elasticsearch中文IK+Pinyin分词器
2019独角兽企业重金招聘Python工程师标准>>> 
一、IK分词器安装
1.分词器的作用
分词顾名思义,就是把一句话分成一个一个的词。这个概念在搜索中很重要,比如 This is a banana. 如果按照普通的空格来分词,分成this,is,a,banana,的出来的a其实对我们并没有什么用处。因此需要注意下面的问题:
- 1 区分停顿词(
a,or,and这种都属于停顿词) - 2 大小写转换(
Banana与banana) - 3 时态的转换....
具体的算法可以参考http://tartarus.org/~martin/PorterStemmer/,对照的词语可以参考这里http://snowball.tartarus.org/algorithms/porter/diffs.txt
相比中文,就复杂的度了。因为中文不能单纯的依靠空格,标点这种进行分词。就比如中华人民共和国国民,不能简单的分成一个词,也不能粗暴的分成中华人民共和国和国民,人民、中华这些也都算一个词!
因此常见的分词算法就是拿一个标准的词典,关键词都在这个词典里面。然后按照几种规则去查找有没有关键词,比如:
- 正向最大匹配(从左到右)
- 逆向最大匹配(从右到左)
- 最少切分
- 双向匹配(从左扫描一次,从右扫描一次)
IK,elasticsearch-analysis-ik提供了两种方式,ik_smart就是最少切分,ik_max_word则为细粒度的切分(可能是双向,没看过源码)
2.安装
了解了分词器的背景后,就可以看一下如何在Elasticsearch重安装分词器了。
ik GitHub地址:https://github.com/medcl/elasticsearch-analysis-ik
插件包地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
安装方式:
1.解压对应版本的插件包到 your-es-directory/plugins/ik,重启es就ok;
2.下载源码,将编译好的jar包导入到 your-es-directory/plugins/ik,重启es就ok;
注意:es 与 ik版本一定要对应。
二、IK分词器使用测试
1.create a index
curl -XPUT http://localhost:9200/ik_index
2.create a mapping
curl -XPOST http://localhost:9200/ik_index/fulltext/_mapping
{"properties": {"content": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"}}}
3.index some docs
curl -XPOST http://localhost:9200/index/fulltext/1 -d'
{"content":"美国留给伊拉克的是个烂摊子吗"}
'
curl -XPOST http://localhost:9200/index/fulltext/2 -d'
{"content":"公安部:各地校车将享最高路权"}
'
curl -XPOST http://localhost:9200/index/fulltext/3 -d'
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
'
curl -XPOST http://localhost:9200/index/fulltext/4 -d'
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
'
4.query with highlighting
curl -XPOST http://localhost:9200/index/fulltext/_search -d'
{"query" : { "match" : { "content" : "中国" }},"highlight" : {"pre_tags" : ["<tag1>", "<tag2>"],"post_tags" : ["</tag1>", "</tag2>"],"fields" : {"content" : {}}}
}
'
5.Dictionary Configuration
IKAnalyzer.cfg.xml can be located at plugins/ik/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">custom/ext_stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">location</entry><!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry> </properties>
热更新 IK 分词使用方法
目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
<!--用户可以在这里配置远程扩展字典 --><entry key="remote_ext_dict">location</entry><!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">location</entry>
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
该 http 请求需要返回两个头部(header),一个是
Last-Modified,一个是ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。该 http 请求返回的内容格式是一行一个分词,换行符用
\n即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
三、pinyin分词器下载与安装
pinyin分词器可以让用户输入拼音,就能查找到相关的关键词。比如在某个商城搜索中,输入shuihu,就能匹配到水壶。这样的体验还是非常好的。
pinyin分词器的安装与IK是一样的,这里就省略掉了。
这个分词器在1.8版本中,提供了两种分词规则:
pinyin,就是普通的把汉字转换成拼音;pinyin_first_letter,提取汉字的拼音首字母
