CVPR 2018摘要:第二部分
转自:https://yq.aliyun.com/news/294835
本文为 AI 研习社编译的技术博客,原标题:
NeuroNuggets: CVPR 2018 in Review, Part II
作者 |Sergey Nikolenko、Aleksey Artamonov
翻译 |老赵 校对 |酱番梨
整理| 菠萝妹
原文链接:
https://medium.com/neuromation-io-blog/neuronuggets-cvpr-2018-in-review-part-ii-4759fd95f65c
注:本文的相关链接请点击文末【阅读原文】进行访问
NeuroNuggets:CVPR 2018年回顾,第二部分
今天,我们继续推出最近的CVPR(计算机视觉和模式识别)会议系列,这是世界上计算机视觉的顶级会议。Neuromation成功参加了DeepGlobe研讨会,现在我们正在看主会议的论文。 在我们的CVPR回顾的第一部分,我们简要回顾了有关计算机视觉的生成对抗网络(GAN)的最有趣的论文。 这一次,我们深入研究了将计算机视觉应用于我们人类的工作:跟踪视频中的人体和其他物体,估计姿势甚至是完整的3D体形,等等。 同样,论文没有特别的顺序,我们的评论非常简短,所以我们绝对建议完整阅读论文。
人物:人物识别,跟踪和姿势估计
人类非常擅长识别和识别其他人类,而不是识别其他物体。特别是,大脑的一个特殊部分,称为梭状回,被认为含有负责面部识别的神经元,并且这些神经元被认为与识别其他事物的神经元有所不同。这就是那些关于颠倒的面孔(撒切尔效应)的幻想来自的地方,甚至还有一种特殊的认知障碍,即失语症,一个人失去了识别人类面孔的能力......但仍然很好地识别桌子,椅子,猫或英文字母。当然,这并不是很清楚,并且可能没有特定的“个体面部神经元”,但面部肯定是不同的。人类一般(它们的形状,轮廓,身体部位)在我们的心灵和大脑中也有一个非常特殊的位置:我们大脑的“基本形状”可能包括三角形,圆形,矩形......和人体轮廓。
人类认知是人类的核心问题,因此它一直是计算机视觉。 早在2014年(很久以前在深度学习中),Facebook声称在人脸识别方面达到了超人的表现,而且不管当代的批评现在我们基本上可以认为人脸识别确实很好地解决了。 但是,仍然有许多任务; 例如,我们已经发布了关于年龄和性别估计以及人类姿势估计的文章。 在CVPR 2018上,大多数与人类相关的论文要么是关于在3D中寻找姿势,要么是关于在视频流中跟踪人类,这正是我们今天所关注的。 为了更好地衡量,我们还回顾了一些关于物体跟踪的论文,这些论文与人类没有直接关系(但人类肯定是最有趣的科目之一)。
