Accumulator Proof解析
最近在看libra的数据结构,发现AccountState的结构在proto中的定义如下
message AccountStateWithProof {uint64 version = 1;AccountStateBlob blob = 2;AccountStateProof proof = 3;
}其中的AccountStateProof的定义:
message AccountStateProof {AccumulatorProof ledger_info_to_transaction_info_proof = 1;TransactionInfo transaction_info = 2;SparseMerkleProof transaction_info_to_account_proof = 3;
}这里出现了两种proof,分别是AccumulatorProof和SparseMerkleProof,恰好对应libra中的Accumulator和Sparse Merkle Tree。关于Accumulator 和Sparse Merkle Tree的结构会在后续文章中详细解读,这里简单介绍下。我们知道,libra中弱化了block的概念,可以看做是一个带版本的数据库,这里的版本号就是transaction的序号,那么这个数据库在逻辑中是如何存储的呢?下图简单的说明了这个问题,Ledger History是一个Merkle Tree Accumulator结构,每当有transaction被commit后,该交易以及与这个交易相关的信息(TransactionInfo)就会append到Accumulator中,这个Accumulator可以看做是一颗二叉树,如果全部展开就是一个完全二叉树,每个transaction都会被当做leaf节点append到树中。TransactionInfo包含了原始交易(Signed Transaction)以及该交易造成的账本状态(Ledger State)还有其输出信息(Event Tree),这里的Ledger State是一个Sparse Merkle Tree,这棵树我们可以暂时将他当做是Ethereum中的MPT(其实基本上差不多,逻辑结构很相似)。
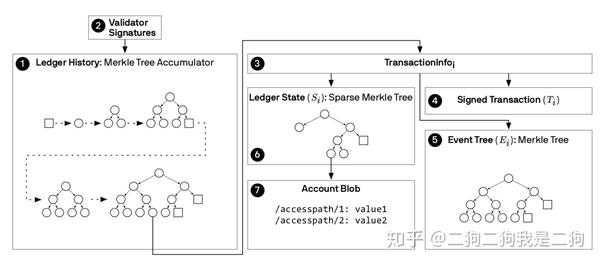
OK,背景介绍完了,接下来开始正题。
首先,我们需要知道为啥要Proof。我们知道,libra中有两种角色validator和client。client会向validator查询数据,那么如何保证validator给client的数据是可信的呢,以及client如何快速验证?
对于上述问题,我们形式化的表述成,client在只存储了小量的验证数据 ,validator存储了全量数据
,现在client通过函数
请求了validator的数据,那么validator返回哪些数据可以让client进行验证其可信?
假设client请求的数据为 ,显然validator只返回结果
是无法自证真伪的,需要增加些验证数据
,那么如何设计这个
就比较关键了。我们结合白皮书的图来分析下。
显然此时的validator的全量数据包括了 ,若client请求的数据为
,那么validator返回的
只要包含
即可。当client接受到上述数据后,只需要计算验证是否相等即可
。
为什么这样就能验证?因为validator如果作假 返回值 ,那么意味着需要构造
来满足上述的验证计算,显然这个难度是非常大的。

理论上分析完了,接下来看libra是如何实现的。
我们看下AccumulatorProof的定义
message AccumulatorProof {// The bitmap indicating which siblings are default. 1 means non-default and// 0 means default. The LSB corresponds to the sibling at the bottom of the// accumulator. The leftmost 1-bit corresponds to the sibling at the level// just below root level in the accumulator, since this one is always// non-default.uint64 bitmap = 1;// The non-default siblings. The ones near the root are at the beginning of// the list.repeated bytes non_default_siblings = 2;
}意思大致就是,通过bitmap来表示是否为default,这里的non default其实就是上面的验证集 ,因为Accumulator 完全展开其实是一个完全二叉树,显然会有一些是空节点,libra将这些空节点当做是default了,因为值是可以确定的。
下面手画的这个图,是一个简单的Accumulator,假设当前Transaction序号为12,,那么leaf节点就是小圆圈,方框表示空节点,这个是逻辑上的,实际存储中是不会存在的。假设我们要取12这个数据,那么proof就是外面有方框的那几个节点的hash。因为13是空节点,所以是default值,因此不需要了,接着从root开始往下每一层都贡献一个hash。左节点表示0,右节点表示1,这两个hash的位置就是:0,10.
