搜索引擎(0xFE)--- 用机器学习再谈排序
2019独角兽企业重金招聘Python工程师标准>>> 
这里没有标记颜色,可能看起来重点不突出,可以去微信页面观看这里
前面说排序的时候已经简单了说了一下排序的方法,包括三部分:相关性排序,商品本身的属性排序,个性化排序,无论怎么排,大体上都逃不掉这三项。
最近看到一篇文章有赞搜索引擎实践(算法篇),中间有一段也说了如何对商品本身的属性进行排序,感兴趣的也可以去看看。
今天,说说如何用机器学习的办法来进行排序(商品本身的属性排序)。
说起机器学习,是个很大的话题,我也不是专家,但是至少用机器学习这个工具还是没什么大问题的,今天我们深入一下机器学习中的逻辑回归,看看如何用逻辑回归来进行排序。
我尽量不会用大量公式,尽量用说人话的方式说一下机器学习的逻辑回归,有些东西我会直接给出结论,如果感兴趣的可以去查资料,好了,开始吧,看我们如何从数据开始,一步一步来做到商品属性的排序的。
前期准备
首先,我们确定一下背景,就是在什么场景下排序,假设我们是一个电商搜索引擎,搜索的数据就是各种各样的商品,并且通过关键字,很多商品的打分是一样的,无法进行区分了,所以需要对这些商品进行商品质量的排序。
然后,我们有哪些数据可以用来进行排序呢?为了简单起见,我们假设我们有最近半年的每个商品的销量,每个商品的收藏数量,每个商品的点击次数这三种数据。
目标
我们有每个商品的销量,每个商品的收藏数量,每个商品的点击次数这三种数据,那我们的目标是什么呢?
既然要确定好还是不好,那么必然最后我们会给每个商品打一个分,分越高越好,我们有上面的数据,那么这个分数我们这么来定义(没有使用点击次数是为了后面说明比较直观,把点击当结果了)
Score = a1*销量 + a2*收藏数量
而我们的目标就是求出a1和a2来(请牢记这一目标),那么以后我们每看到一个商品,用上面这个分数公式一算,就知道这个商品多少分了。
衡量商品
我们的目标是把好的商品排在前面,怎么样来衡量一个商品是好还是不好呢?有种直观的办法来确定,找一群人,然他们凭直观感觉搜索结果中排前面的商品好不好