检测和跟踪:具有姿态估计的两步跟踪
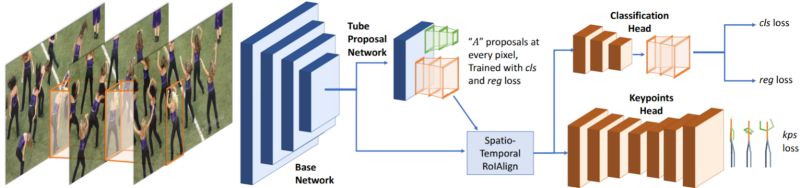
R. Girdhar等人,“检测与跟踪:视频中的高效姿态估计”

我们已经利用Mask R-CNN实现分割,这是2017年出现的最有前途的分割方法之一。去年,基本的Mask R-CNN的几个扩展和修改出现了,卡内基梅隆的合作, Facebook和Dartmouth提出了另一个:作者提出了一个3D Mask R-CNN架构,该架构使用时空卷积来提取特征并直接识别短片上的姿势。 然后他们继续展示以3D Mask R-CNN作为第一步的两步算法(以及将关键点预测作为第二步链接的二分匹配)击败姿势估计和人类跟踪中的现有技术方法。 以下是3D Mask R-CNN架构,肯定会在未来找到更多应用:
用于人员重新识别的敏感姿态嵌入
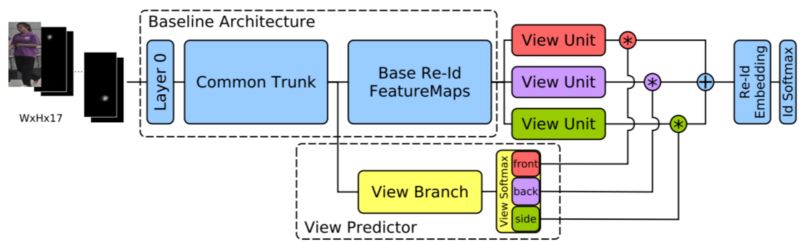
M. Saquib Sarfraz等人,利用扩充的领域重分级敏感姿态嵌入的人员重识别

人员重新识别是计算机视觉中的一个具有挑战性的问题:如上所示,摄像机视图和姿势的变化可能使两张图片完全不同(尽管我们人类仍然立即发现这是同一个人)。 该问题通常通过基于检索的方法来解决,该方法导出查询图像与来自某个嵌入空间的存储图像之间的邻近度量。 德国研究人员的这项工作提出了一种将姿势信息直接纳入嵌入的新方法,从而改善了重新识别结果。 这是一个简短的概述图,但我们建议你完整阅读本文,以了解如何将姿势添加到嵌入中:
单张图像的3D姿势:从2D姿势和2D轮廓构造3D网格
G. Pavlakos等人,从单一彩色图像学习估计3D人体姿势和形状
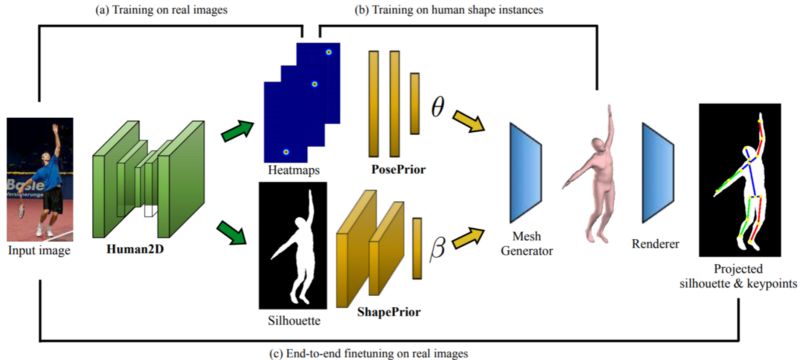
姿态估计是一个众所周知的问题; 我们之前已经写过这篇文章并在本文中已经提到过。 然而,制作完整的3D人体形状是另一回事。 这项工作提出了一个非常有希望和非常令人惊讶的结果:它们直接通过端到端卷积结构生成人体的3D网格,该结构结合了姿势估计,人体轮廓分割和网格生成(见上图)。 这里的关键见解是基于使用SMPL,一种统计的身体形状模型,为人体形状提供了良好的先验。 因此,这种方法设法从单一彩色图像构建人体的3D网格。以下是一些说明性结果,包括标准UP-3D数据集中的一些非常具有挑战性的案例:

FlowTrack:关注视频并关注相关跟踪