那么,如果此时Transaction的序号是13,那么proof就是:0,10,1100。
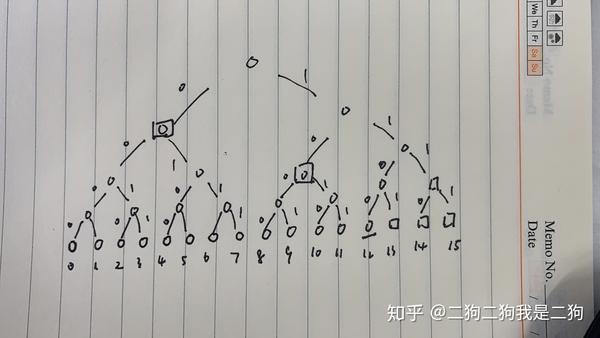
那么这里的规律是啥,因为最终是按照完全二叉树来展开的,所以non default 和default其实都是确定的。最终non default数量就是序号的二进制表示的1的数量。
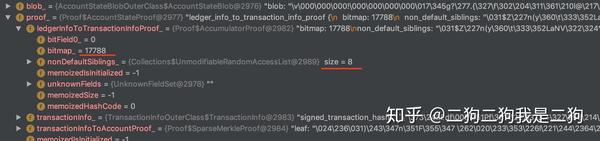
我们实际获取下libra测试网的数据进行下验证,此时序号是17788,二进制表示100010101111100,1的数量是8,符合的。
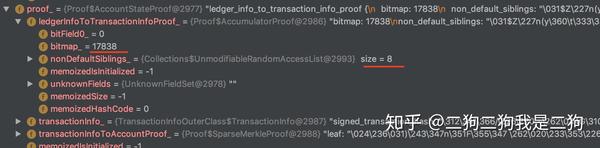
再来一个,序号是17838,二进制是100010110101110,8个,符合的。
嗯,libra的Accumulator设计的还是蛮不错的,后续会分析下Accumulator和sparse Merkle tree的CURD操作啥的。
Accumulator Proof解析相关推荐
- argparse.ArgumentParser()用法解析
argparse.ArgumentParser()用法解析(https://blog.csdn.net/the_time_runner/article/details/97941409) https: ...
- 【Flink】Flink Table SQL 用户自定义函数: UDF、UDAF、UDTF
本文总结Flink Table & SQL中的用户自定义函数: UDF.UDAF.UDTF. UDF: 自定义标量函数(User Defined Scalar Function).一行输入一行 ...
- java rx.observable_Rxjava2 Observable的数据变换详解及实例(二)
1. Window 定期将来自原始Observable的数据分解为一个Observable窗口,发射这些窗口,而不是每次发射一项数据. Window 和 Buffer 类似,但不是发射来自原始Obse ...
- 基于存储证明(Proof of storage)的Permacoin挖矿原理解析
过去的一周让人感觉五味杂陈,心力交瘁,工作非常忙,非常累,非常没有进展,时而芳香,时而谢特,本想着这周末什么也不干撸点没意义的事情度日呢,然而还是觉得把意义拆散来的可靠些.所以依旧很早爬起来总结一下过 ...
- 深度学习目标检测详细解析以及Mask R-CNN示例
深度学习目标检测详细解析以及Mask R-CNN示例 本文详细介绍了R-CNN走到端到端模型的Faster R-CNN的进化流程,以及典型的示例算法Mask R-CNN模型.算法如何变得更快,更强! ...
- 使用 go 实现 Proof of Stake 共识机制
使用 go 实现 Proof of Stake 共识机制 什么是 Proof of Stake 在PoW中,节点之间通过hash的计算力来竞赛以获取下一个区块的记账权,而在PoS中,块是已经铸造好的, ...
- 期刊投稿状态_SCI投稿全过程解析及拒稿后处理对策
之前给大家介绍了如果使用人工智能来提高SCI写作效率的神器,相信大家对SCI写作已经很有信心了.但有些小伙伴后台说对投稿过程很没有概念,不同期刊不同状态.那么今天我们就对SCI投稿过程.投稿状态做一个 ...
- python 命令行 解析模块 optparse、argparse
optparse:https://docs.python.org/zh-cn/3/library/optparse.html argparse :https://docs.python.org/zh- ...
- python命令行解析_python命令行解析函数
sys.argv 在终端运行python 1.py hahah importsysprint(sys.argv) #['1.py', 'hahah'] argparse Python的命令行解析模块, ...
- 怎么证明建立了存储过程_【Filecoin源码仓库全解析】第七章:了解PoRep与PoSt并参与复制证明游戏
欢迎大家来到第七章,经过前章<[Filecoin源码仓库全解析]第六章:如何单机部署多节点集群及矿池设计思路>的介绍,我们分享了如何在单机部署多节点集群的知识以及矿池设计的一些思路. 我们 ...
最新文章
- 如何将CSDN文档输出PDF文件?
- Habana Labs
- Dom onload和jQuery document ready的区别
- cf1555B. Two Tables
- sql数据导入错误代码: 0x80004005_SQL入门第八关 项目实战
- 单值二叉树:如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。 只有给定的树是单值二叉树时,才返回 true;否则返回 false。
- ajax 回调数据 刷新table_Ajax gt;gt;gt; 001
- java正则表达式获取书名
- 怎么让笔记本变路由器,亲身试验可用,不用下第三方软件
- [音乐]阿桑的《叶子》
- 安卓小游戏之2048
- 怎么用matlab求特征向量,MATLAB用eig()函数求【特征值】【特征向量】【归一化
- 又双叒叕夺冠!5年厚积薄发,汇佳学校绿龙冰球队今夏“京城双冠王”!
- C#应用程序退出后托盘图标(notify…
- H3C光模块相关命令和检测方法
- UTC时间与北京时间相互转换
- 【Python】利用tkinter开发测手速小游戏
- 程序员如何准备技术面试
- Eclipse 免安装(便携版)从官网如何下载
- 联想台式计算机编号怎么查,联想电脑怎么查看主机编号_联想电脑编号在哪里...