基于sklearn的分类器实战
已迁移到我新博客,阅读体验更佳基于sklearn的分类器实战
完整代码实现见github:click me
一、实验说明
1.1 任务描述

1.2 数据说明
一共有十个数据集,数据集中的数据属性有全部是离散型的,有全部是连续型的,也有离散与连续混合型的。通过对各个数据集的浏览,总结出各个数据集的一些基本信息如下:
连续型数据集:
1. diabets(4:8d-2c)
2. mozilla4(6:5d-2c)
3. pc1(7:21d-2c)
4. pc5(8:38d-2c)
5. waveform-5000(9:40d-3c)
离散型数据集:
1. breast-w(0:9d-2c-?)
离散-连续混合型数据集:
1. colic(1:22d-2c-?)
2. credit-a(2:15d-2c-?)
3. credit-g(3:20d-2c)
4. hepatitis(少量离散属性)(5:19d-2c-?)举一个例子说明,colic(1:22d-2c-?)对应colic这个数据集,冒号前面的1表示人工标注的数据集序号(在代码实现时我是用序号来映射数据集的),22d表示数据集中包含22个属性,2c表示数据集共有3种类别,'?'表示该数据集中含有缺失值,在对数据处理前需要注意。
二、数据预处理
由于提供的数据集文件格式是weka的.arff文件,可以直接导入到weka中选择各类算法模型进行分析,非常简便。但是我没有借助weka而是使用sklearn来对数据集进行分析的,这样灵活性更大一点。所以首先需要了解.arff的数据组织形式与结构,然后使用numpy读取到二维数组中。
具体做法是过滤掉.arff中'%'开头的注释,对于'@'开头的标签,只关心'@attribute'后面跟着的属性名与属性类型,如果属性类型是以'{}'围起来的离散型属性,就将这些离散型属性映射到0,1,2......,后面读取到这一列属性的数据时直接用建好的映射将字符串映射到数字。除此之外就是数据内容了,读完一个数据集的内容之后还需要检测该数据集中是否包含缺失值,这个使用numpy的布尔型索引很容易做到。如果包含缺失值,则统计缺失值这一行所属类别中所有非缺失数据在缺失属性上各个值的频次,然后用出现频次最高的值来替换缺失值,这就完成对缺失值的填补。具体实现可以参见preprocess.py模块中fill_miss函数。
三、代码设计与实现
实验环境:
python 3.6.7
configparser 3.7.4
scikit-learn 0.20.2
numpy 1.15.4
matplotlib 3.0.3
各个分类器都要用到的几个模块在这里做一个简要说明。
- 交叉验证: 使用sklearn.model_selection.StratifiedKFold对数据作分层的交叉切分,分类器在多组切分的数据上进行训练和预测
