Kafka 入门 and kafka+logstash 实战应用
一、基础理论
这块是整个kafka的核心无论你是先操作在来看还是先看在操作都需要多看几遍。
首先来了解一下Kafka所使用的基本术语
Topic
Kafka将消息种子(Feed)分门别类 每一类的消息称之为话题(Topic).
Producer
发布消息的对象称之为话题生产者(Kafka topic producer)
Consumer
订阅消息并处理发布的消息的种子的对象称之为话题消费者(consumers)
Broker
已发布的消息保存在一组服务器中称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题并从Broker拉数据从而消费这些已发布的消息。
让我们站的高一点从高的角度来看Kafka集群的业务处理就像这样子
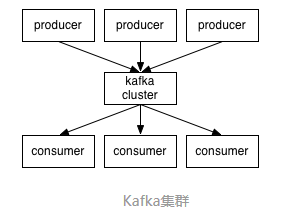
Client和Server之间的通讯是通过一条简单、高性能并且和开发语言无关的TCP协议。除了Java Client外还有非常多的其它编程语言的Client。
话题和日志 (Topic和Log)
让我们更深入的了解Kafka中的Topic。
Topic是发布的消息的类别或者种子Feed名。对于每一个TopicKafka集群维护这一个分区的log就像下图中的示例
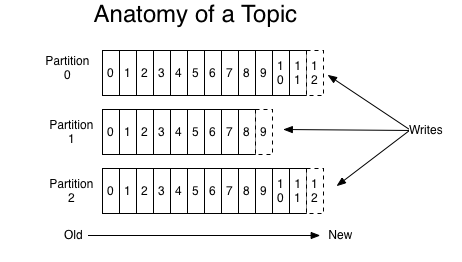
每一个分区都是一个顺序的、不可变的消息队列 并且可以持续的添加。分区中的消息都被分配了一个序列号称之为偏移量(offset)在每个分区中此偏移量都是唯一的。 Kafka集群保持所有的消息直到它们过期 无论消息是否被消费了。 实际上消费者所持有的仅有的元数据就是这个偏移量也就是消费者在这个log中的位置。 这个偏移量由消费者控制正常情况当消费者消费消息的时候偏移量也线性的的增加。但是实际偏移量由消费者控制消费者可以将偏移量重置为更老的一个偏移量重新读取消息。 可以看到这种设计对消费者来说操作自如 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区的设计有几个目的。一是可以处理更多的消息不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二分区可以作为并行处理的单元。
分布式(Distribution)
Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader零或多个follower。Leader处理此分区的所有的读写请求而follower被动的复制数据。如果leader宕机其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader另一个分区的follower。 这样可以平衡负载避免所有的请求都只让一台或者某几台服务器处理。
生产者(Producers)
生产者往某个Topic上发布消息。生产者也负责选择发布到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。开发者负责如何选择分区的算法。
消费者(Consumers)
通常来讲消息模型可以分为两种 队列和发布-订阅式。 队列的处理方式是 一组消费者从服务器读取消息一条消息只有其中的一个消费者来处理。在发布-订阅模型中消息被广播给所有的消费者接收到消息的消费者都可以处理此消息。Kafka为这两种模型提供了单一的消费者抽象模型 消费者组 consumer group。 消费者用一个消费者组名标记自己。 一个发布在Topic上消息被分发给此消费者组中的一个消费者。 假如所有的消费者都在一个组中那么这就变成了queue模型。 假如所有的消费者都在不同的组中那么就完全变成了发布-订阅模型。 更通用的 我们可以创建一些消费者组作为逻辑上的订阅者。每个组包含数目不等的消费者 一个组内多个消费者可以用来扩展性能和容错。正如下图所示
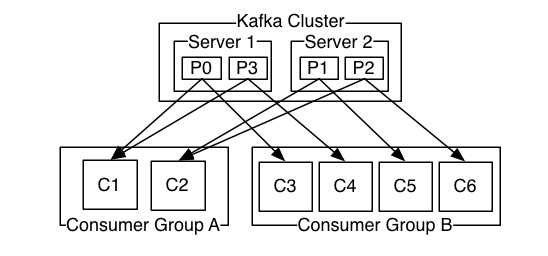
2个kafka集群托管4个分区P0-P32个消费者组消费组A有2个消费者实例消费组B有4个。
正像传统的消息系统一样Kafka保证消息的顺序不变。 再详细扯几句。传统的队列模型保持消息并且保证它们的先后顺序不变。但是 尽管服务器保证了消息的顺序消息还是异步的发送给各个消费者消费者收到消息的先后顺序不能保证了。这也意味着并行消费将不能保证消息的先后顺序。用过传统的消息系统的同学肯定清楚消息的顺序处理很让人头痛。如果只让一个消费者处理消息又违背了并行处理的初衷。 在这一点上Kafka做的更好尽管并没有完全解决上述问题。 Kafka采用了一种分而治之的策略分区。 因为Topic分区中消息只能由消费者组中的唯一一个消费者处理所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理不能保证跨分区的消息先后处理顺序。 所以如果你想要顺序的处理Topic的所有消息那就只提供一个分区。
