Better than better,白山EC2.0发布
近几年存储技术变化之快前所未有,行业正经历翻天覆地的变化。与此同时,企业的数字化转型以及用户数据的暴涨也呼唤新的存储形态出现。在这种背景下,软件定义存储得以快速普及,其中对象存储作为新的存储形态成为了海量存储的首选。海量数据存储业务中往往有大量的冷数据,这些数据同时对可靠性与成本提出了苛刻的要求,于是各家对象存储服务商纷纷采用了纠删码技术来满足这样的要求。
白山一直以来致力于对数据存储管理的极致追求,热数据存储需求促使我们不断推进边缘存储的建设,冷数据存储需求促使我们对纠删码技术的不断改进。在 2016 年 6月 ,纠删码技术随同白山云存储一同发布,开启了白山EC1.0 时代。与此同时,边缘存储也开始发力,为诸多客户的热数据存储提供坚实的基础设施。
现在,全新设计的白山 EC2.0 终于正式登场。在这篇文章中,我们将一同探索 EC2.0 的架构设计,EC 算法与优化,以及 EC1.0 到 EC2.0 的美妙进化。
纠删码集群架构设计
在白山新一代的纠删码存储中, 我们将许久以来积累的改进, 创新, 沉淀成一行行代码, 部署到线上, 包括:
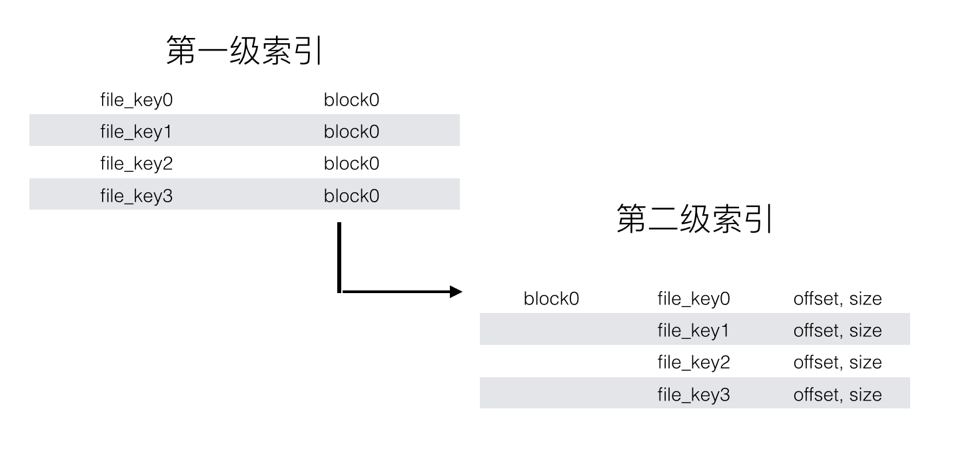
千亿文件的索引设计: 减少 99% 的元数据压力
白山的纠删码文件索引分为两级,第一级指向文件所在的 block(磁盘上的物理文件),第二级索引提供具体的 offset size 信息。
文件与磁盘空间的生命周期管理
在迁移过程中我们使用了灵活可配的热冷分层算法,实现了 “位置” “时间” “顺序” 三大维度的自主调优:
- 纠删码多机房冗余,机房越多,冗余系数越低
- 根据文件创建时间来触发冷数据迁移
- 基于文件名顺序排列,压缩海量元数据
自适应文件级别的冷热分层
“命名”和”缓存” 是计算机领域的两个终极问题, 一个系统中缓存的设计是一个永恒的话题: 如何通过确定的方法, 优化不确定的数据分布问题. 这个问题的左边是存储成本控制, 右边是读写效率的优化;
就像CPU的L1 cache是每个系统工程师必须关注的问题, 分布式存储中的数据分层也渐渐成为一个成熟的存储系统必须考虑的问题.
白山以此为重心, 重新思考了数据在分布式系统中的分布策略, 将传统上离散的分层策略, 进化成集成冷, 热, 地域等信息统一的数据编排算法.
Silent Data Corruption 对数据的危害与防护
我们使用冗余的办法,如副本或纠删码来抵御存储系统的不稳定因素。然而单凭冗余策略,不仅不能保障数据安全,可能还会面临系统雪崩的风险。这类被大多数人忽视,或是不甚了解的潜在错误无时无刻不在威胁着我们的系统安全。
白山在设计伊始便对 Silent Data Corruption 进行了全面的分析。根据网络控制流,副本数据,纠删码数据,数据库数据的不同特点做了针对性的防御措施,全面高效的保障数据安全。
大幅度的降低存储成本的同时提升可靠性
在 EC2.0 的算法优化基础上, 白山在同等冗余度下再次极大提升了数据的修复速度和可靠性。
本篇就以此为核心, 和大家分享白山独到的纠删码算法的设计和实现.
EC 进化简史
纠删码技术作为提高数据可靠性并减低 TCO 的手段,已成为云存储的标准配置。但纠删码方案并不是完美的,其中最主要有以下两点:
- 纠删码编码引擎实现难度高,大部分公司选择开源引擎而不是自研,缺乏对质量的把控。可能在使用有 bug 的代码而不自知。[1]
- 纠删码会倍数级别放大修复开销,影响系统的稳定性和安全性。
因此,尽管要面对成本与研发精力的巨大投入,白山依然从始至终坚持纠删码技术的改进与研发工作。
EC1.0 的算法设计主要针对上面提到的第二个问题,即修复开销放大的问题。
EC1.0 相较于传统的 EC 能减少 50% 的修复开销。
但为此付出的代价就是会增加一定的冗余成本。
那么,我们能不能在成本和修复性能之间实现最佳平衡呢?
对于极致的追求,便是 EC2.0 诞生的摇篮。
RS Codes
纠删码中最典型的算法就是里德-所罗门码 (Reed-Solomon Codes)。RS Codes 最早应用于通信领域,经过数十年的发展,其在存储系统中得到了广泛应用,比如光盘中使用 RS Codes进行容错,防止光盘上的划痕导致数据不可读;生活中,我们经常使用的二维码也利用了 RS Codes 来提高识别成功率。
EC 的基本原理并不复杂,我们只需将原始数据切分成段,计算出比原始数据总量要少的冗余,并能根据冗余恢复原始数据,这样我们就实现了存储成本降低的目标。
原始数据分组
下面我们以 3+2 (原始数据切分为 3 份,计算 2 份冗余)为例,展示 RS Codes 的编码/修复过程。

