Kafka测试1.0.0
2019独角兽企业重金招聘Python工程师标准>>> 
准备工作
硬件:笔记本,windows10系统4核8G内存
软件:接口测试工具,以及kafka自带测试工具
影响测试结果配置分析
Borker
- num.network.thread=3
用于接收并处理网络请求的线程数,默认为3。其内部实现是采用Selector模型。启动一个线程作为Acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从Sockets里读取请求,一般无需改动,除非上下游并发请求量过大。
- num.partiton=1
Partition的数量选取也会直接影响到Kafka集群的吞吐性能。例如我们接口如果开了多个线程去消费kafka的数据,每个Partition对应一个Mapper去消费数据,如果Partition数量太少,则任务会因为Mapper数不足而非常慢。此外,当Partition数量相对于流入流出的数据量显得较少,或由于业务逻辑和Partition数量没有匹配好造成个别Partition读写数据量大,大量的读写请求集中落在一台或几台机器上时就会很影响效率。
- Replica.lag.time.max.ms=10000
- Replica.lag.message=4000
- Num.replica.fetchers=1
对于任意(Broker, Leader)元组,都会有replication.factor-1个Broker作为Replica,在Replica上会启动若干Fetch线程把对应的数据同步到本地,而num.replica.fetchers这个参数是用来控制Fetch线程的数量。
- Default.replication.factor=1
默认创建topic的时候创建replication-factor的数量。(这个相当于备份数据,每次producer发送消息会发送replication-factor的数目的消息,很影响效率,一般设置2-3个性能最好)同样解决这个问题的办法可以设置producer的属性acks(0是生产不会等服务器返回结果,而会一直发送,会丢数据,但速度贼快;1是会等leader的partition返回结果值,有一定延迟但能保证数据不丢,all或者-1是会等所有副本都返回值,再继续生产,延迟大,但保障性最好)
- Batch.size=16384
kafka会默认将发送到一个partiton的数据进行整合,这个大小是处理请求数据大小batch发送的,如果太小,可能就只能单独请求发送消息给kafka。
Producer
使用新版本jar包(producer.client)下的producer进行发送数据(0.8版本上,我们现在使用的0.10版本)
Consumer
- num.consumer.fetchers=1
启动consumer的个数,适度增加可以提高并发量
测试属性之间关系
BrokerList和Replication和Partition之间的关系
BrokerList配置一个7000,partition为3,replication为1,开启了7000,发送一条信息,得到的结果:在7000的生成3个partition文件夹,数据在其中一个partition文件夹中。
BrokerList配置多个7000、7001、7002,partition为3,replication为1,开启7000,发送一条信息,得到的结果:在7000的生成3个partition文件夹,数据在其中一个partition文件夹中。
BrokerList配置多个7000、7001、7002,partition为3,replication为1,开启7000、7001、7002,发送一条信息,得到结果:在7000上面生成1个文件夹,7001生成一个文件夹,7002生成一个文件夹,数据在7001文件夹中。
结论:当我们不配置replication-factor的时候,那么你向brokerList发送数据,kafka会自动根据你的partition生成不同的文件夹目录,并且不会进行备份;同理我们配置了replication为3,开启三个7000,7001,7002那么数据会自动备份,且只会在每个broker中生成三个partition文件夹。(我们配置spring文件的时候,brokerList只需要设置一个就可以,replication会自动帮我匹配已经开启的节点作为follower进行备份,与配置中brokerList个数没有关系,如果你配置了三个broker,那么还是其中一个作为leader进行写入数据,其余两个broker作为follower进行备份,而不会出现上面红色字体情况)
Replication和acks之间的关系
100000条数据速度,replication-factor数据为3表示有两个备份(时间单位毫秒)
| replication-factor=1 | repilication-factor=3 | Offset | |
| Acks=All/-1 | 29529 | 29524 | 具体值 |
| Acks=1 | 29498 | 27123 | 具体值 |
| Acks=0 | 9092 | 10468 | -1 |
结论:100000数据并没有丢失,但是从时间上看,如果acks=0速度是最快的,但是不安全,我们写回调监听的时候返回的offset的数据为-1,表示我们并不知道它是否已经写入kafka的文件夹中;如果设置acks为1,速度有一些慢,但是很安全,回调监听函数会返回插入数据的offset对应具体值,表示我们已经知道他已经插入成功了;如果Acks=All(或者为-1)速度是最慢的,监听器也会返回我们offset具体值,为什么它最慢效率最低,原因是这个参数设置为all表示kafka当配置了replication-factor的时候会follower会从leader中拉取数据作为备份,并告诉leader备份成功了,然后leader在告诉kafka我已经完成了kafka的写入数据操作。与acks=1的差别,就是相差备份数据的完成过程。
BatchSize和发送数据之间的关系
发送100条数据,默认分区数为3(Partition为3)
当我们配置batchSize为默认值的时候(16384),监听器返回的结果数据为:
- 先发送Partiton 0的数据(0,3,6,9....)
