快速近似最近邻算法_数据科学家指南,以选择最佳近似最近邻算法
快速近似最近邻算法
by Braden Riggs and George Williams (gwilliams@gsitechnology.com)
Braden Riggs和George Williams(gwilliams@gsitechnology.com)
Whether you are new to the field of data science or a seasoned veteran, you have likely come into contact with the term, ‘nearest-neighbor search’, or, ‘similarity search’. In fact, if you have ever used a search engine, recommender, translation tool, or pretty much anything else on the internet then you have probably made use of some form of nearest-neighbor algorithm. These algorithms, the ones that permeate most modern software, solve a very simple yet incredibly common problem. Given a data point, what is the closest match from a large selection of data points, or rather what point is most like the given point? These problems are “nearest-neighbor” search problems and the solution is an Approximate Nearest Neighbor algorithm or ANN algorithm for short.
无论您是数据科学领域的新手还是经验丰富的资深人士,您都可能接触过“最近邻居搜索”或“相似搜索”一词。 实际上,如果您曾经使用搜索引擎,推荐器,翻译工具或互联网上的几乎所有其他工具,那么您可能已经在使用某种形式的最近邻居算法。 这些算法已渗透到大多数现代软件中,解决了一个非常简单但难以置信的常见问题。 给定一个数据点,从大量数据点中选择最接近的匹配是什么 ,或者最像给定点的是哪个点? 这些问题是“最近邻居”搜索 问题和解决方案是简称为“ 近似最近邻居”算法或ANN算法。
Approximate nearest-neighbor algorithms or ANN’s are a topic I have blogged about heavily, and with good reason. As we attempt to optimize and solve the nearest-neighbor challenge, ANN’s continue to be at the forefront of elegant and optimal solutions to these problems. Introductory Machine learning classes often include a segment about ANN’s older brother kNN, a conceptually simpler style of nearest-neighbor algorithm that is less efficient but easier to understand. If you aren’t familiar with kNN algorithms, they essentially work by classifying unseen points based on “k” number of nearby points, where the vicinity or distance of the nearby points are calculated by distance formulas such as euclidian distance.
近似最近邻算法或ANN是我在博客上大量谈论的主题,并且有充分的理由。 在我们尝试优化和解决最邻近的挑战时,ANN始终站在解决这些问题的优雅且最优的解决方案的最前沿。 机器学习入门课程通常包括有关ANN的哥哥kNN的部分,kNN是概念上更简单的近邻算法样式,效率较低但更易于理解。 如果您不熟悉kNN算法,则它们实际上是通过基于“ k”个邻近点数对看不见的点进行分类来工作的,其中邻近点的邻近度或距离是通过诸如欧几里得距离之类的距离公式来计算的。
ANN’s work similarly but with a few more techniques and strategies that ensure greater efficiency. I go into more depth about these techniques in an earlier blog here. In this blog, I describe an ANN as:
ANN的工作与此类似,但是有更多的技术和策略可以确保更高的效率。 我在这里先前的博客中对这些技术进行了更深入的介绍。 在此博客中, 我将ANN描述为 :
A faster classifier with a slight trade-off in accuracy, utilizing techniques such as locality sensitive hashing to better balance speed and precision.- Braden Riggs, How to Benchmark ANN Algorithms
一种更快的分类器,在精度上会稍有取舍,利用诸如位置敏感的哈希值之类的技术来更好地平衡速度和精度。- Braden Riggs,如何对ANN算法进行基准测试
The problem with utilizing the power of ANNs for your own projects is the sheer quantity of different implementations open to the public, each having their own benefits and disadvantages. With so many choices available how can you pick which is right for your project?
在您自己的项目中使用ANN的功能所带来的问题是,向公众开放的不同实现的数量庞大,每个实现都有其自身的优缺点。 有这么多的选择,您如何选择最适合您的项目?
Bernhardsson和ANN救援基准: (Bernhardsson and ANN-Benchmarks to the Rescue:)
We have established that there are a range of ANN implementations available for use. However, we need a way of picking out the best of the best, the cream of the crop. This is where Aumüller, Bernhardsson, and Faithfull’s paper ANN-Benchmarks: A Benchmarking Tool for Approximate Nearest Neighbor Algorithms and its corresponding GitHub repository comes to our rescue.
