使用实体框架核心和C#创建具有Dotnet核心的自定义Web爬虫程序
目录
介绍
背景
爬虫的基础知识
一步一步开发DotnetCrawler
eShopOnWeb Microsoft 项目使用示例
Visual Studio解决方案的项目结构
DotnetCrawler.Core
DotnetCrawler.Data
DotnetCrawler.Downloader
DotnetCrawler.Processor
DotnetCrawler.Pipeline
DotnetCrawler.Scheduler
DotnetCrawler.Sample
结论
- 您可以在这里找到GitHub存储库:DotnetCrawler
介绍
在本文中,我们将实现一个自定义Web爬虫,并在eBay电子商务网站上使用此爬虫,该网站正在抓取eBay iphone页面并使用Entity Framework Core在我们的SQL Server数据库中插入此记录。一个示例数据库模式将是Microsoft eShopWeb应用程序,我们将eBay记录插入Catalog表中。
背景
大多数Web抓取和Web爬网程序框架存在于不同的基础结构中。但是当涉及到dotnet环境时,你没有这样的选择,你无法找到适合你的自定义要求的工具。
在开始开发新的爬虫之前,我正在搜索下面列出的用C#编写的工具:
- Abot是一个很好的爬虫,但如果你需要实现一些自定义的东西,它没有免费的支持,也没有足够的文档。
- DotnetSpider拥有非常好的设计,其架构使用与Scrapy和WebMagic等最常用的爬虫相同的架构。但是文档是中文的,所以即使我用Google翻译将其翻译成英文,也很难学会如何实现自定义方案。此外,我想将爬虫输出插入到SQL Server数据库,但它无法正常工作,我在GitHub上打开了一个问题,但还没有人回复。
我没有其他选择在有限的时间内解决我的问题。我不想花更多的时间来研究更多的爬虫基础设施。我决定编写自己的工具。
爬虫的基础知识
搜索大量存储库让我有了创建新存储库的想法。因此,爬虫架构的主要模块几乎是相同的,所有这些模块全部都是爬虫生态的大蓝图,您可以在下面看到:
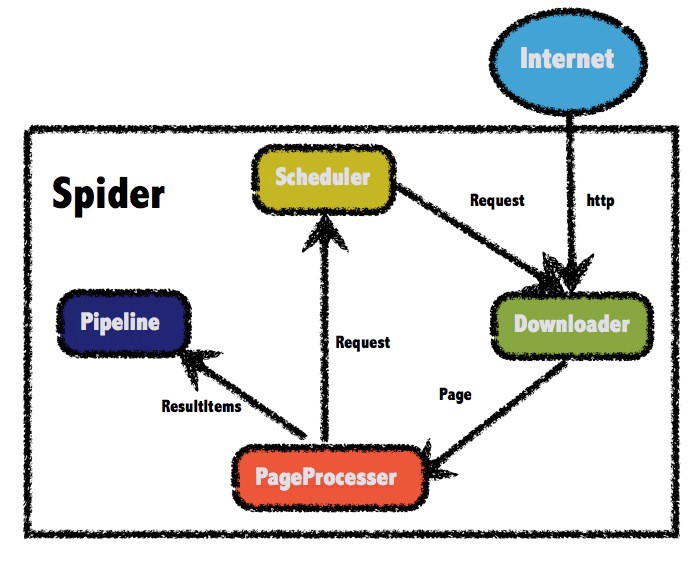
Crawler的主要模块
此图显示了应包含在常见爬网程序项目中的主要模块。因此,我在Visual Studio解决方案下将这些模块添加为单独的项目。
下面列出了这些模块的基本说明:
- Downloader; 负责下载给定的URL到本地文件夹或临时文件并返回到htmlnode处理器的对象。
- Processors; 负责处理给定的HTML节点,提取和查找预期的特定节点,使用这些处理过的数据加载实体。并将此处理器返回管道。
- Pipelines; 负责将实体导出到使用应用程序的不同数据库。
- Scheduler; 负责调度爬虫命令以提供友好的抓取操作。
一步一步开发DotnetCrawler
根据上述模块,我们如何使用Crawler类?让我们试着想象一下,然后一起实现。
static async Task MainAsync(string[] args)
{var crawler = new DotnetCrawler<Catalog>().AddRequest(new DotnetCrawlerRequest { Url = "https://www.ebay.com/b/Apple-iPhone/9355/bn_319682", Regex = @".*itm/.+", TimeOut = 5000 }).AddDownloader(new DotnetCrawlerDownloader { DownloderType = DotnetCrawlerDownloaderType.FromMemory, DownloadPath = @"C:\DotnetCrawlercrawler\" }).AddProcessor(new DotnetCrawlerProcessor<Catalog> { }).AddPipeline(new DotnetCrawlerPipeline<Catalog> { });await crawler.Crawle();
}如您所见,DotnetCrawler<TEntity>类具有泛型实体类型,该类型将用作DTO对象并保存数据库。Catalog是一个泛型类型,DotnetCrawler也是由DotnetCrawler.Data项目中的EF.Core scaffolding命令生成的。这个我们稍后会看到。
DotnetCrawler对象通过使用Builder Design Pattern配置为了加载它们的配置。此外,这种技术命名为流畅的设计。
DotnetCrawler 使用以下方法配置:
- AddRequest; 这包括crawler目标的主要网址。此外,我们可以为目标网址定义过滤器,旨在集中目标部分。
- AddDownloader; 这包括下载程序类型,如果下载类型为“ FromFile”,则表示下载到本地文件夹,然后还需要下载文件夹的路径。其他选项是“ FromMemory”和“ FromWeb”,它们都下载目标网址但不保存。
- AddProcessor; 此方法加载新的默认处理器,它基本上提供了提取HTML页面和定位一些HTML标记。由于可扩展的设计,您可以创建自己的处理器。
- AddPipeline; 此方法加载新的默认管道,其基本上提供将实体保存到数据库中。当前管道提供使用Entity Framework Core连接SqlServer。由于可扩展的设计,您可以创建自己的管道。
所有这些配置都应存储在主类中; DotnetCrawler.cs。
