极大后验概率(MAP)- maximum a posteriori(转载)
在统计学中,最大后验(英文为Maximum a posteriori,缩写为MAP)估计方法根据经验数据获得对难以观察的量的点估计。它与最大似然估计中的 Fisher 方法有密切关系,但是它使用了一个增大的优化目标,这种方法将被估计量的先验分布融合到其中。所以最大后验估计可以看作是规则化(regularization)的最大似然估计。
假设我们需要根据观察数据 x 估计没有观察到的总体参数 θ,让 f 作为 x 的采样分布,这样 f(x | θ) 就是总体参数为θ 时 x 的概率。函数
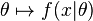
即为似然函数,其估计
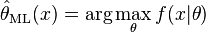
就是 θ 的最大似然估计。
假设 θ 存在一个先验分布 g,这就允许我们将 θ 作为 贝叶斯统计(en:Bayesian statistics)中的随机变量,这样 θ的后验分布就是:
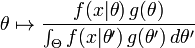
其中 Θ 是 g 的domain,这是贝叶斯定理(en: Bayes' theorem)的直接应用。
最大后验估计方法于是估计 θ 为这个随机变量的后验分布的mode:
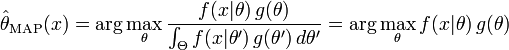
后验分布的分母与 θ 无关,所以在优化过程中不起作用。注意当前验 g 是 uniform(也就是常函数)时最大后验估计与最大似然估计重和。
最大后验估计可以用以下几种方法计算:
- 解析方法,当后验分布的模能够用 closed form 方式表示的时候用这种方法。当使用en:conjugate prior 的时候就是这种情况。
- 通过如共扼积分法或者牛顿法这样的数值优化方法进行,这通常需要一阶或者导数,导数需要通过解析或者数值方法得到。
- 通过 期望最大化算法 的修改实现,这种方法不需要后验密度的导数。
尽管最大后验估计与 Bayesian 统计共享前验分布的使用,通常并不认为它是一种 Bayesian 方法,这是因为最大后验估计是点估计,然而 Bayesian 方法的特点是使用这些分布来总结数据、得到推论。Bayesian 方法试图算出后验均值或者中值以及posterior interval,而不是后验模。尤其是当后验分布没有一个简单的解析形式的时候更是这样:在这种情况下,后验分布可以使用 Markov chain Monte Carlo 技术来模拟,但是找到它的模的优化是很困难或者是不可能的。
极大后验概率(MAP)- maximum a posteriori(转载)相关推荐
- 基础-数学-最大后验概率(MAP)maximum a posteriori
转载自 (http://blog.csdn.net/mafeichao/article/details/6403008) 在统计学中,最大后验(英文为Maximum a posteriori,缩写为M ...
- 最大后验概率(MAP)- maximum a posteriori(转载)
原文:http://student.csdn.net/space.php?uid=119638&do=blog&id=11801 在统计学中,最大后验(英文为Maximum a pos ...
- 【转】最大后验概率(MAP)- maximum a posteriori
最大后验概率(MAP)- maximum a posteriori var $tag='map,最大后验概率,杂谈'; var $tag_code='55bc272ff71193850b39cc269 ...
- 最大后验概率(MAP)- maximum a posteriori
原文:http://student.csdn.net/space.php?uid=119638&do=blog&id=11801 在统计学中,最大后验(英文为Maximum a pos ...
- 【数学基础】参数估计之最大后验估计(Maximum A Posteriori,MAP)
前言,MLE与MAP的联系 在前一篇文章参数估计之极大似然估计中提到过频率学派和贝叶斯学派的区别.如下图 在极大似然估计(MLE)中,我们求参数,通过使得似然函数最大,此时为一个待估参数,其本身是确定 ...
- 最大后验(Maximum a Posteriori,MAP)概率估计详解
最大后验(Maximum A Posteriori,MAP)概率估计 注:阅读本文需要贝叶斯定理与最大似然估计的部分基础 最大后验(Maximum A Posteriori,MAP)估计可以利用经 ...
- MAP(maximum a posteriori)
在统计学中,最大后验概率(MAP) 估计可以用于未知参量的点估计,它和最大似然估计maximum likelihood (ML)的Fisher方法差不多,但是这里的后验概率的最大化是和先验分布紧密相关 ...
- 参数估计(二)----极大后验概率估计
Maximum a posteriori estimation(极大后验概率估计),和ML(极大似然估计)相似,只不过是考虑了参数的先验分布. 还是贝叶斯公式: 极大后验概率,顾名思义,即: 根据贝叶 ...
- 机器学习基础:最大似然(Maximum Likelihood) 和最大后验估计 (Maximum A Posteriori Estimation)的区别
前言 在研究SoftMax交叉熵损失函数(Cross Entropy Loss Function)的时候,一种方法是从概率的角度来解释softmax cross entropy loss functi ...
最新文章
- 将csv文件导入到数据库中
- ROS中阶笔记(三):机器人仿真—ArbotiX+rviz功能仿真
- 台式计算机usb口不识别鼠标,usb鼠标不能识别怎么办解决教程
- php和会计,财务跟会计有什么区别
- 利用WebBrowser获得页面部分数据
- 【51NOD-0】1011 最大公约数GCD
- 如何手动编辑art分区修改qsdk(qca9531、qca9563)无线mac地址
- Data URL 基本介绍
- 服务器没有显示器能接笔记本吗,笔记本能连显示器吗_笔记本能不能接显示器...
- Ubuntu 18.04及Snap体验——让Linux入门更简单(转))
- 大家好,欢迎您加入这个集体!
- 什么是网站的源代码?
- 如何为WordPress的网站建立多级菜单?
- 【预测模型】基于BP神经网络、LSTM、GRNN实现风电功率预测附matlab代码
- Eclipse安装 dbeaver插件及使用
- Flowable实战-Camel使用
- 微信公众平台整合百度天气API
- ActiveX 控件
- 关键词提取-基于python实现tf-idf
- 小白误入软件应用层开发