- 在发送Partition1的数据(1,4,7,10...)
- 最后发送Partition2的数据(2,5,8,11....)
修改batchSize配置为10,监听器返回的数据结果为:
0,1,2,3,4.....(分别对应不同的partition)
结论:当我们设置batchSize数据适当的时候,kakfa-producer提交数据请求的时候会根据partiton进行数据整合,然后统一发送一个producer请求,如果设置的batchsize很小,那么每个写入的都不满足进行整合大小的条件,那么producer每次都会重新提交一个请求进行数据写入。
Consumer数量和Partition之间的关系
我们开启线程作为consumer,配置了三个了partiton0,partition1,partition2,发送了10个数据,看看数据分布:
Partition0:0,3,6,9 partition1:1,4,7 partition2:2,5,8
Consumer只有一个:Consumer的消费顺序:0,3,6,9,2,5,8,1,4,7
结论,如果使用分区,不能保证数据顺序,但是会保证每个partition的数据的顺序
Consumer有两个:Consumer-1消费:0,3,6,9,1;Consumer-2消费:2,5,8,4,7
结论:两个会消费kafka分配给自己分区的数据,多于分区的数据会后消费,且共同消费剩余分区的。注:谁消费多谁消费少完全由消费者消费能力决定的。
Consumer有三个:Consumer-1 消费:0,3,6,9;Consumer-2 消费:1,4,7;Consumer-3 消费:2,5,8
结论:三个消费者分别消费不同分区的数据,并且不进行交互消费。
Consumer有四个:Consumer-1 消费:0,3,6,9;Consumer-2 消费:1,4,7;Consumer-3 消费:2,5,8;Consumer-4 消费:空
结论:消费者数量大于partition数量的时候,多余的consumer会作为空闲等待,除非有consumer挂掉。
定义消费者组group.id:当我们设置了消费者为消费者组group.id相同的时候,消费者组中多余的消费者会空闲等待,如果不是这个组的消费者挂掉,不会启动这个消费者组中的消费者进行补充
结论:topic下的一个分区下的消息只能被同一个消费者组的中的一个消费者消费
所以综上所述,consumer设置的个数要小于partition分区数,如果想要保证顺序,那么不要使用分区,如果要保证并发数量并且使用分区,那么最好设置consumer的消费者数量和分区数量相等。
分区数确定算法:分区数=Tt/Max(Tp,Tc)
Tp:producer吞吐量 Tc:consumer吞吐量 Tt目标的吞吐量
Consumer和Rebalance之间的关系
如果topic1有0,1,2共三个Partition,当group1只有一个Consumer(名为consumer1)时,该 Consumer可消费这3个Partition的所有数据。如图:

增加一个Consumer(consumer2)后,其中一个Consumer(consumer1)可消费2个Partition的数据(Partition 0和Partition 1),另外一个Consumer(consumer2)可消费另外一个Partition(Partition 2)的数据。

再增加一个Consumer(consumer3)后,每个Consumer可消费一个Partition的数据。consumer1消费partition0,consumer2消费partition1,consumer3消费partition2。
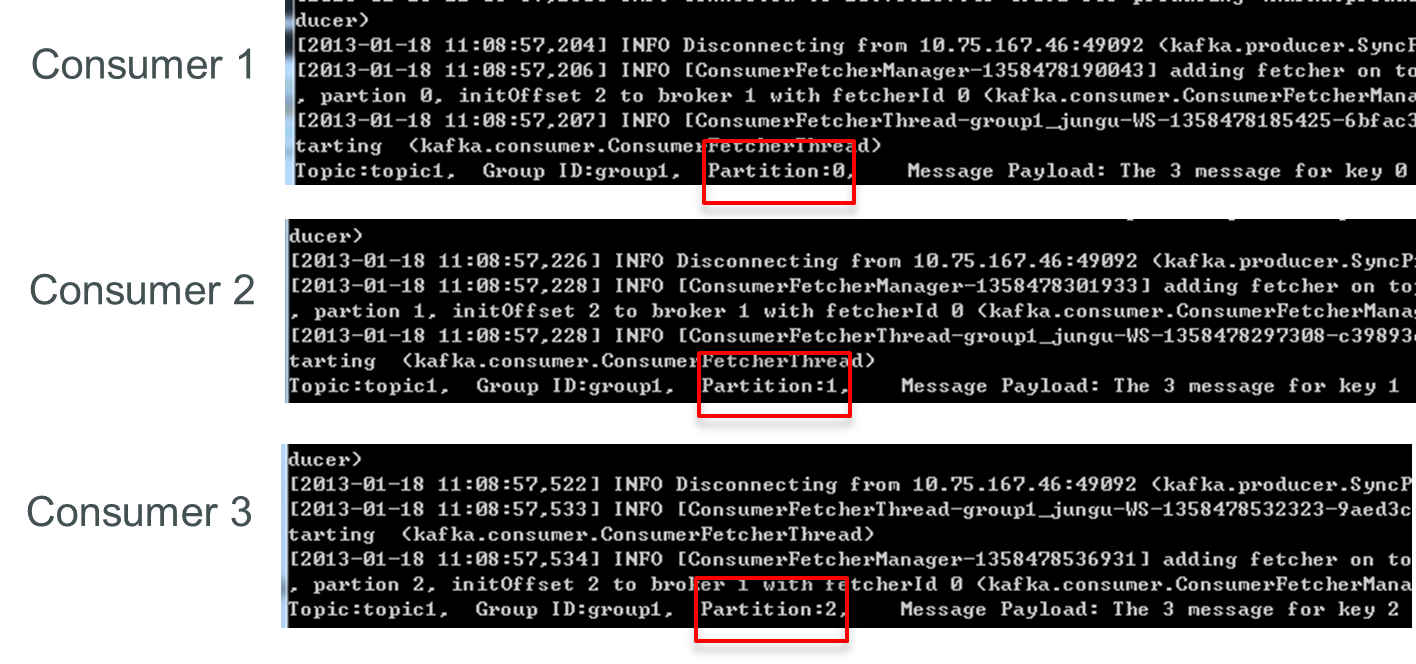
再增加一个Consumer(consumer4)后,其中3个Consumer可分别消费一个Partition的数据,另外一个Consumer(consumer4)不能消费topic1的任何数据。
