[转]谈谈 Bias-Variance Tradeoff
https://liam0205.me/2017/03/25/bias-variance-tradeoff/
谢谢原作者!
谈谈 Bias-Variance Tradeoff
准确是两个概念。准是 bias 小,确是 variance 小。准确是相对概念,因为 bias-variance tradeoff。
——Liam Huang
在机器学习领域,人们总是希望使自己的模型尽可能准确地描述数据背后的真实规律。通俗所言的「准确」,其实就是误差小。在领域中,排除人为失误,人们一般会遇到三种误差来源:随机误差、偏差和方差。偏差和方差又与「欠拟合」及「过拟合」紧紧联系在一起。由于随机误差是不可消除的,所以此篇我们讨论在偏差和方差之间的权衡(Bias-Variance Tradeoff)。
定义
数学上定义
首先需要说明的是随机误差。随机误差是数据本身的噪音带来的,这种误差是不可避免的。一般认为随机误差服从高斯分布,记作 ϵ∼N(0,σϵ)ϵ∼N(0,σϵ)。因此,若有变量 yy 作为预测值,以及 XX 作为自变量(协变量),那么我们将数据背后的真实规律 ff 记作
偏差和方差则需要在统计上做对应的定义。
- 偏差(bias)描述的是通过学习拟合出来的结果之期望,与真实规律之间的差距,记作 Bias(X)=E[f^(X)]−f(X)Bias(X)=E[f^(X)]−f(X)。
- 方差(variance)即是统计学中的定义,描述的是通过学习拟合出来的结果自身的不稳定性,记作 Var(X)=E[f^(X)−E[f^(X)]]Var(X)=E[f^(X)−E[f^(X)]]。
以均方误差为例,有如下推论
直观的图示
下图将机器学习任务描述为一个「打靶」的活动:根据相同算法、不同数据集训练出的模型,对同一个样本进行预测;每个模型作出的预测相当于是一次打靶。
http://scott.fortmann-roe.com/docs/BiasVariance.html

左上角的示例是理想状况:偏差和方差都非常小。如果有无穷的训练数据,以及完美的模型算法,我们是有办法达成这样的情况的。然而,现实中的工程问题,通常数据量是有限的,而模型也是不完美的。因此,这只是一个理想状况。
右上角的示例表示偏差小而方差大。靶纸上的落点都集中分布在红心周围,它们的期望落在红心之内,因此偏差较小。另外一方面,落点虽然集中在红心周围,但是比较分散,这是方差大的表现。
左下角的示例表示偏差大二方差小。显而易见,靶纸上的落点非常集中,说明方差小。但是落点集中的位置距离红心很远,这是偏差大的表现。
右下角的示例则是最糟糕的情况,偏差和方差都非常大。这是我们最不希望看到的结果。
举个栗子
现在我们做一个模拟实验,用以说明至此介绍的内容。
首先,我们生成了两组 array,分别作为训练集和验证集。这里,x 与 y 是接近线性相关的,而在 y 上加入了随机噪声,用以模拟真实问题中的情况。
12345678910111213 |