我们已经建立了一系列可供使用的ANN实现。 但是,我们需要一种方法来挑选最好的农作物。 这是Aumüller,Bernhardsson和Faithfull的论文ANN基准:近似最近邻算法的基准工具 并且其相应的GitHub存储库可为我们提供帮助。
The project, which I have discussed in the past, is a great starting point for choosing the algorithm that is the best fit for your project. The paper uses some clever techniques to evaluate the performance of a number of ANN implementations on a selection of datasets. It has these ANN algorithms solve nearest-neighbor queries to determine the accuracy and efficiency of the algorithm at different parameter combinations. The algorithm uses these queries to locate the 10 nearest data points to the queried point and evaluates how close each point is to the true neighbor, which is a metric called Recall. This is then scaled against how quickly the algorithm was able to accomplish its goal, which it called Queries per Second. This metric provides a great reference for determining which algorithms may be most preferential for you and your project.
我过去讨论过的项目是选择最适合您项目的算法的一个很好的起点。 本文使用一些巧妙的技术来评估多种ANN实施对所选数据集的性能。 它具有这些ANN算法来解决最近邻居查询,以确定算法在不同参数组合下的准确性和效率。 该算法使用这些查询来定位最接近查询点的10个数据点,并评估每个点与真正邻居的接近程度,这是一个称为“召回率”的度量。 然后,根据算法能够实现其目标的速度(称为“每秒查询”)进行缩放。 该指标为确定哪种算法可能最适合您和您的项目提供了很好的参考。

Part of conducting this experiment requires picking the algorithms we want to test, and the dataset we want to perform the queries on. Based off of the experiments I have conducted on my previous blogs, narrowing down the selection of algorithms wasn’t difficult. In Bernhardsson’s original project he includes 18 algorithms. Given the performance I had seen in my first blog, using the glove-25 angular natural language dataset, there are 9 algorithms worth considering for our benchmark experiment. This is because some algorithms perform so slowly and so poorly that they aren’t even worth considering in this experiment. The algorithms selected are:
进行此实验的一部分需要选择我们要测试的算法,以及我们要对其执行查询的数据集。 根据我在以前的博客上进行的实验,缩小算法的选择范围并不困难。 在Bernhardsson的原始项目中,他包括18种算法。 鉴于我在第一个博客中看到的性能,使用了Gloves-25角度自然语言数据集,有9种算法值得我们进行基准测试。 这是因为某些算法的执行速度如此之慢且如此差,以至于在本实验中甚至都不值得考虑。 选择的算法是:
Annoy: Spotify's “Approximate Nearest Neighbors Oh Yeah” ANN implementation.
烦恼: Spotify的 “哦,是,最近的邻居” ANN实现。
Faiss: The suite of algorithms Facebook uses for large dataset similarity search including Faiss-lsh, Faiss-hnsw, and Faiss-ivf.
Faiss: Facebook用于大型数据集相似性搜索的算法套件,包括Faiss-lsh , Faiss-hnsw和Faiss-ivf 。
Flann: Fast Library for ANN.
Flann: ANN的快速库。
HNSWlib: Hierarchical Navigable Small World graph ANN search library.
HNSWlib:分层可导航小世界图ANN搜索库。
NGT-panng: Yahoo Japan’s Neighborhood Graph and Tree for Indexing High-dimensional Data.
NGT-panng: Yahoo Japan的邻域图和树,用于索引高维数据。
Pynndescent: Python implementation of Nearest Neighbor Descent for k-neighbor-graph construction and ANN search.
Pynndescent:用于k邻域图构建和ANN搜索的Nearest Neighbor Descent的Python实现。
SW-graph(nmslib): Small world graph ANN search as part of the non-metric space library.
SW-graph(nmslib):小世界图ANN搜索,作为非度量空间库的一部分。
In addition to the algorithms, it was important to pick a dataset that would help distinguish the optimal ANN implementations from the not so optimal ANN implementations. For this task, we chose 1% — or a 10 million vector slice — of the gargantuan Deep-1-billion dataset, a 96 dimension computer vision training dataset. This dataset is large enough for inefficiencies in the algorithms to be accentuated and provide a relevant challenge for each one. Because of the size of the dataset and the limited specification of our hardware, namely the 64GBs of memory, some algorithms were unable to fully run to an accuracy of 100%. To help account for this, and to ensure that background processes on our machine didn’t interfere with our results, each algorithm and all of the parameter combinations were run twice. By doubling the number of benchmarks conducted, we were able to average between the two runs, helping account for any interruptions on our hardware.
除算法外,重要的是选择一个有助于区分最佳ANN实现与非最佳ANN实现的数据集。 为此,我们选择了庞大的Deep-billion数据集(96维计算机视觉训练数据集)的1%(即一千万个矢量切片)。 该数据集足够大,可以突出算法的低效率,并为每个算法带来相关挑战。 由于数据集的大小和我们硬件的有限规格(即64GB内存),某些算法无法完全运行到100%的精度。 为了解决这个问题,并确保我们机器上的后台进程不会干扰我们的结果,每种算法和所有参数组合都运行两次。 通过将执行的基准测试数量加倍,我们可以在两次运行之间求平均值,从而帮助解决硬件上的任何中断。
This experiment took roughly 11 days to complete but yielded some helpful and insightful results.