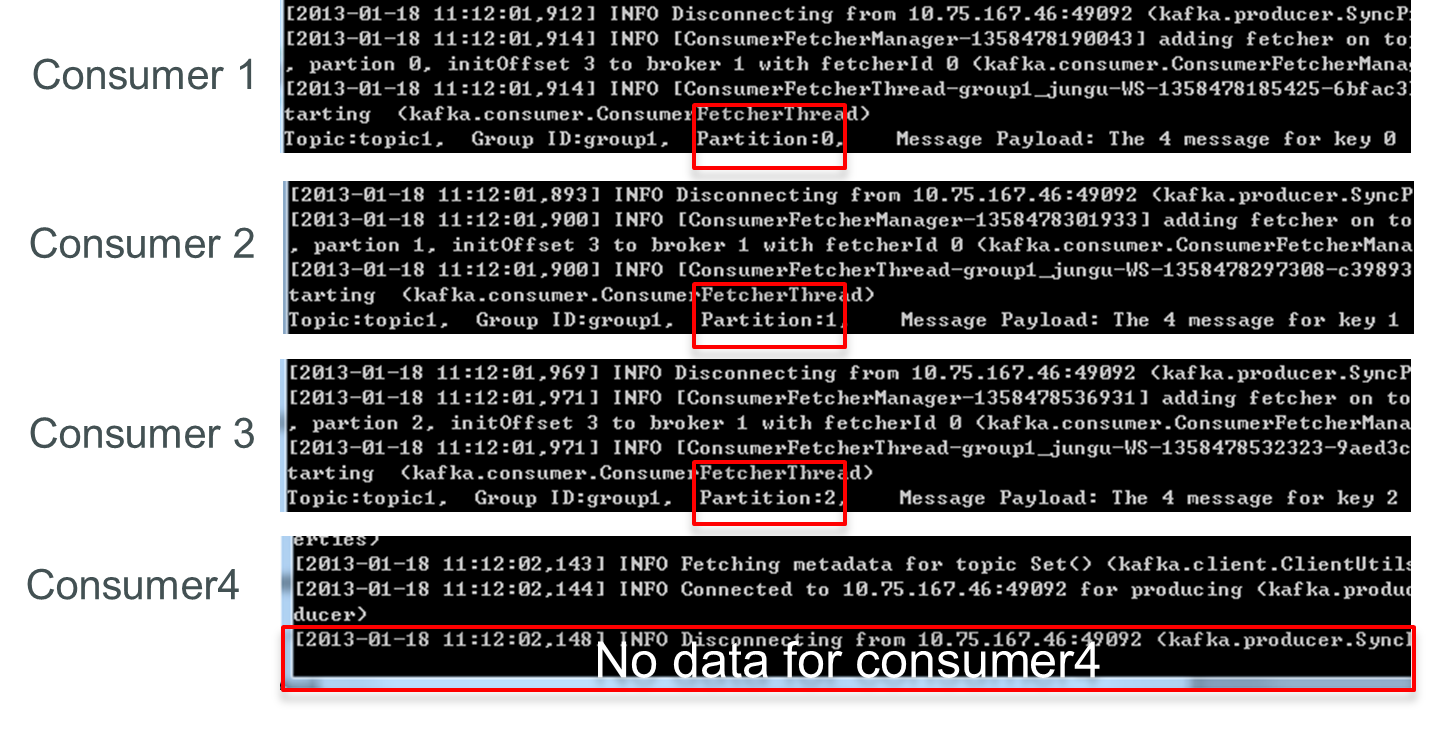
此时关闭consumer1,其余3个Consumer可分别消费一个Partition的数据。

接着关闭consumer2,consumer3可消费2个Partition,consumer4可消费1个Partition。
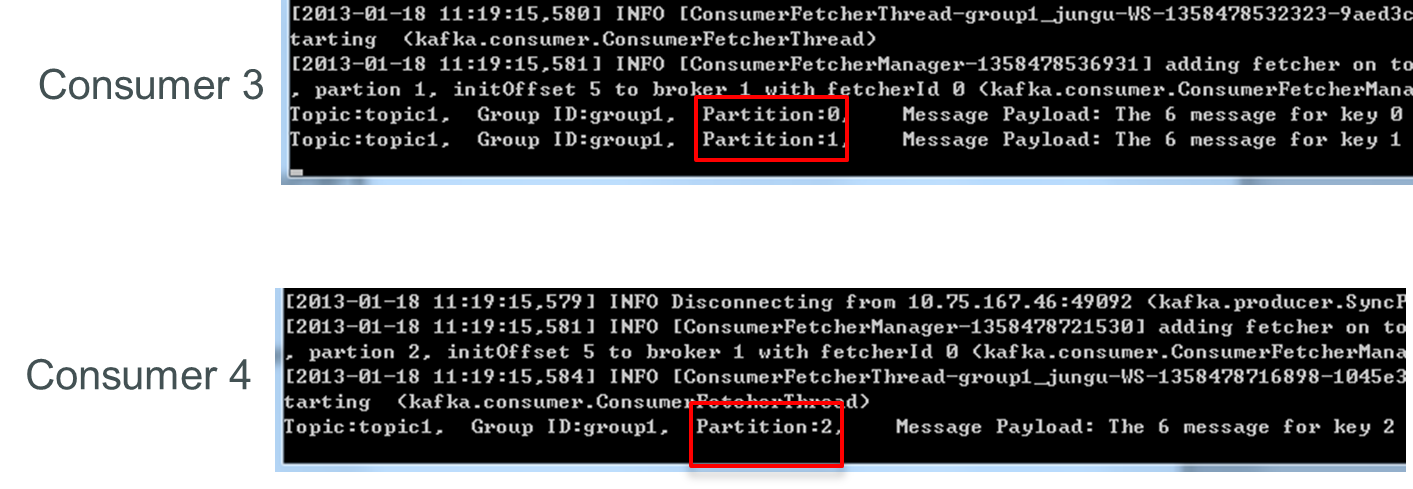
再关闭consumer3,仅存的consumer4可同时消费topic1的3个Partition。
Consumer Rebalance的算法如下:
- 将目标Topic下的所有Partirtion排序,存于PT
- 对某Consumer Group下所有Consumer排序,存于CG,第i个Consumer记为Ci
- N=size(PT)/size(CG),向上取整
- 解除Ci对原来分配的Partition的消费权(i从0开始)
- 将第i∗N到(i+1)∗N−1个Partition分配给Ci
测试性能之间关系
Producer吞吐量
1.线程数
创建一个6个分区,没有备份的topic,设置不同的线程数(server.properties中的配置num.network.thread)生产相同量的数据,查看性能变化。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 6 --topic test-ref-1
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-1 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Replication |
Records/second |
MB/second |
|
1 |
test-ref-1 |
1 |
6 |
1 |
98286.5 |
18.746 |
|
2 |
test-ref-1 |
3 |
6 |
1 |
99946 |
19.06 |
|
3 |
test-ref-1 |
6 |
6 |
1 |
99946 |
19.06 |
初步结论:新版本测试工具可以设置吞吐量大小,所以效果不明显,根据老版本测试是在分区一定的情况下,线程数小于分区数基础上提高吞吐量。
2.分区数
创建两个topic,一个分区数为3,一个分区数6,线程数相同然后生产相同数量的数据。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 3 --topic test-ref-2
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 12 --topic test-ref-3
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-2 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-3 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Replication |
Records/second |
MB/second |
|
1 |
test-ref-2 |
3 |
3 |
1 |
90903.3 |
17.34 |
|
2 |
test-ref-3 |
3 |
12 |
1 |
99297.9 |
18.94 |
初步结论:partition越多,吞吐量越大(但是根据网上结论,这个是有一定峰值,当达到峰值的时候,数量趋于平缓)如下图:
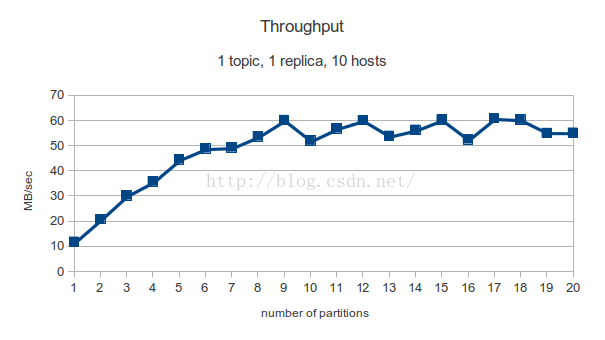
3.备份数
