推荐系统中协同过滤算法实现分析(重要两个图!!)
“协”,指许多人协力合作。
“协同”,就是指协调两个或者两个以上的不同资源或者个体,协同一致地完成某一目标的过程。
“协同过滤”,简单来说,就是利用兴趣相投或拥有共同经验的群体的喜好来给用户推荐感兴趣的信息,记录下来个人对于信息相当程度的回应(如评分),以达到过滤的目的,进而帮助别人筛选信息。回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
最近研究Mahout比较多,特别是里面协同过滤算法;于是把协同过滤算法的这个实现思路与数据流程,总结了一下,以便以后对系统做优化时,有个清晰的思路,这样才能知道该如何优化且优化后数据亦能正确。
推荐中的协同过滤算法简单说明下:
首先,通过分析用户的偏好行为,来挖掘出里面物品与物品、或人与人之间的关联。
其次,通过对这些关联的关系做一定的运算,得出人与物品间喜欢程度的猜测,即推荐值。
最后,将推荐值高的物品推送给特定的人,以完成一次推荐。
这里只是笼统的介绍下,方便下边的理解,IBM的一篇博客对其原理讲解得浅显易懂,同时也很详细《深入推荐引擎相关算法 - 协同过滤》,我这里就不细讲了。
协同过滤算法大致可分为两类,基于物品的与基于用户的;区分很简单,根据上面的逻辑,若你挖掘的关系是物品与物品间的,就是基于物品的协同过滤算法,若你挖掘的关系是用户与用户间的,就是基于用户的协同过滤算法;由于它们实现是有所不同,所以我分开整理,先来看看基于物品的协同过滤实现,我自己画了一幅图:
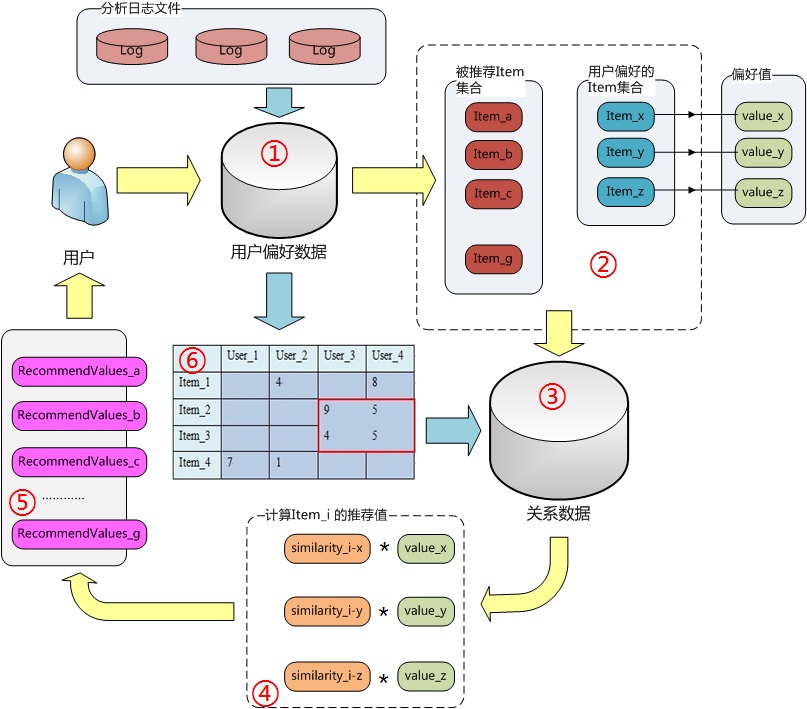
我通过数字的顺序,来标示数据变化的方向(由小到大);下面分析下每一个步骤的功能以及实现。
首先,说明下两个大的数据源,用户偏好数据:UserID、ItemID、Preference:表示一个对一个物品的喜好程度;关系数据:ItemIDA(UserIDA)、ItemIDB(UserIDB)、Similarity:表示两个人或物品间的相似程度;接着一个用户来了,我们需要为其推荐,得拿到他的身份标示,一般是UserID,于是:
①. 查找这个用户喜欢过的物品(即偏好的产品,并查出偏好值后面会用),以及还没有喜欢过的商品,前者是推荐运算的根据,后者作为一个产生推荐的一个集合;如② 画的那样。
②. 这里是一个可扩展的地方(我自己理解);因为这两部分的数据的作用非常明显,修改这两个集合对后面产生的推荐结果可产生非常直观的影响,比如清洗过滤,或根据用户属性缩小集合;不仅使后面推荐效果更优,运算性能也可以大幅度提高。
③. 查找这两个集合之间的关系,这是一对多的关系:一个没有偏好过的物品与该用户所有偏好过的物品间的关系,有一个值来衡量这个关系叫相似度Similarity;这个关系怎么来的,看蓝色箭头的指向。步骤⑥