但这里我们用个简单的办法,就是商品被点击超过10次,我们认为就是好商品,而我们有最近半年的数据,所以我们知道哪些是好商品,哪些是不好的商品。
开始排序
好了,前期准备工作完成了,目标也确定了,我们开始机器学习的排序了。
我们使用的是逻辑回归的方法,如果看维基百科的定义的话,不见得你能明白,我们这里就不做名词解释了,你把它看成一个方法就行了。
为了简单起见,我们假设一共只有6个商品,他们的销量和收藏数量分别是下表,现在,我们一步一步来完成对目标a1和a2的求解。
| 商品 | 销量 | 收藏量 |
|---|---|---|
| A1 | 50 (1.69) | 20(1.30) |
| A2 | 30(1.47) | 60(1.77) |
| A3 | 500(2.70) | 60(1.77) |
| B1 | 30(1.47) | 5(0.70) |
| B2 | 5(0.70) | 30(1.47) |
| B3 | 1(0) | 10(1.00) |
数据归一化
首先,我们需要做的是将数据标准化,也就是归一化。
为什么要归一化数据呢?比如上表中的A3,他的销量是500,和其他的所有的商品的销量差别特别大,所以如果用a1*销量 + a2*收藏数量这个公式来计算分数的话,它就特别占便宜,随随便便就排到前面去了,但是有可能这个商品只是搞了一次1折促销,所以销量突然变大的,对于这种情况,我们就要通过归一化把数据变得尽量在一个可控的区间中。
数据归一化的方法比较多,我们这里用个简单的,直接取log值来归一化,那么上面的数据就被归一化到一个可控的范围内了,这样计算分数的时候一些突变数据就很难占便宜了,上面数据后面括号里面就是归一化以后的数,比较靠谱了吧。
sigmoid函数
到这里,我们目前已经拥有了下面的东西
- 上面表的归一化好的数据
- 一个计算分数的公式:a1*销量 + a2*收藏数量
如果商品的好和坏用1和0表示的话,要是我们能将上面的计算分数的公式和好坏联系起来就好了,好了,直接出结论,真有这样的函数,这个函数叫sigmoid函数,他长成这样:
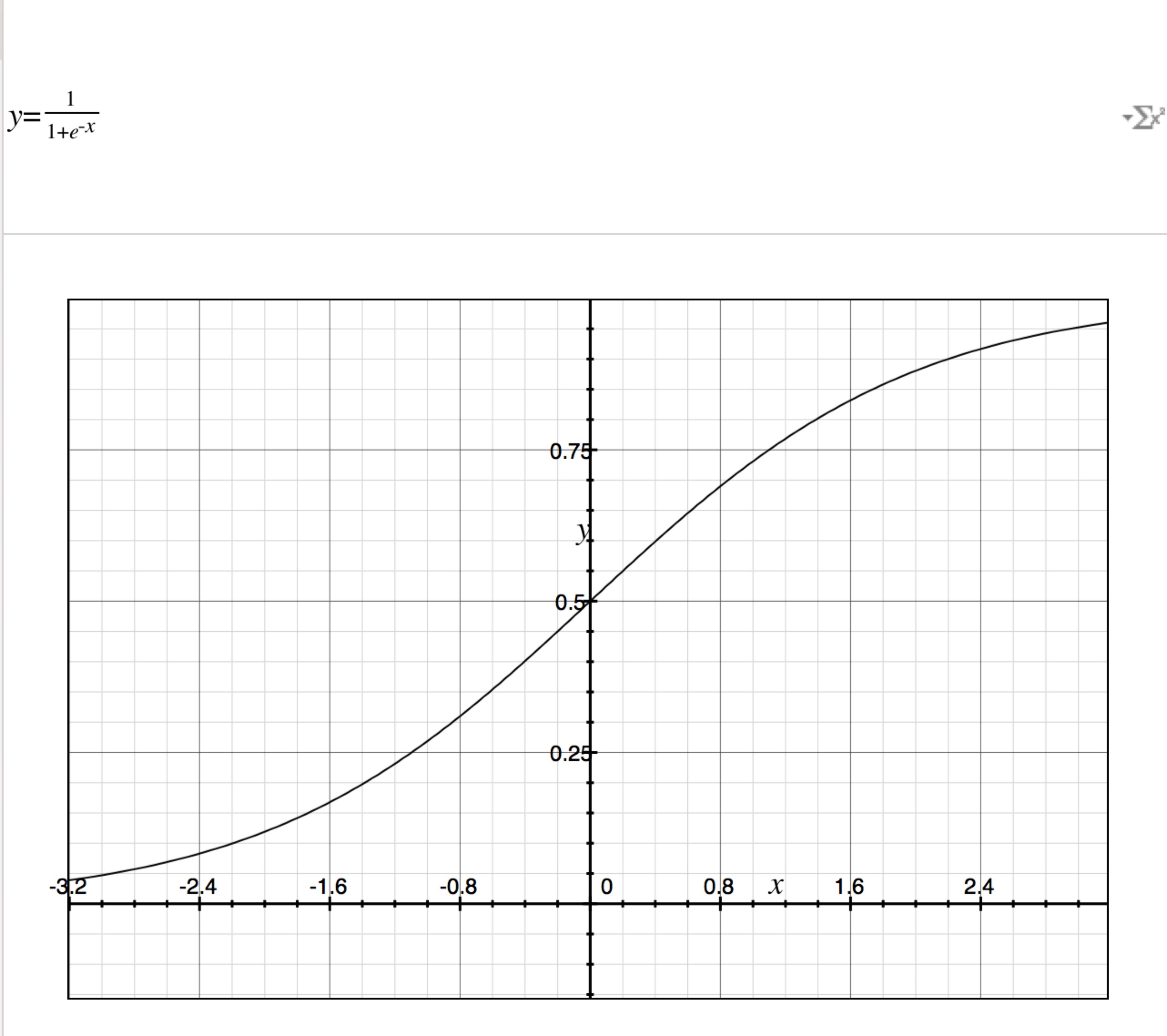