该实验大约花费了11天的时间,但得出了一些有益而有见地的结果。
我们发现了什么? (What did we find?)
After the exceptionally long runtime, the experiment completed with only three algorithms failing to fully reach an accuracy of 100%. These algorithms were Faiss-lsh, Flann, and NGT-panng. Despite these algorithms not reaching perfect accuracy, their results are useful and indicate where the algorithm may have been heading if we had experimented with more parameter combinations and didn't exceed memory usage on our hardware.
经过异常长的运行时间后,该实验仅用三种算法就无法完全达到100%的精度。 这些算法是Faiss-lsh , Flann和NGT-panng 。 尽管这些算法没有达到理想的精度,但是它们的结果还是有用的,它们表明如果我们尝试了更多的参数组合并且未超过硬件上的内存使用量,该算法可能会前进。
Before showing off the results, let’s quickly discuss how we are presenting these results and what terminology you need to understand. On the y-axis, we have Queries per Second or QPS. QPS quantifies the number of nearest-neighbor searches that can be conducted in a second. This is sometimes referred to as the inverse ‘latency’ of the algorithm. More precisely QPS is a bandwidth measure and is inversely proportional to the latency. As the query time goes down, the bandwidth will increase. On the x-axis, we have Recall. In this case, Recall essentially represents the accuracy of the function. Because we are finding the 10 nearest-neighbors of a selected point, the Recall score takes the distances of the 10 nearest-neighbors our algorithms computed and compares them to the distance of the 10 true nearest-neighbors. If the algorithm selects the correct 10 points it will have a distance of zero from the true values