public class DotnetCrawler<TEntity> : IDotnetCrawler where TEntity : class, IEntity{public IDotnetCrawlerRequest Request { get; private set; }public IDotnetCrawlerDownloader Downloader { get; private set; }public IDotnetCrawlerProcessor<TEntity> Processor { get; private set; }public IDotnetCrawlerScheduler Scheduler { get; private set; }public IDotnetCrawlerPipeline<TEntity> Pipeline { get; private set; }public DotnetCrawler(){}public DotnetCrawler<TEntity> AddRequest(IDotnetCrawlerRequest request){Request = request;return this;}public DotnetCrawler<TEntity> AddDownloader(IDotnetCrawlerDownloader downloader){Downloader = downloader;return this;}public DotnetCrawler<TEntity> AddProcessor(IDotnetCrawlerProcessor<TEntity> processor){Processor = processor;return this;}public DotnetCrawler<TEntity> AddScheduler(IDotnetCrawlerScheduler scheduler){Scheduler = scheduler;return this;}public DotnetCrawler<TEntity> AddPipeline(IDotnetCrawlerPipeline<TEntity> pipeline){Pipeline = pipeline;return this;} }据此,在完成必要的配置之后,异步触发crawler.Crawle ()方法。此方法通过分别导航到下一个模块,从而完成其操作。
eShopOnWeb Microsoft 项目使用示例
该库还包括名称为DotnetCrawler.Sample的示例项目。基本上,在这个示例项目中,实现了Microsoft eShopOnWeb存储库。你可以在这里找到这个存储库。在这个示例存储库中实现了电子商务项目,当您使用EF.Core 代码优先方法生成时,它具有“Catalog”表。因此,在使用爬虫之前,您应该使用真实数据库下载并运行此项目。要执行此操作,请参阅此信息。(如果您已有数据库,则可以继续使用数据库。)
我们在DotnetCrawler类中将“Catalog”表作为泛型类型传递。
var crawler = new DotnetCrawler<Catalog>()Catalog是一个DotnetCrawler的泛型类型,也是由DotnetCrawler.Data项目中的EF.Core scaffolding命令生成的。DotnetCrawler.Data项目安装EF.Core nuget 包。在运行此命令之前,.Data项目应下载以下nuget包。
运行EF命令所需的包
现在,我们的软件包已准备就绪,可以在软件包管理器控制台中运行EF命令并选择DotnetCrawler.Data项目。
Scaffold-DbContext "Server=(localdb)\mssqllocaldb;Database=Microsoft.eShopOnWeb.CatalogDb;
Trusted_Connection=True;" Microsoft.EntityFrameworkCore.SqlServer -OutputDir Models通过此命令DotnetCrawler.Data项目创建了Model文件夹。此文件夹包含从eShopOnWeb Microsoft的示例生成的所有实体和上下文对象。
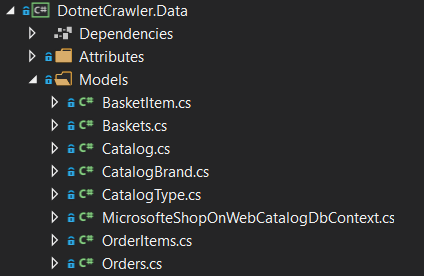
eShopOnWeb实体
之后,您需要使用自定义爬虫属性配置您的实体类,以便从eBay iphone的网页了解爬虫蜘蛛和加载实体字段;
[DotnetCrawlerEntity(XPath = "//*[@id='LeftSummaryPanel']/div[1]")]
public partial class Catalog : IEntity
{public int Id { get; set; }[DotnetCrawlerField(Expression = "1", SelectorType = SelectorType.FixedValue)]public int CatalogBrandId { get; set; }[DotnetCrawlerField(Expression = "1", SelectorType = SelectorType.FixedValue)]public int CatalogTypeId { get; set; } public string Description { get; set; }[DotnetCrawlerField(Expression = "//*[@id='itemTitle']/text()", SelectorType = SelectorType.XPath)]public string Name { get; set; }public string PictureUri { get; set; }public decimal Price { get; set; }public virtual CatalogBrand CatalogBrand { get; set; }public virtual CatalogType CatalogType { get; set; }
