L1 distace、L2 distance,L1 norm、L2 norm,L1、L2范数
在练习机器学习时,可能会选择决定是使用L1范数还是L2范数进行正则化,还是作为损失函数等。
L1范数也称为最小绝对偏差(LAD),最小绝对误差(LAE)。它基本上是最小化目标值(Y i)和估计值(f(x i))之间的绝对差值(S)的总和:
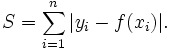
L2范数也称为最小二乘法。它基本上是最小化目标值(Y i)和估计值(f(x i)之间的差值(S)的平方和:
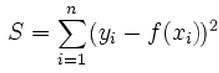
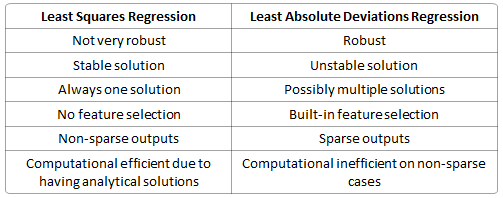
L1范数和L2范数的差异可以迅速归纳如下:
Robustness,维基解释如下:
最小绝对偏差的方法由于其与最小二乘法相比的鲁棒性而在许多领域中得到应用。最小的绝对偏差是稳健的,因为它可以抵抗数据中的异常值。这可能有助于可以安全有效地忽略异常值的研究。如果注意任何和所有异常值都很重要,那么最小二乘法是更好的选择。
直观地说,由于L2范数对误差进行平方(如果误差> 1则增加很多),模型将看到比L1范数大得多的误差(e vs e 2),因此模型对此示例,并调整模型以最小化此错误。如果此示例是异常值,则将调整模型以最小化此单个异常值情况,但会牺牲许多其他常见示例,因为与单个异常值情况相比,这些常见示例的错误较小。
Stability,维基百科的解释如下:
最小绝对偏差方法的不稳定性意味着,对于基准的小的水平调整,回归线可能跳跃很大量。该方法具有一些数据配置的连续解决方案; 但是,通过移动少量数据,可以“跳过”具有跨越区域的多个解决方案的配置。在通过该解决方案区域之后,最小绝对偏差线的斜率可能与前一线的斜率差别很大。相比之下,最小二乘解是稳定的,因为对于数据点的任何小调整,回归线总是只会轻微移动; 也就是说,回归参数是数据的连续函数。
最好用下面的图片解释:
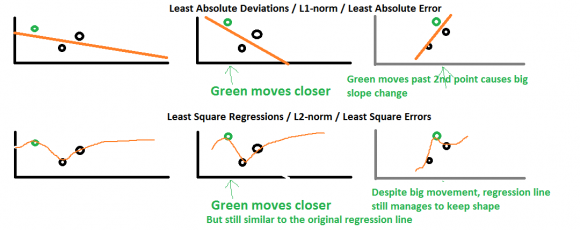
顶部代表L1范数,底部代表L2范数。第一列分别表示回归线如何使用L1范数和L2范数拟合这三个点。
假设我们将绿点水平向右略微移动,L2范数仍保持原始回归线的形状,但抛出更陡峭的抛物线。然而,在L1范数情况下,回归线的斜率现在更加陡峭,影响其他所有预测甚至超出最右边的点。因此,所有未来的预测都比L2标准结果受到更严重的影响。
假设我们将绿点更加水平地移动到第一个黑点(第三列)之后的右侧,L2范数现在也改变了一点但不像L1范数那样,斜率已完成转向方向。斜率的这种变化肯定会使之前的所有结果无效。
通过对数据点的微小扰动,回归线会发生很大变化。这就是L1范数的不稳定性(相对于L2范数的稳定性)在这里意味着什么。
解决方案的唯一性是一个更简单的情况,但需要一点想象力。首先,这张图片如下:
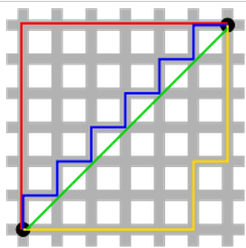
绿线(L2范数)是唯一的最短路径,而红色,蓝色,黄色(L1范数)对于相同路线都是相同的长度(= 12)。将其推广到n维。这就是L2-norm具有独特解决方案而L1-norm没有的原因。
内置特征选择 经常被提及作为L1范数的有用属性,而L2范数则不然。这实际上是L1范数的结果,它倾向于产生稀疏系数(如下所述)。假设模型有100个系数,但只有10个系数具有非零系数,这实际上是说“其他90个预测变量在预测目标值方面毫无用处”。L2范数产生非稀疏系数,因此没有这个属性。
稀疏性 指的是矩阵(或向量)中只有非常少的条目是非零的。L1范数具有产生具有零值的非常系数或具有很少大系数的非常小的值的特性。
计算效率。 L1范数没有解析解,但L2范数确实如此。这允许在计算上有效地计算L2范数解。然而,L1范数解决方案确实具有稀疏性属性,允许它与稀疏算法一起使用,这使得计算在计算上更有效。
参考资料:http://www.chioka.in/differences-between-the-l1-norm-and-the-l2-norm-least-absolute-deviations-and-least-squares/
L1 distace、L2 distance,L1 norm、L2 norm,L1、L2范数相关推荐
- TfidfVectorizer中的参数norm默认值是l2
TfidfVectorizer中的参数norm默认值是l2,而不是一直以为的None; 注释中的解释: norm是可选 ,而不是None值:如果默认为None,就会用default=None:对比图中 ...