and hence a Recall of 1. When using ANN algorithms we are constantly trying to maximize both of these metrics. However, they often improve at each other’s expense. When you speed up your algorithm, thereby improving latency, it becomes less accurate. On the other hand, when you prioritize its accuracy, thereby improving Recall, the algorithm slows down.
在展示结果之前,让我们快速讨论一下我们如何呈现这些结果以及您需要了解哪些术语。 在y轴上,我们有每秒查询数或QPS。 QPS量化了每秒可以进行的最近邻居搜索的次数。 有时将其称为算法的逆“潜伏期”。 更准确地说,QPS是带宽量度,与延迟成反比。 随着查询时间的减少,带宽将增加。 在x轴上,我们有Recall 。 在这种情况下,调用实质上代表了函数的准确性。 由于我们正在查找选定点的10个最近邻居,因此Recall分数将采用我们的算法计算出的10个最近邻居的距离,并将它们与10个真实最近邻居的距离进行比较。 如果该算法选择了正确的10个点,则它与真实值的距离为零,因此召回率为1。使用ANN算法时,我们一直在不断尝试使这两个指标最大化。 但是,它们通常会以互相牺牲为代价而有所改善。 当您加快算法速度从而改善延迟时,它的准确性就会降低。 另一方面,当您优先考虑其准确性从而提高查全率时,该算法会变慢。
Pictured below is the plot of Queries Performed per Second, over the Recall of the algorithm:
下图是算法调用时每秒执行的查询的图:
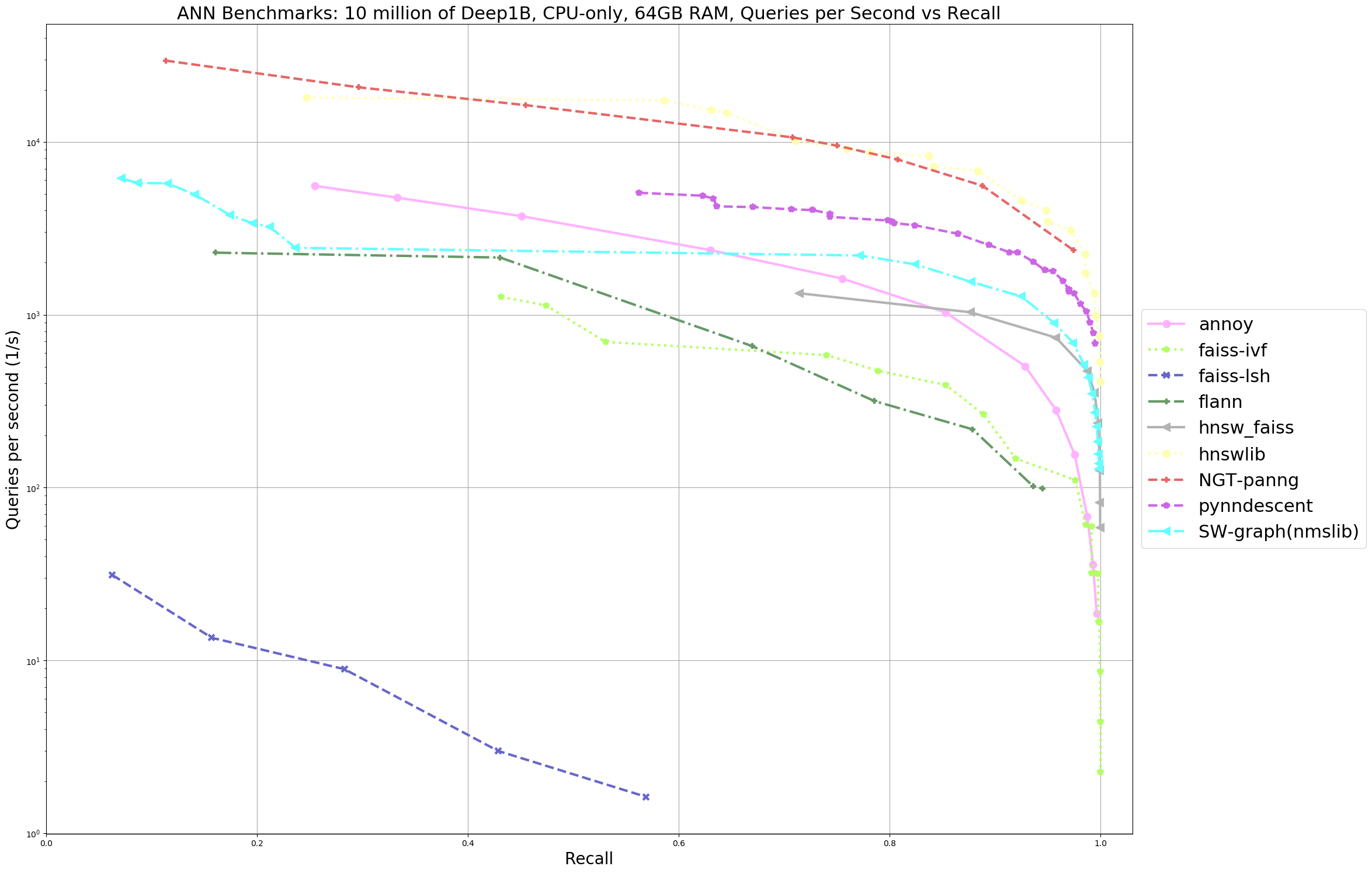
As evident by the graph above there were some clear winners and some clear losers. Focusing on the winners, we can see a few algorithms that really stand out, namely HNSWlib (yellow) and NGT-panng (red) both of which performed at a high accuracy and a high speed. Even though NGT never finished, the results do indicate it was performing exceptionally well prior to a memory-related failure.
从上图可以明显看出,有一些明显的赢家和一些明显的输家。 着眼于获胜者,我们可以看到一些真正脱颖而出的算法,即HNSWlib(黄色)和NGT-panng(红色),它们均以高精度和高速执行。 尽管NGT从未完成,但结果确实表明它在与内存相关的故障之前表现出色。
So given these results, we now know which algorithms to pick for our next project right?
因此,鉴于这些结果,我们现在知道为下一个项目选择哪种算法对吗?