}使用此代码,基本上,crawler请求给定url并尝试查找为目标Web url定义xpath地址的给定属性。
在这些定义之后,最后我们能够运行crawler.Crawle()异步方法。在该方法中,它分别执行以下操作。
- 它访问给定的请求对象中的url并查找其中的链接。如果Regex的属性值已满,则会相应地应用过滤。
- 它在互联网上找到这些网址,并通过应用不同的方法下载。
- 处理下载的网页以产生所需数据。
- 最后,这些数据将使用EF.Core保存到数据库中。
public async Task Crawle()
{
var linkReader = new DotnetCrawlerPageLinkReader(Request);
var links = await linkReader.GetLinks(Request.Url, 0);foreach (var url in links)
{
var document = await Downloader.Download(url);
var entity = await Processor.Process(document);
await Pipeline.Run(entity);
}
}Visual Studio解决方案的项目结构
因此,您可以从使用空白解决方案在Visual Studio上创建新项目开始。之后,您可以添加.NET核心类库项目,如下图所示:
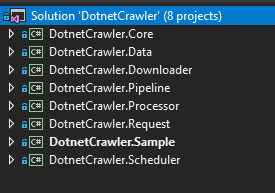
只有示例项目才是.NET Core控制台应用程序。我将逐一解释此解决方案中的所有项目。
DotnetCrawler.Core
该项目包括主要的爬虫类。它只有一个定义Crawle方法的interface和interface的实现。因此,您可以在此项目上创建自定义爬网程序。
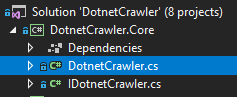
DotnetCrawler.Data
该项目包括Attributes,Models和Repository文件夹。我们应该深入研究这些文件夹。
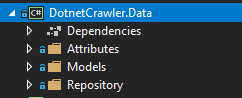
- Models文件夹; 应包括由Entity Framework Core生成的Entity类。因此,您应该将数据库表实体放在此文件夹中,此文件夹也应该是Entity Framework Core的Context对象。现在这个文件夹有eShopOnWeb微软的数据库示例。
- Attributes文件夹; 包括爬虫程序特性,用于获取有关已爬网页的xpath信息。有两个类,DotnetCrawlerEntityAttribute.cs用于实体特性,DotnetCrawlerFieldAttribute.cs用于属性特性。这些特性应该在EF.Core实体类上。您可以在下面的代码块中看到特性的示例用法:
[DotnetCrawlerEntity(XPath = "//*[@id='LeftSummaryPanel']/div[1]")]
public partial class Catalog : IEntity
{
public int Id { get; set; }
[DotnetCrawlerField(Expression = "//*[@id='itemTitle']/text()", SelectorType = SelectorType.XPath)]
public string Name { get; set; }
}第一个xpath用于在开始抓取时定位该HTML节点。第二个用于获取特定HTML节点中的真实数据信息。在此示例中,此路径从eBay检索iphone名称。
- Repository文件夹; 包括EF.Core实体和数据库上下文的存储库设计模式实现。我用这个资源的存储库模式。为了使用存储库模式,我们必须为所有EF.Core实体申请IEntity interface。您可以看到上述代码,Catalog类实现了IEntity interface。所以爬虫的泛型类型应该从IEntity中实现。
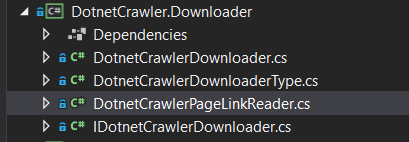
DotnetCrawler.Downloader
该项目包括主要爬虫类中的下载算法。根据下载程序DownloadType可以应用不同类型的下载方法。此外,您可以在此处开发自己的自定义下载程序,以实现您的要求。为了提供这些下载功能,这个项目应该加载HtmlAgilityPack和HtmlAgilityPack.CssSelector.NetCore包;

下载方法的主要功能是在DotnetCrawlerDownloader.cs中——DownloadInternal()方法:
private async Task<HtmlDocument> DownloadInternal(string crawlUrl)