创建两个topic,一个备份数1,一个备份数3,单线程生产相同数量的数据。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 2 --partition 3 --topic test-ref-4
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-4 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Replication |
Records/second |
MB/second |
|
1 |
test-ref-2 |
3 |
3 |
1 |
90903.3 |
17.34 |
|
2 |
test-ref-4 |
3 |
3 |
2 |
48962.2 |
9.34 |
初步结论:备份数越大,吞吐量越低。
4.Broker数
分两次创建分区数大于1的topic:第一次开启一个broker创建topic,并且发送数据,第二次开启两个broker创建topic,并发送数据。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 3 --topic test-ref-5
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-5 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Replication |
Records/second |
MB/second |
|
1 |
test-ref-2 |
3 |
3 |
1 |
90903.3 |
17.34 |
|
2 |
test-ref-5 |
3 |
3 |
1 |
92539.5 |
17.65 |
初步结论:broke越多,吞吐量越大(但是效果不明显-测试了broker为3和4的情况,并未截图)
5.批处理大小
批处理大小引用他人测试,并未进行实测。
通过如下图表查看测试结果:
|
操作 |
Bacth-size |
线程数 |
Partition |
Replication |
Records/second |
MB/second |
|
1 |
200 |
2 |
6 |
2 |
86491.7227 |
8.2485 |
|
2 |
1000 |
2 |
6 |
2 |
187594.7353 |
17.8904 |
|
3 |
2000 |
2 |
6 |
2 |
244479.6495 |
23.3154 |
|
4 |
3000 |
2 |
6 |
2 |
248172.2117 |
23.6675 |
|
5 |
4000 |
2 |
6 |
2 |
242217.5501 |
23.0997 |
|
6 |
5000 |
2 |
6 |
2 |
172405.4701 |
16.4419 |
关系折线图如下:
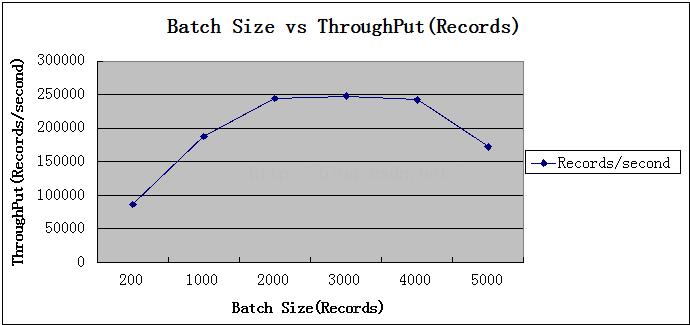
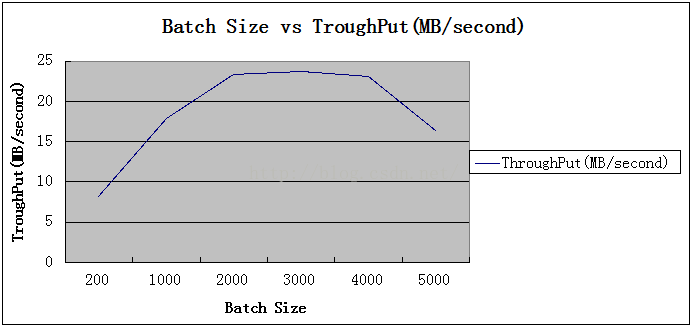
初步结论:批处理在适当范围内会使吞吐量增高,一定范围内趋于平稳,大于峰值之后会减小吞吐量。
6.消息长度
消息大小引用他人测试,并未进行实测。
通过如下图表查看测试结果:
|
操作 |
Bytes |
线程数 |
Records/second |
MB/second |
|
1 |
100 |
2 |
248172.2117 |
23.6675 |
|
2 |
200 |
2 |
132873.0610 |
25.3435 |
|
3 |
500 |
2 |
79277.1195 |
37.8023 |
|
4 |
1000 |
2 |
39015.5290 |
37.2081 |
关系折线图如下:

初步结论:上面的所有测试都基于短消息(payload100字节),而正如上文所说,短消息对Kafka来说是更难处理的使用方式,可以预期,随着消息长度的增大,records/second会减小,但MB/second会有所提高。下图是records/second与消息长度的关系图。(我们消息长度大约:650~800字节/每条订单)