import numpy as npnp.random.seed(42) # the answer to life, the universe and everythingreal = lambda x:x + x ** 0.1 x_train = np.linspace(0, 15, 100)y_train = map(real, x_train)y_noise = 2 * np.random.normal(size = x_train.size)y_train = y_train + y_noise x_valid = np.linspace(0, 15, 50)y_valid = map(real, x_valid)y_noise = 2 * np.random.normal(size = x_valid.size)y_valid = y_valid + y_noise |
现在,我们选用最小平方误差作为损失函数,尝试用多项式函数去拟合这些数据。
1234 |
prop = np.polyfit(x_train, y_train, 1)prop_ = np.poly1d(prop)overf = np.polyfit(x_train, y_train, 15)overf_ = np.poly1d(overf) |
这里,对于 prop,我们采用了一阶的多项式函数(线性模型)去拟合数据;对于 overf,我们采用了 15 阶的多项式函数(多项式模型)去拟合数据。如此,我们可以把拟合效果绘制成图。
12345678910111213141516171819202122232425 |
import matplotlib.pyplot as plt
_ = plt.figure(figsize = (14, 6))
plt.subplot(1, 2, 1)prop_e = np.mean((y_train - np.polyval(prop, x_train)) ** 2)overf_e = np.mean((y_train - np.polyval(overf, x_train)) ** 2)xp = np.linspace(-2, 17, 200)plt.plot(x_train, y_train, '.')plt.plot(xp, prop_(xp), '-', label = 'proper, err: %.3f' % (prop_e))plt.plot(xp, overf_(xp), '--', label = 'overfit, err: %.3f' % (overf_e))plt.ylim(-5, 20)plt.legend()plt.title('train set')