{switch (DownloderType){case DotnetCrawlerDownloaderType.FromFile:using (WebClient client = new WebClient()){await client.DownloadFileTaskAsync(crawlUrl, _localFilePath);}return GetExistingFile(_localFilePath);case DotnetCrawlerDownloaderType.FromMemory:var htmlDocument = new HtmlDocument();using (WebClient client = new WebClient()){string htmlCode = await client.DownloadStringTaskAsync(crawlUrl);htmlDocument.LoadHtml(htmlCode);}return htmlDocument;case DotnetCrawlerDownloaderType.FromWeb:HtmlWeb web = new HtmlWeb();return await web.LoadFromWebAsync(crawlUrl);}throw new InvalidOperationException("Can not load html file from given source.");
}此方法根据下载类型下载目标网址; 下载本地文件,下载临时文件或不直接从网上下载。
此外,爬虫的主要功能之一是页面访问算法。所以在这个项目中,在DotnetCrawlerPageLinkReader.cs类中应用页面访问算法和递归方法。您可以通过给出depth参数来使用此页面访问算法。我正在使用此资源来解决此问题。
public class DotnetCrawlerPageLinkReader
{private readonly IDotnetCrawlerRequest _request;private readonly Regex _regex;public DotnetCrawlerPageLinkReader(IDotnetCrawlerRequest request){_request = request;if (!string.IsNullOrWhiteSpace(request.Regex)){_regex = new Regex(request.Regex);}}public async Task<IEnumerable<string>> GetLinks(string url, int level = 0){if (level < 0)throw new ArgumentOutOfRangeException(nameof(level));var rootUrls = await GetPageLinks(url, false);if (level == 0)return rootUrls;var links = await GetAllPagesLinks(rootUrls);--level;var tasks = await Task.WhenAll(links.Select(link => GetLinks(link, level)));return tasks.SelectMany(l => l);}private async Task<IEnumerable<string>> GetPageLinks(string url, bool needMatch = true){try{HtmlWeb web = new HtmlWeb();var htmlDocument = await web.LoadFromWebAsync(url);var linkList = htmlDocument.DocumentNode.Descendants("a").Select(a => a.GetAttributeValue("href", null)).Where(u => !string.IsNullOrEmpty(u)).Distinct();if (_regex != null)linkList = linkList.Where(x => _regex.IsMatch(x));return linkList;}catch (Exception exception){return Enumerable.Empty<string>();}}private async Task<IEnumerable<string>> GetAllPagesLinks(IEnumerable<string> rootUrls){var result = await Task.WhenAll(rootUrls.Select(url => GetPageLinks(url)));return result.SelectMany(x => x).Distinct();}
}DotnetCrawler.Processor
该项目提供将下载的Web数据数据转换为EF.Core实体。此需求通过使用反射来解决泛型类型的 get或set成员。在DotnetCrawlerProcessor.cs类中,实现crawler的当前处理器。此外,您可以在此处开发自己的自定义处理器,以实现您的要求。
public class DotnetCrawlerProcessor<TEntity> : IDotnetCrawlerProcessor<TEntity> where TEntity : class, IEntity