Kafka的保证(Guarantees)
生产者发送到一个特定的Topic的分区上的消息将会按照它们发送的顺序依次加入
消费者收到的消息也是此顺序
如果一个Topic配置了复制因子( replication facto)为N 那么可以允许N-1服务器宕机而不丢失任何已经增加的消息
Kafka官网
http://kafka.apache.org/
作者半兽人
链接http://orchome.com/5
来源OrcHome
著作权归作者所有。商业转载请联系作者获得授权非商业转载请注明出处。
二、安装和启动
1、下载二进制安装包直接解压
|
1
2
|
tar xf kafka_2.11-0.10.0.1.tgz
cd kafka_2.11-0.10.0.1
|
2、启动服务
Kafka需要用到ZooKeepr所以需要先启动一个ZooKeepr服务端如果没有单独的ZooKeeper服务端可以使用Kafka自带的脚本快速启动一个单节点ZooKeepr实例
|
1
2
3
|
bin/zookeeper-server-start.sh config/zookeeper.properties # 启动zookeeper服务端实例
bin/kafka-server-start.sh config/server.properties # 启动kafka服务端实例
|
三、基本操作指令
1、新建一个主题topic
创建一个名为“test”的Topic只有一个分区和一个备份
|
1
|
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
|
2、创建好之后可以通过运行以下命令查看已创建的topic信息
|
1
|
bin/kafka-topics.sh --list --zookeeper localhost:2181
|
3、发送消息
Kafka提供了一个命令行的工具可以从输入文件或者命令行中读取消息并发送给Kafka集群。每一行是一条消息。
运行producer生产者,然后在控制台输入几条消息到服务器。
|
1
2
3
|
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
|
4、消费消息
Kafka也提供了一个消费消息的命令行工具,将存储的信息输出出来。
|
1
2
3
|
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
This is a message
This is another message
|
5、查看topic详细情况
|
1
|
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic peiyinlog
|

Topic: 主题名称
Partition: 分片编号
Leader: 该分区的leader节点
Replicas: 该副本存在于哪个broker节点
Isr: 活跃状态的broker
6、给Topic添加分区
|
1
|
bin/kafka-topics.sh --zookeeper 192.168.90.201:2181 --alter --topic test2 --partitions 20
|
7、删除Topic
|
1
|
bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name
|
主题(Topic)删除选项默认是关闭的,需要服务器配置开启它。
|
1
|
delete.topic.enable=true
|
注:如果需要在其他节点作为客户端使用指令连接kafka broker,则需要注意以下两点(二选一即可)
另 : ( 使用logstash input 连接kafka也需要注意 )
1、设置kafka broker 配置文件中 host.name 参数为监听的IP地址
2、给broker设置一个唯一的主机名,然后在本机/etc/hosts文件配置解析到自己的IP(当然如果有内网的DNS服务器也行),同时还需要在zk server 和 客户端的 /etc/hosts 添加broker主机名的解析。
原因详解:
场景假设
| broker_server ip | 主机名 | zookeeper ip | 客户端 ip |
| 192.168.1.2 | 默认 localhost | 192.168.1.4 | 192.168.1.5 |
|
1
2
3
|
# 此时客户端向broker发起一些消费:
bin/kafka-console-consumer.sh --zookeeper 192.168.1.4:2181 --topic test2 --from-beginning
|
这时客户端连接到zookeeper要求消费数据,zk则返回broker的ip地址和端口给客户端,但是如果broker没有设置host.name 和 advertised.host.name broker默认返回的是自己的主机名,默认就是localhost和端口9092,这时客户端拿到这个主机名解析到自己,操作失败。
