svm原理详解,看完就懂(七):松弛变量part2
接下来要说的东西其实不是松弛变量本身,但由于是为了使用松弛变量才引入的,因此放在这里也算合适,那就是惩罚因子C。回头看一眼引入了松弛变量以后的优化问题:

注意其中C的位置,也可以回想一下C所起的作用(表征你有多么重视离群点,C越大越重视,越不想丢掉它们)。这个式子是以前做SVM的人写的,大家也就这么用,但没有任何规定说必须对所有的松弛变量都使用同一个惩罚因子,我们完全可以给每一个离群点都使用不同的C,这时就意味着你对每个样本的重视程度都不一样,有些样本丢了也就丢了,错了也就错了,这些就给一个比较小的C;而有些样本很重要,决不能分类错误(比如中央下达的文件啥的,笑),就给一个很大的C。
当然实际使用的时候并没有这么极端,但一种很常用的变形可以用来解决分类问题中样本的“偏斜”问题。
先来说说样本的偏斜问题,也叫数据集偏斜(unbalanced),它指的是参与分类的两个类别(也可以指多个类别)样本数量差异很大。比如说正类有10,000个样本,而负类只给了100个,这会引起的问题显而易见,可以看看下面的图:
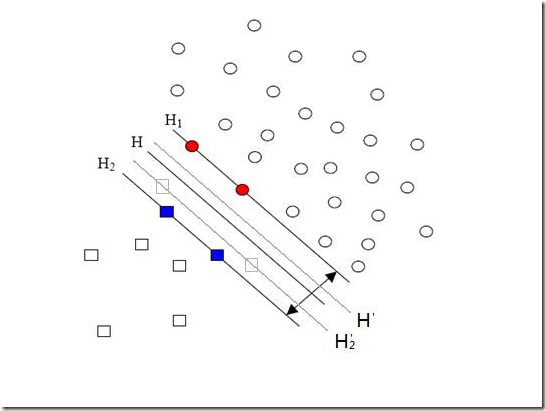
方形的点是负类。H,H1,H2是根据给的样本算出来的分类面,由于负类的样本很少很少,所以有一些本来是负类的样本点没有提供,比如图中两个灰色的方形点,如果这两个点有提供的话,那算出来的分类面应该是H’,H2’和H1,他们显然和之前的结果有出入,实际上负类给的样本点越多,就越容易出现在灰色点附近的点,我们算出的结果也就越接近于真实的分类面。但现在由于偏斜的现象存在,使得数量多的正类可以把分类面向负类的方向“推”,因而影响了结果的准确性。
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:

其中i=1…p都是正样本,j=p+1…p+q都是负样本。libSVM这个算法包在解决偏斜问题的时候用的就是这种方法。
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
看到这里读者一定疯了,因为说来说去,这岂不成了一个解决不了的问题?然而事实如此,完全的方法是没有的,根据需要,选择实现简单又合用的就好(例如libSVM就直接使用样本数量的比)。
svm原理详解,看完就懂(七):松弛变量part2相关推荐
- 查看计算机配置讲解,教您如何看显示器参数!电脑显示器常见参数详解,看完秒懂!...
由于显示器可选的范围比较广,同一个尺寸大小的显示器,不同品牌不同型号不同参数会有上百种可供选择,其实我们只需明确了预算与用途,才可以正确选择合适自己的显示器.那么如何看显示器参数?下面装机之家分享一下 ...
- 计算机网络参数怎么看,电脑显示器参数详解 看完秒懂! 显示器参数怎么看?...
显示器参数怎么看?无论是显示器的宣传.购买页面,还是专业媒体的显示器评测中,我们都会看到一些用来描述显示器性能的参数.小编觉着,显示器就像是电脑的一张面孔,显示着它的各种表情,也负责与用户的沟通,而显 ...
- svm原理详解,看完就懂(六):松弛变量part1
现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而变成了线性可分的.就像下图这样: 圆形和方形的点各有成千上万个(毕竟,这就是我们训练集中文档的数量嘛,当然很大了).现在想象我们有另 ...
- python使用kafka原理详解真实完整版_转:Kafka史上最详细原理总结 ----看完绝对不后悔...
消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一.下面将从Kafka文件存储机制和物理结构角度,分析Kafka是如何实现高效文件存储,及实际应用效果. 1.1 K ...
- spring注解详解,看完你就都全懂了!!
转载:https://blog.csdn.net/walkerjong/article/details/7946109
- SVM 原理详解,通俗易懂
看了该作者的文章,瞬间膜拜了!讲得太好了! 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
- 向量机SVM原理详解
转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Support Vector Machine)是Co ...
- 通俗易懂的 SVM 原理详解
看了该作者的文章,瞬间膜拜了!讲得太好了! 转自:http://www.blogjava.net/zhenandaci/category/31868.html (一)SVM的简介 支持向量机(Supp ...
- python使用kafka原理详解真实完整版_史上最详细Kafka原理总结
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
最新文章
- CVPR 2019 | 一种用于年龄估计的连续感知概率网络
- 【Java 虚拟机原理】栈帧 | 局部变量表 | 操作数栈 | 方法出口 | JVM 指令逐条解析
- QuickSort简解(分治思想) By ACReaper
- IDEA 集成Lombok 插件-安装插件
- TestinPro应用与DevOps之路
- 使用JAX-RS和Spring构建HATEOAS API
- python列表切片图解_Python列表切片操作实例总结
- 腾讯第一季度总收入1353亿元 净利润478亿元
- linq判断集合中相同元素个数_高中数学:集合与函数概念知识点汇总
- 检测到你的手机处于root环境_玩手游多开还在用模拟器?云手机了解一下
- 智汀、米家、苹果homekit智能门锁新体验,打开不一样的大门
- Java 中status意思_struts2中iterator里属性status=stat什么意思
- 完美世界3D格斗手游[格斗宝贝]今日公测
- 微信渐变国旗头像来了!一键生成
- win10 永久关闭自动更新
- Koo叔说Shader—果冻效果
- 计算机系统如何恢复出厂设置路由器,迅捷(fast)路由器恢复出厂设置后怎么重新设置?...
- 风影ASP.NET基础教学 12 GridView详解
- GSM与N-CDMA网络覆盖能力对比研究(转)
- webSevice基础学习
热门文章
- Dell 7920工作站2080ti配置Ubuntu18.04+CUDA11.7+Cudnn
- 荣耀8开屏锁显示无法连接服务器,华为荣耀8解锁教程 华为荣耀8如何解锁
- js 字符串数组转换成数字数组
- 电信运营商基于 MQTT 协议 构建千万级 IoT 设备管理平台
- html 磁帖 模板,帖子编辑器预置模板
- 计算机操作系统(第四版)第四章存储器管理—课后习题答案
- mt2523 LinkIt_SDK_v4_GCC_Build_Environment_Guide
- 北大肖臻老师《区块链技术与应用》系列课程学习笔记[1]Bitcoin中用到的密码学原理和数据结构
- 怎么还原计算机字体库,如何在XP系统中恢复字库文件?WinXp系统恢复字库文件图文教程...
- DOSBOX与DEBUG的使用方法及命令