Spark shuffle:hash和sort性能对比
我们都知道Hadoop中的shuffle(不知道原理?可以参见《MapReduce:详细介绍Shuffle的执行过程》),Hadoop中的shuffle是连接map和reduce之间的桥梁,它是基于排序的。同样,在Spark中也是存在shuffle,Spark 1.1之前,Spark的shuffle只存在一种方式实现方式,也就是基于hash的。而在最新的Spark 1.1.0版本中引进了新的shuffle实现(《Spark 1.1.0正式发布》):基于sort的。
在Spark 1.1.0文档是这么说的:
Implementation to use for shuffling data. A hash-based shuffle manager is the default, but starting in Spark 1.1 there is an experimental sort-based shuffle manager that is more memory-efficient in environments with small executors, such as YARN. To use that, change this value to SORT.
从上面说明可以看出,Spark 1.1版本默认的shuffle是基于hash,不过这个版本引入了基于sort的shuffle,在一些环境下使用该shuffle实现会得到更高效的表现;在这个版本中的Shuffle实现还是处于实验阶段,不过大家可以通过spark.shuffle.manager参数进行使用。
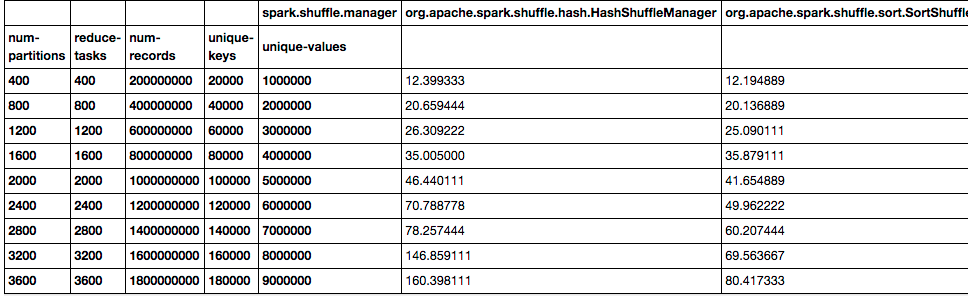
不过随着对基于hash的shuffle实现和基于sort的shuffle实现进行实验对比,如下图所示:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
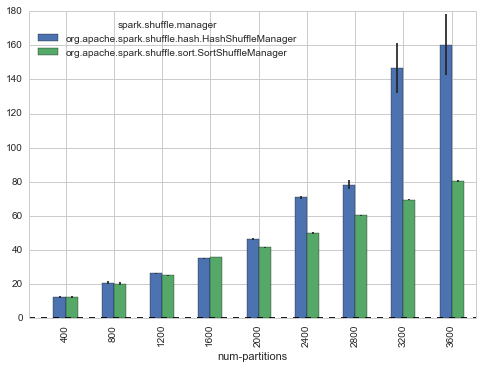
还有下面的实验:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从上面的两幅实验对比我们可以看到,随着mapper数量或者Reduce数量的增加,基于hash的shuffle实现的表现比基于sort的shuffle实现的表现越来越糟糕。
基于这个事实,在Spark 1.2版本,默认的shuffle将选用基于sort的。下面是spark 1.2文档的说明:
Implementation to use for shuffling data. There are two implementations available: sort and hash. Sort-based shuffle is more memory-efficient and is the default option starting in 1.2.
不过从源码中我们可以看出,其实如果有需要的话,完全可以实现自己的shuffle实现:
1
|
// Let the user specify short names for shuffle managers
|
2
|
val shortShuffleMgrNames = Map(
|
3
|
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
|
4
|
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
|
5
|
val shuffleMgrName = conf.get("spark.shuffle.manager", "hash")
|
6
|
val shuffleMgrClass =shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
|
7
|
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
|
上述代码我们可以看到基于Hash的shuffle其实是org.apache.spark.shuffle.hash.HashShuffleManager类,而sort的shuffle是org.apache.spark.shuffle.sort.SortShuffleManager。如果我们没有配置spark.shuffle.manager,则默认选用hash,这个大小写没有关系。如果用户配置的spark.shuffle.manager在shortShuffleMgrNames中没有查到,则选用用户自定义的Shuffle。用户自定义的Shuffle必须继承ShuffleManager类,重写里面的一些方法。