plt.subplot(1, 2, 2)prop_e = np.mean((y_valid - np.polyval(prop, x_valid)) ** 2)overf_e = np.mean((y_valid - np.polyval(overf, x_valid)) ** 2)xp = np.linspace(-2, 17, 200)plt.plot(x_valid, y_valid, '.')plt.plot(xp, prop_(xp), '-', label = 'proper, err: %.3f' % (prop_e))plt.plot(xp, overf_(xp), '--', label = 'overfit, err: %.3f' % (overf_e))plt.ylim(-5, 20)plt.legend()plt.title('validation set')
|
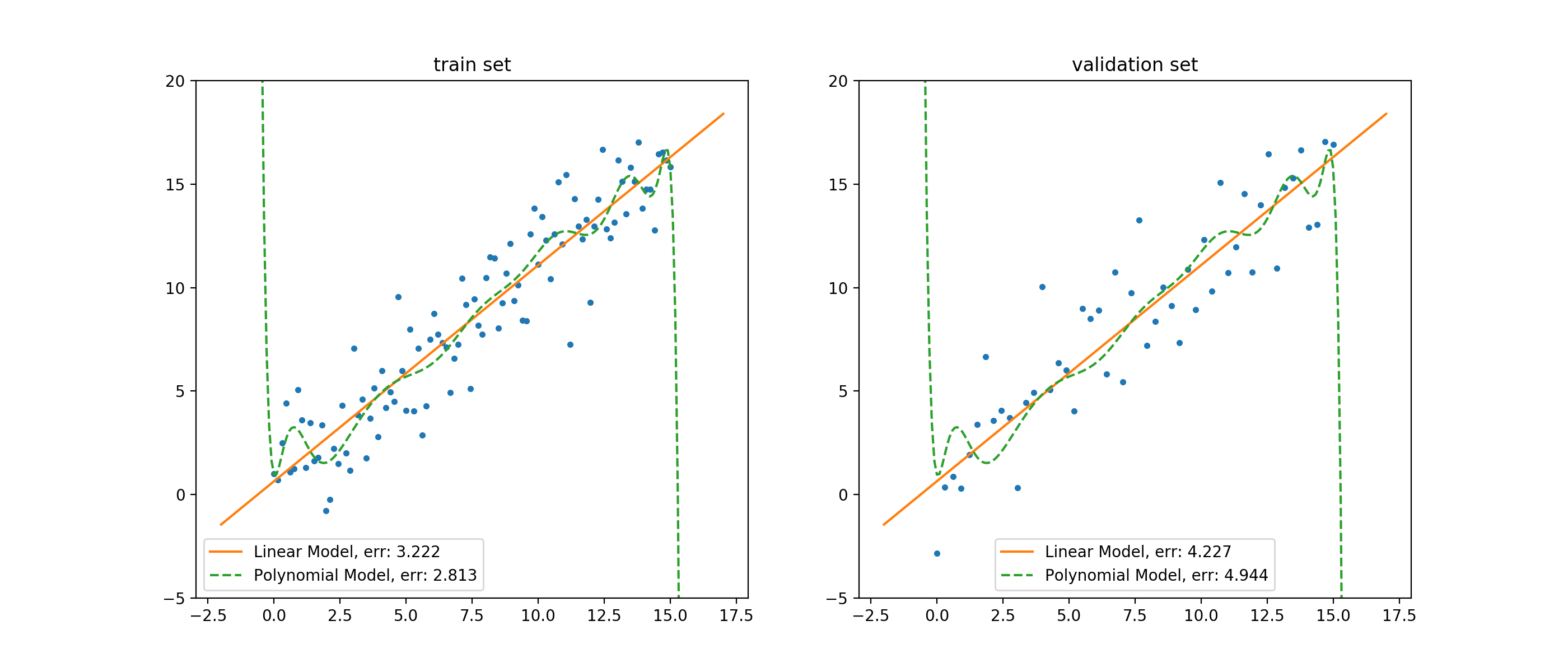
以训练集上的结果来说,线性模型的误差要明显高于多项式模型。站在人类观察者的角度来说,这似乎是显而易见的:数据是围绕一个近似线性的函数附近抖动的,那么用简单的线性模型,自然就无法准确地拟合数据;但是,高阶的多项式函数可以进行各种「扭曲」,以便将训练集的数据拟合得更好。
这种情况,我们说线性模型在训练集上欠拟合(underfitting),并且它的偏差(bias)要高于多项式模型的偏差。
但这并不意味着线性模型在这个问题里,要弱于多项式模型。我们看到,在验证集上,线性模型的误差要小于多项式模型的误差。并且,线性模型在训练集和验证集上的误差相对接近,而多项式模型在两个数据集上的误差,差距就很大了。
这种情况,我们说多项式模型在训练集上过拟合(overfitting),并且它的方差(variance)要高于线性模型的偏差。此外,因为线性模型在两个集合上的误差较为接近,因此我们说线性模型在训练过程中未见的数据上,泛化能力更好。因为,在真实情况下,我们都需要使用有限的训练集去拟合模型,而后工作在无限的真实样本中,而这些真实样本对于模型训练过程都是不可见的。所以,模型的泛化能力,是非常重要的指标。
考虑到两个模型在验证集上的表现,在这个任务上,我们说线性模型表现得较好。
权衡之术
克服 OCD
对于很多人来说,不可避免地会有这样的强迫症:希望训练误差降至 0。
我们说,人想要过得快乐,首先要接纳自己,与自己和解。做机器学习相关的任务也是一样,首先要理解和接受机器学习的基本规律,克服自己的强迫症。
首先,对于误差,在公式 11 中,我们得知误差中至少有「随机误差」是无论如何不可避免的。因此,哪怕有一个模型在训练集上的表现非常优秀,它的误差是 0,这也不能说明这个模型完美无缺。因为,训练集本身存在的误差,将会被带入到模型之中;也就是说,这个模型天然地就和真实情况存在误差,于是它不是完美的。
其次,由于训练样本无法完美地反应真实情况(样本容量有限、抽样不均匀),以及由于模型本身的学习能力存在上限,也意味着我们的模型不可能是完美的。
因此,我们需要克服强迫症,不去追求训练误差为 0;转而去追求在给定数据集和模型算法的前提下的,逼近最优结果。
最佳平衡点的数学表述
在实际应用中,我们做模型选择的一般方法是:
- 选定一个算法;
- 调整算法的超参数;
- 以某种指标选择最合适的超参数组合。