Unfortunately, this graph doesn’t depict the full story when it comes to the efficiency and accuracy of these ANN implementations. Whilst HNSWlib and NGT-panng can perform quickly and accurately, that is only after they have been built. “Build time” refers to the length of time that is required for the algorithm to construct its index and begin querying neighbors. Depending on the implementation of the algorithm, build time can be a few minutes or a few hours. Graphed below is the average algorithm build time for our benchmark excluding Faiss-HNSW which took 1491 minutes to build (about 24 hours):
不幸的是,当涉及到这些ANN实现的效率和准确性时,该图并没有完整描述。 虽然HNSWlib和NGT-panng可以快速而准确地执行,但这只是在它们构建之后。 “构建时间”是指算法构建其索引并开始查询邻居所需的时间长度。 根据算法的实现,构建时间可能是几分钟或几小时。 下图是我们的基准测试的平均算法构建时间, 不包括Faiss-HNSW,该过程花费了1491分钟的构建时间(约24小时) :
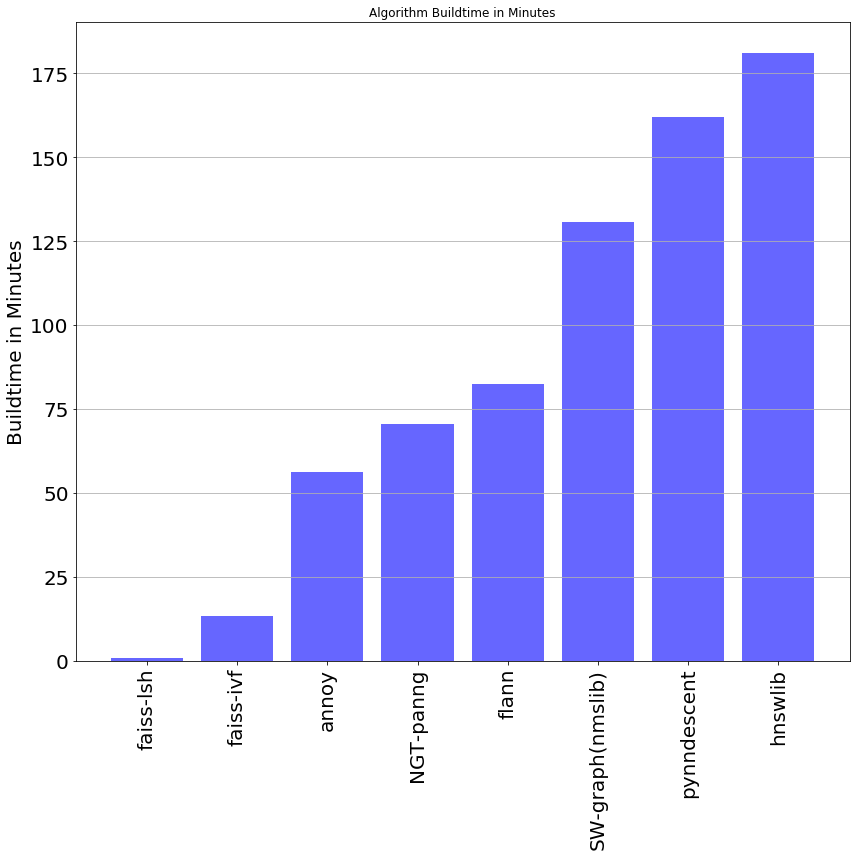
As we can see the picture changes substantially when we account for the time spend “building” the algorithm’s indexes. This index is essentially a roadmap for the algorithm to follow on its journey to find the nearest-neighbor. It allows the algorithm to take shortcuts, accelerating the time taken to find a solution. Depending on the size of the dataset and how intricate and comprehensive this roadmap is, build-time can be between a matter of seconds and a number of days. Although accuracy is always a top priority, depending on the circumstances it may be advantageous to choose between algorithms that build quickly or algorithms that run quickly:
正如我们看到的那样,当我们考虑“构建”算法索引所花费的时间时,情况会发生很大的变化。 该索引本质上是该算法在查找最近邻居的过程中要遵循的路线图。 它允许算法采用快捷方式,从而加快了找到解决方案的时间。 根据数据集的大小以及此路线图的复杂程度,构建时间可能在几秒钟到几天之间。 尽管准确性始终是头等大事,但根据具体情况,在快速构建的算法或快速运行的算法之间进行选择可能会比较有利:
Scenario #1: You have a dataset that updates regularly but isn’t queried often, such as a school’s student attendance record or a government’s record of birth certificates. In this case, you wouldn’t want an algorithm that builds slowly because each time more data is added to the set, the algorithm must rebuild it’s index to maintain a high accuracy. If your algorithm builds slowly this could waste valuable time and energy. Algorithms such as Faiss-IVF are perfect here because they build fast and are still very accurate.
方案1:您有一个定期更新但不经常查询的数据集,例如学校的学生出勤记录或政府的出生证明记录。 在这种情况下,您不希望算法构建缓慢,因为每次将更多数据添加到集合中时,该算法必须重建其索引以保持较高的准确性。 如果算法构建缓慢,可能会浪费宝贵的时间和精力。 Faiss-IVF之类的算法在这里非常理想,因为它们构建速度很快并且仍然非常准确。
Scenario #2: You have a static dataset that doesn’t change often but is regularly queried, like a list of words in a dictionary. In this case, it is more preferential to use an algorithm that is able to perform more queries per second, at the expense of built time. This is because we aren’t adding new data regularly and hence don’t need to rebuild the index regularly. Algorithms such as HNSWlib or NGT-panng are perfect for this because they are accurate and fast, once the build is completed.
