python怎么训练模型_GPU如何训练大批量模型?方法在这里
分布式训练:在多台机器上训练本文引用地址:http://www.eepw.com.cn/article/201810/393173.htm
在更大的批量上训练时,我们要如何控制多个服务器的算力呢?
最简单的选择是使用 PyTorch 的 DistributedDataParallel,它几乎可以说是以上讨论的 DataParallel 的直接替代元件。
但要注意:尽管代码看起来很相似,但在分布式设定中训练模型要改变工作流程,因为你必须在每个节点上启动一个独立的 Python训练脚本。正如我们将看到的,一旦启动,这些训练脚本可以通过使用 PyTorch 分布式后端一起同步化。
在实践中,这意味着每个训练脚本将拥有:
它自己的优化器,并在每次迭代中执行一个完整的优化步骤,不需要进行参数传播(DataParallel 中的步骤 2);
一个独立的 Python解释器:这也将避免 GIL-freeze,这是在单个 Python解释器上驱动多个并行执行线程时会出现的问题。
当多个并行前向调用由单个解释器驱动时,在前向传播中大量使用 Python 循环/调用的模型可能会被 Python 解释器的 GIL 放慢速度。通过这种设置,DistributedDataParallel 甚至在单台机器设置中也能很方便地替代 DataParallel。
现在我们直接讨论代码和用途。
DistributedDataParallel 是建立在 torch.distributed 包之上的,这个包可以为同步分布式运算提供低级原语,并能以不同的性能使用多种后端(tcp、gloo、mpi、nccl)。在这篇文章中,我将选择一种简单的开箱即用的方式来使用它,但你应该阅读文档和 Séb Arnold 写的教程来深入理解这个模块。
文档:https://pytorch.org/docs/stable/distributed.html
教程:https://pytorch.org/tutorials/intermediate/dist_tuto.html
我们将考虑使用具有两个 4 - GPU 服务器(节点)的简单但通用的设置:
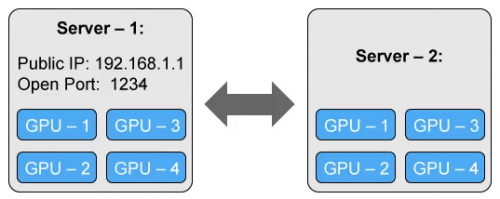
主服务器(服务器 1)拥有一个可访问的 IP 地址和一个用于通信的开放端口。
改写 Python 训练脚本以适应分布式训练
首先我们需要改写脚本,从而令其可以在每台机器(节点)上独立运行。我们将实现完全的分布式训练,并在每个节点的每块 GPU 上运行一个独立的进程,因此总共需要 8 个进程。
我们的训练脚本有点长,因为需要为同步化初始化分布式后端,封装模型并准备数据,以在数据的一个子集上来训练每个进程(每个进程都是独立的,因此我们需要自行处理)。以下是更新后的代码:
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
# Each process runs on 1 GPU device specified by the local_rank argument.
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
# Initializes the distributed backend which will take care of sychronizing nodes/GPUs
torch.distributed.init_process_group(backend='nccl')
# Encapsulate the model on the GPU assigned to the current process
device = torch.device('cuda', arg.local_rank)
model = model.to(device)
distrib_model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[args.local_rank],
output_device=args.local_rank)
# Restricts data loading to a subset of the dataset exclusive to the current process
sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=sampler)
for inputs, labels in dataloader:
predictions = distrib_model(inputs.to(device)) # Forward pass
loss = loss_function(predictions, labels.to(device)) # Compute loss function
loss.backward() # Backward pass
optimizer.step() # Optimizer step
启动 Python 训练脚本的多个实例
我们就快完成了,只需要在每个服务器上启动训练脚本的一个实例。
为了运行脚本,我们将使用 PyTorch 的 torch.distributed.launch 工具。它将用来设置环境变量,并用正确的 local_rank 参数调用每个脚本。
第一台机器是最主要的,它应该对于所有其它机器都是可访问的,因此拥有一个可访问的 IP 地址(我们的案例中是 192.168.1.1)以及一个开放端口(在我们的案例中是 1234)。在第一台机器上,我们使用 torch.distributed.launch 来运行训练脚本:
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234 OUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of our training script) # Optimizer step
在第二台机器上,我们类似地启动脚本:
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=2 --node_rank=1 --master_addr="192.168.1.1" --master_port=1234 OUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other arguments of our training script)
这两个命令是相同的,除了—node_rank 参数,其在第一台机器上被设为 0,在第二台机器上被设为 1(如果再加一台机器,则设为 2,以此类推…)。
python怎么训练模型_GPU如何训练大批量模型?方法在这里相关推荐
- python 调用gpu算力_GPU捉襟见肘还想训练大批量模型?谁说不可以
原标题:GPU捉襟见肘还想训练大批量模型?谁说不可以 选自Medium 深度学习模型和数据集的规模增长速度已经让 GPU 算力也开始捉襟见肘,如果你的 GPU 连一个样本都容不下,你要如何训练大批量模 ...
