Python爬虫入门实战之猫眼电影数据抓取(实战篇)
项目实战
静态网页实战
本节我们将为大家展现一个完整爬虫的大致过程,此次项目内容为提取猫眼电影TOP100榜中的所有电影信息并存储至CSV文件中,其首页地址为http://maoyan.com/board/4,在3.2.2中我们已经获取过第一页中的所有电影名了,但是如何获取第二页、第三页的数据呢,即获取第二页第三页对应的URL,那么我们可以在浏览器中不断翻页寻找地址栏中URL的变化规律:
第二页: http://maoyan.com/board/4?offset=10 第三页: http://maoyan.com/board/4?offset=20 第四页: http://maoyan.com/board/4?offset=30 ......
我们看见URL的改变规律就是参数offset值不断偏移,每页偏移的值为10,由此我们可以编写一个获取每页数据函数,接收参数就是页码数:
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } # 偏移参数,默认为0,即为第一页 params = { 'offset': 0 } def get_html(page): ''' 获取一页html页面 :param page: 页数 :return: 该页html页面 ''' params['offset'] = page * 10 url = 'http://maoyan.com/board/4' try: response = requests.get(url, headers=headers, params=params) if response.status_code == 200: html = response.text return html else: return -1 except: return None
当我们获取到html页面后,就可以提取相应的电影信息了,比如榜单张每一项电影都会有的属性:电影名称,主演,上映时间,评分等信息。提取信息有多种方式,下面我们利用正则表达式提取电影信息:
def parse_infor(html): ''' 提取html页面中的电影信息 :param html: html页面 :return: 电影信息列表 ''' # 编写正则字符串规则,提取 电影名,主演,上映时间,评分信息 pat = re.compile('<div class="movie-item-info">.*?<p.*?><a.*?>(.*?)</a></p>.*?<p.*?>(.*?)</p>.*?<p.*?>(.*?)</p>.*?</div>.*?<div.*?>.*?<p.*?><i.*?>(.*?)</i><i.*?>(.*?)</i></p>.*?</div>.*?</div>.*?</div>', re.S) # 得到一个二重列表 results = re.findall(pat, html) one_page_film = [] if results: for result in results: film_dict = {} # 获取电影名信息 film_dict['name'] = result[0] # 获取主演信息 start = result[1] # 替换字符串中的 '\n' 字符,即换行字符 start.replace('\n', '') # 去掉字符串两边的空格,并使用切片去除字符串开头的'主演:'三个字符 start = start.strip()[3:] film_dict['start'] = start # 获取上映时间信息 releasetime = result[2] # 使用切片去除字符串开头的'上映时间:'五个字符 releasetime = releasetime[5:] film_dict['releasetime'] = releasetime # 获取评分信息,由于评分是有两个字符拼接的,这里我们提取后也需要进行拼接操作 left_half =result[3] right_half = result[4] score = left_half + right_half film_dict['score'] = score # 打印该电影信息: print(film_dict) # 将该电影信息字典存入一页电影列表中 one_page_film.append(film_dict) return one_page_film else: return None
不熟悉正则读者要好好复习下前面的知识,虽然正则写起来可能会麻烦些,当时他的提取效率是最高的,接下来我们就可以将提取好的电影信息进行存储操作,这里我们存储为CSV文件:
def save_infor(one_page_film): ''' 存储提取好的电影信息 :param html: 电影信息列表 :return: None ''' with open('top_film.csv', 'a', newline='') as f: csv_file = csv.writer(f) for one in one_page_film: csv_file.writerow([one['name'], one['start'], one['releasetime'], one['score']])
以上是获取一页html页面并提取电影信息存储至CSV中的过程,接下来我们构造十页的URL便可以完成猫眼电影TOP100榜中的所有电影信息的获取和存储了,以下是完整程序:
import requests import re import csv import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } params = { 'offset': 0 } def get_html(page): ''' 获取一页html页面 :param page: 页数 :return: 该页html页面 ''' params['offset'] = page * 10 url = 'http://maoyan.com/board/4' try: response = requests.get(url, headers=headers, params=params) if response.status_code == 200: html = response.text return html else: return -1 except: return None def parse_infor(html): ''' 提取html页面中的电影信息 :param html: html页面 :return: 电影信息列表 ''' pat = re.compile('<div class="movie-item-info">.*?<p.*?><a.*?>(.*?)</a></p>.*?<p.*?>(.*?)</p>.*?<p.*?>(.*?)</p>.*?</div>.*?<div.*?>.*?<p.*?><i.*?>(.*?)</i><i.*?>(.*?)</i></p>.*?</div>.*?</div>.*?</div>', re.S) results = re.findall(pat, html) one_page_film = [] if results: for result in results: film_dict = {} # 获取电影名信息 film_dict['name'] = result[0] # 获取主演信息 start = result[1] # 替换字符串中的 '\n' 字符,即换行字符 start.replace('\n', '') # 去掉字符串两边的空格,并使用切片去除字符串开头的'主演:'三个字符 start = start.strip()[3:] film_dict['start'] = start # 获取上映时间信息 releasetime = result[2] # 使用切片去除字符串开头的'上映时间:'五个字符 releasetime = releasetime[5:] film_dict['releasetime'] = releasetime # 获取评分信息 left_half =result[3] right_half = result[4] score = left_half + right_half film_dict['score'] = score # 打印该电影信息: print(film_dict) # 将该电影信息字典存入一页电影列表中 one_page_film.append(film_dict) return one_page_film else: return None def save_infor(one_page_film): ''' 存储提取好的电影信息 :param one_page_film: 电影信息列表 :return: None ''' with open('top_film.csv', 'a', newline='', errors='ignore') as f: csv_file = csv.writer(f) for one in one_page_film: csv_file.writerow([one['name'], one['start'], one['releasetime'], one['score']]) if __name__ == "__main__": # 利用循环构建页码 for page in range(10): # 请求页面 html = get_html(page) if html: # 提取信息 one_page_film = parse_infor(html) if one_page_film: # 存储信息 save_infor(one_page_film) time.sleep(1)
动态网页实战
本节我们将爬取猫眼电影实时票房数据,学会在动态网页中获取我们想要的数据,首先打开猫眼专业版-实时票房, 其网址为:https://piaofang.maoyan.com/dashboard,然后我们可以看见现在的实时电影票房数据,可以看见 “今日实时” 的数据在不断地动态增加:
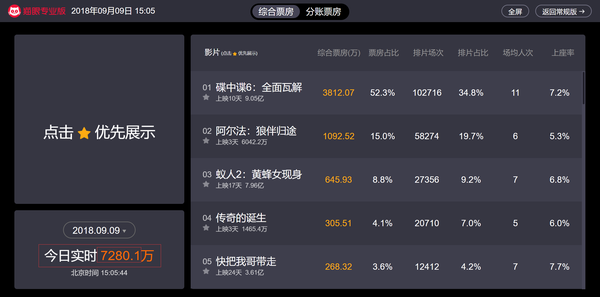
而当我们查看该网页源代码时,却并没有电影相关的票房等信息,那么可以判断该页面可能使用了Ajax(即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML))技术,即动态网页(是指跟静态网页相对的一种网页编程技术。静态网页,随着html代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非你修改页面代码。而动态网页则不然,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变)。我们可以利用浏览器的开发者工具进行分析:
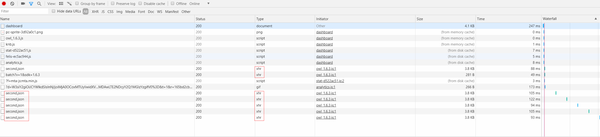
我们可以发现每隔一段时间都会有一个新的请求,其请求类型都为xhr,而Ajax的请求类型就是xhr,这请求可能就是实时更新的票房信息,而我们需要的数据可能就在这些文件里,于是我们选择一个进行分析:
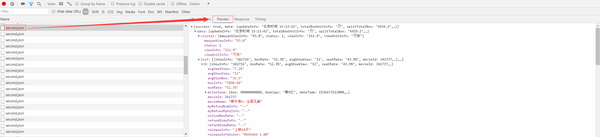
在Preview中,我们可以看见大量的电影相关的信息,即我们想要获取的实时电影票房数据,而这些内容是JSON格式的,浏览器开发者工具自动做了解析方便我们查看,接下来我们只需要用Python模拟这些Ajax请求,拿下这些数据然后解析即可,而这些Ajax无非依然是HTTP请求,所以只要拿到对应URL然后使用Python模拟该请求即可,我们可以直接复制,如下图:
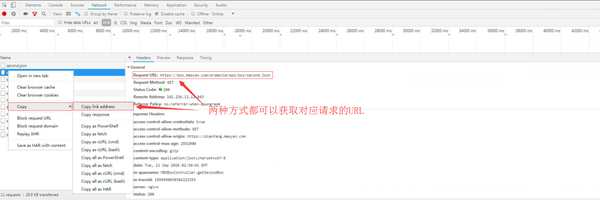
获取到该请求的链接,接下来我们就用Python模拟该请求:
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } def get_html(): ''' 获取JSON文件 :return: JSON格式的数据 ''' # 请求second.json的URL url = 'https://box.maoyan.com/promovie/api/box/second.json' try: response = requests.get(url, headers=headers) if response.status_code == 200: # 由于是JSON文件,我们可以返回JSON格式的数据便于后续提取 return response.json() else: return -1 except: return None
获取对应的JSON数据后,我们就可以利用进行提取操作了。
def parse_infor(json): ''' 从JSON数据中提取电影票房数据,包括:电影名,上映信息,综合票房,票房占比,累计票房 :param json: JSON格式的数据 :return: 每次循环返回一次字典类型的电影数据 ''' if json: # 利用json中的get()方法层层获取对应的信息 items = json.get('data').get('list') for item in items: piaofang = {} piaofang['电影名'] = item.get('movieName') piaofang['上映信息'] = item.get('releaseInfo') piaofang['综合票房'] = item.get('boxInfo') piaofang['票房占比'] = item.get('boxRate') piaofang['累计票房'] = item.get('sumBoxInfo') # 利用生成器每次循环都返回一个数据 yield piaofang else: return None
读者可能看见我们没有使用常规的return进行函数返回,而是使用了生成器,这样就能每次循环都返回一次数据,具体读者可以生成器 | 廖雪峰的官方网站进一步了解学习,接下来我们就将提取好的票房信息存储为格式化的HTML文件:
def save_infor(results): ''' 存储格式化的电影票房数据HTML文件 :param results: 电影票房数据的生成器 :return: None ''' rows = '' for piaofang in results: # 利用Python中的format字符串填充html表格中的内容 row = '<tr><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td></tr>'.format(piaofang['电影名'], piaofang['上映信息'], piaofang['综合票房'], piaofang['票房占比'], piaofang['累计票房']) # 利用字符串拼接循环存储每个格式化的电影票房信息 rows = rows + '\n' + row # 利用字符串拼接处格式化的HTML页面 piaofang_html = ''' <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>电影票房</title> </head> <body> <style> .table1_5 table { width:100%; margin:15px 0 } .table1_5 th { background-color:#00BFFF; color:#FFFFFF } .table1_5,.table1_5 th,.table1_5 td { font-size:0.95em; text-align:center; padding:4px; border:1px solid #dddddd; border-collapse:collapse } .table1_5 tr:nth-child(odd){ background-color:#aae9fe; } .table1_5 tr:nth-child(even){ background-color:#fdfdfd; } </style> <table class='table1_5'> <tr> <th>电影名</th> <th>上映信息</th> <th>综合票房</th> <th>票房占比</th> <th>累计票房</th> </tr> ''' + rows + ''' </table> </body> </html> ''' # 存储已经格式化的html页面 with open('piaofang.html', 'w', encoding='utf-8') as f: f.write(piaofang_html)
我们将以上过程整合,即可得到完整的票房数据获取的代码实例:
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' } def get_html(): ''' 获取JSON文件 :return: JSON格式的数据 ''' # 请求second.json的URL url = 'https://box.maoyan.com/promovie/api/box/second.json' try: response = requests.get(url, headers=headers) if response.status_code == 200: # 由于是JSON文件,我们可以返回JSON格式的数据便于后续提取 return response.json() else: return -1 except: return None def parse_infor(json): ''' 从JSON数据中提取电影票房数据,包括:电影名,上映信息,综合票房,票房占比,累计票房 :param json: JSON格式的数据 :return: 每次循环返回一次字典类型的电影数据 ''' if json: # 利用json中的get()方法层层获取对应的信息 items = json.get('data').get('list') for item in items: piaofang = {} piaofang['电影名'] = item.get('movieName') piaofang['上映信息'] = item.get('releaseInfo') piaofang['综合票房'] = item.get('boxInfo') piaofang['票房占比'] = item.get('boxRate') piaofang['累计票房'] = item.get('sumBoxInfo') # 利用生成器每次循环都返回一个数据 yield piaofang else: return None def save_infor(results): ''' 存储格式化的电影票房数据HTML文件 :param results: 电影票房数据的生成器 :return: None ''' rows = '' for piaofang in results: # 利用Python中的format字符串填充html表格中的内容 row = '<tr><td>{}</td><td>{}</td><td>{}</td><td>{}</td><td>{}</td></tr>'.format(piaofang['电影名'], piaofang['上映信息'], piaofang['综合票房'], piaofang['票房占比'], piaofang['累计票房']) # 利用字符串拼接循环存储每个格式化的电影票房信息 rows = rows + '\n' + row # 利用字符串拼接处格式化的HTML页面 piaofang_html = ''' <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>电影票房</title> </head> <body> <style> .table1_5 table { width:100%; margin:15px 0 } .table1_5 th { background-color:#00BFFF; color:#FFFFFF } .table1_5,.table1_5 th,.table1_5 td { font-size:0.95em; text-align:center; padding:4px; border:1px solid #dddddd; border-collapse:collapse } .table1_5 tr:nth-child(odd){ background-color:#aae9fe; } .table1_5 tr:nth-child(even){ background-color:#fdfdfd; } </style> <table class='table1_5'> <tr> <th>电影名</th> <th>上映信息</th> <th>综合票房</th> <th>票房占比</th> <th>累计票房</th> </tr> ''' + rows + ''' </table> </body> </html> ''' # 存储已经格式化的html页面 with open('piaofang.html', 'w', encoding='utf-8') as f: f.write(piaofang_html) if __name__ == "__main__": # 获取信息 json = get_html() # 提取信息 results = parse_infor(json) # 存储信息 save_infor(results)
HTML文件存储效果如下图所示:
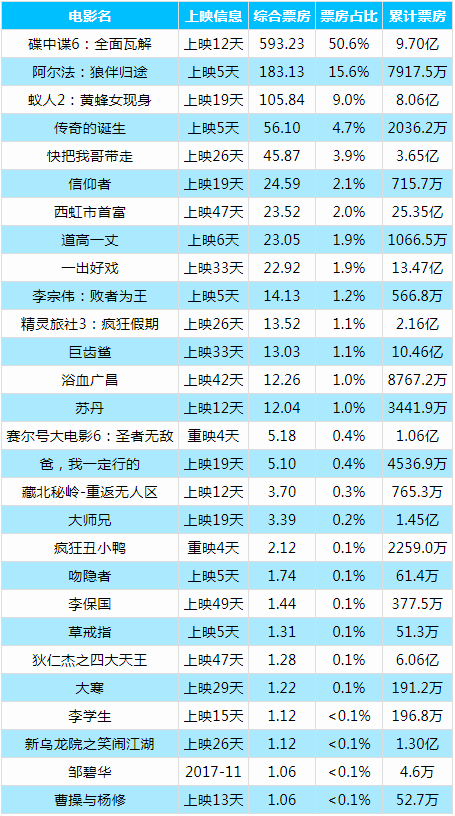
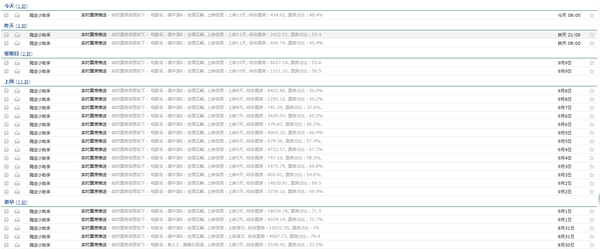
可以看见,动态网页的爬虫可能会更加简单些,关键就在于找到对应的XHR格式的请求,而一般这种格式的文件都是JSON格式的,提取相对也会更加简单方便,而读者可能会问为何要把这个信息存储为HTML文件格式的呢,喜欢电影的读者可能会经常打开猫眼电影查看每天的电影票房数据,何不尝试将我们所学的爬虫知识运用起来制作一个定时爬取电影票房数据并推送至个人邮箱的爬虫小程序呢,这样就省得我们每天打开网页查看,让数据主动为我们服务,也算是学习致用了吧,感兴趣的读者可以自己尝试下,下图笔者根据这个爬虫程序扩展每天收到的实时票房信息邮件,每天定时爬取推送给笔者,列表内容如下图所示:
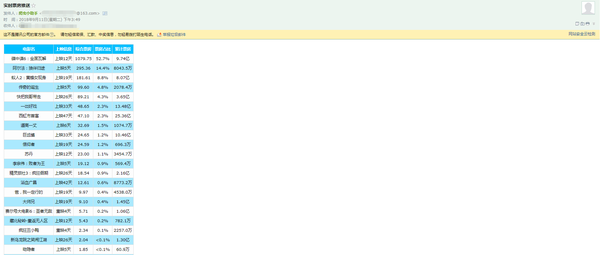
推动内容如下图所示:
因为邮箱定时推送会涉及邮箱设置、邮箱模块使用和不同系统(Linux和Windows)定时任务的部署等诸多环节,感觉会有些偏题,毕竟这是一篇爬虫入门方面的文章,笔者把这部分实战内容放到了微信公众号上,想要了解的同学可以关注公众号“若数”学习。 如果反响不错的话,笔者会推出更多的进阶实战,比如selenium的使用、代理、模拟登陆、APP爬取等实战内容,谢谢大家的阅读,拜拜~
Python爬虫入门实战之猫眼电影数据抓取(实战篇)相关推荐
- Python爬虫入门实战之猫眼电影数据抓取(理论篇)
前言 本文可能篇幅较长,但是绝对干货满满,提供了大量的学习资源和途径.达到让读者独立自主的编写基础网络爬虫的目标,这也是本文的主旨,输出有价值能够真正帮助到读者的知识,即授人以鱼不如授人以渔,让我们直 ...