github: https://github.com/medcl/elasticsearch-analysis-pinyin
安装: 在github下载源码,idea import 源码,修改pom.xml文件中es版本号,执行maven的package命令,在target目录下的*.zip文件便是pinyin分词器的插件包。安装方式同上IK分词器。
插件介绍:
该插件包括分析器:pinyin,标记器:pinyin和令牌过滤器: pinyin。
**可选参数**
keep_first_letter : 启用此选项时,例如:刘德华> ldh,默认值:true
keep_separate_first_letter : 启用该选项时,将保留第一个字母分开,例如:刘德华> l,d,h,默认:假的,注意:查询结果也许是太模糊,由于长期过频
limit_first_letter_length : 设置first_letter结果的最大长度,默认值:16
keep_full_pinyin : 当启用该选项,例如:刘德华> [ liu,de,hua],默认值:true
keep_joined_full_pinyin : 启用此选项时,例如:刘德华> [ liudehua],默认值:false
keep_none_chinese : 在结果中保留非中文字母或数字,默认值:true
keep_none_chinese_together : 保持非中国信一起,默认值:true,如:DJ音乐家- > DJ,yin,yue,jia,当设置为false,例如:DJ音乐家- > D,J,yin,yue,jia,注意:keep_none_chinese必须先启动
keep_none_chinese_in_first_letter : 第一个字母不能是中文,例如:刘德华AT2016- > ldhat2016,default:true
keep_none_chinese_in_joined_full_pinyin : 保持非中文字母加入完整拼音,例如:刘德华2016- > liudehua2016,默认:false
none_chinese_pinyin_tokenize : 打破非中国信成单独的拼音项,如果他们拼音,默认值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意: keep_none_chinese和keep_none_chinese_together应首先启用
keep_original : 当启用此选项时,也将保留原始输入,默认值:false
lowercase : 小写非中文字母,默认值:true
trim_whitespace : 默认值:true
remove_duplicated_term : 当启用此选项时,将删除重复项以保存索引,例如:de的> de,默认值:false注意:位置相关查询可能受影响
四、pinyin分词器使用测试
1.使用自定义拼音分析器创建索引
curl -XPUT http://localhost:9200/medcl
{"index" : {"analysis" : {"analyzer" : {"pinyin_analyzer" : {"tokenizer" : "my_pinyin"}},"tokenizer" : {"my_pinyin" : {"type" : "pinyin","keep_separate_first_letter" : false,"keep_full_pinyin" : true,"keep_original" : true,"limit_first_letter_length" : 16,"lowercase" : true,"remove_duplicated_term" : true}}}}
}
2.测试分析器,分析一个中文名字,比如刘德华
http://localhost:9200/medcl/_analyze?text=%e5%88%98%e5%be%b7%e5%8d%8e&analyzer=pinyin_analyzer
3.创建映射
properties 中定义了特定字段的分析方式。在上面的例子中,仅仅设置了content的分析方法。
- type,字段的类型为string,只有string类型才涉及到分词,像是数字之类的是不需要分词的。
- store,定义字段的存储方式,no代表不单独存储,查询的时候会从_source中解析。当你频繁的针对某个字段查询时,可以考虑设置成true。
- term_vector,定义了词的存储方式,with_position_offsets,意思是存储词语的偏移位置,在结果高亮的时候有用。
- analyzer,定义了索引时的分词方法
- search_analyzer,定义了搜索时的分词方法
- include_in_all,定义了是否包含在_all字段中
- boost,是跟计算分值相关的
curl -XPOST http://localhost:9200/medcl/folks/_mapping
{"folks": {"properties": {"name": {"type": "keyword","fields": {"pinyin": {"type": "text","store": "no","term_vector": "with_offsets","analyzer": "pinyin_analyzer","boost": 10}}}}}
}
4、搜索
http://localhost:9200/medcl/folks/_search?q=name:刘德华 http://localhost:9200/medcl/folks/_search?q=name.pinyin:刘 http://localhost:9200/medcl/folks/_search?q=name.pinyin:liu http://localhost:9200/medcl/folks/_search?q=name.pinyin:ldh http://localhost:9200/medcl/folks/_search?q=name.pinyin:de+hua
5.使用拼音 - TokenFilter
curl -XPUT http://localhost:9200/medcl1