{public async Task<IEnumerable<TEntity>> Process(HtmlDocument document){var nameValueDictionary = GetColumnNameValuePairsFromHtml(document);var processorEntity = ReflectionHelper.CreateNewEntity<TEntity>();foreach (var pair in nameValueDictionary){ReflectionHelper.TrySetProperty(processorEntity, pair.Key, pair.Value);}return new List<TEntity>{processorEntity as TEntity};}private static Dictionary<string, object> GetColumnNameValuePairsFromHtml(HtmlDocument document){var columnNameValueDictionary = new Dictionary<string, object>();var entityExpression = ReflectionHelper.GetEntityExpression<TEntity>();var propertyExpressions = ReflectionHelper.GetPropertyAttributes<TEntity>();var entityNode = document.DocumentNode.SelectSingleNode(entityExpression);foreach (var expression in propertyExpressions){var columnName = expression.Key;object columnValue = null;var fieldExpression = expression.Value.Item2;switch (expression.Value.Item1){case SelectorType.XPath:var node = entityNode.SelectSingleNode(fieldExpression);if (node != null)columnValue = node.InnerText;break;case SelectorType.CssSelector:var nodeCss = entityNode.QuerySelector(fieldExpression);if (nodeCss != null)columnValue = nodeCss.InnerText;break;case SelectorType.FixedValue:if (Int32.TryParse(fieldExpression, out var result)){columnValue = result;}break;default:break;}columnNameValueDictionary.Add(columnName, columnValue);}return columnNameValueDictionary;}
}DotnetCrawler.Pipeline
该项目为处理器模块中的给定实体对象提供insert数据库。使用EF.Core对象关系映射框架插入数据库。在DotnetCrawlerPipeline.cs类中实现了当前的crawler管道。您也可以在此处开发自己的自定义管道,以实现您的要求。(不同数据库类型的持久性)。
public class DotnetCrawlerPipeline<TEntity> : IDotnetCrawlerPipeline<TEntity> where TEntity : class, IEntity
{private readonly IGenericRepository<TEntity> _repository;public DotnetCrawlerPipeline(){_repository = new GenericRepository<TEntity>();}public async Task Run(IEnumerable<TEntity> entityList){foreach (var entity in entityList){await _repository.CreateAsync(entity);}}
}DotnetCrawler.Scheduler
此项目为爬网程序的爬取操作提供调度作业。此需求未实现默认解决方案,因此您可以在此处开发自己的自定义处理器以实现您的要求。您可以使用Quartz或Hangfire进行后台作业。
DotnetCrawler.Sample
该项目证明了使用DotnetCrawler从eBay电子商务网站插入新的iPhone到Catalog表中 。因此,您可以将启动项目设置为DotnetCrawler.Sample并调试我们在本文上面部分中解释的模块。

Catalog 表列表,Crawler插入的最后10条记录
结论
该库的设计与其他强大的爬虫库(如WebMagic和Scrapy)一样, 但是建立在体系结构之上,通过应用域驱动设计和面向对象原则等最佳实践,重点关注其易扩展性。因此,您可以轻松实现自定义需求,并使用这个简单、轻量级的Web爬行/抓取库的默认功能,以实现基于dotnet核心的Entity Framework Core输出。
- GitHub:源代码
原文地址:https://www.codeproject.com/Articles/1278217/Creating-Custom-Web-Crawler-with-Dotnet-Core-using
使用实体框架核心和C#创建具有Dotnet核心的自定义Web爬虫程序相关推荐
- 使用Angular 2, ASP。NET Core 1.1和实体框架核心(第1部分)
介绍 这是本系列的第一部分.在本系列中,我们将使用Angular 2.Asp创建一个SPA应用程序.Net Core 1.1和实体框架核心.这里我们使用Angular 2作为应用程序的UI,使用Asp ...