- AUC性能指标: 使用sklearn.metrics.roc_auc_score计算AUC值,AUC计算对多类(二类以上)数据属性还需提前转换成one hot编码,使用了sklearn,preprocessing.label_binarize来实现,对于多分类问题选择micro-average
- 数据标准化: 使用sklearn.preprocessing.StandardScaler来对数据进行归一标准化,实际上就是z分数
3.1 朴素贝叶斯Naive Bayes
由于大部分数据集中都包含连续型属性,所以选择sklearn.naive_bayes.GaussianNB来对各个数据集进行处理
clf = GaussianNB()
skf = StratifiedKFold(n_splits=10)
skf_accuracy1 = []
skf_accuracy2 = []
n_classes = np.arange(np.unique(y).size)
for train, test in skf.split(X, y):clf.fit(X[train], y[train])skf_accuracy1.append(clf.score(X[test], y[test]))if n_classes.size < 3:skf_accuracy2.append(roc_auc_score(y[test], clf.predict_proba(X[test])[:, 1], average='micro'))else:ytest_one_hot = label_binarize(y[test], n_classes)skf_accuracy2.append(roc_auc_score(ytest_one_hot, clf.predict_proba(X[test]), average='micro'))
accuracy1 = np.mean(skf_accuracy1)
accuracy2 = np.mean(skf_accuracy2)在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
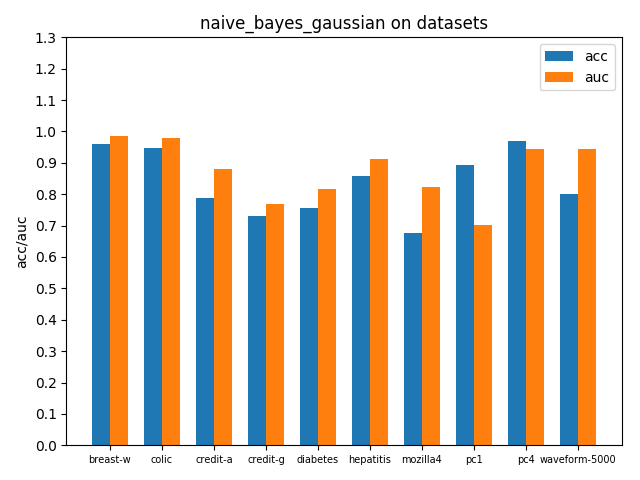
可以看到大部分数据集上的auc指标都比acc高,说明控制好概率阈值(这里默认0.5)acc可能还有提升空间,因为样本分布跟总体分布还有一定的差距,样本数布可能很不平衡,并且权衡一个合适的阈值点还需要结合分类问题的背景和关注重点。由于auc指标考虑到了所有可能阈值划分情况,auc越高能说明模型越理想,总体上能表现得更好。
3.2 决策树decision tree
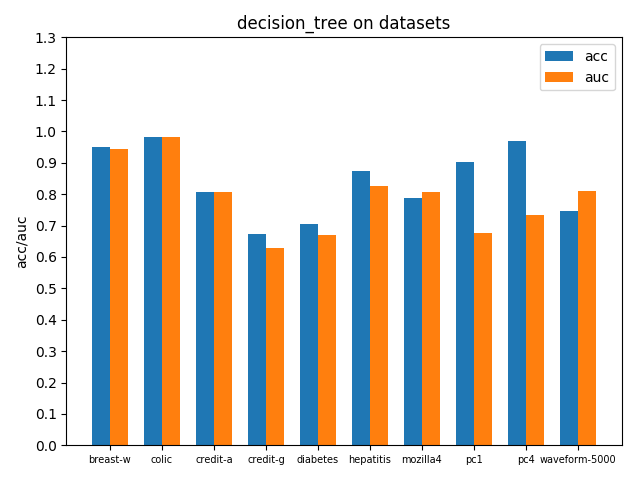
使用sklearn.tree.DecisionTreeClassifier作决策树分析,并且采用gini系数选择效益最大的属性进行划分,下面给出接口调用方式,交叉验证方式与前面的naive bayes一样