④. 得到这个一对多的关系后,就可以计算这个物品对于这个用户的推荐值了,图中similarity_i-x表示Item_i 与 Item_x 之间的相似度,Item_x是该用户偏好过得,该用户对其偏好值记为 value_x ,相乘;Item_i 与 该用户偏好过的所有物品以此做以上运算后,得到的值取平均值 便是 Item_i的推荐值了。注:有可能Item_i 不是与所有 该用户偏好过的物品都都存在相似性,不存在的,不计算即可;另外这里方便理解介绍的都是最简单的实现;你也可以考一些复杂的数学元素,比如方差来判断离散性等。
⑤. 这步就简单多了,刚才对该用户没有偏好过的集合中的所有Item都计算了推荐值,这里就会得到一个list,按推荐值由大到小排序,返回前面的一个子集即可。
⑥。 前面已经提到,关系数据时怎么来的,也是根据用户的偏好数据;你把其看成一个矩阵,横着看过来,参考两个Item间的共同用户,以及共同用户的偏好的值的接近度;这里的可选择的相似度算法很多,不一一介绍了,前面提到的IBM博客也详细讲解了。
基于物品的协同过滤算法分析完了,下面是基于用户的协同过滤算法,还是自己画了一幅图:

①. 同样也是查询,只是查询的对象不一样了,查询的是与该用户相似的用户,所以一来直接查了关系数据源。以及相似用户与该用户的相似度。
②. 与刚才类似,也是对数据集的一个优化,不过作用可能没那么大。(个人感觉)
③. 查询关系数据源,得到相似用户即邻居偏好过的物品;如步骤④;图中由于空间小,没有把所有邻居的偏好关系都列出来,用……表示。其次还要得到该用户偏好过的物品集合。
④. 被推荐的Item集合是由该用户的所有邻居的偏好过的物品的并集,同时再去掉该用户自己偏好过的物品。作用就是得到你的相似用户喜欢的物品,而你还没喜欢过的。
⑤. 集合优化同基于物品的协同过滤算法的步骤②。
⑥. 也是对应类似的,依次计算被推荐集合中Item_i 的推荐值,计算的方式略有不同,Value_1_i表示邻居1对,Item_i的偏好值,乘以该用户与邻居1的相似度 Similarity1;若某个邻居对Item_i偏好过,就重复上述运算,然后取平均值;得到Item_i的推荐值。
⑦、⑧. 与上一个算法的最后两部完全类似,只是步骤 ⑧你竖着看,判断两个用户相似的法子和判断两个物品相似的法子一样。
详细的实现过程分析完了,但Mahout里面的实现时,似乎不太考虑查询的成本,并非一次全部查出,每计算个Item的推荐值查一次,你计算5000个就查5000次,若数据源都使用的是MySQL的话,我有点根儿颤,但一次全部查出再计算,肯定是个慢查询,且查询后的数据不是规则的,需要整,又添加了计算量;若各位有好的优化思路,望能分享下,先谢过。
原文地址:https://blog.csdn.net/mousever/article/details/52518124
推荐系统中协同过滤算法实现分析(重要两个图!!)相关推荐
- 推荐系统中协同过滤算法实现分析
原创博客,欢迎转载,转载请注明:http://my.oschina.net/BreathL/blog/62519 最近研究Mahout比较多,特别是里面协同过滤算法:于是把协同过滤算法的这个实现思路与 ...