Z. Zhu等,具有时空注意力的端到端流动相关跟踪
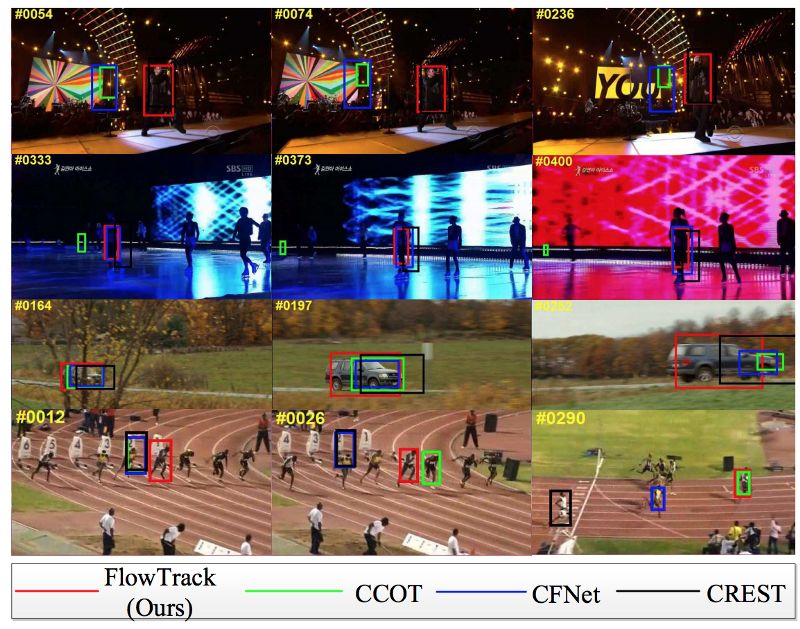
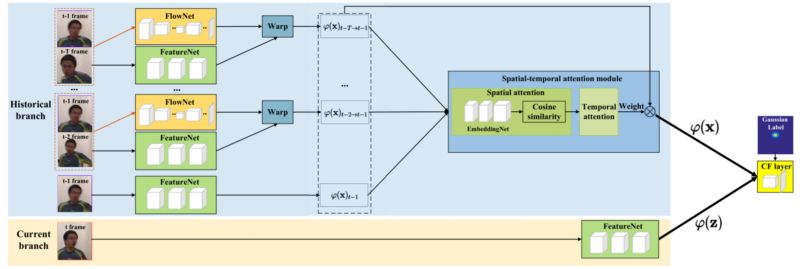
判别相关滤波器(DCF)是用于对象跟踪的现有技术学习技术。 我们的想法是学习一个过滤器 - 即图像窗口的转换,通常只是一个卷积 - 它对应于你想要跟踪的对象,然后将其应用于视频中的所有帧。 正如经常发生在神经网络中一样,DCF远非一个新的想法,可追溯到1980年的一篇开创性论文,但它们几乎被遗忘到2010年;MOSSE跟踪器开始复兴,现在DCF风靡一时。 然而,经典DCF不利用实际视频流并分别处理每个帧。 在这项工作中,中国研究人员提出了一种建筑,其中涉及能够跨越不同时间框架参与的时空关注机制; 他们报告了大大改善的结果。以下是他们模型的一般流程:
回到经典:相关跟踪
C.Suni等人,通过联合歧视和可靠性学习进行相关跟踪
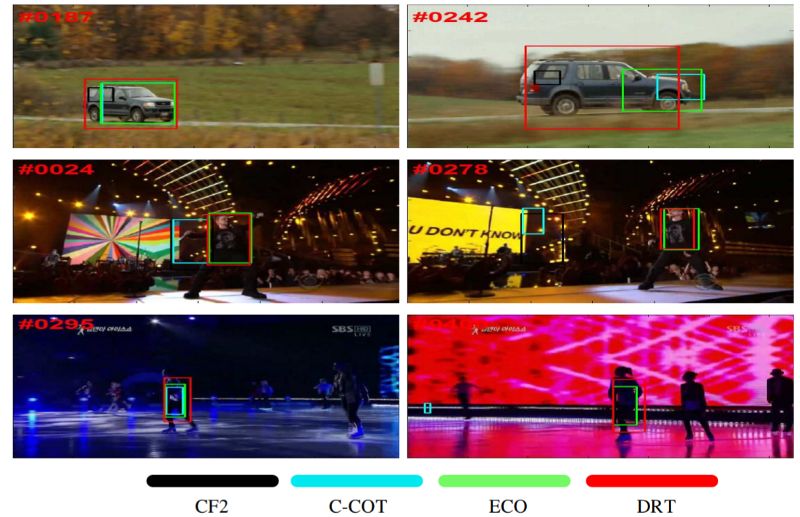
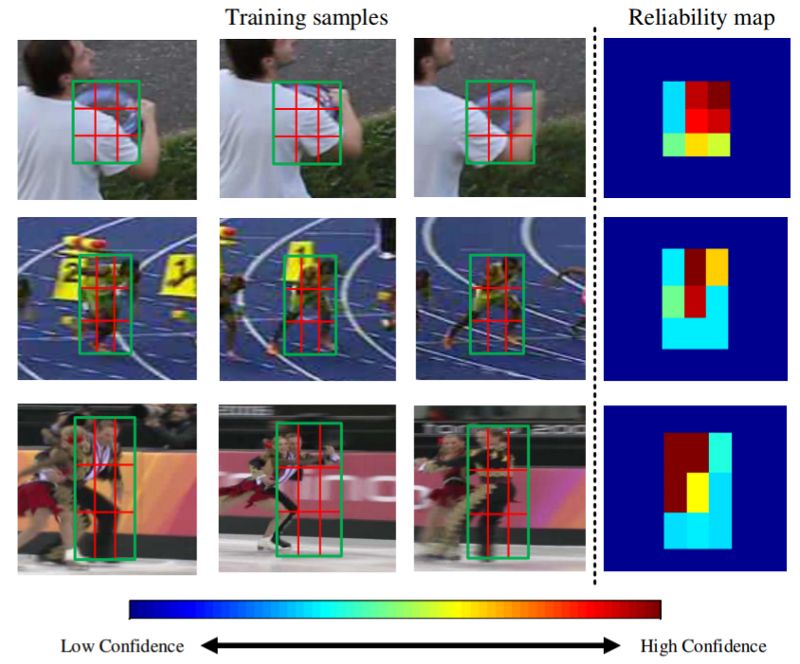
与前一篇文章一样,本文致力于跟踪视频中的对象(目前这是一个非常热门的话题),就像前一篇一样,它使用相关过滤器进行跟踪。 但是,与前一个形成鲜明对比的是,本文并没有使用深度神经网络。这里的基本思想是在模型中明确地包括可靠性信息,即,向目标函数添加一个术语,该目标函数模拟学习过滤器的可靠性。 作者报告显着改进了跟踪,并显示了经常看起来非常合理的学习可靠性图:
这就是所有的文章,朋友们。
感谢您的关注。下次加入我们 - 来自CVPR 2018的更多有趣的论文......而且,就像偷看一样,ICLR 2019截止日期已经过去,其提交的论文已经上线,虽然我们不知道哪些可以接受更多 几个月我们已经在看他们了。
Sergey NikolenkoChief Research Officer, Neuromation
Aleksey ArtamonovSenior Researcher, Neuromation
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1194
CVPR 2018摘要:第二部分相关推荐
- CVPR 2018摘要:第五部分
转自:http://ai.yanxishe.com/page/TextTranslation/1241 英文原文:What's In a Face (CVPR in Review V) 标签: 图像描 ...