- python编程理论篇_Python爬虫入门实战之猫眼电影数据抓取(理论篇)
前言 本文可能篇幅较长,但是绝对干货满满,提供了大量的学习资源和途径.达到让读者独立自主的编写基础网络爬虫的目标,这也是本文的主旨,输出有价值能够真正帮助到读者的知识,即授人以鱼不如授人以渔,让我们直 ...
- python爬虫入门实战争胜法_Python爬虫入门实战之猫眼电影数据抓取(理论篇)
前言 本文可能篇幅较长,但是绝对干货满满,提供了大量的学习资源和途径.达到让读者独立自主的编写基础网络爬虫的目标,这也是本文的主旨,输出有价值能够真正帮助到读者的知识,即授人以鱼不如授人以渔,让我们直 ...
- python 爬虫实例 电影-Python爬虫入门实战之猫眼电影数据抓取(实战篇)
电影名 上映信息 综合票房 票房占比 累计票房
- 猫眼api html,猫眼电影数据抓取
猫眼电影数据抓取实现分析 1.基准xpath: 匹配所有电影信息的节点对象列表 '//dl[@class="board-wrapper"]/dd' 2.遍历对象列表,依次获取每个电 ...
- python爬虫之Ajax动态加载数据抓取--豆瓣电影/腾讯招聘
动态加载数据抓取-Ajax 特点 1.右键 -> 查看网页源码中没有具体数据 2.滚动鼠标滑轮或其他动作时加载 抓取 1.F12打开控制台,页面动作抓取网络数据包 2.抓取json文件URL地址 ...
- Python爬虫4.2 — ajax(动态网页数据抓取)用法教程
Python爬虫4.2 - ajax[动态网页数据]用法教程 综述 AJAX 介绍 什么是AJAX 实例说明 请求分析 获取方式 实例说明 其他博文链接 综述 本系列文档用于对Python爬虫技术的学 ...
- python爬虫之app数据抓取_Python爬虫入门教程 29-100 手机APP数据抓取 pyspider
1. 手机APP数据----写在前面 继续练习pyspider的使用,最近搜索了一些这个框架的一些使用技巧,发现文档竟然挺难理解的,不过使用起来暂时没有障碍,估摸着,要在写个5篇左右关于这个框架的教程 ...
- 分页请求json数据_Python爬虫入门教程 28-100 虎嗅网文章数据抓取 pyspider
1. 虎嗅网文章数据----写在前面 今天继续使用pyspider爬取数据,很不幸,虎嗅资讯网被我选中了,网址为 https://www.huxiu.com/ 爬的就是它的资讯频道,本文章仅供学习交流 ...
最新文章
- Handler 实现的一个延时操作
- JS 实现下载Blod文件
- bitwarden自建服务器,BitWarden
- 【树莓派】【转载】基于树莓派,制作家庭媒体中心+下载机
- 法律规则鬼畜图解||全面易懂的旅游投诉赔偿标准
- windows系统磁盘使用记录(自用)
- ElasticSearch5.4X 搜索引擎查询java工具类
- 记录一次和朋友聊天遇到的面试题 ip地址字符串和long类型的相互转换 都是参考了别人的代码 加了一些个人理解的总结
- torch.randn
- 刮刮乐html5效果擦除,HTML5实现刮刮卡的效果
- 去掉Mac窗口截图自带的阴影?
- PHP+Selenium爬虫 物理跳过反爬虫机制 PHP爬虫最佳实践方案分享
- 关于继承BaseServlet后为什么form表单中必须加上method=“post”
- 笛卡尔坐标系和齐次坐标系
- ETH 或者 ERC20 如何通过 TxID 查询充值状态
- 2021年浙江省跨境电商行业发展概况及发展趋势分析[图]
- 全国24小时降水量pyecharts可视化分析
- 【新知实验室TRTC】
- SECTION 11 安装软件程序
- 2021年建筑架子工(建筑特殊工种)考试及建筑架子工(建筑特殊工种)新版试题