Consumer吞吐量
1.consumer数
创建Topic,分区数为6,线程数1,设置不同的consumer数量。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 6 --topic test-ref-6
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-6 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
(3)消费数据
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 1 --topic test-ref-6
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 3 --topic test-ref-6
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 6 --topic test-ref-6
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 12 --topic test-ref-6
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Consumer |
Message/second |
MB/second |
|
1 |
test-ref-6 |
1 |
6 |
1 |
370644.9222 |
70.6949 |
|
2 |
test-ref-6 |
1 |
6 |
3 |
432900.4329 |
86.5692 |
|
2 |
test-ref-6 |
1 |
6 |
6 |
407664.0848 |
77.7558 |
|
2 |
test-ref-6 |
1 |
6 |
12 |
430663.2214 |
82.1425 |
初步结论:在partition一样的时候,一个consumer-group中的consumer越多消费吞吐量越大,但是consumer数量到达和partition数量相同的时候那么消费者吞吐量不会增加。
2.consumer分区数
创建Topic,线程数1,consumer数量为3,设置不同的分区数量。
执行命令:
(1)创建topic
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 1 --topic test-ref-7
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 3 --topic test-ref-8
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 6 --topic test-ref-9
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partition 12 --topic test-ref-10
(2)生产数据
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-7 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-8 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-9 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
