深度学习工作机制通俗介绍
在本文之前,写过一些关于人工智能的科普性文章,比如人工智能为什么能起作用、模型是什么以及如何去创建模型、还原论和整体论以及降维过程(需外网)。这些基础性的文章使得我们能够更好地理解机器学习,感兴趣的读者可以阅读一下。本文主要是讨论深度学习的工作原理,这也是人工智能科普性文章系列的最后一篇。
深度学习执行降维过程
考虑到之前的章节,这不是一个令人吃惊的断言。在之前的章节中,我们从几个角度和层次讨论了人工智能是如何地高效工作。此外,也使用TensorFlow及相关API实现的例子演示了二者的性能。可以发现,TensorFlow及API的结合能够在这个系统中实现很多的解决方案,且泛化足够简单。
下图是使用Keras图像理解示意图
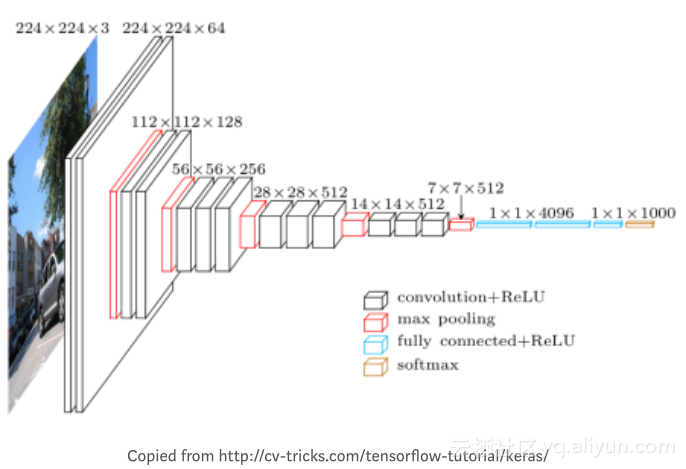
首先,将最左边的输入层称作“底部”,将上图旋转九十度后可以发现,可以将其看作是一个从低到高的抽象层次堆栈,随着层数的增多,可以看到数据量和每层的复杂度明显降低,我们能否确定这个系统是否也在执行认知降维过程?它是否减少了一些不重要的东西?如果是这样的话,深度学习是如何做到这一点以及怎样确定哪些是重要的东西?
一般而言,可以通过一些压缩或随机删除等方法来实现原始数据的降维,但这是不可取的。降维的目标是丢掉一些不重要的部分,保留重要的部分。一些人可能不理解基于显著性简化和可逆无损压缩算法作为智能度量的重要性,这些对于机器学习而言都是非常重要的内容。
所以我们可以想象一个关于深度学习的神话,假设我们已经建立了一个从图像中找到人脸的系统,并意图将它作为照相机中的一个功能特性。目前,许多照相机已经具备了这一特性,因此,这也是个常见的例子。我们实现了一个图像理解神经网络模型,并花一些时间给该模型展示许多不同类型的图像,这就是使用监督学习来学习模型,之后就能利用该模型来展示从图像中识别人脸的这一童话。
如上图所示,模型首先将输入图像从RGB彩色值转换为输入数组,然后数组经过许多层的操作处理后,输出的数据比输入的数据更少,这也意味着有些数据被处理掉了。每层接收的输入信号都来自上一层的输入,每层的输出传送给下一层。
在一些底层时,一些操作可能只是得到一些相邻的像素并确定方向,提取到一些边角信息。随着层数的加深,可以提取到更加抽象具体的信息,最终得到能够确定为一张人脸的特征信息。
丢弃所有非人脸特征信息后,剩下的就是脸。
人为的丢弃某些信息是不可取的,因为无法判断这些丢弃掉的信息是否有用,直到可以确定抽象级别的信息时,才可以进行操作。同理,以一个公园游玩照片为例,模型的一些底层操作不能丢弃草坪的信息,因为它们没有关于草坪或地面的显著线索,而更高层能够得到更加抽象具体的信息,因此能够丢弃一些无用的信息。每一层从前一层接收“低级描述”,并丢弃它认为不相干的信息,并向下一层传送更抽象的信息,直到最终找到人脸。这也是为什么深度学习模型一般层次会比较深的原因。
深度学习这一想法本身并不新颖,早在1959年就被讨论过。当时受限于算法、硬件水平及数据量的限制,没有得到很好的发展。近60年,随着硬件水平的不断提升,数据量的爆炸式增长,深度学习再一次焕发出勃勃生机,并展现出优异的性能。
下面讲解池化层操作,如下图所示。在TensorFlow中,有50多种池化操作,下图显示的2x2最大值池化操作,左图到右图需要执行四次池化操作。
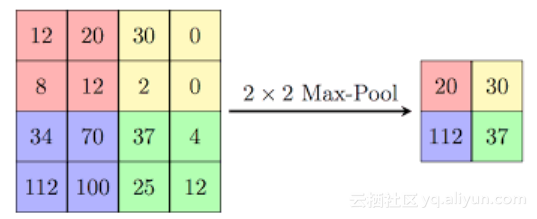
2x2最大值池化操作就是从2x2矩形框中挑选出其中的最大值,并将其作为输出。输入层四个相邻的像素值可能表示RGB通道中的亮度,因此数值更大的值能够更能代表其亮度信息。在2x2最大值池化操作中,舍去了75%的输入数据,只保存并传播其中的最大值。
就像素值而言,它可能意味着最亮的颜色值,但就草叶而言,这可能意味着“这里至少有一片草叶”。每层提取特征,并丢弃一些特征,这也意味着进行着降维操作。
可以清楚地看到,深层神经网络中最重要的思想之一就是:必须在多个抽象层上进行降维。只有在适当的层才能决定哪些信息可能是相关的,哪些信息可能是需要丢弃的。这也是一种简化过程,只有在学习中取得好的结果时,才会以这种方式作出决定。
下面讲解卷积过程,根据TensorFlow手册:
“请注意,虽然这些操作被称为卷积,严格上来讲,应该被称作‘互相关’”。