- ADO.NET Entity Framework如何:通过每种类型一个表继承以定义模型(实体框架)
本主题介绍如何手动创建具有每种类型一个表继承层次结构的概念模型.每种类型一个表继承使用数据库中单独的表为继承层次结构中的每种类型维护非继承属性和键属性的数据. 说明: 建议使用 ADO.NET 实体数 ...
- 如何创建PDF发票Web应用程序
目录 构建Web应用程序以创建和发送PDF发票 先决条件 创建新的Express应用程序 创建发票路由 添加视图和样式 使用Foxit生成PDF 使用Nodemailer发送电子邮件 结论 获得报酬是 ...
- 2022年8月10日:使用 ASP.NET Core 为初学者构建 Web 应用程序--使用 ASP.NET Core 创建 Web UI(没看懂需要再看一遍)
ASP.NET Core 支持使用名为 Razor 的本地模板化引擎创建网页. 本模块介绍了如何使用 Razor 和 ASP.NET Core 创建网页. 简介 通过在首选终端中运行以下命令,确保已安 ...
- 使用实体框架核心创建简单的审计跟踪
目录 介绍 背景 审核日志数据 审核表实体 审核类型 审计Db上下文 审核表配置 数据更改到审核表 实体更改为审核表实体 所有实体更改为审计表 在现有的DbContext中使用审核跟踪 创建DbCon ...
- 带有审计表的实体框架核心(EF Core)
目录 介绍 背景 使用代码 主(Main)方法 运行程序 IAudited Model1.cs Model1.Partial.cs 部分类CUsers TVUT类 局部类Model1 OnModelC ...
- 实体框架高级应用之动态过滤 EntityFramework DynamicFilters
实体框架高级应用之动态过滤 EntityFramework DynamicFilters 实体框架高级应用之动态过滤 EntityFramework DynamicFilters 我们开门见山,直奔主 ...
- 【SSM框架系列】Mybatis映射配置文件与核心配置文件深入
传统开发方式Dao层实现 编写UserDao接口 public interface UserDao {List<User> findAll() throws IOException;} 编 ...
- 使用 ASP.NET Core Razor 页、Web API 和实体框架进行分页和排序
目录 核心类 数据层 The API Razor页面 如何使用 .NET Core Razor 页.Web API 和实体框架实现分页和排序,以产生良好的性能. 该项目的特点是: 选择页面大小(Pag ...
最新文章
- 《需求工程-软件建模与分析之读书笔记之三》
- 解决‘tf.ResizeNearestNeighbor‘ op is neither a custom op nor a flex op
- 月薪2万程序员面试,被HR直面吐槽:毕业生能值这个数?
- 关于JSBuilder2的使用.
- scala中的伴生对象,
- Wincc7.3安装说明
- Emu8086下载和注册
- 关于Linux消息队列的简单说明、使用、编码
- 新中大财务软件虚拟化解决方案
- html 数组动态添加元素,js如何动态添加数组?
- 课工场论坛列表发帖制作
- 最近看了一些东西,随便写写JFinal的一些东西吧
- oracle jpg格式导出,格式记RAW,另存或导出就是JPG格式,就这么很简单
- Python+OpenCV实现实时视频3D换脸
- 微信机器人终端1.0未来的设想就是做成telegram一样强大的机器人群体集控终端
- ubuntu 安装mysql 源码,命令ubuntu上用源代码安装mysql的详细操作说明
- 什么是 Daemon 线程
- 哈哈~ 开心死了 厚厚
- Ubuntu 20.04没有声音播放时出现哒哒的噪音
- 《英雄联盟》简介及其社会价值