也就是说,在整个过程中,我们固定训练样本,改变模型的描述能力(模型复杂度)。不难理解,随着模型复杂度的增加,其描述能力也就会增加;此时,模型在验证集上的表现,偏差会倾向于减小而方差会倾向于增大。而在相反方向,随着模型复杂度的降低,其描述能力也就会降低;此时,模型在验证集上的表现,偏差会倾向于增大而方差会倾向于减小。
考虑到,模型误差是偏差与方差的加和,因此我们可以绘制出这样的图像。
http://scott.fortmann-roe.com/docs/BiasVariance.html
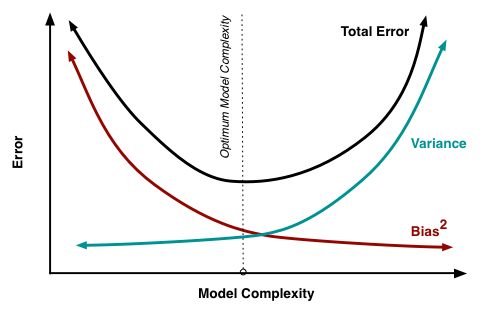
图中的最有位置,实际上是 total error 曲线的拐点。我们知道,连续函数的拐点意味着此处一阶导数的值为 0。考虑到 total error 是偏差与方差的加和,所以我们有,在拐点处:
公式 22 给出了寻找最优平衡点的数学描述。若模型复杂度大于平衡点,则模型的方差会偏高,模型倾向于过拟合;若模型复杂度小于平衡点,则模型的偏差会偏高,模型倾向于过拟合。
过拟合与欠拟合的外在表现
尽管有了上述数学表述,但是在现实环境中,有时候我们很难计算模型的偏差与方差。因此,我们需要通过外在表现,判断模型的拟合状态:是欠拟合还是过拟合。
同样地,在有限的训练数据集中,不断增加模型的复杂度,意味着模型会尽可能多地降低在训练集上的误差。因此,在训练集上,不断增加模型的复杂度,训练集上的误差会一直下降。
因此,我们可以绘制出这样的图像。
http://www.learnopencv.com/bias-variance-tradeoff-in-machine-learning/
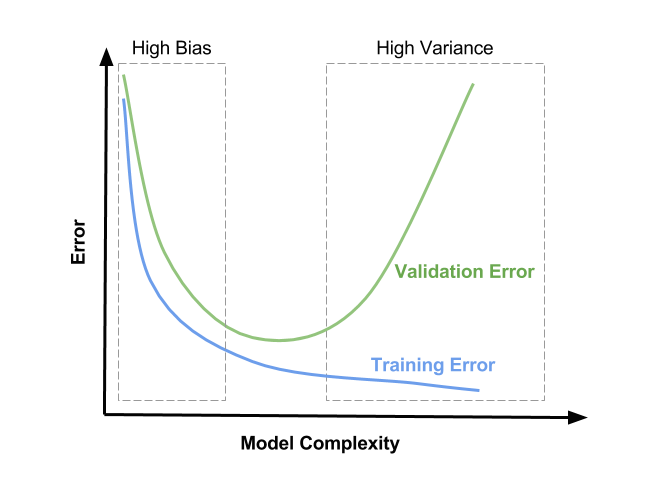
因此,
- 当模型处于欠拟合状态时,训练集和验证集上的误差都很高;
- 当模型处于过拟合状态时,训练集上的误差低,而验证集上的误差会非常高。
处理欠拟合与过拟合
有了这些分析,我们就能比较容易地判断模型所处的拟合状态。接下来,我们就可以参考 Andrew Ng 博士提供的处理模型欠拟合/过拟合的一般方法了。
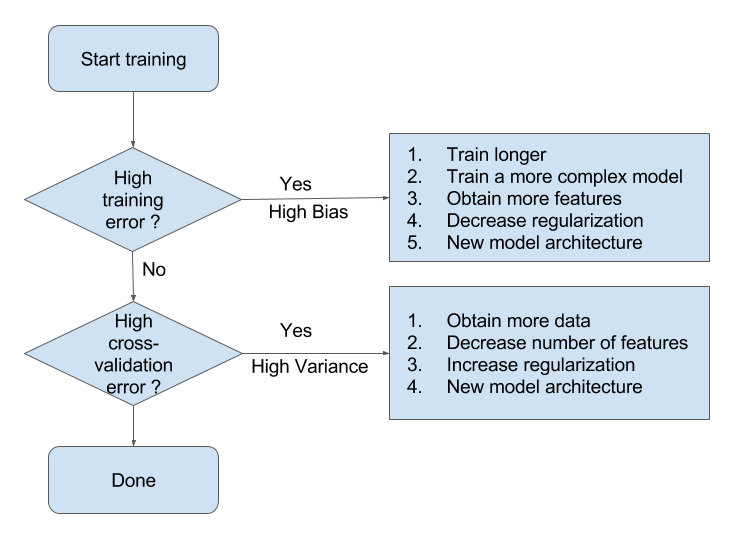
欠拟合
当模型处于欠拟合状态时,根本的办法是增加模型复杂度。我们一般有以下一些办法:
- 增加模型的迭代次数;
- 更换描述能力更强的模型;
- 生成更多特征供训练使用;
- 降低正则化水平。
过拟合
当模型处于过拟合状态时,根本的办法是降低模型复杂度。我们则有以下一些武器:
- 扩增训练集;
- 减少训练使用的特征的数量;
- 提高正则化水平。
转载于:https://www.cnblogs.com/freebird92/p/8144557.html
[转]谈谈 Bias-Variance Tradeoff相关推荐
- Bias/variance tradeoff
Bias/variance tradeoff 线性回归中有欠拟合与过拟合,例如下图: 则会形成欠拟合, 则会形成过拟合. 尽管五次多项式会精确的预测训练集中的样本点,但在预测训练集中没有的数据,则不能 ...
