Flair实战文本分类
2019独角兽企业重金招聘Python工程师标准>>> 
Flair是一个基于PyTorch构建的NLP开发包,它在解决命名实体识别(NER)、语句标注(POS)、文本分类等NLP问题时达到了当前的顶尖水准。本文将介绍如何使用Flair构建定制的文本分类器。
简介
文本分类是一种用来将语句或文档归入一个或多个分类的有监督机器学习方法,被广泛应用于垃圾邮件过滤、情感分析、新文章归类等众多业务领域。
当前绝大多数领先的文本分类方法都依赖于文本嵌入技术,它将文本转换为高维空间的数值表示,可以将文档、句子、单次或字符表示为这个高维空间的一个向量。
Flair基于Zalando Research的论文“用于串行标准的上下文相关字符串嵌入”,论文算法表现可以毙掉之前的最好方案,该算法在Flair中得到完整实现,可以用来构建文本分类器。
1. 准备
Flair安装需要Python 3.6,执行pip安装即可:
~$ pip install flair
上面的命令将安装运行Flair所需要的依赖包,当然也包括了PyTorch。
2. 使用训练好的预置分类模型
最新的Flair 0.4版本包含有两个预先训练好的模型。一个基于IMDB数据集训练的情感分析模型和一个攻击性语言探测模型(当前仅支持德语)。
只需一个命令就可以下载、存储并使用模型,这使得预置模型的使用过程异常简单。例如,下面的代码将使用情感分析模型:
from flair.models import TextClassifier
from flair.data import Sentenceclassifier = TextClassifier.load('en-sentiment')sentence = Sentence('Flair is pretty neat!')
classifier.predict(sentence)# print sentence with predicted labels
print('Sentence above is: ', sentence.labels)
当第一次运行上述代码时,Flari将下载情感分析模型,默认情况下会保存到本地用户主目录的.flair子目录,下载可能需要几分钟。
上面的代码首先载入必要的库,然后载入情感分析模型到内存中(必要时先下载),接下来 就可以预测“Flair is pretty neat!”的情感分值了(0~1之间)。最后的命令输入结果为:
The sentence above is: [Positive (1.0)].
就是这么简单!现在你可以将上述代码整合为一个REST API,提供类似于google云端情感分析API的功能了!
3. 训练自定义文本分类器
要训练一个自定义的文本分类器,首先需要一个标注文本集。Flair的分类数据集格式基于Facebook的FastText格式,要求在每一行的开始使用**label**前缀定义一个或多个标签。格式如下:
__label__<class_1> <text>
__label__<class_2> <text>
在这篇文章中我们将使用Kaggle的SMS垃圾信息检测数据集来用Flair构建一个垃圾/非垃圾分类器。这个数据集很适合我们的学习任务,因为它很小,只有5572行数据,可以在单个CPU上只花几分钟就完成模型的训练。
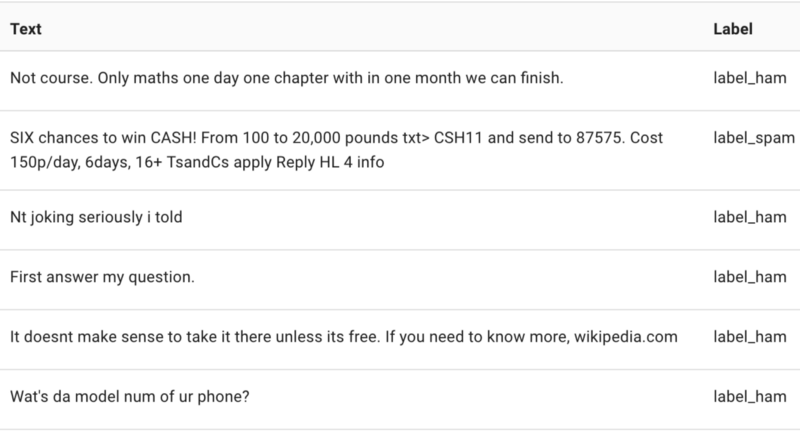
3.1 预处理 - 构建数据集
首先下载Kaggle上的数据集,得到spam.csv;然后再数据集目录下,运行我们的处理脚本,得到训练集、开发集和测试集:
import pandas as pd
data = pd.read_csv("./spam.csv", encoding='latin-1').sample(frac=1).drop_duplicates()data = data[['v1', 'v2']].rename(columns={"v1":"label", "v2":"text"})data['label'] = '__label__' + data['label'].astype(str)data.iloc[0:int(len(data)*0.8)].to_csv('train.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.8):int(len(data)*0.9)].to_csv('test.csv', sep='\t', index = False, header = False)
data.iloc[int(len(data)*0.9):].to_csv('dev.csv', sep='\t', index = False, header = False);
上面的脚本会进行剔重和随机乱序处理,并按照80/10/10的比例进行数据集的分割。脚本成功执行后,就会得到FastText格式的三个数据文件:train.csv、dev.csv和test.csv。
3.2 训练自定义文本分类模型
用下面的脚本训练模型:
from flair.data_fetcher import NLPTaskDataFetcher
from flair.embeddings import WordEmbeddings, FlairEmbeddings, DocumentLSTMEmbeddings
from flair.models import TextClassifier
from flair.trainers import ModelTrainer
from pathlib import Pathcorpus = NLPTaskDataFetcher.load_classification_corpus(Path('./'), test_file='train.csv', dev_file='dev.csv', train_file='test.csv')word_embeddings = [WordEmbeddings('glove'), FlairEmbeddings('news-forward-fast'), FlairEmbeddings('news-backward-fast')]document_embeddings = DocumentLSTMEmbeddings(word_embeddings, hidden_size=512, reproject_words=True, reproject_words_dimension=256)classifier = TextClassifier(document_embeddings, label_dictionary=corpus.make_label_dictionary(), multi_label=False)trainer = ModelTrainer(classifier, corpus)trainer.train('./', max_epochs=20)
第一次运行上面这个脚本时,Flair会自动下载所需要的嵌入模型,这可能需要几分钟,然后接下来的整个训练过程还需要大约5分钟。
脚本首先载入需要的库和数据集,得到一个corpus对象。
接下来,我们创建一个嵌入列表,包含两个Flair上下文字符串嵌入和一个GloVe单词嵌入,这个列表接下来将作为我们文档嵌入对象的输入。堆叠和文本嵌入是Flair中最有趣的感念之一,它们提供了将不同的嵌入整合在一起的手段,你可以同时使用传统的单词嵌入(例如GloVe、word2vector、ELMo)和Flair的上下文字符串嵌入。在上面的示例中我们使用一个基于LSTM的方法来生成文档嵌入,关于该方法的详细描述可以参考这里。
最后,上面的代码训练模型并生成两个模型文件:final-model.pt和best-model.pt。
3.3 用训练好的模型进行预测
现在我们可以使用导出的模型进行预测了。脚本如下:
from flair.models import TextClassifier
from flair.data import Sentenceclassifier = TextClassifier.load_from_file('./best-model.pt')sentence = Sentence('Hi. Yes mum, I will...')classifier.predict(sentence)print(sentence.labels)
上面的代码输出如下:
[ham (1.0)]
这意味着模型100%的确信我们输入的示例消息不是垃圾信息。
Flair是如何超越其他框架的?
与Facebook的FastText或者Google的AutoML平台不同,用Flair进行文本分类还是相对底层的任务。我们可以完全控制文本如何嵌入,也可以设置训练的参数例如学习速率、批大小、损失函数、优化器选择策略等,这些超参数是要实现最优性能所必须进行调整的。Flair提供了著名的超参数调整库Hyperopt的一个封装。
在这篇文章中,出于简化考虑我们使用了默认的超参数,得到的Flair模型的f1-score在20个epoch之后达到了0.973。
为了对比,我们使用FastText和AutoML训练了一个文本分类器。我们首先使用默认参数运行 FastText,得到的f1-score为0.883,这意味着我们的Flair模型远远优于FastText模型,不过FastText的训练很快,只需要几秒钟。
然后我们也与AutoML自然语言平台上得到的结果进行了对比。平台首先需要20分钟来 解析数据集,然后我们启动训练过程,这大约花了3个小时才完成,但是f1-score达到了 99.211,要稍好于我们自己训练的Flair模型。
原文链接:用Flair进行文本分类 - 汇智网
转载于:https://my.oschina.net/u/3794778/blog/2993209
Flair实战文本分类相关推荐
- 用最新NLP库Flair做文本分类
摘要: Flair是一个基于PyTorch构建的NLP开发包,它在解决命名实体识别(NER).部分语音标注(PoS).语义消歧和文本分类等NLP问题达到了当前的最高水准.它是一个建立在PyTorch之 ...