这个可以将任何东西变成0到1之间的值,我们再取巧一点,在0到1之间如果大于0.5我们就认为是1,小于0.5我们认为是0的话,那么这个算分公式就和好坏联系起来了。
根据已知的条件,我们可以列出下面的东西
A1的好坏值 = sigmoid( a1*A1的销量 + a2*A1的收藏数量 ) A2的好坏值 = sigmoid( a1*A2的销量 + a2*A2的收藏数量 ) A3的好坏值 = sigmoid( a1*A3的销量 + a2*A3的收藏数量 ) B1的好坏值 = sigmoid( a1*B1的销量 + a2*B1的收藏数量 ) B2的好坏值 = sigmoid( a1*B2的销量 + a2*B2的收藏数量 ) B3的好坏值 = sigmoid( a1*B3的销量 + a2*B3的收藏数量 )
好了,到这一步,我们的原始数据(销量,收藏数量)就和商品的好坏联系起来了。
代价函数
至此,我们已经有了以下几个东西了:
- 上面表的归一化好的数据
- 一个计算分数的公式:a1*销量 + a2*收藏数量
- 一个计算商品好坏的公式:sigmoid( a1*商品销量 + a2*商品收藏数量 )
除了上面的,我们还有5个月的真实数据,也就是我们知道每个商品实际是否真被点击了,如果我们按照上面衡量商品的方法统计一下,我们就得到了一批真实的好商品和一批真实的坏商品,假设分别是A1,A2,A3和B1,B2,B3,如果我们找到一个a1和a2,用计算商品好坏的公式把所有商品一算,如果和真实的好坏一致,那么a1和a2就是我们要找的目标了。
那么,怎么来描述我们算的结果和实际结果的差异呢?这里再引入一个公式(这是最后一个公式),我不做推导了,直接给出来,这个公式长成这样子,它表示每一个商品预测的好坏和实际的好坏的差异
-log(sigmoid( a1*销量 + a2*收藏数量 )) — 实际被点击的时候 -log(1 - sigmoid( a1*销量 + a2*收藏数量 ) ) — 实际没有被点击的时候
有了这个公式,那么总体的差异就是每个商品的差异求和除以商品数了,我们叫代价函数,就是下面这个公式,X1和X2对应的就是销量和收藏数量,m表示一共有多少个商品,代价函数的值越小,那么对应的a1和a2就越接近我们需要的值。