- 统计视角下的Bias Variance Tradeoff 和它在KNN模型中的体现
统计视角下的Bias Variance Tradeoff 和它在KNN模型中的体现 前言 一.Bias Variance Tradeoff 1. 真实数据分布和取样的假设 2. 统计理论中的Bias和 ...
- A detailed derivation for the Bias Variance tradeoff Decomposition
Introduction 在 ESL和 ISLR中,都给出了对于 bias和 variance的讨论,并给出这样的结论: Err(X)=Var(f^(X))+Bias(f^(X))2+Var(ϵ)Er ...
- Bias Variance Tradeoff
统计学习中有一个重要概念叫做residual sum-of-squares RSS看起来是一个非常合理的统计模型优化目标.但是考虑k-NN的例子,在最近邻的情况下(k=1),RSS=0,是不是k-NN ...
- 偏见方差的权衡(Bias Variance Tradeoff)
统计学习中有一个重要概念叫做residual sum-of-squares RSS看起来是一个非常合理的统计模型优化目标.但是考虑k-NN的例子,在最近邻的情况下(k=1),RSS=0,是不是
- DL中的Bias Variance
Bias Variance Trade-off Prediction Error motivation bias variance comparison derivation Analysis los ...
- AI学习笔记——Bias and Variance tradeoff (方差偏差的平衡)
上一篇文章介绍了机器学习中需要理解的几个重要概念,这些概念在训练模型的过程中至关重要,尤其是Bias 和 Variance 的分析,关系到在机器学习的过程的实际操作中,如何优化训练模型. 1.Bias ...
- Machine Learning第六周笔记一:评估学习算法和bias/variance
博客已经迁移到Marcovaldo's bolg (http://marcovaldong.github.io/) 入坑机器学习近一个月,学习资料主要是李航的<统计学习方法>.Peter ...
- 机器学习笔记:误差的来源(bias variance)
1 bias & variance 简单的模型--bias大,variance小 复杂的模型--bias小,variance大 2 variance 3 bias 黑线--实际的曲线 蓝线-- ...
- Bias - Variance Decomposition
偏差-方差分解定理 解释了训练的数据和调控因子lamda(惩罚项里的)的作用 因为机器学习的真实目标是期望风险最小化(Expected Generalization Loss),其可以分解为三个部分 ...
最新文章
- 「SAP技术」A项目关联公司间退货STO流程
- SQL语言学习(五)流程控制函数学习
- 计算机网络基础(缩短版)
- 《Redis官方文档》Redis调试指南
- HEML、CSS、Javascript基础知识总结
- zookeeper 3.6.0安装以及基本使用
- 两平面平行但不重合的条件是_____2012江苏省数学竞赛《提优教程》教案:第77讲_组合几何...
- usb打印机linux识别不了怎么办,打印机usb连接电脑无法识别怎么办_打印机usb插上无响应怎么办-win7之家...
- 帝国cms忘记后台帐号密码的处理方法
- python 数字运算及格式化_Python基础教程(3)Python数据类型、运算与格式化
- 父进程回收子进程之wait()函数使用解读
- Homekit智能家居DIY一智能插座
- 在word中输入各种公式
- 基于DE2的开源片上系统Freedom E310移植
- CSS3选择器--结构性伪类选择器
- 新式单片机视频教程下载
- 华硕飞行堡垒7开启虚拟化
- 985本科大二,计算机专业,为什么很多普通一本甚至二本三本的都比自己懂得多?
- 江南大学计算机水平怎么样,江南大学在211中什么水平?无锡人眼中的江南大学怎么样?...
- 探花交友_第12章_实现推荐系统(新版)