场景2:您有一个静态数据集,该数据集不会经常更改,而是会定期查询,例如字典中的单词列表。 在这种情况下,更可取的是使用能够每秒执行更多查询的算法,但会浪费构建时间。 这是因为我们不会定期添加新数据,因此不需要定期重建索引。 HNSWlib或NGT-panng之类的算法非常适合此操作,因为一旦构建完成,它们便准确且快速。
There is a third scenario worth mentioning. In my experiments attempting to benchmark ANN algorithms on larger and larger portions of the deep1b dataset, available memory started to become a major limiting factor. Hence, picking an algorithm with efficient use of memory can be a major advantage. In this case, I would highly recommend the Faiss suite of algorithms which have been engineered to perform under some of the most memory starved conditions.
还有第三种情况值得一提。 在我的实验中,试图在Deep1b数据集的越来越大的部分上对ANN算法进行基准测试 ,可用内存开始成为主要的限制因素。 因此,选择一种有效利用内存的算法可能是一个主要优势。 在这种情况下,我强烈建议使用Faiss算法套件,这些套件经设计可在某些内存不足的情况下执行。
Regardless of the scenario, we almost always want high accuracy. In our case accuracy, or recall, is evaluated based on the algorithm’s ability to correctly determine the 10 nearest-neighbors of a given point. Hence the algorithm’s performance could change if we consider its 100 nearest-neighbors or its single nearest-neighbor.
无论哪种情况,我们几乎总是希望获得高精度。 在我们的情况下,根据算法正确确定给定点的10个最近邻居的能力来评估准确性或召回率。 因此,如果我们考虑它的100个最近邻居或单个最近邻居,算法的性能可能会改变。
摘要: (The Summary:)
Based on our findings from this benchmark experiment there are clear benefits to using some algorithms as opposed to others. The key to picking an optimal ANN algorithm is understanding what about the algorithm you want to prioritize and what engineering tradeoffs you are comfortable with. I recommend you prioritize what fits your circumstances, be that speed (QPS), accuracy (Recall), or pre-processing (Build time). It is worth noting algorithms that perform with less than 90% Recall aren’t worth discussing. This is because 90% is considered to be the minimum level of performance when conducting nearest-neighbor search. Anything less than 90% is underperforming and likely not useful.
根据我们从基准测试中获得的发现,使用某些算法相对于其他算法具有明显的好处。 选择最佳ANN算法的关键是了解要确定优先级的算法是什么,以及需要进行哪些工程折衷。 我建议您优先考虑适合您的情况的速度,速度(QPS),准确性(调用)或预处理(构建时间)。 值得注意的是,执行调用率不到90%的算法不值得讨论。 这是因为在执行最近邻居搜索时,90%被认为是最低性能。 少于90%的广告效果不佳,可能没有用。
With that said my recommendations are as follows:
话虽如此,我的建议如下:
For projects where speed is a priority, our results suggest that algorithms such as HNSWlib and NGT-panng perform accurately with a greater number of queries per second than alternative choices.
对于优先考虑速度的项目,我们的结果表明,与其他选择相比,诸如HNSWlib和NGT-panng之类的算法每秒可以执行的查询数量更高, 从而能够准确执行。
For Projects where accuracy is a priority, our results suggest that algorithms such as Faiss-IVF and SW-graph prioritize higher Recall scores, whilst still performing quickly.
对于以准确性为优先的项目,我们的结果表明,诸如Faiss-IVF和SW-graph之类的算法会优先考虑较高的查全率,同时仍能快速执行。
For projects where pre-processing is a priority, our results suggest that algorithms such as Faiss-IVF and Annoy exhibit exceptionally fast build times whilst still balancing accuracy and speed.
对于需要优先处理的项目,我们的结果表明,诸如Faiss-IVF和Annoy之类的算法显示出异常快的构建时间,同时仍然在准确性和速度之间取得了平衡。
Considering the circumstances of our experiment, there are a variety of different scenarios where some algorithms may perform better than others. In our case, we have tried to perform in the most generic and common of circumstances. We used a large dataset with high, but not excessively high, dimensionality to help indicate how these algorithms may perform on sets with similar specifications. For some of these algorithms, more tweaking and experimentation may lead to marginal improvements in runtime and accuracy. However, given the scope of this project it would be excessive to attempt to accomplish this with each algorithm.
考虑到我们的实验环境,在许多不同的情况下,某些算法的性能可能会优于其他算法。 在我们的案例中,我们试图在最普通和最常见的情况下执行。 我们使用了一个具有高(但不是过高)维的大型数据集,以帮助指示这些算法如何在具有相似规格的集合上执行。 对于其中一些算法,更多的调整和实验可能会导致运行时和准确性的轻微改善。 但是,鉴于该项目的范围,尝试使用每种算法来完成此任务将是多余的。
If you are interested in learning more about Bernhardsson’s project I recommend reading some of my other blogs on the topic. If you are interested in looking at the full CSV file of results from this benchmark, it is available on my GitHub here.