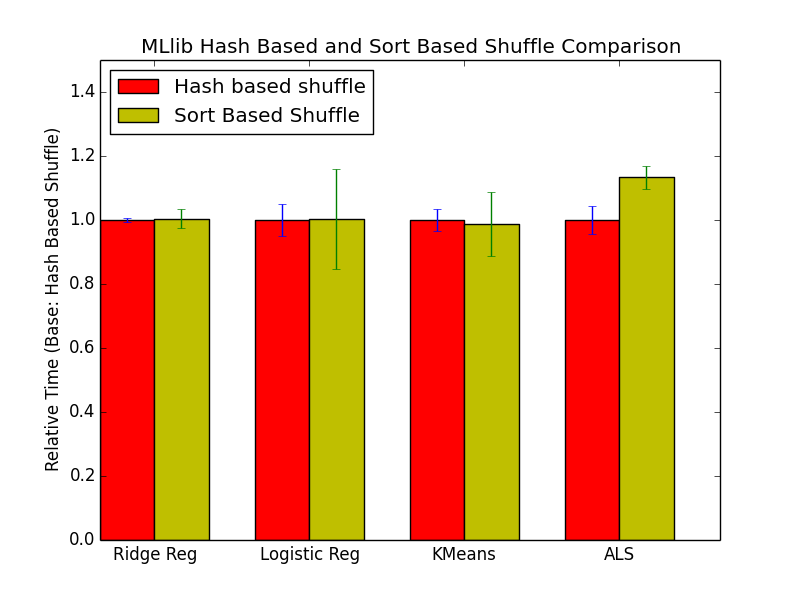
不过,也有人对MLlib中Shuffle进行了对比,实验如下结果:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从这个图可以看出,在MLlib下,基于sort的Shuffle并不一定比基于hash的Shuffle表现好,所以我们程序选择哪个Shuffle实现是需要考虑到具体的场景,如果内置的Shuffle实现不能满足自己的需求,我们完全可以自己实现一个Shuffle。
本文转自http://www.iteblog.com/archives/1138,所有权力归原作者所有。
Spark shuffle:hash和sort性能对比相关推荐
- Presto、Spark 和 Hive 即席查询性能对比
Presto.Spark 和 Hive 是三个非常流行的大数据处理框架,它们都有着各自的优缺点.在本篇博客文章中,我们将对这三个框架进行详细的对比,以便读者更好地了解它们的异同点. Presto 是一 ...
- 阿里云Spark Shuffle的优化
转自:大数据技术与架构 本次分享者:辰石,来自阿里巴巴计算平台事业部EMR团队技术专家,目前从事大数据存储以及Spark相关方面的工作. Spark Shuffle介绍 Smart Shuffle设计 ...
- spark shuffle 内幕彻底解密
一:到底什么是Shuffle? Shuffle中文翻译为"洗牌",需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节点上进行计算. 二:Shuffle可 ...
- Spark Shuffle原理解析
Spark Shuffle原理解析 一:到底什么是Shuffle? Shuffle中文翻译为"洗牌",需要Shuffle的关键性原因是某种具有共同特征的数据需要最终汇聚到一个计算节 ...
- Spark shuffle调优
Spark shuffle是什么 Shuffle在Spark中即是把父RDD中的KV对按照Key重新分区,从而得到一个新的RDD.也就是说原本同属于父RDD同一个分区的数据需要进入到子RDD的不同的分 ...
- 022 Spark shuffle过程
1.官网 http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior Spark数据进行重新分区的操作就叫做shuf ...
- java sort 效率_性能对比:collections.sort vs treeSet sort vs java8 stream.sorted
0 写在前面的话 在项目中有一个排序问题,考虑到未来需要排序的数据量可能很大,想用一个性能较好的排序算法,现在有三套解决方法:jdk提供的集合的sort方法(Collections.sort).一个可 ...
- 《Spark商业案例与性能调优实战100课》第27课:彻底解密Spark Shuffle令人费解的6大经典问题
<Spark商业案例与性能调优实战100课>第27课:彻底解密Spark Shuffle令人费解的6大经典问题
- 一文搞清楚 Spark shuffle 调优
Spark shuffle 调优 Spark 基于内存进行计算,擅长迭代计算,流式处理,但也会发生shuffle 过程.shuffle 的优化,以及避免产生 shuffle 会给程序提高更好的性能.因 ...
最新文章
- 三、数据预处理——处理分类型数据:编码与哑变量
- 为什么python发展的好_为什么Python发展这么快,有哪些优势?
- KVO(NSKeyValueObserving)、KVC(NSKeyValueCoding)作用浅谈
- C/C++ 常见误区
- java jdbc 占位符_java-jdbc
- WIN7新功能:跳转列表
- PDPS教程之工艺仿真必备软件
- Android 中文 API (29) —— CompoundButton
- fedora9的安装
- Linux安装ghostscript
- errorcode 微信分享_分享错误码
- 易语言安卓模拟器adb模块制作查看模拟器设备adb devices
- 微软Excel输入1.之后,小数点消失了
- layui弹框回车越来越黑
- Qt+sqlite 《扫雷》游戏排名功能
- 超新星计算机网络技术就业方向,超新星网络影响力榜单:林彦俊第三,蔡徐坤跌至第二,第一力压登顶...
- linux系统创建RAID0、1、10、50
- 利用计算机求解问题的核心工作就是,教材习题及答案
- 百趣代谢组学资讯:寻求多年,黄瓜品质好的秘密居然在这里
- python判断手机号码是否正确_Python:尝试检查有效的电话号码