首先,假设我们拥有一段随机的原始数据: “0, 1, 211, 3, 77, 88”,我们将它切分成3 组向量(如上图所示),组成 The Original Data Matrix(原始数据矩阵)。
数据编码

接下来,我们需要生成一个 Encoding Matrix(编码矩阵)。编码矩阵的作用是在编码过程中,与原始数据相乘,得到编码后的数据。另外,我们还需要保证编码矩阵的任意子矩阵可逆,这样才能帮助我们恢复数据。
通过将 The Original Data Matrix 与 The Encoding Matrix 相乘,得到 The Original Data Matrix 与 The Parity Data Matrix(冗余数据矩阵)。类似这种编码后,原始数据不变的编码我们称之为 Systematic Codes (系统码),这也是实践当中应用最广泛的编码类型。
修复损坏数据
由于矩阵中的行是线性无关的,当我们丢失了两个数据块,也就是删除了矩阵中的两行,是不影响等式成立的:


以上就是 RS Codes 基本工作原理的图解,其修复步骤可以概括如下:
- 求 Encoding Matrix 的逆矩阵 e'
- e'*e = I
- origina data matrix = e' * valid data matrix
第一次进化:LRC
在 k+m 的 RS Codes 中,修复任一数据块均需要 k 个数据块参与,修复放大系数为 k,修复代价高昂,甚至影响了系统的可靠性。在这种背景下,Locally Reconstruction Codes (LRC) 应运而生。
这里以 6+2+2 为例,看 LRC 是如何工作的:

计算冗余块的步骤如下:

当LRC中有一个数据损坏时, 恢复开销仅仅为 50%
在丢失任一原始数据块的情况下,都能通过 3 个数据块来进行异或运算来进行修复: 使用 Px 或 Py 进行修复, 而不是原先的需要 6 个数据块进行 RS 解码.
而在多数情况下(约95%), 系统内都只需要修复一个数据块丢失的问题;
因为两个数据块同时损坏的概率是单磁盘故障率的平方.
但这样做,并不满足 MDS 性质(最大距离可分 Maximum Distance 码是一种最优容错编码方法,即 n= k+m 编码后的最大可容忍任意m 份数据失效,原始数据也不会丢失。RS Codes 就是 MDS 码。)。 因此可靠性不如相同冗余度的 RS Codes
再次进化:EC1.0

在 EC1.0 中:

因此, P0 可以不用实际落盘。相较于传统的 LRC, Baishan LRC 减少了存储的冗余度。
高阶进化:EC2.0
算法性质
经过上面的研究与沉淀,我们试图找到一种更加平衡的算法,新算法具备如下性质:
- 满足 MDS 性质
- 相较于 RS Codes 能减少修复 I/O 开销
- 支持 SSSE3 AVX2 AVX512 等多种扩展指令集
- API 丰富易用
- 代码简洁清晰
由于开源的 RS Codes 引擎 Intel ISA-L 曾导致 OpenStack Swift 出现数据不可修复的 bug[1],在研究之后[3],我们选择完全自主研发。
极限性能
首先,为了实现高性能引擎(满足目标 3),我们必须掌握加速有限域运算的技术。
对于任意 1 字节来说,在 GF(2^8) 内有 256 种可能的值,所以每一个元素对应的乘法表大小为 256 字节,每次查表仅可以进行一个字节数据的乘法运算,效率很低:

在论文 <Screaming Fast Galois Field Arithmetic Using Intel SIMD Instructions> 中介绍了将乘法表放入 XMM 寄存器的方法,其中用两个等式可以概括其精髓:

受限于篇幅,我们将在后续文章展开讲解性能优化细节与技巧。有兴趣的读者可以看我们开源的 RS Codes 编码引擎[4]。这份开源代码中,我们在保持其高性能的同时(与 Intel ISA-L 相媲美),加强了对代码可读性的提升。需要注意的是:为了支持 AVX512 并使得汇编代码使用指令而不是字节序列,要求 Go 的版本大于等于 1.11

注:
- 运行平台: AWS c5d.large
- 结果 = 10 * 数据分块尺寸 / 消耗时间
- 数值越大表明性能越好
最终形态
为了取得冗余成本与修复代价之间的平衡,我们翻阅了许多学术论文。
其中 Beehive 是我们最终考察的编码方案之一[5]。Beehive 能保证丢失一个甚至多个数据块的情况下只需要更少的数据来重建丢失块。论文中给了如下例子:

由上图,我们不难发现 Beehive 显著减少了修复开销。但 Beehive 并没有完全满足我们对于空间的追求。其存储效率要低于 RS Codes,因此,Beehive 被我们暂时排除掉了。
在经过更多的学习与研究后,我们得出了一个关于减少修复带宽编码系统的基本结论:
要将冗余信息蕴含在计算过程当中,通过特定步骤在临时信息中找到线索以求减少修复开销。
根据这个指导思想,我们重新阅读了论文 <Rethinking Erasure Codes for Cloud File Systems: Minimizing I/O for Recovery and Degraded Reads>。
在 Rotated Reed-Solomon Codes 这一章节中,我们可以发现一种较为简单的对原始数据切割的算法,论文中的例子如下:


以这个算法为基础,我们对原始数据切割整合,随后将信息合并到冗余块中。通过这样的操作,在丢失数据块的情况下,我们对数据的依赖由 k+m 中的 k 转为了部分需要 k 部分需要其它整合数据,只要保证剩余数据所需的组合数据少于 k 份,就可以实现减少修复开销的目的。
华山论剑
存储开销PK

可以明显发现, EC2.0 具有和 RS 一致的冗余开销,在 EC1.0 的基础之上进一步减少了冗余成本。
修复开销PK

LRC 与 EC1.0 的修复开销最小仅为 3, RS 最大为 6,EC2.0 为 4.2
性能PK
注: 运行平台: AWS c5d.large
编码 & 修复一块原始数据 (数据在内存中)
注:
- 6+3 (4MB 每个数据块)
- 结果 = 消耗时间 (单位 ms)
- 横坐标(时间)越短性能越好

其中 LRC Encode 速度最慢,EC1.0与 EC2.0 速度一致,RS 最快。在修复速度上,由于数据在内存中,体现不出 EC2.0 在节约 I/O 开销上的优势。
修复一块原始数据 (数据在磁盘中)
注:
- 9+4 (360MB 每个数据块)
- 结果 = 消耗时间 (单位 ms)

EC2.0 在修复速度上有了明显的提升,这得益于 30% 的磁盘 I/O 的减少。
结束语
分布式存储并不是一个新鲜的技术,似乎很难发掘出新东西。但我们相信,如果有耐心,有足够的工程能力和实践经验去做支撑,我们依然可以一小步一小步的去开拓。新一代的纠删码只是白山的一个阶段性成果,目前,更先进的纠删码引擎的开发已在进行中。我们希望能继续创新,继续为大家带来惊喜。
感兴趣的朋友,可以扫描下方二维码,加入“白山云存储技术交流群”,一起碰撞、一起进步。