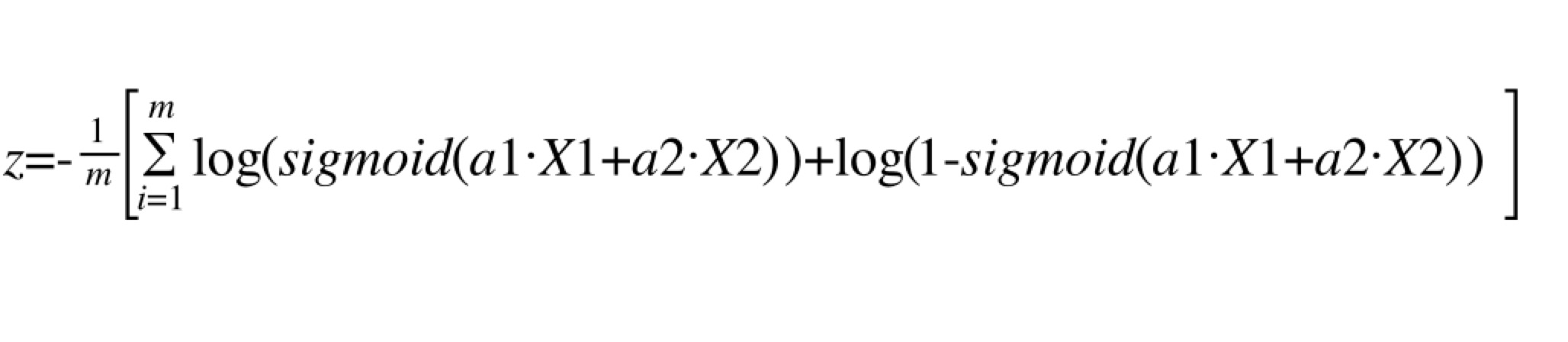
开始求解
至此,我们有了以下内容了
- 上面表的归一化好的数据
- 一个计算分数的公式:a1*销量 + a2*收藏数量
- 一个计算商品好坏的公式:sigmoid( a1*商品销量 + a2*商品收藏数量 )
- 实际每个商品的好坏A1,A2,A3为好商品,B1,B2,B3为坏商品
- 有一个预测值和实际值比较差异的代价函数,可以用来判断我们预测得准不准
通过上面这么些步骤,最后,我们通过代价函数将我们通过销量和收藏预测出来的点击和实际的点击联系起来了,终于,我们完成了数据到商品实际好坏(是否真的被点击)的联系。
我们通过代价函数将我们通过销量和收藏预测出来的点击和实际的点击联系起来了,终于,我们完成了数据到商品实际好坏(是否真的被点击)的联系。
我们通过代价函数将我们通过销量和收藏预测出来的点击和实际的点击联系起来了,终于,我们完成了数据到商品实际好坏(是否真的被点击)的联系。
重点说三遍,相当于我们的排序模型已经建立起来了
梯度下降
好了,前面铺垫了这么多,终于要开始求解a1和a2了。
首先,我们有一个函数,这个函数是上面的最后一个公式,我们再写一遍

这里的a1和a2是未知数,也就是我们要求的,其他的都是已知的,通过已有的六个月的销量和收藏的值,以及不断变化a1和a2,我们可以画出这个函数的三维图像(我直接用mac的画图软件画的,和数据对应不上,但不影响我们的分析),其中X,Y轴分别表示a1和a2,Z轴表示代价函数的值。
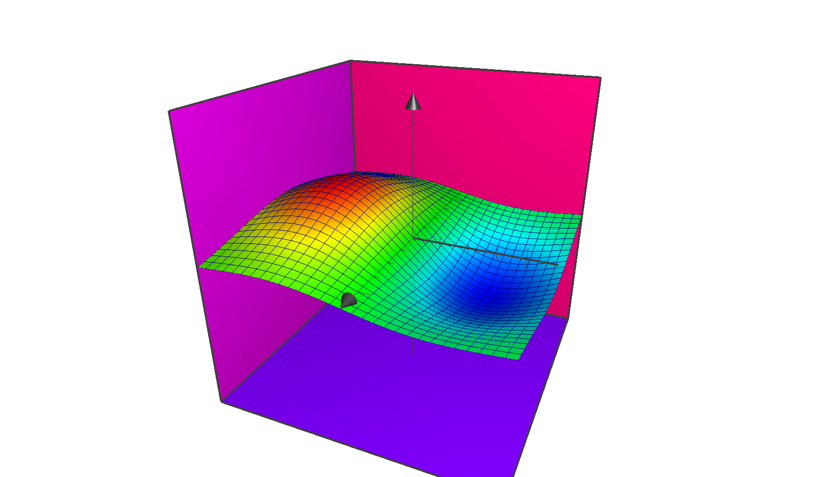
我们要求的a1和a2,实际上就是这个代价函数的最小值的情况下的a1和a2,也就是图像中蓝色的区域对应的a1和a2值。
通过上面这么多步骤,我们终于把求a1和a2变成了求一个函数的最小值。
要求解出这个函数的最小值,接下来就看计算机的了,一个一个去试呗,看看哪两个参数下,整体的代价函数值最小,那么就用这个a1和a2了。呵呵,傻子也看得出来这一个一个试的方法有多傻。
机器学习之所以叫机器学习,那么至少需要体现出来学习的能力吧,怎么体现呢?