- 网页怎么预先加载模型_使用预先训练的模型进行转移学习
网页怎么预先加载模型 深度学习 (Deep Learning) 什么是转学? (What is Transfer Learning?) Transfer learning is a research ...
- 是否有可能从python中的句子语料库重新训练word2vec模型(例如GoogleNews-vectors-negative300.bin)?
是否有可能从python中的句子语料库重新训练word2vec模型(例如GoogleNews-vectors-negative300.bin)? http://www.voidcn.com/artic ...
- python如何训练模型生产_手把手教你用Python构建你的第一个多标签图像分类模型(附案例)...
你正在处理图像数据吗?我们可以使用计算机视觉算法来做很多事情: 对象检测 图像分割 图像翻译 对象跟踪(实时),还有更多-- 这让我思考--如果一个图像中有多个对象类别,我们该怎么办?制作一个图像分类 ...
- Java如何跨语言调用Python/R训练的模型
在 如何使用sklearn进行在线实时预测(构建真实世界中可用的模型) 这篇文章中,我们使用 sklearn + flask 构建了一个实时预测的模型应用.无论是 sklearn 还是 flask,都 ...
- python knn模型_使用Python训练KNN模型并进行分类
K临近分类算法是数据挖掘中较为简单的一种分类方法,通过计算不同数据点间的距离对数据进行分类,并对新的数据进行分类预测.我们在之前的文章<K邻近(KNN)分类和预测算法的原理及实现>和< ...
- Python statsmodel包训练LR模型
Python中训练LR模型一般使用sklearn包,输出模型报告和其他机器学习方法一样.但从统计背景出发,想看更详细的报告,statsmodel包可以帮助实现. 1.训练模型 import stats ...
- bert中文预训练模型_HFL中文预训练系列模型已接入Transformers平台
哈工大讯飞联合实验室(HFL)在前期陆续发布了多个中文预训练模型,目前已成为最受欢迎的中文预训练资源之一.为了进一步方便广大用户的使用,借助Transformers平台可以更加便捷地调用已发布的中文预 ...
- PyTorch(Python)训练MNIST模型移动端IOS上使用Swift实时数字识别
识别手写数字是计算机视觉的基石问题,可以通过神经网络来解决.在此,我不会重复有关模型构建和训练的细节. 本文中,我的目的是将经过训练的模型移植到移动环境中.我使用 pytorch 构建模型,因为我想尝 ...
最新文章
- Makefile注意点总结
- c# 字符串排序 (面试题)
- mysql 分页有数据没了_mysql分页丢数据的分析
- 72. Leetcode 99. 恢复二叉搜索树 (二叉搜索树-中序遍历类)
- (网络编程)TCP实现文件上传
- 高并发高可靠性系统思考1
- python开发工具下所有软件都打不开_Python 开发工具链全解
- 遍历删除_面试难题:List 如何一边遍历,一边删除?
- 学Python的初体验——模块简述
- Hadoop HA on Yarn——集群配置
- 怎么用eclipse修改web工程的访问路径
- Android编程之另一种原因造成Cursor未关闭错误
- Java 泛型完全解读
- keepalived实现双机互备
- Mysql Too many connections解决方案
- 【Python】fastapi框架之Web部署机器学习模型
- 基于C++的BNN推理
- 计算机考研404是什么意思,研路分享:我的404分考研高分心得体会
- 关于“微笑涛声”博客
- SQL 语句:不得使用外键与级联,一切外键概念必须在应用层解决