- [机器学习] 推荐系统之协同过滤算法(转)
[机器学习]推荐系统之协同过滤算法 在现今的推荐技术和算法中,最被大家广泛认可和采用的就是基于协同过滤的推荐方法.本文将带你深入了解协同过滤的秘密.下面直接进入正题. 1. 什么是推荐算法 推荐算法最 ...
- 吴恩达|机器学习作业8.1.推荐系统(协同过滤算法)
8.1.推荐系统(协同过滤算法) 1)题目: 在本次练习中,你将实现协同过滤算法并将它运用在电影评分的数据集上,最后根据新用户的评分来给新用户推荐10部电影.这个电影评分数据集由1到5的等级组成.数据 ...
- 《推荐系统》基于用户和Item的协同过滤算法的分析与实现(Python)
1:协同过滤算法简介 2:协同过滤算法的核心 3:协同过滤算法的应用方式 4:基于用户的协同过滤算法实现 5:基于物品的协同过滤算法实现 一:协同过滤算法简介 关于协同过滤的一个最经典的例子就是看电影 ...
- 推荐系统之协同过滤算法分布式实现(附代码实现)
图片来自网络 文章作者:Sunbow 高级工程师 编辑整理:Hoh Xil 导读:本文主要介绍协同过滤基础知识,以及分布式实现设计,并最终在 Spark 平台上对同现相似度.Cosine 相似度.欧几 ...
- 推荐系统-经典协同过滤算法【基于记忆的协同过滤算法、基于模型的协同过滤算法】
推荐系统-经典协同过滤理论基础实践 1.协同过滤推荐方法CF简介 协同过滤CF 基于记忆的协同过滤 ---- 用户和物品的相似度矩阵 用户相似度的推荐 物品相似度推荐 UserCF用户协同过滤算法 I ...
- 推荐系统 - 3 - 协同过滤算法、随机游走算法
本总结是是个人为防止遗忘而作,不得转载和商用. 本节的前置知识是我总结的"推荐系统 - 1.2". 协同过滤算法 基于用户行为的数据而设计的推荐算法被称为协同过滤算法(Collab ...
- Apache Mahout基于商品的协同过滤算法流程分析
最近使用mahout的itemBase协同过滤算法,研究了下他的源码,记录如下,以备后忘-- 其算法实现大致分四个主要的部分: 1.将输入数据转化成矩阵 2.计算相似性 3.还是转化数据格式,为计算预 ...
- 【机器学习入门到精通系列】推荐系统之协同过滤算法
文章目录 1 基于内容的推荐算法 2 协同过滤 3 矢量化:低秩矩阵分解 4 均值规范化 1 基于内容的推荐算法
最新文章
- 在线考试系统html模板,请问谁有在线考试系统的网页模板?
- [CareerCup] 11.2 Sort Anagrams Array 异位词数组排序
- 简易重采样resampler的实现
- 无线宝服务器连接不上,无线网络连接不上怎么办 为什么无线网络连接不上
- Gradle接口:Gradle构建元数据
- Spring Boot笔记-自动配置(Spring Boot封装成jar被其他项目引用)
- java 秒变成时间_使用Quarkus开发Java云原生应用
- 深度学习工程师能力评估标准
- DWM1000 帧过滤代码实现
- innerhtml与outerhtml的区别
- 聊聊那些知识管理软件
- android audiomixer,Android多媒体:AudioMixer
- php数组的作业,PHP数组
- 一直在寻找:我亲爱的朋友。
- iOS 12 - iOS 15,如何在iPhone上设置“早上好”功能
- gitlab设置自动备份
- STM32F103频率计
- 国企银行面试 信息科技岗研发岗面试经验
- MACOS PowerPoint导出指定分辨率的图片
- iOS调试技巧(转载)