clf = DecisionTreeClassifier(random_state=0, criterion='gini')在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
3.3 K近邻KNN
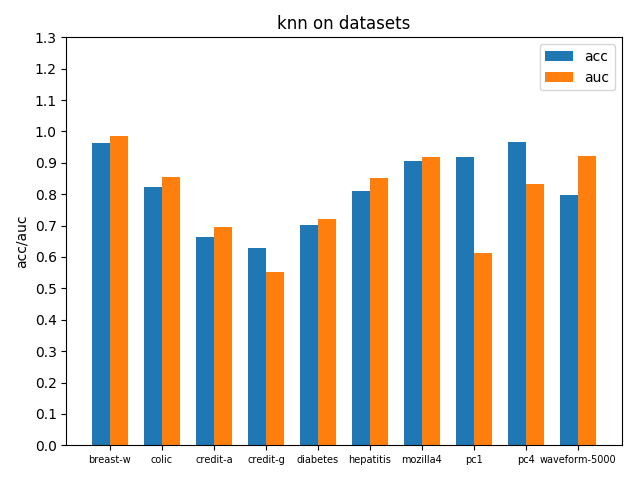
使用sklearn.neighbors.KNeighborsClassifier实现KNN,邻居数设置为3即根据最近的3个邻居来投票抉择样本所属分类,因为数据集最多不超过3类,邻居数选择3~6较为合适,设得更高效果增益不明显并且时间开销大,下面给出接口调用方式
clf = KNeighborsClassifier(n_neighbors=3)在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
3.4 神经网络之多层感知机MLP
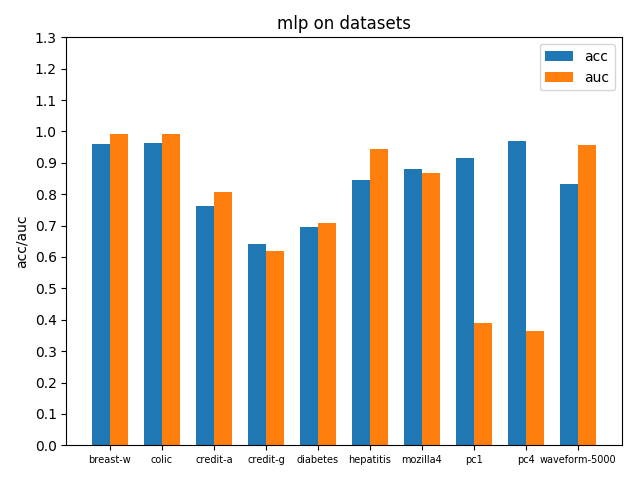
使用sklearn.neural_network.MLPClassifier实现MLP,设置一层隐藏层100个节点,激活函数relu,优化器Adam,学习率1e-3并且自适应降低,l2正则项惩罚系数,下面给出具体的接口调用方式以及参数配置
clf = MLPClassifier(hidden_layer_sizes=(100), activation='relu',solver='adam',batch_size=128,alpha=1e-4,learning_rate_init=1e-3,learning_rate='adaptive',tol=1e-4,max_iter=200)在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
3.5 支持向量机SVM
使用sklean.svm.LinearSVC实现线性SVM分类器,接口调用方式如下
clf = LinearSVC(penalty='l2', random_state=0, tol=1e-4)在各个数据集上进行交叉验证后的accuracy和AUC性能指标如下
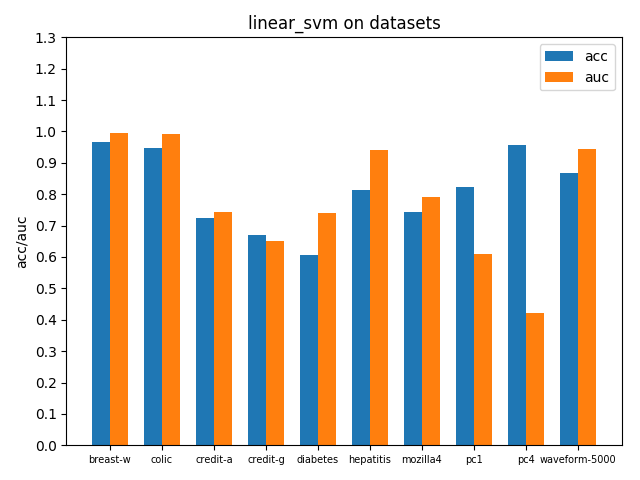
四、实验结果与分析
4.1 不同数据集上的模型对比
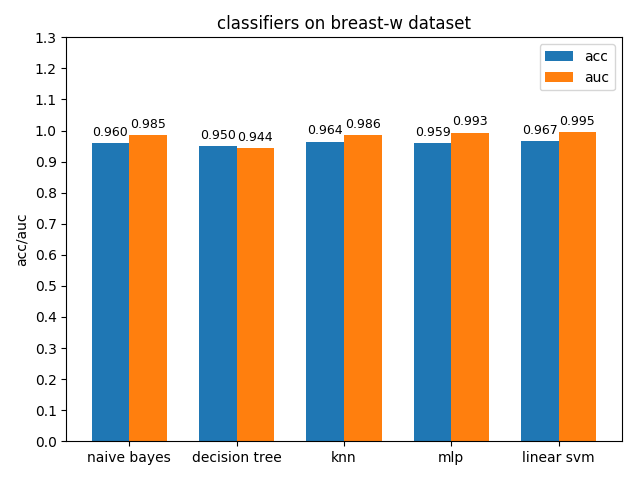
4.1.1 breast-w dataset
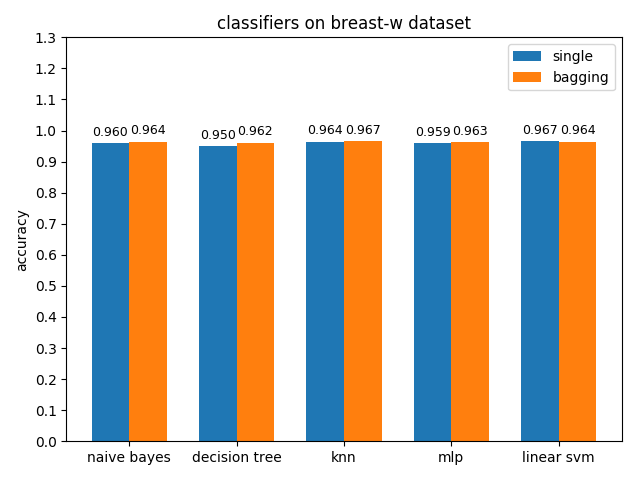
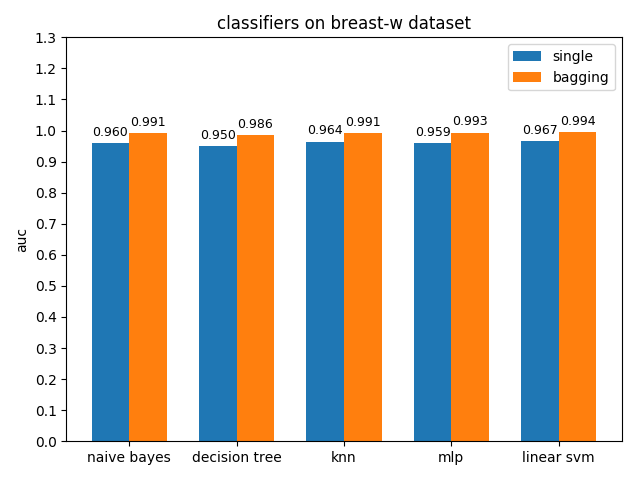
breast-w数据集上,各分类模型的效果都很好,其中linear svm的准确率最高,mlp的auc值最高
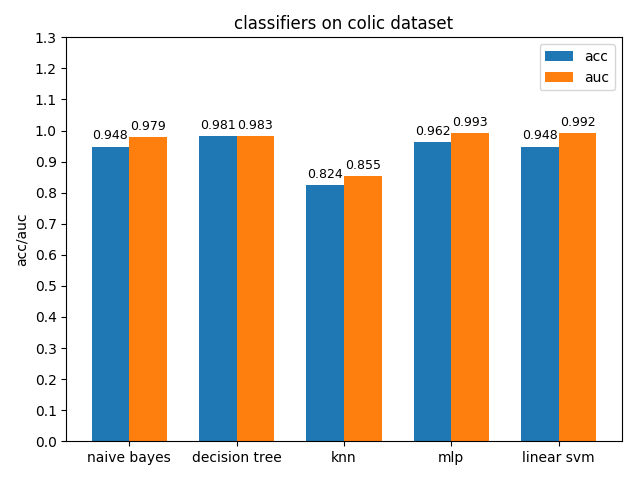
4.1.2 colic dataset
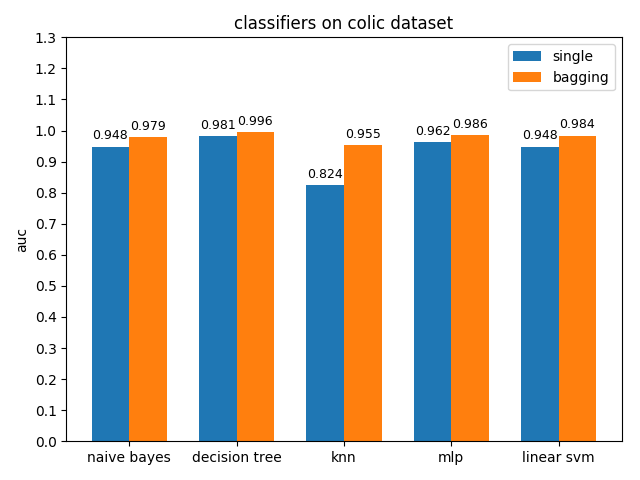