kafka-producer-perf-test.bat --num-records 1000000 --topic test-ref-10 --record-size 200 --throughput 100000 --producer-props bootstrap.servers=localhost:7000
(3)消费数据
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 3 --topic test-ref-7
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 3 --topic test-ref-8
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 3 --topic test-ref-9
kafka-consumer-perf-test.bat --messages 1000000 --threads 1 --zookeeper localhost:2181 --num-fetch-threads 3 --topic test-ref-10
运行结果如下表所示:
|
操作 |
Topic |
线程数 |
Partition |
Consumer |
Message/second |
MB/second |
|
1 |
test-ref-7 |
1 |
1 |
3 |
320410.1250 |
61.1134 |
|
2 |
test-ref-8 |
1 |
3 |
3 |
423908.4358 |
80.8541 |
|
3 |
test-ref-9 |
1 |
6 |
3 |
440528.6344 |
84.0242 |
|
4 |
test-ref-10 |
1 |
12 |
3 |
458505.2728 |
87.4529 |
初步结论:在consumer数量相同的时候,partition数量越大,吞吐量越高。但是partition数量大于255的时候producer发送速度和consumer消费速度慢的要死。(前提是consumer数量小于partition数,如果大于,有consumer闲置)
3.consumer数与分区数(消费接口)
Consumer-group下的consumer数越多消费效率越快,但是当大于topic分区数的时候有些consumer是休息状态,具体看上面Consumer的数量和Partition之间的关系;由于本地只有一台机器无法模拟多个consumer消费的情况。
1. 测试前准备:创建topic
1.1 查看参数描述:./bin/kafka-topics.sh
1.2 创建topic,根据实际应用场景选择replication-factor和partitions
./bin/kafka-topics.sh --create --zookeeper zookeeper_1,zookeeper_2,zookeeper_3 --replication-factor 1 --partitions 1 --topic topic_name
1.3 查看创建topic的详细信息
./bin/kafka-topics.sh --describe --zookeeper zookeeper_1,zookeeper_2,zookeeper_3 --topic topic_name
2. producer测试: 主要不同kafka 8部分
2.1 首先看看参数:./bin/kafka-producer-perf-test.sh
usage: producer-performance [-h] --topic TOPIC --num-records NUM-RECORDS --record-size RECORD-SIZE --throughput THROUGHPUT --producer-props PROP-NAME=PROP-VALUE [PROP-NAME=PROP-VALUE ...] 脚本规范
optional arguments:
-h, --help show this help message and exit
--topic TOPIC produce messages to this topic
--num-records NUM-RECORDS
number of messages to produce
--record-size RECORD-SIZE
message size in bytes
--throughput THROUGHPUT
throttle maximum message throughput to *approximately* THROUGHPUT messages/sec
--producer-props PROP-NAME=PROP-VALUE [PROP-NAME=PROP-VALUE ...]
kafka producer related configuaration properties like bootstrap.servers,client.id etc..
参数producer-props可以并列填写多个参数,这里给个案例:
--producer-props bootstrap.servers=broker_1,broker_2,broker_3 acks=all
这里设定两个参数bootstrap.servers和acks,其他的都是默认,具体代表的意义,可以参看apache kafaka官网的documents>>producer config;
最后列个完整的producer测试脚本
./bin/kafka-producer-perf-test.sh --topic topic_name --throughput 100000 --num-records 100000 --producer-props --producer-props bootstrap.servers=broker_1,broker_2,broker_3 acks=all --record-size 1000
3. consumer测试
需要特别注意一点,就是在测试不同大小的消息队列时,最好使用不同的topic。完整流程最好这样:(1)确定测试的record-size = A1;(2)新建topic;(3)使用producer脚本和(2)的topic,脚本参数设定record-size = A1,产生足量的数据;(4)consumer测试,对应message-size = A1
按照和producer类似的方法,这里只列个脚本案例:
./bin/kafka-consumer-perf-test.sh --messages 100000 --topic topic_name --zookeeper zookeeper_1,zookeeper_2,zookeeper_3 --broker_1,broker_2,broker_3 --message-size A1
https://www.cnblogs.com/wangb0402/p/6221626.html
转载于:https://my.oschina.net/xiaominmin/blog/1794722
Kafka测试1.0.0相关推荐
- linux中kafka主题修改分区,kafka_2.11-2.0.0的部署与配置修改
1 [yun@mini01 config]$ pwd 2 /app/kafka/config3 [yun@mini01 config]$ vim server.properties4 ######## ...
- 测试hudi-0.7.0对接spark structure streaming
测试hudi-0.7.0对接spark structure streaming 测试环境 Hudi version :0.7.0 Spark version :2.4.0 Hive version : ...
- Apache Kafka 3.0.0 稳定版发布,有哪些值得关心的变化?