一个一个值去试显然不是机器学习,那叫穷举,机器学习就是我先试一个值,然后看看和实际结果有多少差异,然后去调整这个值,让新的结果和实际结果的差距变小,直到差距变得最小,这样的过程才叫机器学习。
我们通过一个叫梯度下降的迭代运算,可以得出满足差异最小化的a1和a2的值,什么叫梯度下降我这里不描述了,感兴趣的可以自己去查资料,因为这一部分涉及的数学内容太多,我也描述得不好,大家看着也没兴趣。真正感兴趣的可以自己去查查资料。
简单来说,就是先随便选一个a1和a2,比如下图中的红色部分的白点,计算出一个代价函数的值,然后通过求代价函数的偏导数,我们就知道了如何调整这个a1和a2,那么通过一步一步的迭代循环(这一步一步的迭代就是机器学习的过程了),沿着白点的路径,我们就可以走到图像蓝色的部分,从而得到满足最小值的a1和a2,这样可以通过有限的几次迭代运算,而不用求出全部的a1和a2来得到最小值。
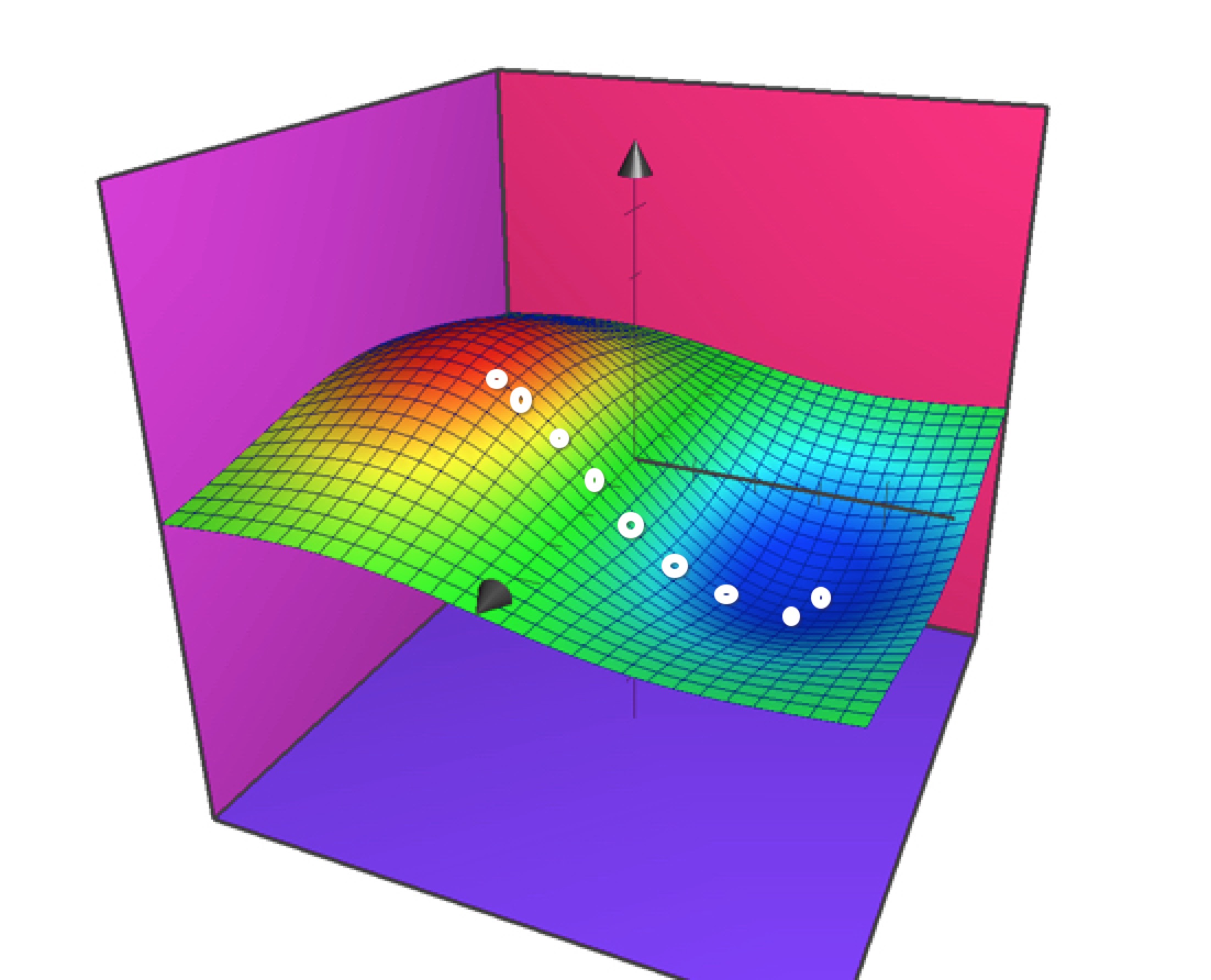
现在,通过梯度下降的算法,就求出a1和a2了,我们的目标也就达成了。
使用a1和a2
好了,上面通过一系列步骤,a1和a2已经求出来了,使用起来就简单了,碰到任何一个商品,通过上面的算分公式a1*销量 + a2*收藏数量就可以直接算出来这个商品的分数,在排序的时候按这个分数排序就行了。
评估
有了这个a1和a2,我们如何来评估好还是不好呢?