如果您有兴趣了解有关Bernhardsson项目的更多信息,我建议您阅读其他一些有关该主题的博客。 如果您有兴趣查看此基准测试结果的完整CSV文件,请在我的GitHub上此处获取 。
未来的工作: (Future Work:)
Whilst this is a good starting point for picking ANN algorithms there are still a number of alternative conditions to consider. Going forward I would like to explore how batch performance impacts our results and whether different algorithms perform better when batching is included. Additionally, I suspect that some algorithms will perform better when querying for different numbers of nearest-neighbors. In this project, we chose 10 nearest neighbors, however, our results could shift when querying for 100 neighbors or just the top 1 nearest-neighbor.
虽然这是选择ANN算法的一个很好的起点,但仍然需要考虑许多替代条件。 展望未来,我想探讨批处理性能如何影响我们的结果以及包括批处理时不同的算法是否表现更好。 另外,我怀疑在查询不同数量的最近邻居时某些算法的性能会更好。 在此项目中,我们选择了10个最近的邻居,但是,当查询100个邻居或仅搜索前1个最近的邻居时,结果可能会发生变化。
附录: (Appendix:)
Computer specifications: 1U GPU Server 1 2 Intel CD8067303535601 Xeon® Gold 5115 2 3 Kingston KSM26RD8/16HAI 16GB 2666MHz DDR4 ECC Reg CL19 DIMM 2Rx8 Hynix A IDT 4 4 Intel SSDSC2KG960G801 S4610 960GB 2.5" SSD.
计算机规格: 1U GPU服务器1 2 Intel CD8067303535601Xeon®Gold 5115 2 3 Kingston KSM26RD8 / 16HAI 16GB 2666MHz DDR4 ECC Reg CL19 DIMM 2Rx8 Hynix A IDT 4 4 Intel SSDSC2KG960G801 S4610 960GB 2.5“ SSD。
Link to How to Benchmark ANN Algorithms: https://medium.com/gsi-technology/how-to-benchmark-ann-algorithms-a9f1cef6be08
链接到如何对ANN算法进行基准测试: https : //medium.com/gsi-technology/how-to-benchmark-ann-algorithms-a9f1cef6be08
Link to ANN Benchmarks: A Data Scientist’s Journey to Billion Scale Performance: https://medium.com/gsi-technology/ann-benchmarks-a-data-scientists-journey-to-billion-scale-performance-db191f043a27
链接到ANN基准:数据科学家的十亿规模绩效之旅: https : //medium.com/gsi-technology/ann-benchmarks-a-data-scientists-journey-to-billion-scale-performance-db191f043a27
Link to CSV file that includes benchmark results: https://github.com/Briggs599/Deep1b-benchmark-results
链接到包含基准测试结果的CSV文件: https : //github.com/Briggs599/Deep1b-benchmark-results
资料来源: (Sources:)
Aumüller, Martin, Erik Bernhardsson, and Alexander Faithfull. “ANN-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms.” International Conference on Similarity Search and Applications. Springer, Cham, 2017.
Aumüller,Martin,Erik Bernhardsson和Alexander Faithfull。 “ ANN基准:用于近似最近邻算法的基准测试工具。” 国际相似性搜索及其应用会议 。 湛,施普林格,2017
Deep billion-scale indexing. (n.d.). Retrieved July 21, 2020, from http://sites.skoltech.ru/compvision/noimi/
十亿规模的深索引。 (nd)。 于2020年7月21日从http://sites.skoltech.ru/compvision/noimi/检索
Liu, Ting, et al. “An investigation of practical approximate nearest neighbor algorithms.” Advances in neural information processing systems. 2005.