- CVPR 2018摘要:第五部分
标题 What's In a Face (CVPR in Review V) CVPR 2018摘要:第五部分 by 啦啦啦2 01 What's In a Face (CVPR in Review ...
- CVPR 2018摘要:第一部分
原文链接:CVPR GAN部分 本文为 AI 研习社编译的技术博客,原标题 :NeuroNuggets: CVPR 2018 in Review, Part I作者 | Sergey Nikolenk ...
- CVPR 2018 | 腾讯AI Lab关注的三大方向与55篇论文
感谢阅读腾讯 AI Lab 微信号第 32 篇文章,CVPR 2018上涌现出非常多的优秀论文,腾讯 AI Lab 对其中精华文章归类与摘要,根据受关注程度,对生成对抗网络.视频分析与理解和三维视觉三 ...
- CVPR 2018 | ETH Zurich提出利用对抗策略,解决目标检测的域适配问题
CVPR 2018 | ETH Zurich提出利用对抗策略,解决目标检测的域适配问题 原创: Panzer 极市平台 今天 ↑ 点击蓝字关注极市平台 识别先机 创造未来 论文地址:https://a ...
- CVPR 2018 | TVNet:可端到端学习视频的运动表征
"来自腾讯 AI Lab.MIT.清华.斯坦福大学的研究者完成并入选 CVPR 2018 Spotlight 论文的一项研究提出了一种能从数据中学习出类光流特征并且能进行端到端训练的神经网络 ...
- CVPR 2018 论文解读集锦(9月26日更新)
本文为极市平台原创收集,转载请附原文链接: https://blog.csdn.net/Extremevision/article/details/82757920 CVPR 2018已经顺利闭幕,目 ...
- CVPR2019接收结果公布了,但CVPR 2018的那些论文都怎么样了?
CVPR 作为计算机视觉三大顶级会议之一,一直以来都备受关注.被 CVPR 收录的论文更是代表了计算机视觉领域的最新发展方向和水平.今年,CVPR 2019 将于美国洛杉矶举办,上个月接收结果公布后, ...
- CVPR 2018 论文解读 | 基于GAN和CNN的图像盲去噪
作者丨左育莘 学校丨西安电子科技大学 研究方向丨计算机视觉 图像去噪是low-level视觉问题中的一个经典的话题.其退化模型为 y=x+v,图像去噪的目标就是通过减去噪声 v,从含噪声的图像 y 中 ...
最新文章
- JavaScript学习笔记 - 入门篇(1)- 准备
- 中国电子学会青少年编程能力等级测试图形化四级编程题:太空大战
- Python之路,day3-Python基础
- Linux查看所有用户和组信息
- Vue.js 列表渲染
- CMMI之需求管理和股票池管理
- 斯坦福助理教授马腾宇:ML非凸优化很难,如何破?
- 2020年8月编程语言排行榜新鲜出炉 - 编程语言世界的假期
- AutoConfigurationImportSelector是什么?
- Java基础之写文件——缓冲区中的多条记录(PrimesToFile3)
- php判断桌面宽度,js获取页面宽度高度及屏幕分辨率
- Java核心API需要掌握的程度
- C语言 strcat_s 函数 - C语言零基础入门教程
- Ztree手风琴效果(第三版)
- 【python工具篇】pip和pypi
- 知乎回答:为什么微博很难起到社交的作用?
- redis学习——数据持久化
- 编写可维护的 JavaScript
- java高级教程pdf_《Java高级编程实用教程》PDF 下载_IT教程网
- 在线标准程序员计算器