消费者姓名 | 消费者积分 | 注册时间 |
|---|---|---|---|
| c0001 | 消赵一 | 818 | 2018-07-07 14:33:51 |
| 售货员编号(主键) | 售货员姓名 | 售货员积分 | 入职日期 |
|---|---|---|---|
| s0001 | 售赵一 | 613 | 2018-07-07 14:27:59 |
| 产品编号(主键) | 产品名 | 产品品牌 | 产品类型 | 产品单价 | 新增时间 |
|---|---|---|---|---|---|
| p0001001 | iphone 6 | 苹果 | 手机 | 6969.00 | 2018-07-07 14:44:39 |
4、数据读取
数据读取分为两类:
主键读取
基于原生表格存储的主键列获取:getRow, getRange, batchGetRow等。主键读取用于索引(自动)反查,用户也可以提供主键(订单md5)的单条查询的页面,亿量级下查询速度极快。单主键查询方式不支持多维度检索;
索引读取
基于新SearchIndex功能Query:search接口。用户可以自由设计索引字段的多维度条件组合查询。通过设置选择不同的查询参数,构建不同的查询条件、不同排序方式;目前支持:精确查询、范围查询、前缀查询、匹配查询、通配符查询、短语匹配查询、分词字符串查询,并通过布尔与、或组合。
如【c0001号消费者,且消费在99.99以上的订单】组合方式如下:
List<Query> mustQueries = new ArrayList<Query>();TermQuery termQuery = new TermQuery();
termQuery.setFieldName("cId");
termQuery.setTerm(ColumnValue.fromString("c0001"));
mustQueries.add(termQuery);RangeQuery rangeQuery = new RangeQuery();
rangeQuery.setFieldName("totalPrice");
rangeQuery.setFrom(ColumnValue.fromDouble(99.99));
mustQueries.add(rangeQuery);BoolQuery boolQuery = new BoolQuery();
boolQuery.setMustQueries(mustQueries);原文链接
本文为云栖社区原创内容,未经允许不得转载。
基于TableStore的亿级订单管理解决方案相关推荐
- 100亿级订单怎么调度,来一个大厂的极品方案
背景 超时处理,是一个很有技术难度的问题. 所以很多的小伙伴,在写简历的时候,喜欢把这个技术难题写在简历里边, 体现自己高超的技术水平. 在40岁老架构师 尼恩的读者交流群(50+)中,尼恩经常指导大 ...
- 大数据主题分享第三期 | 基于ELK的亿级实时日志分析平台实践
猫友会希望建立更多高质量垂直细分社群,本次是"大数据学习交流付费群"的第三期分享. "大数据学习交流付费群"由猫友会联合,斗鱼数据平台总监吴瑞诚,卷皮BI技术总 ...
- 基于BIM的工程建设智慧管理解决方案
对于超大型的基建工程项目,通常是业主单位或总包公司带领设计院.施工企业.监理和供应商等多个参与方数年或数十年协同工作.然而,工程项目目前依然缺乏机制.标准和信息系统支撑全生命周期一体化融合管控,设计. ...
- 基于java超市收银订单管理、基于ssm+mysql商店库存进销存和便利店商品管理系统
基于java超市收银订单管理.基于ssm+mysql商店库存进销存和便利店商品管理系统 系统架构 SpringBoot\SSM(两个版本都有) JSP.JSTL.jQuery.HTML.CSS.JS ...
- 阿里CCO:基于 Hologres 的亿级明细 BI 探索分析实践
CCO是Chief Customer Officer的缩写,也是阿里巴巴集团客户体验事业部的简称.随着业务的多元化发展以及行业竞争的深入,用户体验问题越来越受到关注.CCO体验业务运营小二日常会大量投 ...
- 太强了,300分钟撸一个基于redis的亿级用户高并发系统
对于双十一这种高并发.大流量的场景一般都会用到缓存抗住大并发,市面上缓存框架用的最多的无疑就是Redis了,Redis作为稳居世界排名第一的KV内存数据库,同时也是最受欢迎的分布式缓存中间件,是应对高 ...
- 数据库改造:怎样用MySQL对10亿级订单量进行分库分表?
一.背景 随着公司业务增长,如果每天1000多万笔订单的话,3个月将有约10亿的订单量,之前数据库采用单库单表的形式已经不满足于业务需求,数据库改造迫在眉睫. 二.订单数据如何划分 我们可以将订单数据 ...
- 10亿级订单系统分库分表设计思路
一.背景 随着公司业务增长,如果每天1000多万笔订单的话,3个月将有约10亿的订单量,之前数据库采用单库单表的形式已经不满足于业务需求,数据库改造迫在眉睫. 二.订单数据如何划分 我们可以将订单数据 ...
- vivo 全球商城:亿级订单中心架构设计与实践
一.背景 随着用户量级的快速增长,vivo 官方商城 v1.0 的单体架构逐渐暴露出弊端:模块愈发臃肿.开发效率低下.性能出现瓶颈.系统维护困难. 从2017年开始启动的 v2.0 架构升级,基于业务 ...
最新文章
- boost::mpi模块对 all_gather() 集体的测试
- SpringBoot高级-任务-定时任务
- 对硬盘进行分区和格式化
- 知了课堂 python_没想到你是这样的“知了课堂”
- mysql数据排序指令_MySQL 排序 | 菜鸟教程
- linux模块创建proc,[Linux 运维]/proc/modules 以及内核模块工具
- XMLHTTP---介绍
- 微服务架构实战(五):选择微服务部署策略
- Zabbix 3.4.2 install Configuration
- 40套各种风格住宿酒店行业网站html5模板大气商务酒店网站模板度假村酒店官方网站模板旅行酒店宾馆整站模板html5网页静态模板Bootstrap扁平化网站源码css3手机seo自适响应
- 将AD原理图文件和PCB文件转换为KiCad格式的方法
- 智能电销机器人语音自动外呼效果好吗
- JVM中的Xms和Xmx
- Python常见实体提取库Duckling,多语言,实体如日期、金额、距离
- 京东金融APP被曝侵犯隐私
- MVG读书笔记——单应矩阵估计这件小事(二)
- JS数组转字符串传到JAVA后端取出
- 拼多多用户数超越淘宝,电商市场正变成腾讯与阿里的对决
- RabbitMQ用户管理界面各个标签的解释,使用图片标注
- 微信小程序引用vant框架