刘婷,等。 “研究实用的近似最近邻算法。” 神经信息处理系统的研究进展 。 2005。
翻译自: https://medium.com/gsi-technology/a-data-scientists-guide-to-picking-an-optimal-approximate-nearest-neighbor-algorithm-6f91d3055115
快速近似最近邻算法
http://www.taodudu.cc/news/show-3337582.html
相关文章:
- mongdb ngt_NGT:用于高速近似最近邻居搜索的库
- NGT使用
- 推荐系统:ann算法之ngt
- HeidiSQL 简单使用流程
- sql中的IF ELSE使用方法
- sql中使用md5
- SQL 中union的使用
- Mysql使用sql语句建表
- sqlserver使用正则表达式
- sql——分号的运用
- 使用SQL语句UPDATE更新表数据
- HeidiSQL使用心得
- SQL使用using关键字详解
- SQl使用方法总结
- SQL基本使用(通俗易懂,适合适合0基础的小伙伴们)
- SQL基本用法
- SQL的使用规范以及基本使用
- SQL的使用
- 【解决错误】AttributeError: partially initialized module ‘seaborn‘ has no attribute ‘distplot‘
- AttributeError:部分初始化的模块没有属性...(Python)
- TortoiseSVN进行patch后出现中文乱码的解决方法
- 高级AISC芯片综合
- VISUAL STUDIO 2019 的安装
- Widgets基础篇(上)
- centos下遇见unzip命令错误及解决
- python中文转到ascii码_解决Python2中文ascii编码的方法
- ASIC设计开发流程
- 彻底弄懂 ASCII 码的所有符号
- linux离线安装程序,安装和使用Apt-offline以离线安装Debian应用程序
- centos安装airflow
快速近似最近邻算法_数据科学家指南,以选择最佳近似最近邻算法相关推荐
- 近似算法的近似率_选择最佳近似最近算法的数据科学家指南
近似算法的近似率 by Braden Riggs and George Williams (gwilliams@gsitechnology.com) Braden Riggs和George Willi ...
- 数据模型最佳实践_数据科学家应了解软件工程最佳实践
数据模型最佳实践 意见 (Opinion) 介绍 (Introduction) I have been eagerly researching, speaking to friends and tes ...
- 西雅图治安_数据科学家对西雅图住宿业务的分析
西雅图治安 介绍 (Introduction) Airbnb provides an online platform for hosts to accommodate guests with shor ...
- 数据科学家应该掌握的12种机器学习算法
算法已经成为我们日常生活的一个重要组成部分,它们几乎出现在商业的任何领域.调查公司 Gartner 称这种现象为「算法化商业」,算法化商业正在改变我们经营和管理公司(应有的)的方式.现在,你可以在「算 ...
- 深度学习算法和机器学习算法_啊哈! 4种流行的机器学习算法的片刻
深度学习算法和机器学习算法 Most people are either in two camps: 大多数人都在两个营地中: I don't understand these machine lea ...
- 关联规则挖掘算法_关联规则的挖掘与应用——Apriori和CBA算法
文|光大科技大数据部 魏乐 卢格润 1 关联规则 1.1 关联规则基本概念 1.2 Apriori算法基本思路 2 关联分类 2.1 CBA关联分类算法思路 2.2 CBA算法实现 总结 关 ...
- 独家 | 数据科学家指南:梯度下降与反向传播算法
作者:Richmond Alake 翻译:陈之炎 校对:zrx本文约3300字,建议阅读5分钟 本文旨在为数据科学家提供一些基础知识,以理解在训练神经网络时所需调用的底层函数和方法. 标签:神经网络, ...
- dijkstra算法代码_数据科学家需要知道的5种图算法(附代码)
在本文中,我将讨论一些你应该知道的最重要的图算法,以及如何使用Python实现它们. 作者:AI公园 导读 因为图分析是数据科学家的未来. 作为数据科学家,我们对pandas.SQL或任何其他关系数据 ...
- 数据探查_数据科学家,开始使用探查器
数据探查 Data scientists often need to write a lot of complex, slow, CPU- and I/O-heavy code - whether y ...
最新文章
- python中一共有多少个关键字-Python之33个关键字是哪些
- ng-repeat 设定select 选择项
- 利用Python搜索51CTO推荐博客并保存至Excel
- GPS模块输出的NMEA数据ddmm.mmmm转换成dd.ddddd,在google Earth Pro中描点
- javascript中的字符串和数组的互转
- linux查看目录下 开头,Linux下ls如何看到.开头的文件
- hdu 6016 Count the Sheep
- uni app 录音结束监听_全新重构,uni-app实现微信端性能翻倍
- python的核心理念_python核心基础 - 草稿
- 零基础入门语义分割-Task4 评价函数与损失函数
- node.js 资料
- 【坐标标注】点坐标标注插件使用手册,可支持批量标注
- AndroidStudio配置夜神模拟器
- 图形界面中消息盒子的使用
- 计算机专业学生的学期规划,大学生大一下学期规划
- Tivoli基础架构管理解决方案
- excel怎么把两个表格合成一个
- 跨端融合!探索前沿科技无限可能,深圳腾讯2018TLC大会再度来袭,早鸟票最后一天...
- 微信小程序:云开发表情包制作源码
- 公司网站建设的几点建议—竹晨网络