卷积层发现各种类型的交叉相关与共生性,图像内部存在空间关系,就像Geoff Hinton最近举的例子一样,通常在鼻子下面发现嘴巴。更明显的是,在有监督学习情况中,模式与可用元信息(标签)之间存在关联。
网络模型中的更高层次的信息描述了这些相关性,不相关信息被视为非显著信息而被丢弃。从之前的模型图中可以看到,卷积层与ReLU激活函数层后接着最大值池化层。其中ReLU是一种新型激活函数,能够舍去负值,该非线性函数对深度学习而言是非常重要的,相较于传统的Sigmoid等激活函数而言,ReLU激活函数表现更加优异。
由卷积层-ReLU层-池化层这三层组成的这种模式是相当流行且实用的,这是由于这种组合方式执行了一个可靠的降维过程,绝大多数的卷积神经网络模型都参考这种结构模式来建模。随着模型的加深,特征逐渐被减少,直到最终得到能够完成相关任务的正确特征。
这也是为什么深度学习模型是深层的原因,因为如果你明白在不同抽象层中哪些是相关和不相干信息,那么你只能通过丢弃无关的信息来降维。
深度学习是科学的吗?
尽管深度学习过程可以用数学符号描述(大多数是采用线性代数的形式),但这个过程本身是不科学的。深度学习就像一个黑匣子,我们无法理解这个系统是如何理解处理特征并完成相关任务的。
就拿卷积操作举例,正如TensorFlow手册中所说,卷积层发现相关性。许多草叶通常代表一个草坪,在TensorFlow中,系统会花费大量时间来发现这些相关性。一旦发现了某些相关性,这种关联会导致模型中某些权重的调整,从而使得特征提取正确。但从本质上来说,所有的相关性开始时对于模型来说都被遗忘了,必须在每次前向传播和梯度下降的过程中来重新发现。这种系统实际上是从错误中吸取教训,即模型输出与理想输出之间的误差。
前向和反向传播过程对图像理解有一定的意义,有些人在文本上使用了相同的算法。幸运的是,针对于文本任务而言,有更加高效的算法。首先,我们可以使用大脑突触或编程语言中的常规指针或对象引用显式地表示所发现的相关性,神经元与神经元之间有关联。
无论是深度学习算法,还是有机学习,都不是科学的。它们在缺乏证据并信任相关性的前提下得出结论,而不坚持可证明的因果关系。大多数深层神经网络编程很难得到理想结果并存在一定的误差,只能通过从实验结果中发现线索来改进模型。增加网络层数不总是有效的,对于大多数深度神经网络从业者而言,根据实验结果来调整改进网络就是他们的日常工作。没有先验模型,就没有先验估计。任何深层神经网络可靠性和正确性的最佳估计,都是经过大量的实验得到。
为什么我们会使用不能保证得到正确答案的工程系统呢?因为我们别无选择,使用整体方法当作可靠的降维方法是不可用的。与此类似,当任务需要有能力自主地执行上下文切片简化时,模型需要具有理解能力。
我们没有别的办法来处理这些不靠谱的机器吗?当然可以,因为地球上有几十亿的人类已经掌握了处理这项复杂任务的技能,所以你可以取代表现良好但理论上未经证实的玩意儿——一个通过深层神经网络建立的机器。比比你和机器谁每小时能挣更多的钱?这看起来不太像是科技的进步,这类机器不能被证明是正确的,因为它不能像普通计算机那样运行。
我最喜欢的一句话是由McCarthy和Hayes所断言的,“你看到了它,你将再次看到它”,深度学习是人工智能认识论其中一部分内容,尽管目前大多数智能是不科学的,但在几年后,我们将对智能定义达成一致意见,最终实现智能化的世界。
数十款阿里云产品限时折扣中,赶紧点击领劵开始云上实践吧!
作者信息
Monica Anderson,Syntience公司研究总监。
个人主页:https://www.linkedin.com/in/syntience/
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《Why Deep Learning Works》,作者:Monica Anderson,译者:海棠,审阅:袁虎。
文章为简译,更为详细的内容,请查看原文
深度学习工作机制通俗介绍相关推荐
- 深度学习工作开展_深入开展深度工作:新经济中的两项核心能力
深度学习工作开展 by Bar Franek 由Bar Franek 深入开展深度工作:新经济中的两项核心能力 (Going Deeper on Deep Work: Two Core Abiliti ...