{"index" : {"analysis" : {"analyzer" : {"user_name_analyzer" : {"tokenizer" : "whitespace","filter" : "pinyin_first_letter_and_full_pinyin_filter"}},"filter" : {"pinyin_first_letter_and_full_pinyin_filter" : {"type" : "pinyin","keep_first_letter" : true,"keep_full_pinyin" : false,"keep_none_chinese" : true,"keep_original" : false,"limit_first_letter_length" : 16,"lowercase" : true,"trim_whitespace" : true,"keep_none_chinese_in_first_letter" : true}}}}
}
Token Test:刘德华 张学友 郭富城 黎明 四大天王
curl -XGET http://localhost:9200/medcl1/_analyze?text=刘德华+张学友+郭富城+黎明+四大天王&analyzer=user_name_analyzer
{"tokens" : [{"token" : "ldh","start_offset" : 0,"end_offset" : 3,"type" : "word","position" : 0},{"token" : "zxy","start_offset" : 4,"end_offset" : 7,"type" : "word","position" : 1},{"token" : "gfc","start_offset" : 8,"end_offset" : 11,"type" : "word","position" : 2},{"token" : "lm","start_offset" : 12,"end_offset" : 14,"type" : "word","position" : 3},{"token" : "sdtw","start_offset" : 15,"end_offset" : 19,"type" : "word","position" : 4}]
}
6.使用短语查询
option 1
PUT /medcl/{"index" : {"analysis" : {"analyzer" : {"pinyin_analyzer" : {"tokenizer" : "my_pinyin"}},"tokenizer" : {"my_pinyin" : {"type" : "pinyin","keep_first_letter":false,"keep_separate_first_letter" : false,"keep_full_pinyin" : true,"keep_original" : false,"limit_first_letter_length" : 16,"lowercase" : true}}}}}GET /medcl/folks/_search{"query": {"match_phrase": {"name.pinyin": "刘德华"}}}option 2
PUT /medcl/{"index" : {"analysis" : {"analyzer" : {"pinyin_analyzer" : {"tokenizer" : "my_pinyin"}},"tokenizer" : {"my_pinyin" : {"type" : "pinyin","keep_first_letter":false,"keep_separate_first_letter" : true,"keep_full_pinyin" : false,"keep_original" : false,"limit_first_letter_length" : 16,"lowercase" : true}}}}}POST /medcl/folks/andy{"name":"刘德华"}GET /medcl/folks/_search{"query": {"match_phrase": {"name.pinyin": "刘德h"}}}GET /medcl/folks/_search{"query": {"match_phrase": {"name.pinyin": "刘dh"}}}GET /medcl/folks/_search{"query": {"match_phrase": {"name.pinyin": "dh"}} }
四、分词流程
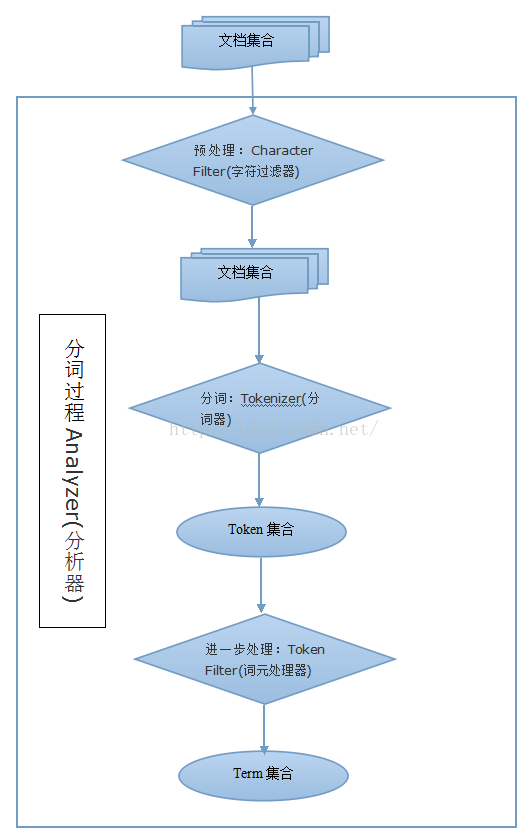
整个流程大概是:单词 ====》Character Filter 预处理 =====》tokenizer分词 ====》 token filter对分词进行再处理。
- 单词或文档先经过Character Filters;Character Filters的作用就是对文本进行一个预处理,例如把文本中所有“&”换成“and”,把“?”去掉等等操作。
- 之后就进入了十分重要的tokenizers模块了,Tokenizers的作用是进行分词,例如,“tom is a good doctor .”。经过Character Filters去掉句号“.”(假设)后,分词器Tokenizers会将这个文本分出很多词来:“tom”、“is”、“a”、“good”、“doctor”。
- 经过分词之后的集合,最后会进入Token Filter词单元模块进行处理,此模块的作用是对已经分词后的集合(tokens)单元再进行操作,例如把“tom”再次拆分成“t”、“o”、“m”等操作。最后得出来的结果集合,就是最终的集合
五、参考
分词配置详解: http://blog.csdn.net/napoay/article/details/53907921
分词过程: http://blog.csdn.net/hu948162999/article/details/68922035
分词原理: http://blog.csdn.net/i6448038/article/details/51509439(推荐)
转载于:https://my.oschina.net/u/1765168/blog/1570050
elasticsearch中文IK+Pinyin分词器相关推荐
- solr配置中文IK Analyzer分词器
1.下载IK Analyzer分词器文件 链接: https://pan.baidu.com/s/1hrA1YyK 密码: 9hpk 中文IK Analyzer分词器的相关配置使用资料: 链接:htt ...