我们不是有最近半年的数据么,那么我们只用其中5个月的数据来计算a1和a2,然后用最后一个月的数据来测试,把数据套入公式中看看预测的点击和真实的点击准不准,准确度越高那么就越有效。
当然,最直接的办法还是上线以后做AB测试,看用户买单不买单了。
写在后面的话
这篇文章我尽量没有特意去写逻辑回归的数学原理,只是用工程化的思想将排序的方式说了一遍,没有特别涉及数学原理,如果感兴趣我可以再写一篇来说说逻辑回归的数学原理,不过估计看的人少,我也怕我这半桶水写不好,呵呵。
上面的方法我们使用了销量和收藏数据,其实任何一个你认为可能会影响排序的因素都可以用来排序,每一个因素叫一个feature,比如发货速度,购物车添加次数,最近7天点击次数,最近一个月点击次数,评论数,好评数,图片数量,发货范围,甚至包括图片的好看程度,这样,求a1和a2就变成了求a1,a2...an了,每个因素对应一个权重,算法没有任何区别。
如果我们有个特别牛逼的专家,他说别算了,也别搞那么多因素,就选销量和收藏数量,按我的直觉来,拍一个权重:a1等于0.9,a2等于0.1,结果一上线,效果出奇的好,用户哗哗点击,哗哗下单啊。有没有这种可能呢???当然有!!因为机器学习的方法来计算排序,本质上是因为我们有大量的数据而人工无法处理,我们觉得这些数据有用,于是我们想出来机器学习的办法来使用这些数据,最后的可解释性其实不强,你算出来a1等于0.86,a2等于0.14,为什么呢??看似一步一步都是按照数学公式来的,但其实不好解释,就和人的直觉一样,不见得比专家的直觉强。
好了,本篇结束,你有什么问题可以留言,但可能我也da不出来,所以不见得会回哦。。
最后,欢迎关注我:)主要说说搜索,推荐,广告的架构和算法,以及一个搜索引擎的实现,有时也会瞎扯一下

转载于:https://my.oschina.net/wuyinghao/blog/674387
搜索引擎(0xFE)--- 用机器学习再谈排序相关推荐
- 再谈排序算法的pairwise,pointwise,listwise
NewBeeNLP·干货 作者:DOTA 大家好,这里是 NewBeeNLP. 最近因为工作上的一些调整,好久更新文章和个人的一些经验总结了,下午恰好有时间,看了看各渠道的一些问题和讨论,看到一个熟悉 ...
- 【徒手写机器学习算法】再谈数据源:从普通图片到Cifar-10(使用C++)
[徒手写机器学习算法]再谈数据源:从普通图片到Cifar-10(使用C++) 在本系列的第一篇文章里,关于机器学习的数据源的问题被一笔带过(使用csv格式的数据),这一篇文章我会给出关于图片数据制作的 ...
- 再谈目前QQ空间主流的赚钱方法
重点导读 同样是腾讯旗下的产品,QQ空间和微信,这两个在今年都得到了重视,各种微信营销培训和QQ空间流量培训,满天飞,让很多新手朋友眼花缭乱.在这里我就说下,用QQ空间来获取人民币.因为QQ空间流量 ...