所以,需要配置broker 的host.name参数为监听的IP,这时broker就会返回IP。 客户端就能正常连接了。
或者也可以设置好broker的主机名,然后分别给双方配置好解析。
四、broker基本配置
|
1
2
3
4
5
6
7
8
|
# server.properties
broker.id=0 # broker节点的唯一标识 ID 不能重复。
host.name=10.10.4.1 # 监听的地址,如果不设置默认返回主机名给zk_server
log.dirs=/u01/kafka/kafka_2.11-0.10.0.1/data # 消息数据存放路径
num.partitions=6 # 默认主题(Topic)分片数
log.retention.hours=24 # 消息数据的最大保留时长
zookeeper.connect=10.160.4.225:2181 # zookeeper server 连接地址和端口
|
五、Logstash + Kafka 实战应用
Logstash-1.51才开始内置Kafka插件,也就是说用之前的logstash版本是需要手动编译Kafka插件的,相信也很少人用了。建议使用2.3以上的logstash版本。
1、使用logstash向kafka写入一些数据
软件版本:
logstash 2.3.2
kafka_2.11-0.10.0.1
logstash output 部分配置
|
1
2
3
4
5
6
7
8
9
|
output {
kafka {
workers => 2
bootstrap_servers => "10.160.4.25:9092,10.160.4.26:9092,10.160.4.27:9092"
topic_id => "xuexilog"
}
}
|
参数解释 :
workers:用于写入时的工作线程
bootstrap_servers:指定可用的kafka broker实例列表
topic_id:指定topic名称,可以在写入前手动在broker创建定义好分片数和副本数,也可以不提前创建,那么在logstash写入时会自动创建topic,分片数和副本数则默认为broker配置文件中设置的。
2、使用logstash消费一些数据,并写入到elasticsearch
软件版本:
logstash 2.3.2
elasticsearch-2.3.4
logstash 配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
input{
kafka {
zk_connect => "112.100.6.1:2181,112.100.6.2:2181,112.100.6.3:2181"
group_id => "logstash"
topic_id => "xuexilog"
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
# 这里group_id 需要解释一下,在Kafka中,相同group的Consumer可以同时消费一个topic,不同group的Consumer工作则互不干扰。
# 补充: 在同一个topic中的同一个partition同时只能由一个Consumer消费,当同一个topic同时需要有多个Consumer消费时,则可以创建更多的partition。
output {
if [type] == "nginxacclog" {
elasticsearch {
hosts => ["10.10.1.90:9200"]
index => "logstash-nginxacclog-%{+YYYY.MM.dd}"
manage_template => true
flush_size => 50000
idle_flush_time => 10
workers => 2
}
}
}
|
3、通过group_id 查看当前详细的消费情况
|
1
|
bin/kafka-consumer-groups.sh --group logstash --describe --zookeeper 127.0.0.1:2181
|

输出解释:
| GROUP | TOPIC | PARTITION | CURRENT-OFFSET | LOG-END-OFFSET | LAG |
| 消费者组 | 话题id | 分区id | 当前已消费的条数 | 总条数 | 未消费的条数 |
本文出自 “突破舒适区” 博客,请务必保留此出处http://tchuairen.blog.51cto.com/3848118/1855090
来源:http://tchuairen.blog.51cto.com/3848118/1855090
Kafka 入门 and kafka+logstash 实战应用相关推荐
- kafka分区与分组原理_大数据技术-Kafka入门
在大数据学习当中,主要的学习重点就是大数据技术框架,针对于大数据处理的不同环节,需要不同的技术框架来解决问题.以Kafka来说,主要就是针对于实时消息处理,在大数据平台当中的应用也很广泛.大数据学习一 ...