- 【神经网络与深度学习】CIFAR10数据集介绍,并使用卷积神经网络训练图像分类模型——[附完整训练代码]
[神经网络与深度学习]CIFAR-10数据集介绍,并使用卷积神经网络训练模型--[附完整代码] 一.CIFAR-10数据集介绍 1.1 CIFAR-10数据集的内容 1.2 CIFAR-10数据集的结 ...
- 深入理解深度学习——注意力机制(Attention Mechanism):带掩码的多头注意力(Masked Multi-head Attention)
分类目录:<深入理解深度学习>总目录 相关文章: ·注意力机制(AttentionMechanism):基础知识 ·注意力机制(AttentionMechanism):注意力汇聚与Nada ...
- 深入理解深度学习——注意力机制(Attention Mechanism):注意力评分函数(Attention Scoring Function)
分类目录:<深入理解深度学习>总目录 相关文章: ·注意力机制(AttentionMechanism):基础知识 ·注意力机制(AttentionMechanism):注意力汇聚与Nada ...
- 程序如何在两个gpu卡上并行运行_深度学习分布式训练相关介绍 - Part 1 多GPU训练...
本篇文章主要是对深度学习中运用多GPU进行训练的一些基本的知识点进行的一个梳理 文章中的内容都是经过认真地分析,并且尽量做到有所考证 抛砖引玉,希望可以给大家有更多的启发,并能有所收获 介绍 大多数时 ...
- 推荐系统深度学习篇-NFM 模型介绍(1)
一.推荐系统深度学习篇-NFM 模型介绍(1) NFM是2017年由新加披国立大学提出的一种模型,其主要优化点在于提出了Bi-Interaction,Bi-Interaction考虑到了二阶特征组合, ...
- 15个小时彻底搞懂NLP自然语言处理(2021最新版附赠课件笔记资料)【LP自然语言处理涉及到深度学习和神经网络的介绍、 Pytorch、 RNN自然语言处理】 笔记
15个小时彻底搞懂NLP自然语言处理(2021最新版附赠课件笔记资料)[LP自然语言处理涉及到深度学习和神经网络的介绍. Pytorch. RNN自然语言处理] 笔记 教程与代码地址 P1 机器学习与 ...
- 深入理解深度学习——注意力机制(Attention Mechanism):自注意力(Self-attention)
分类目录:<深入理解深度学习>总目录 相关文章: ·注意力机制(AttentionMechanism):基础知识 ·注意力机制(AttentionMechanism):注意力汇聚与Nada ...
- 用物理学突破深度学习理论瓶颈? Google-斯坦福发布《深度学习统计力学》综述论文,30页pdf阐述深度学习成功机制...
来源:专知 [导读]深度学习革新了很多应用,但是背后的理论作用机制一直没有得到统一的解释.最近来自谷歌大脑和斯坦福的学者共同在Annual Review of Condensed Matter Phy ...
最新文章
- java的工作原理你知道吗_每天用Mybatis,但是Mybatis的工作原理你真的知道吗?
- 将Node.js升级到最新版本
- 重新精读《Java 编程思想》系列之public,protected,private与无修饰符权限的区别...
- mysql安装提示create_MySQL5.1安装时出现Cannot create windows service for mysql.error:0
- 最真实的办公自动化案例!
- python数据结构练习
- 如何取消计算机的自动更新,电脑自动更新如何取消 电脑自动更新取消方法
- PLSQL使用技巧 如何设置默认显示My Objects、记住密码等
- 中鸣机器人编程教程 c 语言,足球机器人编程(最好是图形化语言
- MATLAB画柱状图对比
- Axure RP9 制作下拉式菜单
- mysql统计近n天每天的数据量
- Linux下安装JDK(rpm版)
- 计算机应用基础第三版175页答案,计算机应用基础试题(附答案).doc
- MySQL批量导入Excel数据
- 让蔡徐坤来教你实现游戏中的帧动画(上)
- Intellij idea 第一天
- 分布式系统之----CAP理论
- 初学者使用html制作的一个新闻页面
- 树莓派4安装Ubuntu20.04
热门文章
- python sort函数排序_Python中排序常用到的sort 、sorted和argsort函数
- wxif 判断字符串相等_ES6:字符串、数组、对象的扩展
- 代码模板在哪里_C++的可变参数模板
- c语言常量x,C语言的数据、常量和变量
- 湖北大学计算机学院胡院长,学院召开新一届领导干部任命宣布大会
- 连接maven_Maven系列——超简单入门级教程
- java8电脑版安装包下载百度云_everything电脑文件搜索工具
- Java根据学号提取班级_学生成绩管理系统 1. 能够实现根据以下关键字查询:学生姓名 、学号、班级、课 联合开发网 - pudn.com...
- 不同sheet 选择若干条件_干货 | 不同加工条件下如何正确选择铣刀
- android实现博客app,如何从零实现一个你的个人博客Android App?