colic数据集上,knn效果不佳,其它分类模型的效果都很好,其中decision tree的准确率最高,mlp的auc值最高
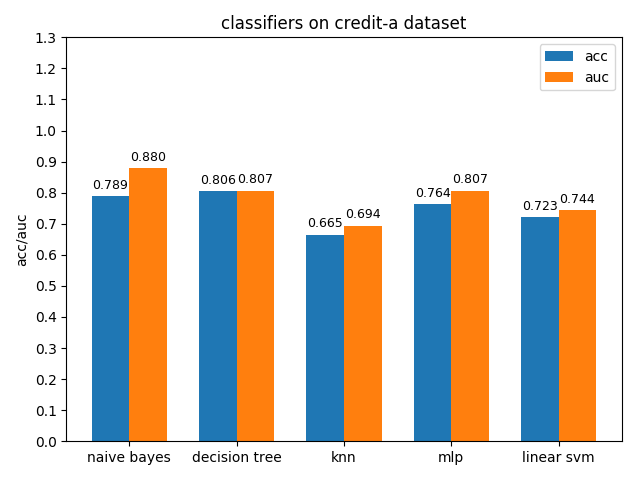
4.1.3 credit-a dataset
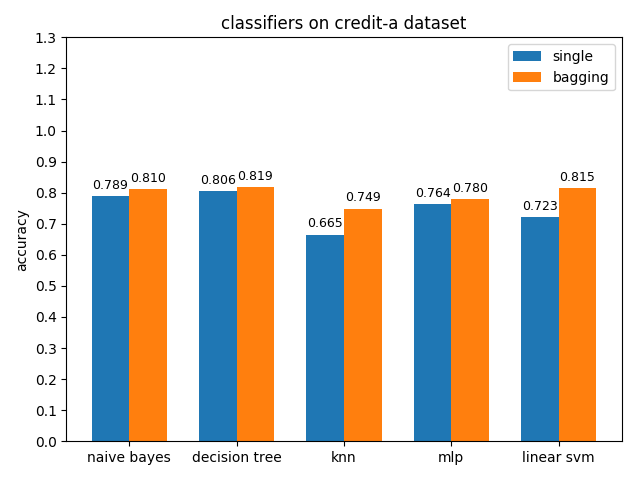
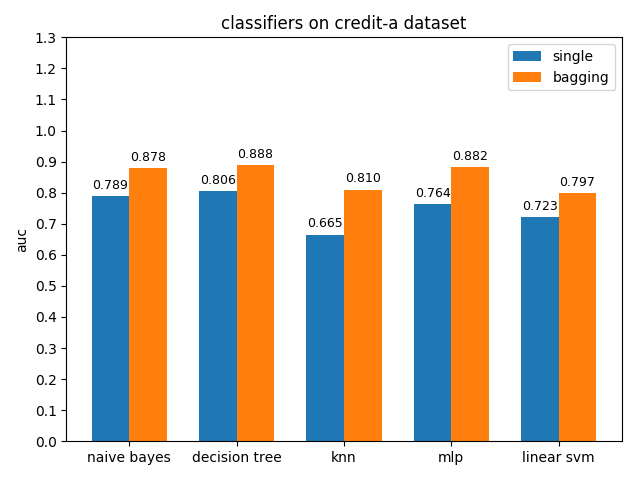
credit-a数据集上,各分类模型的效果都不是很好,其中decision tree的准确率最高,naive bayes的auc值最高
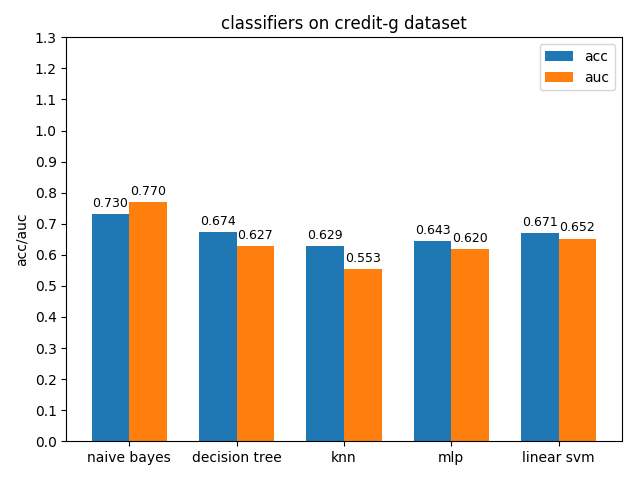
4.1.4 credit-g dataset
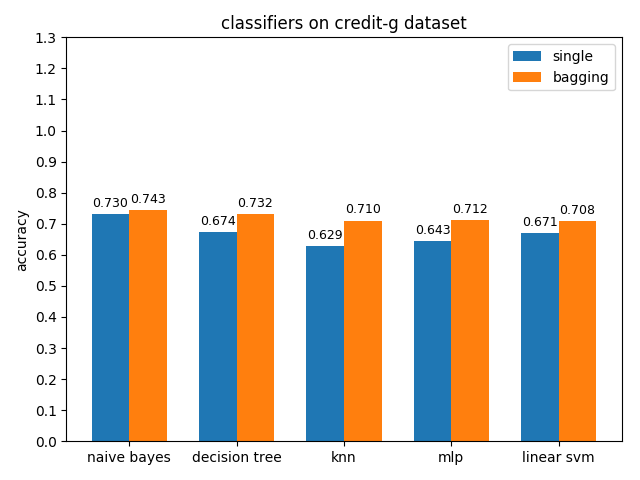
credit-a数据集上,各分类模型的效果都不是很好,其中naive bayes的准确率和auc值都是最高的
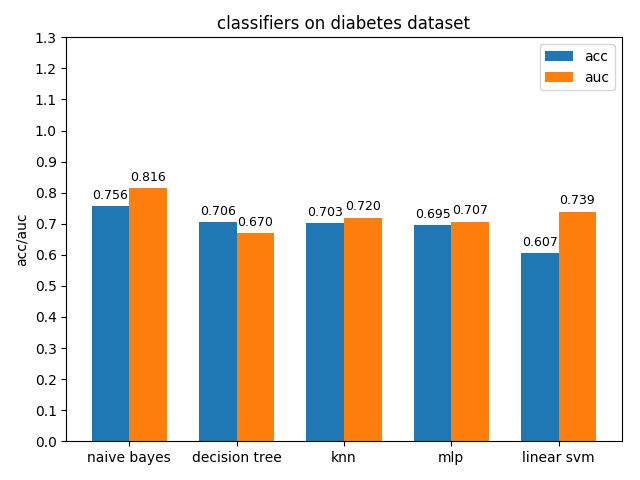
4.1.5 diabetes dataset
diabetes数据集上,各分类模型的效果都不是很好,其中naive bayes的准确率和auc值都是最高的
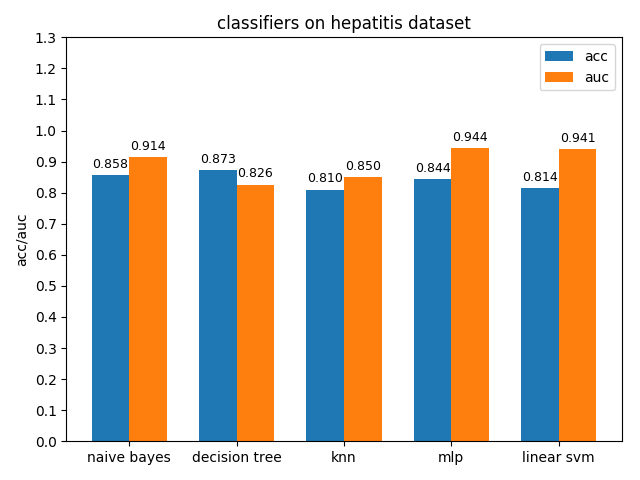
4.1.6 hepatitis dataset
hepatitis数据集上,各分类模型的准确率都没达到90%,decision tree的准确率最高,mlp的auc值最高,但是各分类模型的auc值基本都比acc高除了decision tree,说明hepatitis数据集的数据分布可能不太平衡
通过weka对hepatitis数据集上的正负类进行统计得到下面的直方图
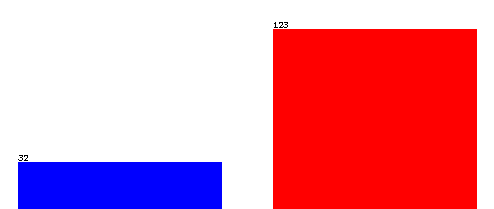
从上面的直方图可以验证之前的猜测是对的,hepatitis数据集正负类1:4,数据分布不平衡,正类远少于负类样本数
4.1.7 mozilla4 dataset
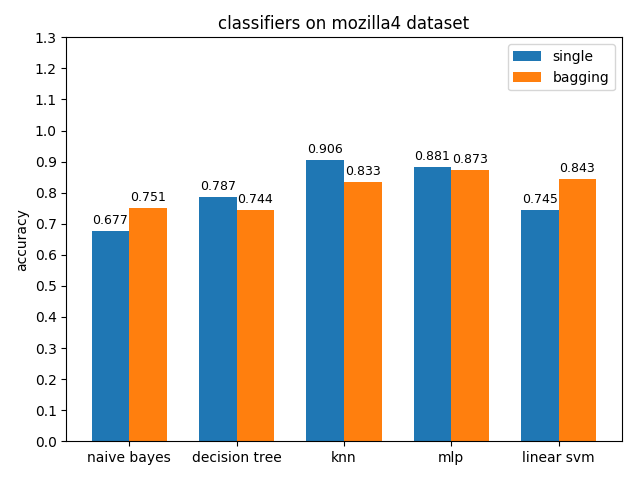
mozilla4数据集上,各分类模型的表现差异很大,其中knn的acc和auc都是最高的,naivie bayes的acc和auc相差甚大
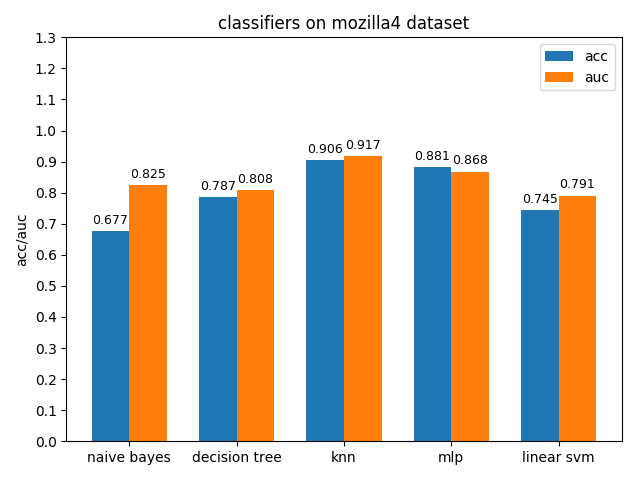
4.1.8 pc1 dataset
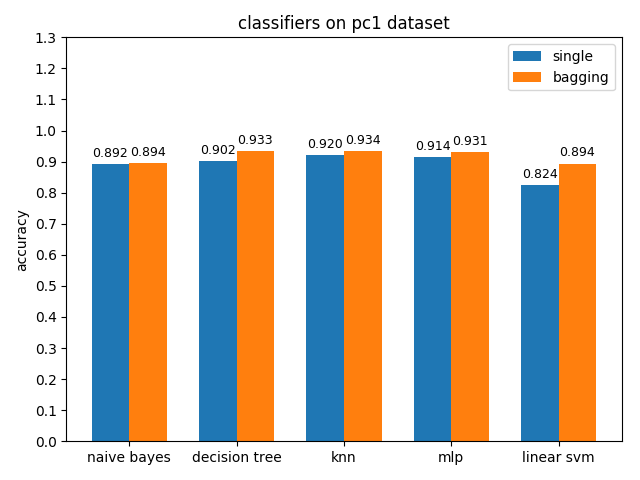
pc1数据集上,各分类模型的准确率基本都挺高的,但是auc值普遍都很低,使用weka对数据进行统计分析后发现pc1数据集的正负类比达到13:1,根据auc计算原理可知正类太多可能会导致TPR相比FPR会低很多,从而压低了auc值
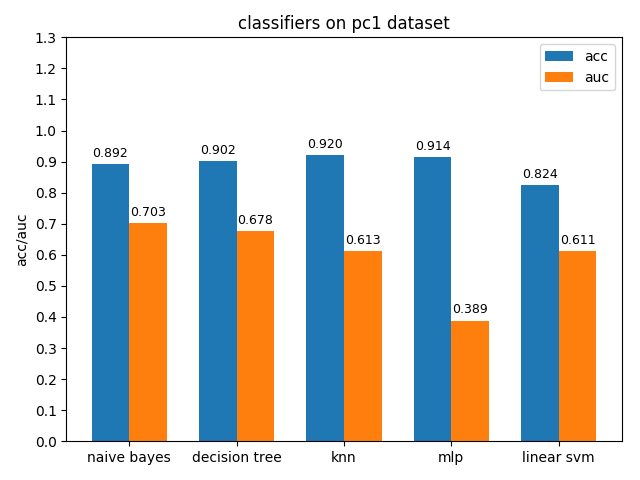
4.1.9 pc5 dataset