Apache Kafka 3.0 于2021年9月21日正式发布.本文将介绍这个版本的新功能.以下文章翻译自 <What's New in Apache Kafka 3.0.0>. 我很高 ...
- 官宣弃用Java 8!Kafka 3.0.0 新功能get
作者 | Travis 来源 | OSC开源社区(ID:oschina2013) Apache Kafka 是一个分布式流平台,具有四个核心 API.借助这些 API,Kafka 可以用于以下两大类应 ...
- 回复——在我测试的软件说明中,说安装好jboss后,在浏览器的地址栏中输入127.0.0.1:88这……...
回复--在我测试的软件说明中,说安装好jboss后,在浏览器的地址栏中输入127.0.0.1:88这个地址打开我的网页,请教版主127.0.0.1:88中的:88是什么意思?我怎么捆绑域名?谢谢! 首 ...
- kafka安装(版本kafka_2.11-0.11.0.0)
下载地址 https://archive.apache.org/dist/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz 安装 配置server.properties 搭 ...
- Apache Kafka 1.0.0正式发布!
千呼万唤始出来,经过7年的发展与完善,Apache Kafka 1.0.0正式发布!在笔者看来,比起1.0.0引入的新功能,此版本最大的意义在于标识Kafka各种组件功能的稳定性.不过我们还是来看下1 ...
- JUnit:使用Java 8和AssertJ 3.0.0测试异常
Java 8的AssertJ 3.0.0发行版比以前更容易测试异常. 在我以前的一篇博客文章中,我描述了如何利用纯 Java 8实现此目的,但是使用AssertJ 3.0.0可能会删除我创建的许多代码 ...
- 查询linux kafka安装目录,Kafka 1.0.0安装和配置--Linux篇
阅读目录: 1. 关闭防火墙和Selinux 2. 安装所需环境JDK,Zookeeper 3. 下载Kafka 1.0.0版本 4. 配置Kafka 5. 启动Kafka并验证 6. 报错及解决 7 ...
- kafka exporter v0.3.0 发布: Prometheus官方推荐,欢迎试用
2019独角兽企业重金招聘Python工程师标准>>> 时隔1个半月,kakfa exporter v0.3.0于今日正式发布,欢迎大家试用. 项目地址 Github: https: ...
最新文章
- 语义分割--Efficient Deep Models for Monocular Road Segmentation
- Angular 一个简单的指令实现 阻止事件扩散
- ResultSet 的相关介绍
- java redis快速入门_SpringDataRedis快速入门
- java编译时多态和运行时多态_运行时多态、编译时多态和重载、重写的关系(不区分Java和C#,保证能看懂!)...
- pbl和sbl_谈PBL和SBL教学法结合模式
- SpringBoot番外篇(一):使用Spring Initializer快速创建Spring Boot项目(IDEA版)
- 神奇!未来物联网的能源——纸生电
- Java 的 ArrayList 的底层数据结构
- 黄聪:一个拼图工具的制作思路
- 关于SQL92标准和Sybase,SQLServer2000,Oracle的数据类型对比关系
- 数据结构——队列操作
- 自动驾驶仿真:VTD自定义超声波雷达FOV
- 2021年了!!Xftp新手的下载和安装教程(超详细),以及演示了远程登录和远程文件传输
- mac+python3+selenium做pc的界面自动化测试
- 电脑版美食大战老鼠放置html,美食大战老鼠电脑版
- Fetch —— 中止尚未完成的接口请求
- Vue + Element UI 表格分页记忆选中
- 关于商业智能BI,今天只谈这五点
- 0行代码拿210万年薪,ChatGPT催生新型「程序员」岗:工作纯靠和AI聊天
热门文章
- fat32 linux 打包工具_一个方便的用于创建树莓派 SD 卡镜像的程序 | Linux 中国
- 1041. Robot Bounded In Circle
- 记conda 安装geopandas遇到的一个小错误
- ANDROID调用webservice带soapheader验证
- apache2.2:使一个目录允许执行cgi程序
- (转自ztp800201) Android - 自定义标题栏(在标题栏中增加按钮和文本居中)
- JPA基础(四):第一个JPA实例与JPA主键生成策略
- Springboot环境下mybatis配置多数据源配置
- 新代系统cnc怎样连接电脑_你真的了解3C产线上的运控系统吗?
- python步态识别算法_译 | GaitSet:将步态作为序列的交叉视角步态识别(一)