附录
- Swift Data Corruption: https://openstack.nimeyo.com/114966/openstack-dev-swift-upcoming-impact-to-configuration-swift
- Baishan LRC: https://github.com/baishancloud/lrc-erasure-code
- Vandermonde Matrix: http://drmingdrmer.github.io/tech/distributed/2017/02/01/ec.html#gf256-下的-vandermonde-矩阵的可逆性
- Reed-Solomon Codes: https://github.com/templexxx/reedsolomon
- Beehive: Erasure Codes for Fixing Multiple Failures in Distributed Storage Systems
白山简介
白山云科技有限公司(简称“白山”)是中国首家云链服务提供商,为客户提供高效数据内容应用与交换的定制化服务。
白山率先在国内引入云链服务(CCX),包括云分发、云存储、云聚合。其核心是建立数据的连接,基于客户对数据内容的高速传输、冷热存储、应用整合需求,为数据的传输、存储、消费和治理提供全生命周期服务。
自2015年4月成立以来,白山以云分发为切入点,在云服务市场上迅速崛起,首款云分发产品CDN-X引领行业创新。2016年6月,白山发布云存储CWN-X,作为云链第二款产品,其分级式对象存储,专注于热数据的存储及存储间的数据转移,广受市场好评。 2017年5月,白山推出云聚合CLN-X,抢先布局云后市场,与CDN-X、CWN-X共同构成云链服务体系,助力经济数字化转型。
2016年3月,白山美国公司成立,以此为战略支点,辐射全球市场。目前,白山服务于微软、央视、小米、美团、中船重工、国美金融等四百余家行业领先客户。
转载于:https://my.oschina.net/u/3468210/blog/1935514
Better than better,白山EC2.0发布相关推荐
- 开源的云计算开发包:Apache jclouds 1.8.0发布
Apache jclouds是一个开源的云计算Java开发工具包,能够帮助开发者进行云计算应用开发,并可重用已有的Java和Clojure技能.jclouds提供了云计算环境的可移植抽象层以及云规范特 ...
- AutoK3s v0.5.0 发布 延续简约和友好
作者简介 鞠宏超,SUSE SW Engineering,6 年云计算领域经验,先后参与了 Longhorn 产品研发.Rancher2.x 产品研发,目前主要致力于 Rancher 企业版产品设计与 ...
- Boost 1.53.0 发布,可移植的C++标准库
Boost 1.53.0 发布了,包含了 5 个新的库,修复了一些安全漏洞以及 Boost.Locale 组件的 bug . 新增的 5 个库包括: Boost.Atomic Boost.Corout ...
- java 开源sns_JEESNS V1.0发布,JAVA 开源 SNS 社交系统
JEESNS V1.0 发布了,本次更新内容: 增加后台管理员授权与取消功能 增加私信模块 解决在微博页面,左侧微博点赞过后,左侧展示列表小手会变黑,但是右侧热门出小手依然是白色 修复后台添加栏目.文 ...
- EOSIO Dawn 4.0 发布
链客,专为开发者而生,有问必答! 此文章来自区块链技术社区,未经允许拒绝转载. 关于Dawn 4.0 RAM分配的反馈 一些社区成员表示担心,在其他任何人发现之前,有些人会通过购买便宜的内存来获得不合 ...
- Element 2.6.0 发布,基于 Vue 2.0 的桌面端组件库
开发四年只会写业务代码,分布式高并发都不会还做程序员? Element 2.6.0 发布了,Element 是一套为开发者.设计师和产品经理准备的基于 Vue 2.0 的桌面端组件库,提供了配套设 ...
- Git 2.25.0发布,支持部分clone、稀疏checkout
点击上方"方志朋",选择"设为星标" 回复"666"获取新整理的面试资料 作者 | oschina 来源 | https://www.osc ...
- Sequelize 4.43.0 发布,基于 Nodejs 的异步 ORM 框架
Sequelize 4.43.0 发布了,Sequelize 是一款基于 Nodejs 的异步 ORM 框架,它同时支持 PostgreSQL.MySQL.SQLite 和 MSSQL 多种数据库,很 ...
- pxeconfig 4.2.0 发布,PXE 首要启动设备
pxeconfig 4.2.0 发布了,pexconfig 可以让你使用支持 PXE 的网卡作为系统的首要启动设备.该软件包括 PXE 菜单工具用于控制网络计算机直接在 BIOS 级别上从控制台上启动 ...
- Ionic 4.3.0 发布,移动应用开发框架
Ionic 4.3.0 发布了,Ionic 是一个高级的 HTML5 移动端应用框架,也是一个开发混合移动应用的前端框架. Bug 修复 action-sheet:默认按钮清空数组(9e63947) ...
最新文章
- 关于MySQL的酸与MVCC和面试官小战三十回合
- 3项目在ie11浏览器打不开_Chrome/Safari都输了:新Edge浏览器率先实现100%支持HTML5...
- curl 命令行下载工具使用方法小结
- 访问远程数据库,把远程数据库当做本地库来用
- c语言保存图片image,iOS 保存图片到【自定义相册】
- 一道关于比赛胜负的Sql查询题目
- pytorch实现Dropout与正则化防止过拟合
- 面向对象的特征有哪些方面?
- java swing 如何设置按钮大小_Java Swing - Button不改变宽度的大小
- silverlight 自定义资源整理(待后续补充)
- vscode 5500 but failed to open in Browser Preview. Got Browser Preview extension installed?
- 中间人攻击 - 攻防
- 三维重建笔记_三维重建方法导图
- 最近在做的一个项目,利用FFMpeg合并视频时发现的问题及解决方法
- 80端口为什么要备案_搞网站的你,不了解一下共享虚拟主机和备案问题
- 什么叫定向广告?定向传播有哪些好处
- 高性能diffpatch算法 -- 如何将微信Apk的官方增量包20.4M缩小到7.0M
- 深度学习与自然语言处理(1)_斯坦福cs224d Lecture 1
- Ubuntu 20.04 LTS (Focal Fossa) OVF 模板下载 百度网盘
- post请求https安全证书问题