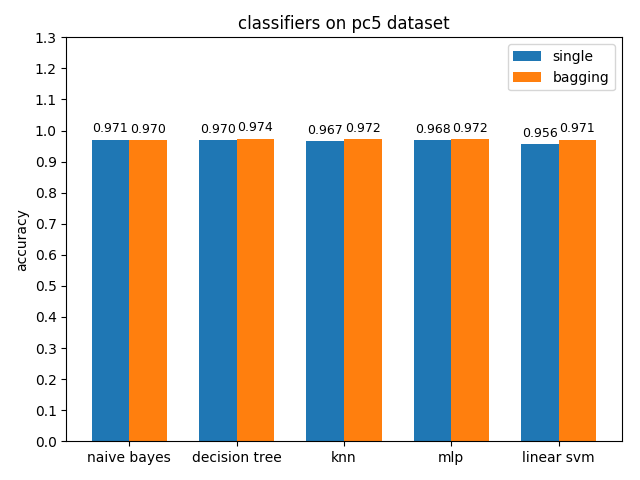
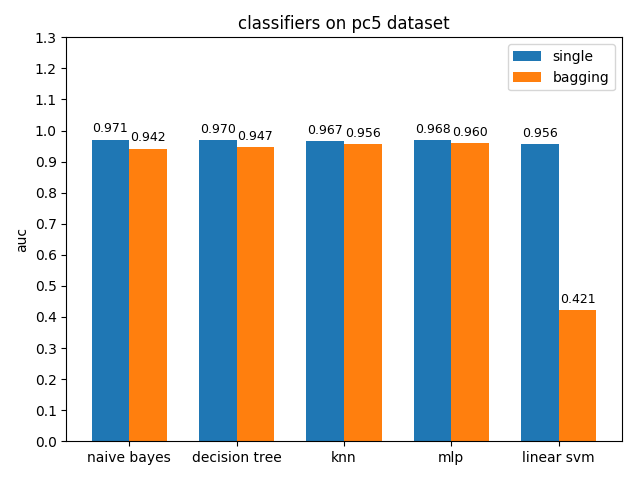
pc5数据集上,各分类模型的准确率都达到了90%以上,但是auc都比acc要低,其中mlp和linear svm的acc与auc相差甚大,原因估计和pc1差不多,正类样本太多拉低了AUC,使用weka分析后发现pc5正负类样本比值达到了32:1,并且数据中夹杂着些许异常的噪声点
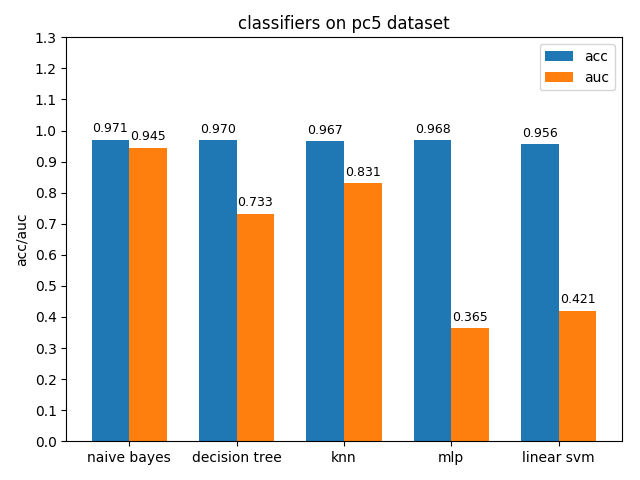
4.1.10 waveform-5000 dataset
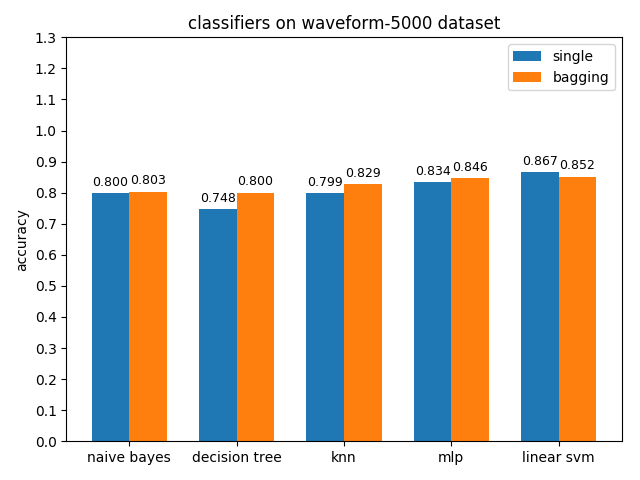
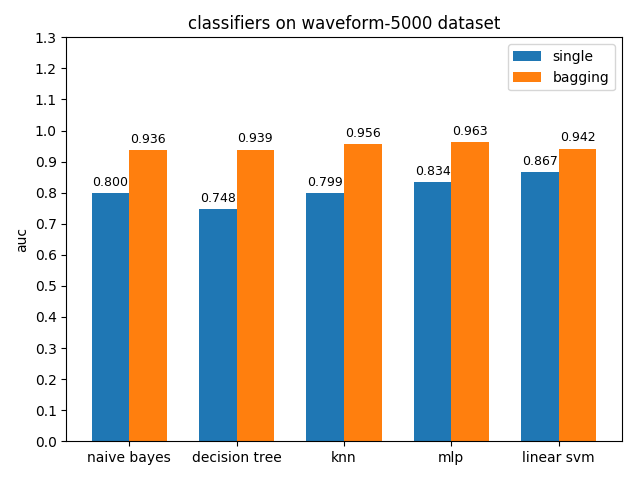
waveform-5000数据集上,各分类模型的准确率基本都是在80%左右,各分类模型的auc基本都有90%除了decision tree以外。waveform-5000是一个三类别的数据集,相比前面的2分类数据集预测难度也会更大,概率阈值的选择尤为关键,一个好的阈值划分会带来更高的准确率。
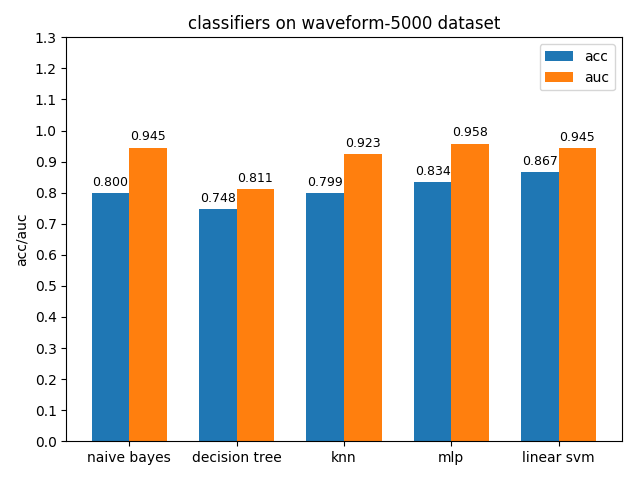
4.2 模型的bagging和single性能对比
4.2.1 breast-w dataset
准确率对比
AUC对比
4.2.1 colic dataset
准确率对比
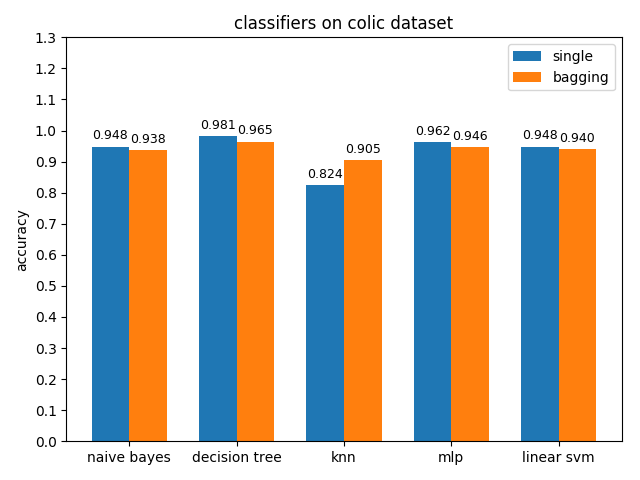
AUC对比
4.2.3 credit-a dataset
准确率对比
AUC对比
4.2.4 credit-g dataset
准确率对比
AUC对比
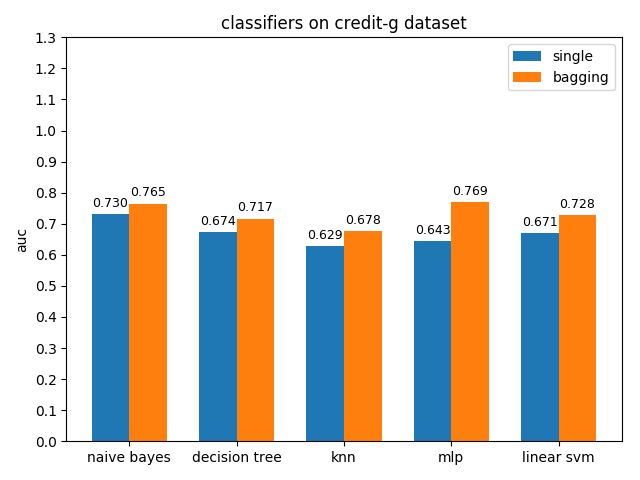
4.2.5 diabetes dataset
准确率对比
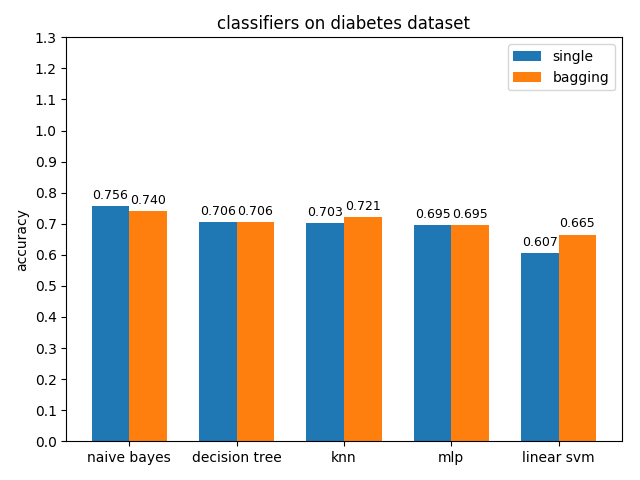
AUC对比
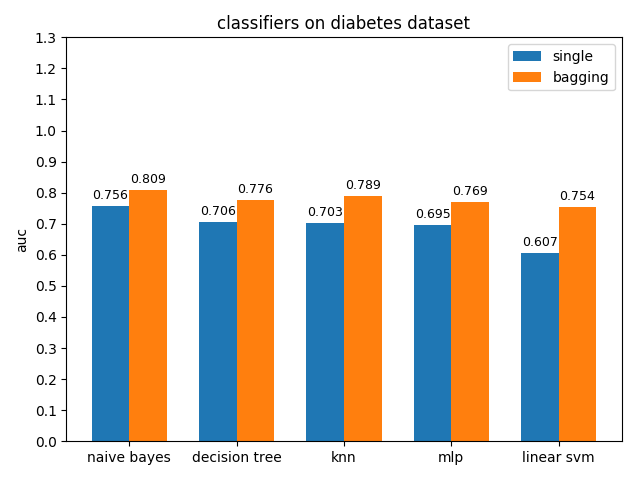
4.2.6 hepatitis dataset
准确率对比
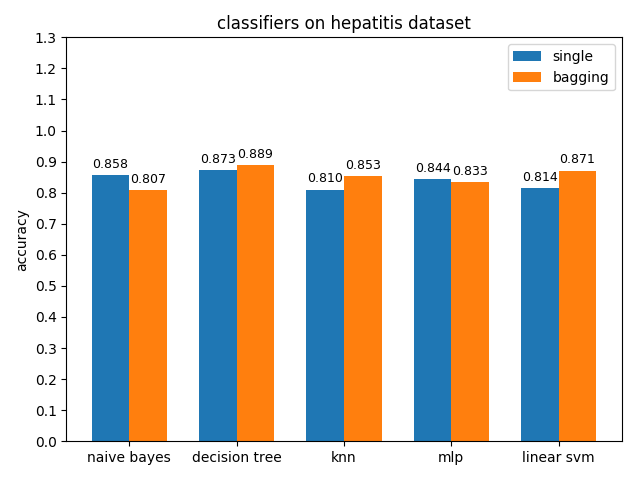
AUC对比
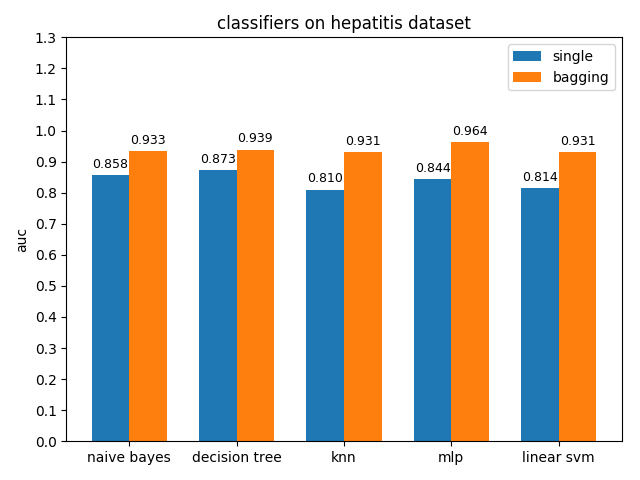
4.2.7 mozilla4 dataset
准确率对比
AUC对比
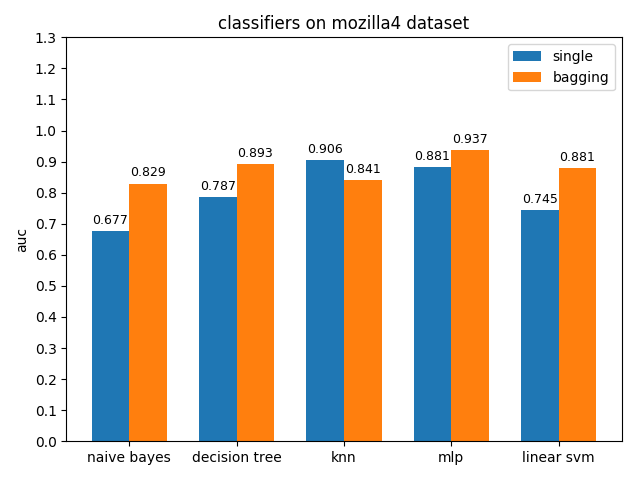
4.2.8 pc1 dataset
准确率对比
AUC对比
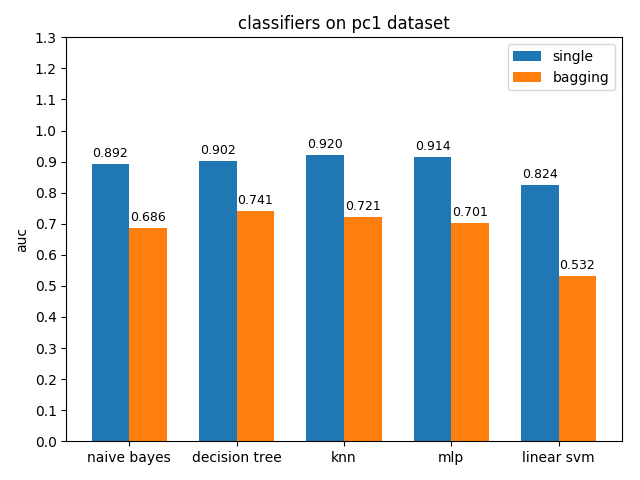
4.2.9 pc5 dataset
准确率对比
AUC对比
4.2.10 waveform-5000 dataset
准确率对比
AUC对比
五、优化
5.1 降维