- tensorflow和python先学哪个-前辈说先学会了这些Python知识点,再谈学习人工智能!...
原标题:前辈说先学会了这些Python知识点,再谈学习人工智能! 首先我们看一看Python的优势: 开源,跨平台. 社区.不要小看这一点.社区意味着有很多教程.书籍,出了问题很容易google到,乃 ...
- 数据结构与算法--再谈递归与循环(斐波那契数列)
再谈递归与循环 在某些算法中,可能需要重复计算相同的问题,通常我们可以选择用递归或者循环两种方法.递归是一个函数内部的调用这个函数自身.循环则是通过设置计算的初始值以及终止条件,在一个范围内重复运算. ...
- 模板引擎工作原理_「白皮书解读搜索引擎的工作原理」如何排序
导读:搜索引擎是如何对网站进行排序的呢?今天解读的是索引. 本文解读的是:<百度官方课程检索排序> 1.检索排序原理 2.影响搜索结果排序的几个因素 一.检索排序原理 搜索引擎工作过程包括 ...
- 透过数字化转型再谈数据中台(三):一文遍历大数据架构变迁史
编者按:<透过数字化转型再谈数据中台>系列连载 6-8 篇左右,作者结合自己在数据中台领域多年实践经验,总结了数据架构知识.BI 知识,以及分享给大家一些产业互联网实施经验.本文是系列文章 ...
- 再谈P2P技术:网络拓扑结构、核心技术分析
随着P2P应用的蓬勃发展,作为P2P应用中核心问题的发现技术除了遵循技术本身的逻辑以外,也受到某些技术的发展趋势.需求趋势的深刻影响. P2P协议概述 P2P打破了传统的Client/Server ( ...
- 网络协议报文理解刨析篇二(再谈Http和Https), 加上TCP/UDP/IP协议分析(理解着学习), 面试官都惊讶你对网络的见解
目录 前文链接(系列助学, 也为后文学习做铺垫, 可按需读取) 一. 再谈HTTP再理解 二. HTTP对比学习HTTPS HTTP和HTTPS的区别如下: 三.TCP协议 (三次握手四次挥手细节过 ...
最新文章
- c语言程序开发过程上机步骤,C语言程序上机步骤2010.doc
- sql查询出的字段切割_SPL 简化 SQL 案例详解:多层固定分组
- Visio2007 与Microsoft Studio 2008不兼容
- Vue检测当前是否处于mock模式
- Team Foundation 和 Visual SourceSafe 之间的区别
- 经典问题8连:小球和盒子
- 现代Web开发需要学习的15大技术
- 史上最全macos安装xgboost教程
- [干货]手把手教你写一个安卓app
- java uint64_Java 中的 uint64
- 关于window10修改默认浏览器闪退的情况
- 我的冷笑话20100125
- 【原创】RPA在BPO领域的场景分享-中科云创CEO每日分享
- 什么是沾包?如何处理?
- Unity用户手册2019.3(中文版)1.3.1 常见资源类型
- Inno setup 常用修改技巧
- 在线视频转音频怎么弄?这几个软件建议你们收藏
- IJPay微信退款协议不正确 No appropriate protocol
- php图文排版样式模版,20款简约样式,多种类型文章的通用模板!
- 解决nexus 6p 无限重启的问题。nexus 6p 刷入twrp,magisk
热门文章
- Boost:BOOST_ASSERT_MSG扩展的用法测试程序
- Boost:标准地图比较的测试程序
- ITK:跟踪两个代码执行之间的内存费用
- VTK:直线网格之VisualizeRectilinearGrid
- OpenGL基本窗口和OpenGL 初始化
- c++ vector方法
- QT的QWizard类的使用
- C++指针地址内存,数据结构,文件操控
- 09_Flink入门案例、word-count程序(java和scala版本)、添加依赖、Flink Streaming和Batch的区别 、在集群上执行程序等
- 史上最简单的SpringCloud教程 | 第六篇: 分布式配置中心(Spring Cloud Config)