- Elasticsearch 5 Ik+pinyin分词配置详解
一.拼音分词的应用 拼音分词在日常生活中其实很常见,也许你每天都在用.打开淘宝看一看吧,输入拼音"zhonghua",下面会有包含"zhonghua"对应的中文 ...
- elasticsearch ik pingyin 分词器的安装和使用
ES的核心就是搜索, 那么用ES不得不提到ES的搜索机制. 提搜索机制 就不得不提到 index的mapping 里的分词器 我们在搭建的过程中,默认通过 ip:9200/index 来创建一个索引. ...
- Elasticsearch:Pinyin 分词器
Elastic 的 Medcl 提供了一种搜索 Pinyin 搜索的方法.拼音搜索在很多的应用场景中都有被用到.比如在百度搜索中,我们使用拼音就=可以出现汉字: 对于我们中国人来说,拼音搜索也是非常直 ...
- 【ES】ES 拼音 Pinyin 分词器
1.概述 转载:https://www.cnblogs.com/sanduzxcvbnm/p/12083606.html Elastic的Medcl提供了一种搜索Pinyin搜索的方法.拼音搜索在很多 ...
- ElasticSearch入门:ES分词器与自定义分词器
ES入门:ES分词器与自定义分词器 分词器的简单介绍 不同分词器的效果对比 自定义分词器的应用 分词器的简单介绍 分词器是es中的一个组件,通俗意义上理解,就是将一段文本按照一定的逻辑,分析成多个词语 ...
- Springboot集成elasticsearch 使用IK+拼音分词
Springboot集成elasticsearch 使用IK+拼音分词 docker安装ES 下载 docker pull docker.elastic.co/elasticsearch/elasti ...
- Elasticsearch 定义多个分词器模板
Elasticsearch 定义多个分词器模板 版本:Elasticsearch 7.2.0 1.定义索引时,使用多个分词器 2.在模板中定义中使用多个分词器 3.ik+pinyin 对人工智能感 ...
- Elasticsearch Analyzer 内置分词器
Elasticsearch Analyzer 内置分词器 篇主要介绍一下 Elasticsearch中 Analyzer 分词器的构成 和一些Es中内置的分词器 以及如何使用它们 前置知识 es 提供 ...
最新文章
- HA03-fence设置
- 一款实用可行的支付系统,专供互联网企业使用,赶紧收藏了!
- OpenCV学习笔记(3)——Scalar数据类型理解
- Spread for WinRT 7新功能使用指南
- 【笔试题】京东2017秋招笔试真题
- RabbitMQ研究与应用
- html 简单 在线编辑器 ie ff,一款垃圾中的极品HTML编辑器(兼容IE OR FF)
- java 线程模型_Java基础篇之Java线程模型
- Spring在3.1版本后的bean获取方法的改变
- make文件基础用法
- spring学习(30):定义第一个bean
- security center拒绝访问_Steam被曝出0day提权漏洞,但厂商拒绝修复
- python 替换文本 通配符_使用通配符搜索和替换文本文件中的字符串
- 18、监听器/国际化
- Oracle 在 Linux 下移动控制文件步骤
- erp系统源码php_最新仿金蝶 PHP电商ERP进销存系统软件 带扫描功能
- Silverlight 解谜游戏 之十二 游戏暗示(1)
- hot-S22和X参数的原理(转)
- 用台达PLC485通信控制11台英威腾变频启动停止速度设定
- win7设置自动开机时间_win7本地连接ip设置方法