pc1,pc5,waveform-5000,colic,credit-g这几个数据集的属性维度都在20维及以上,而对分辨样本类别有关键作用的就只有几个属性,所以想到通过降维来摈除干扰属性以使分类模型更好得学习到数据的特征。用主成分分析(PCA)降维之后的数据分类效果不佳,考虑到都是带标签的数据,就尝试使用线性判别分析(LDA)利用数据类别信息来降维。但是LDA最多降维到类别数-1,对于二类数据集效果不好。waveform-5000包含三种类别,于是就尝试用LDA对waveform-5000降维之后再使用各分类模型对其进行学习。
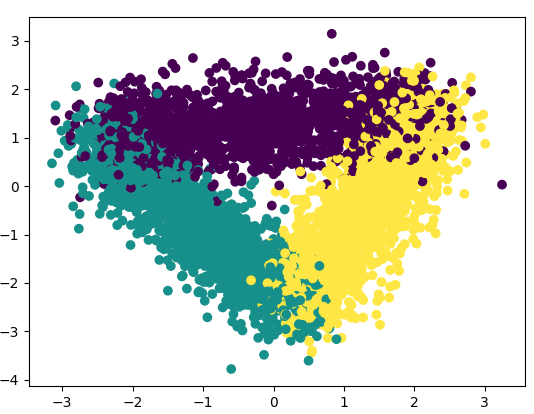
使用sklearn.discriminant_analysis.LinearDiscriminantAnalysis对waveform-5000降维之后的数据样本分布散点图如下,可以明显看到数据被聚为三类,降维之后的数据特征信息更为明显,干扰信息更少,对分类更有利
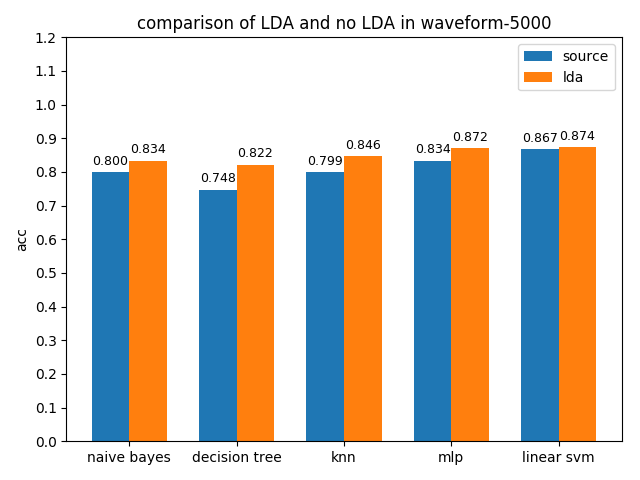
各分类模型在原数据集和LDA降维数据集上准确率对比如下图
各分类模型在原数据集和LDA降维数据集上AUC值对比如下图
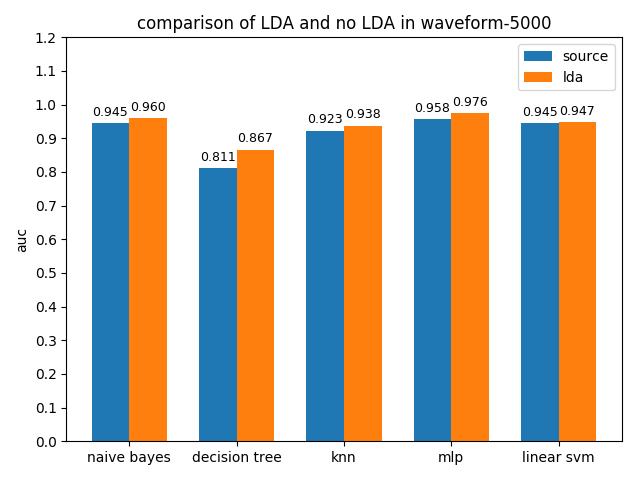
可以看到降维之后的分类效果很理想,无论是acc还是auc,各个分类模型都得到了不同程度的性能提升
5.2 标准化提升bagging with KNN性能
由于KNN是基于样本空间的欧氏距离来计算的,而多属性样本的各属性通常有不同的量纲和量纲单位,这无疑会给计算样本之间的真实距离带来干扰,影响KNN分类效果。为了消除各属性之间的量纲差异,需要进行数据标准化处理,计算属性的z分数来替换原属性值。在具体的程序设计时使用sklearn.preprocessing.StandardScaler来对数据进行标准化。
bagging with KNN在原数据集和标准化数据集上准确率对比如下图
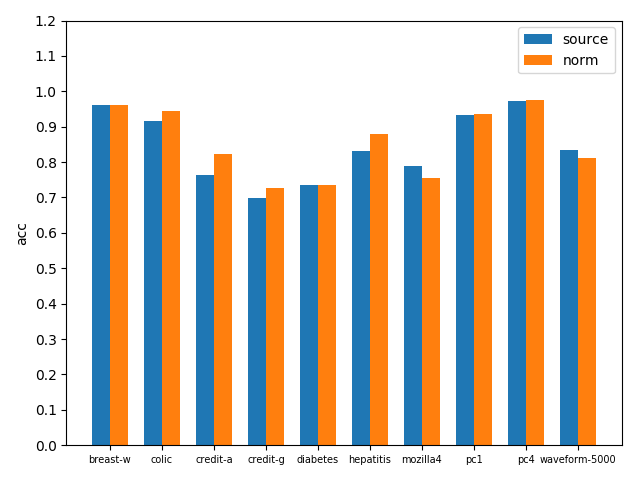
bagging with KNN在原数据集和标准化数据集上AUC对比如下图
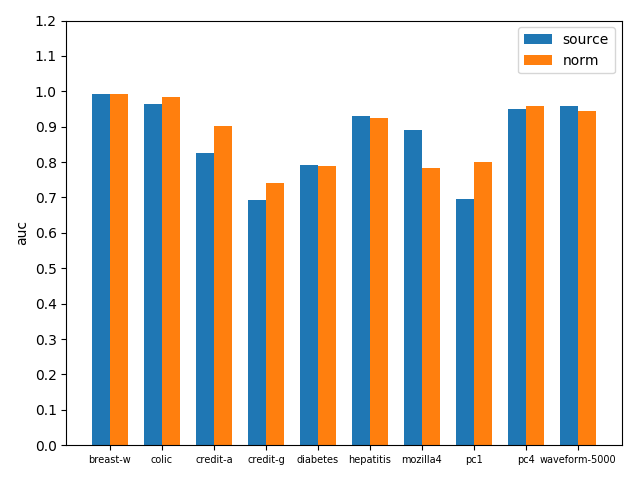
可以看到标准化之后效果还是不错的,无论是acc还是auc,基本在各数据集上都得到了性能提升
六、实验总结
此次实验让我对各个分类器的具体用法有了初步的了解,不同的数据集上应用不同分类模型的效果截然不同。数据挖掘任务70%时间消耗在数据清洗上,无论什么分类模型,其在高质量数据上的表现肯定是要优于其在低质量数据上的表现。所以拿到一个数据集后不能贸然往上面套分类模型,而是应该先对数据集进行观察分析,然后利用工具对数据进行清洗、约简、集成以及转换,提升数据质量,让分类更好得学习到数据的特征,从而有更好的分类效果。本次实验我也对各数据集进行了预处理,包括数据缺失值填补、数据类型转换、数据降维、数据标准化等等,这些工作都在各分类模型的分类效果上得到了一定的反馈。实验过程中也遇到了一些问题,比如使用sklearn.metrics.roc_auc_score计算多类别数据的AUC时需要提前将数据标签转换为one hot编码,LDA最多只能将数据维度降维到类别数-1等等,这些都为我以后进行数据挖掘工作积累了宝贵经验。