- 用最新NLP库Flair做文本分类 1
介绍 文本分类是一种监督机器学习方法,用于将句子或文本文档归类为一个或多个已定义好的类别.它是一个被广泛应用的自然语言处理方法,在垃圾邮件过滤.情感分析.新闻稿件分类以及与许多其它业务相关的问题中发挥 ...
- Bert实战--文本分类(一)
使用Bert预训练模型进行文本分类 bert做文本分类,简单来说就是将每句话的第一个位置加入了特殊分类嵌入[CLS].而该[CLS]包含了整个句子的信息,它的最终隐藏状态(即,Transformer的 ...
- 实战文本分类对抗攻击
文章写得比较长,先列出大纲,以便读者直取重点. "文本分类对抗攻击"是清华大学和阿里安全2020年2月举办的一场AI比赛,从开榜到比赛结束20天左右,内容是主办方在线提供1000条 ...
- 《基于Tensorflow的知识图谱实战》 --- 实战文本分类与命名实体识别,快速构建知识图谱(王晓华 著)
⚽开发平台:jupyter lab
- 用Flair(PyTorch构建的NLP开发包)进行文本分类
Flair是一个基于PyTorch构建的NLP开发包,它在解决命名实体识别(NER).语句标注(POS).文本分类等NLP问题时达到了当前的顶尖水准.本文将介绍如何使用Flair构建定制的文本分类器. ...
- R语言构建文本分类模型并使用LIME进行模型解释实战:文本数据预处理、构建词袋模型、构建xgboost文本分类模型、基于文本训练数据以及模型构建LIME解释器解释多个测试语料的预测结果并可视化
R语言构建文本分类模型并使用LIME进行模型解释实战:文本数据预处理.构建词袋模型.构建xgboost文本分类模型.基于文本训练数据以及模型构建LIME解释器解释多个测试语料的预测结果并可视化 目录
- 【英文文本分类实战】之四——词典提取与词向量提取
·请参考本系列目录:[英文文本分类实战]之一--实战项目总览 ·下载本实战项目资源:神经网络实现英文文本分类.zip(pytorch) [1] 提取词典 在这一步,我们需要把训练集train.cs ...
- 【英文文本分类实战】之三——数据清洗
·请参考本系列目录:[英文文本分类实战]之一--实战项目总览 ·下载本实战项目资源:神经网络实现英文文本分类.zip(pytorch) [1] 为什么要清洗文本 这里涉及到文本分类任务中:词典.词 ...
最新文章
- 使用Python从PDF导出数据
- java线程 打印_java多线程实现 5秒一次打印当前时间
- 9.java.lang.ClassCastException
- 中科燕园GIS外包-----基于ArcGIS的应急平台
- ci mysql高并发_高并发访问mysql时的问题(一):库存超减
- 我说程序员要测试自己的代码,结果被怼!
- 微服务主见传递ID还是json_后台管理系统之微服务搭建
- python迭代器是什么意思_理解Python的迭代器
- 为什么要使用 React-Redux?
- 0基础学python做什么工作好-写给0基础小白:Python能干什么?就业前景好不好?怎么开始学?...
- sqlite C#
- 梅花雨的日历控件在ASP.NET2.0下不可用的解决方法
- hibernate 反向生实体类 and 为什么老是多一个id
- 白话阿里巴巴Java开发手册高级篇
- Java排序算法-桶排序
- 交中IB课程中心2022届早申阶段录取成果汇总
- 关于计算机系调查问卷表,计算机系统调查问卷.xls
- 【程序人生】“阶段总结“-幕天席地
- 中国互联网金融:浪潮还是浪花?
- DOS批处理高级教程(一) 批处理基础