python 视频语音转文字_使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频
安装 moviepy
pip install moviepy
相关代码:
audio_file = work_path + '\\out.wav'
video = VideoFileClip(video_file)
video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1'])
根据静音对音频分段
使用音频库 pydub,安装:
pip install pydub
第一种方法:
# 这里silence_thresh是认定小于-70dBFS以下的为silence,发现小于 sound.dBFS * 1.3 部分超过 700毫秒,就进行拆分。这样子分割成一段一段的。
sounds = split_on_silence(sound, min_silence_len = 500, silence_thresh= sound.dBFS * 1.3)
sec = 0
for i in range(len(sounds)):
s = len(sounds[i])
sec += s
print('split duration is ', sec)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(sounds)))

感觉分割的时间不对,不好定位,我们换一种方法:
# 通过搜索静音的方法将音频分段
# 参考:https://wqian.net/blog/2018/1128-python-pydub-split-mp3-index.html
timestamp_list = detect_nonsilent(sound,500,sound.dBFS*1.3,1)
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
print("Section is :", timestamp_list[i], "duration is:", d)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(timestamp_list)))
输出结果如下:
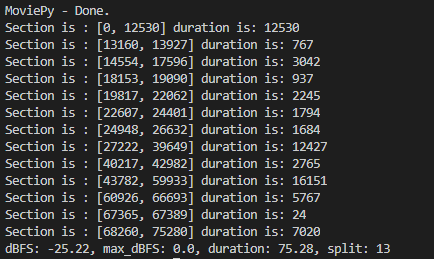
感觉这样好处理一些
使用百度语音识别
现在百度智能云平台创建一个应用,获取 API Key 和 Secret Key:

获取 Access Token
使用百度 AI 产品需要授权,一定量是免费的,生成字幕够用了。
'''
百度智能云获取 Access Token
'''
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode( 'utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req)
result_str = f.read()
except URLError as err:
print('token http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = result_str.decode()
print(result_str)
result = json.loads(result_str)
print(result)
if ('access_token' in result.keys() and 'scope' in result.keys()):
print(SCOPE)
if SCOPE and (not SCOPE in result['scope'].split(' ')): # SCOPE = False 忽略检查
raise DemoError('scope is not correct')
print('SUCCESS WITH TOKEN: %s EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))
return result['access_token']
else:
raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')
使用 Raw 数据进行合成
这里使用百度语音极速版来合成文字,因为官方介绍专有GPU服务集群,识别响应速度较标准版API提升2倍及识别准确率提升15%。适用于近场短语音交互,如手机语音搜索、聊天输入等场景。 支持上传完整的录音文件,录音文件时长不超过60秒。实时返回识别结果
def asr_raw(speech_data, token):
length = len(speech_data)
if length == 0:
# raise DemoError('file %s length read 0 bytes' % AUDIO_FILE)
raise DemoError('file length read 0 bytes')
params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID}
#测试自训练平台需要打开以下信息
#params = {'cuid': CUID, 'token': token, 'dev_pid': DEV_PID, 'lm_id' : LM_ID}
params_query = urlencode(params)
headers = {
'Content-Type': 'audio/' + FORMAT + '; rate=' + str(RATE),
'Content-Length': length
}
url = ASR_URL + "?" + params_query
# print post_data
req = Request(ASR_URL + "?" + params_query, speech_data, headers)
try:
begin = timer()
f = urlopen(req)
result_str = f.read()
# print("Request time cost %f" % (timer() - begin))
except URLError as err:
# print('asr http response http code : ' + str(err.errno))
result_str = err.reason
if (IS_PY3):
result_str = str(result_str, 'utf-8')
return result_str
生成字幕
生成字幕其实就是语音识别的应用,将识别后的内容按照 srt 字幕格式组装起来就 OK 了。具体字幕格式的内容可以参考上面的文章,代码如下:
idx = 0
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
data = sound[timestamp_list[i][0]:timestamp_list[i][1]].raw_data
str_rst = asr_raw(data, token)
result = json.loads(str_rst)
# print("rst is ", result)
# print("rst is ", rst['err_no'][0])
if result['err_no'] == 0:
text.append('{0}\n{1} --> {2}\n'.format(idx, format_time(timestamp_list[i][0]/ 1000), format_time(timestamp_list[i][1]/ 1000)))
text.append( result['result'][0])
text.append('\n')
idx = idx + 1
print(format_time(timestamp_list[i][0]/ 1000), "txt is ", result['result'][0])
with open(srt_file,"r+") as f:
f.writelines(text)
总结
我在视频网站下载了一个视频来作测试,极速模式从速度和识别率来说都是最好的,感觉比网易见外平台还好用。
到此这篇关于使用Python和百度语音识别生成视频字幕的文章就介绍到这了,更多相关Python 百度语音识别生成视频字幕内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
python 视频语音转文字_使用Python和百度语音识别生成视频字幕的实现相关推荐
- python怎么加字幕_使用Python和百度语音识别生成视频字幕的实现
从视频中提取音频 安装 moviepy pip install moviepy 相关代码: audio_file = work_path + '\\out.wav' video = VideoFile ...