- 【回归损失函数】L1(MAE)、L2(MSE)、Smooth L1 Loss详解
1. L1 Loss(Mean Absolute Error,MAE) 平均绝对误差(MAE)是一种用于回归模型的损失函数.MAE 是目标变量和预测变量之间绝对差值之和,因此它衡量的是一组预测值中的平 ...
- 数据结构:假设有一个带头结点的单链表L,每个结点值由单个数字、小写字母和大写字母构成。设计一个算法将其拆分成3个带头结点的单链表L1、L2和L3,L1包含L中的所有数字结点,L2包含L中的所有小写字母
假设有一个带头结点的单链表L,每个结点值由单个数字.小写字母和大写字母构成.设计一个算法将其拆分成3个带头结点的单链表L1.L2和L3,L1包含L中的所有数字结点,L2包含L中的所有小写字母结点,L3 ...
- [论文笔记]Decoupling Direction and Norm for Efficient Gradient-Based L2 Adversarial Attacks and Defenses
Decoupling Direction and Norm for Efficient Gradient-Based L2 Adversarial Attacks and Defenses(2019 ...
- matlab中norm a b,matlab中范数norm(A)
matlab中范数norm(A) (2013-08-09 17:40:33) 格式:n=norm(A,p) 功能:norm函数可计算几种不同类型的矩阵范数,根据p的不同可得到不同的范数 以下是Matl ...
- java 中_l1,L2指令获取错过远高于L1指令获取未命中
我正在生成一个合成C基准测试,旨在通过以下Python脚本导致大量的指令获取错过: #!/usr/bin/env python import tempfile import random import ...
- 给定单链表L:L0→L1→...→Ln-1→Ln, 重新排序:L0→Ln→L1→Ln-1→L2→Ln-2→...
1.重排链表 给定一个单链表 L:L0→L1→-→Ln-1→Ln , 将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→- 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换 ...
- 【L1正则化与L2正则化详解及为什么L1和L2正则化可防止过拟合】
一.为什么L1和L2正则化可防止过拟合? 线性模型常用来处理回归和分类任务,为了防止模型处于过拟合状态,需要用L1正则化和L2正则化降低模型的复杂度,很多线性回归模型正则化的文章会提到L1是通过稀疏参 ...
- 为什么L1正则化会有稀疏性?为什么L1正则化能进行内置特征选择?
# 个人认为,这两个应该是同一个问题. 首先给大家推荐一个比较直观地搞懂L1和L2正则化的思考,有视频有图像,手动赞! https://zhuanlan.zhihu.com/p/25707761 当然 ...
最新文章
- LINUX下的21个特殊符号 转
- Naveen Tewari先生荣获艾奇奖“年度商业创新领袖人物”
- Django创建第一个应用
- 怎么从计算机上删除东西吗,怎么在电脑中删除不想要的软件
- (54)Xilinx双沿原语-IDDR与ODDR(第11天)
- AirFlow常见问题汇总
- centos7 yum安装maven_Linux安装tomcat、mysql 、Maven与Eclipse的整合、settings.xml
- AngularJS中的表单验证机制
- 线上环境websocket连接地址_WebSocket:沙盒里的TCP
- python 环境问题
- UDS常用诊断服务介绍
- 基于UML的人事管理系统
- 后盾网经典原创视频教程php,《后盾网经典原创视频教程-PHP》139集
- canvas——绘制文字
- 重庆大学计算机学院张敏,张敏(安徽大学生命科学学院院长)_百度百科
- PCB设计—AD20和立创EDA设计(1)创建项目
- 网站SEO优化之图片优化方法
- 数据标准化的方法与作用
- Hadoop HA介绍
- 相机SD卡文件夹下所有文件损坏解决方法