- kafka topic 一段时间不消费_全网最通俗易懂的 Kafka 入门
众所周知,消息队列的产品有好几种,这里我选择学习Kafka的原因,无他,公司在用. 我司使用的是Kafka和自研的消息队列(Kafka和RocketMQ)改版,于是我就想学学Kafka这款消息队列啦. ...
- Apache Kafka 入门 - Kafka命令详细介绍
Apache Kafka 入门 Apache Kafka 入门大概分为5篇博客,内容都比较基础,计划包含以下内容: Kafka的基本配置和运行 Kafka命令详细介绍 Kafka-manager的基本 ...
- filebeat + logstash 发送日志至kafka 入门
filebeat 官方文档 配置文件 filebeat.yml filebeat.inputs:# Each - is an input. Most options can be set at the ...
- kafka入门到实战
kafka笔记 一.kafka基础 Linux下kafka配置:必须与zookeeper连用(先启动zookeeper再启动kafka) 1.vi server.properties broker.i ...
- Kafka 入门和 Spring Boot 集成
2019独角兽企业重金招聘Python工程师标准>>> Kafka 入门和 Spring Boot 集成 概述 kafka 是一个高性能的消息队列,也是一个分布式流处理平台(这里的流 ...
- Kafka入门篇学习笔记整理
Kafka入门篇学习笔记整理 Kafka是什么 Kafka的特性 应用场景 Kafka的安装 单机版部署 集群部署环境准备 Kafka 2.x集群部署 Kafka 3.x集群部署 监听器和内外网络 K ...
- Kafka : Kafka入门教程和JAVA客户端使用
目录 目录 Kafka简介 环境介绍 术语介绍 消费模式 下载 集群安装配置 命令使用 JAVA实战 参考文献 Kafka简介 由Scala和Java编写,Kafka是一种高吞吐量的分布式发布订阅消息 ...
- Kafka入门教程与详解
1 Kafka入门教程 1.1 消息队列(Message Queue) Message Queue消息传送系统提供传送服务.消息传送依赖于大量支持组件,这些组件负责处理连接服务.消息的路由和传送.持久 ...
最新文章
- 云视通手机录像存储在什么地方_抖音影视剪辑抽帧是什么意思
- php pdo预处理查询,关于php:从PDO预处理语句中获取原始SQL查询字符串
- 解决waitfor()阻塞问题
- CMS模板引擎:XHtmlAction
- 微信数据有望彻底删除了!史上最严隐私法规 GDPR 正式推行
- 介绍数据库中的wal技术_简介事务ACID的实现机制
- 象棋游戏显示服务器断开,天天象棋黑屏闪退怎么办 游戏玩不了解决方法
- 怎么用wps做区域分布图_《wps频数分布表怎么做》 在EXCEL中如何做频率分布图
- GitHub 上有哪些优秀的 Python 爬虫项目?
- php爬虫入门之phpspider框架
- visio 连接线样式设置 如箭头线
- 硬盘的老化测试软件,扩容卡检测、扩容U盘检测工具(MyDiskTest)
- 华为达芬奇AI芯片架构
- python 豆瓣源_使用豆瓣源来安装python中的第三方库方法
- 用IE浏览器打开网址https显示不能访问怎么办
- php 考试座位编排系统,具才考场座次编排系统
- unity-shader-基于图像的光照IBL
- RemoteView流程
- 微信小程序解密过程(java)
- win10用户查看系统激活码方式
热门文章
- kerberos安装配置、配置kerberos server、client、日常操作与常见问题、卸载kerberos、hive整合kerberos
- 大数据之mongodb -- (2)java集成 MongoDB 3.2,使用Spring-data-mongodb进行集成
- MySQL 8.0 CentOS 7安装手册
- java画虚线_java cansvas 画虚线要怎么设置?
- 黑电平校正、FPN校正、平场校正、白平衡校正
- 编译 pycaffe时报错:fatal error: numpy/arrayobject.h没有那个文件或目录
- 谈VHDL/Verilog的可综合性以及对初学者的一些建议
- defparam的语法
- icp点云匹配迭代最近邻算法
- JAVA NIO编程入门(二)