- python调用百度语音搜索_使用 Python 和百度语音识别生成视频字幕
从视频中提取音频 安装 moviepy pip install moviepy 相关代码: audio_file = work_path + '\\out.wav' video = VideoFile ...
- 使用 Python 和百度语音识别生成视频字幕
文章目录 从视频中提取音频 根据静音对音频分段 使用百度语音识别 获取 Access Token 使用 Raw 数据进行合成 生成字幕 总结 从视频中提取音频 安装 moviepy pip insta ...
- python 录音本地转文字_用Python将抖音视频转换为字符视频
字符视频就是画面全部由字符组成的, 那么用代码怎么实现的呢?下面用python实现,话不多说,直接上干货. 代码实现详解 其实总体思路分为3个步骤: 1.将原视频分割成若干个图片以及分离出音频 2.将 ...
- python离线语音转文本_使用Python将语音转换为文本的方法
使用Python将语音转换为文本的方法,语音,转换为,文本,您的,麦克风 使用Python将语音转换为文本的方法 易采站长站,站长之家为您整理了使用Python将语音转换为文本的方法的相关内容. 语音 ...
- python 语音转文字_基于python将音频文件转化为文本输出
实验目的:学习利用python进行音频转文本文件 实验环境:已正确安装python3.5 1.需要安装的第三方库 (1)安装speechrecognition speechrecognition集合了 ...
- python批量识别图片中文字_利用Python批量进行图片文字识别
实现逻辑 1. 批量获取图片的路径 2. 通过调用百度OCR接口批量识别图片 3. 将返回值写入txt 实现过程 1. 安装百度的Python SDK pip install baidu-aip 2. ...
- python图片转换成文字_使用Python脚本将文字转换为图片的实例分享
有时候,我们需要将文本转换为图片,比如发长微博,或者不想让人轻易复制我们的文本内容等时候.目前类似的工具已经有了不少,不过我觉得用得都不是很趁手,于是便自己尝试实现了一个. 在 Python 中,PI ...
- python怎么窗口显示文字_用python和pygame游戏编程入门-显示文字
上一节我们通过键盘可以控制角色移动,如果要让角色说话,那就要用到文字显示.Pygame可以直接调用系统字体,或者也可以使用TTF字体,TTF就是字体文件,可以从网上下载.为了使用字体,你得先创建一个F ...
最新文章
- spring boot多环境配置
- Linux 思维导图整理(建议收藏)
- Aspcms框架的webshell
- React开发(135):ant design学习指南之form中动态form新增删除
- python安装到桌面的路径是什么_Python 获取windows桌面路径的5种方法小结
- AI本质就是“暴力计算”?看华为云如何应对算力挑战
- A query was run and no Result Maps were found for the Mapped Statement
- Java基础篇:finalize( )方法的使用
- 凸优化第九章无约束优化 9.2下降方法
- 戴尔台式计算机怎么安装的,戴尔台式机怎么安装无线网卡驱动
- 广州电商行---Just do IT
- CentOS 7 虚拟机网卡失效问题:ens33:<NO-CARRIER,BROADCAST,MULTICAST,UP>mtu 1508 gdisc pf ifo_fast state DOWN
- [NLP]高级词向量表达之Word2vec详解(知识点全覆盖)
- 自学软件测试3个月,原来15K也就这么回事...
- MySQL索引面试题六连击
- 1024@程序员:图灵社区福利来了,请本人签收
- CS61A Proj 3
- Golang实现并发版网络爬虫:捧腹网段子爬取并保存文件
- 脾胃系病证--便秘,痢疾,泄泻,腹痛,呃逆。。。。。。。。
- 爬取博客园首页并定时发送到微信