转载于:https://www.cnblogs.com/brooksj/p/10923659.html
基于sklearn的分类器实战相关推荐
- 基于sklearn的机器学习实战
本文目录如下: LinearRegression 线性回归入门 数据生成 定义模型 模型测试与比较 多项式回归 具体实现 LogisticRegression 算法思想简述 算法实现 Decision ...
- Python基于MASK信息抽取ROI子图并构建基于迁移学习(densenet)的图像分类器实战(原始影像和mask文件都是二维的情况)
Python基于MASK信息抽取ROI子图并构建基于迁移学习(densenet)的图像分类器实战(原始影像和mask文件都是二维的情况) 目录
- 基于sklearn的LogisticRegression鸢尾花多类分类实践
文章目录 1. 问题描述 2. 数据介绍 2.1 数据描述 2.2 数据 2.3 数据可视化 3. 模型选择 3.1 固有的多类分类器 3.2 1对多的多类分类器 3.3 OneVsRestClass ...
- 【ML】决策树(Decision tree)原理 + 实践 (基于sklearn)
[ML]决策树(Decision tree)原理 + 实践 (基于sklearn) 原理介绍 简要介绍 原理 得分函数(信息熵) 实战 数据集 数据处理 训练 预测+评估 绘制决策树 原理介绍 简要介 ...
- 基于sklearn的人工神经网络
基于sklearn的人工神经网络 概述 前馈神经网络 BP算法 实验步骤 1 安装并引入必要的库 2 数据处理 3 拟合预测 4 调参 4.1 不同的隐含层对于多层神经网络分类器的影响 4.2 不同的 ...
- 第十九课.基于sklearn的SVM人脸识别
目录 数据集 确定人脸的类别标记 划分训练集和测试集与训练 实验为基于sklearn的SVM人脸识别,使用 SVM 算法对戴眼镜的人脸和不戴眼镜的人脸进行分类,从而完成 识别戴眼镜的人脸 的任务:实验 ...
- R语言dplyr包数据过滤(filter)基于not in规则实战(not in Filter):基于单数据列not in规则过滤数据行、基于多数据列not in规则过滤数据行
R语言dplyr包数据过滤(filter)基于not in规则实战(not in Filter):基于单数据列not in规则过滤数据行.基于多数据列not in规则过滤数据行 目录
- R构建径向核支持向量机分类器实战代码(Radial kernel Support Vector Classifier)
R构建径向核支持向量机分类器实战代码(Radial kernel Support Vector Classifier) 目录 R构建径向核支持向量机分类器实战代码(Radial kernel Supp ...
- R构建KNN分类器实战
R构建KNN分类器实战 目录 R构建KNN分类器实战 KNN分类模型 加载数据集 构建KNN模型 KNN模型预测推理
- ML之NB:(NLP)基于sklearn库利用不同语种数据集训练NB(朴素贝叶斯)算法,对新语种进行语种检测
ML之NB:(NLP)基于sklearn库利用不同语种数据集训练NB(朴素贝叶斯)算法,对新语种进行语种检测 目录 输出结果 训练数据集 设计思路 核心代码 输出结果 测试01:I love you ...
最新文章
- 迁移学习之MobileNet(88层)和MobileNetV2(88层)
- sqlite3.OperationalError: database is locked
- Druid(准)实时分析统计数据库——列存储+高效压缩
- Oracle 的一些语句
- RabbitMQ之TTL(Time-To-Live 过期时间)
- java wsdl xfire_java调用wsdl xfire和cxf两种方式
- Progress lifecycle
- 显示用户上次访问时间
- 十个利用矩阵解决的经典题目
- ORACLE数据库 基础练习表EMP\DEPT \SALGRADE脚本
- php 输入需要删除文本里的字符串_重新学习php基础之-安全E-mail(十九)
- 计算机应用基础三次没有通过怎么办,计算机应用基础第三次作业
- springboot毕业设计 基于springboot旅游景区景点购票系统毕业设计设计与实现参考
- womic网络错误_wo mic 电脑版下载-WO Mic Client下载 3.4 最新电脑版 - 河东下载站
- 第十二课:树莓驱动SG90派舵机
- 大学生网页作业成品——基于HTML网上书城项目的设计与实现
- ps 转html node,Node.js模拟发起http请求从异步转同步的5种方法
- kangle配置cdn_kangle穿刺及cdn回源配置
- 玩家参与装备熔炼顺序是怎样进行
- VMware中ubuntu设置成中文
热门文章
- NHibernate初学者指南(3):创建Model
- 专业化分类服务,引领IDC行业发展新模式
- 两个app应用之间的跳转
- 简述linux命令的,简述linux系统以及一些简单的命令
- Javascript异步操作(Promise)
- PHP 利用CURL抓取页面内容
- Windows Mysql报错:Access denied for user ‘root‘ @ localhost useing password no 或者 yes 解决
- 小白自定义bat文件一键启动电脑应用
- Kibana 自定义索引模式 Index patterns
- 热烈祝贺龙芯Loongarch OpenJDK8开源,已编译完成