反击“猫眼电影”网站的反爬虫策略
0×01 前言
前两天在百家号上看到一篇名为《反击爬虫,前端工程师的脑洞可以有多大?》的文章,文章从多方面结合实际情况列举了包括猫眼电影、美团、去哪儿等大型电商网站的反爬虫机制。的确,如文章所说,对于一张网页,我们往往希望它是结构良好,内容清晰的,这样搜索引擎才能准确地认知它;而反过来,又有一些情景,我们不希望内容能被轻易获取,比方说电商网站的交易额,高等学校网站的题目等。因为这些内容,往往是一个产品的生命线,必须做到有效地保护。这就是爬虫与反爬虫这一话题的由来。本文就以做的较好的“猫眼电影”网站为例,搞定他的反爬虫机制,轻松爬去我们想要的数据!
0×02 常见反爬虫
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。而作为程序员的我们只关心数据采集部分,处理什么的还是交给那些数据分析师去搞吧。
一般来说,大多数网站会从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫,而第三种则相对比较特殊,一些应用ajax的网站会采用,这样无疑会增大了爬虫爬取的难度。
然而,这三种反爬虫策略则早已有应对的方法和策略。如果遇到了从用户请求的Headers反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。对于基于用户行为的反爬虫其实就是通过限制同一IP短时间内多次访问同一页面,应对策略也是很粗暴——使用IP代理,可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。有了大量代理ip后可以每请求几次更换一个ip,即可绕过这种反爬虫机制。对于最后一种动态页面反爬虫机制来讲,selenium+phantomJS框架能够让你在无界面的浏览器中模拟加载网页的动态请求,毕竟selenium可是自动化渗透的神器。
0×03 猫眼反爬虫介绍
介绍完常见的反爬虫机制,我们回过头看看我们今天的主角:猫眼电影的反爬虫是什么样的。
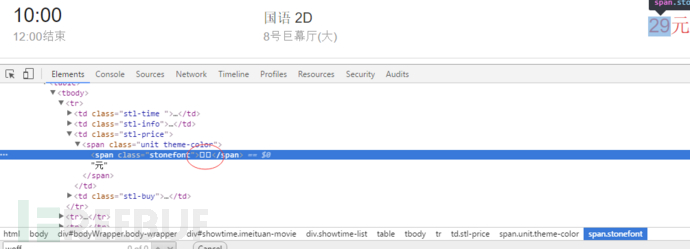
对于每日的电影院票价这一重要数据,源代码中展示的并不是纯粹的数字。而是在页面使用了font-face定义了字符集,并通过unicode去映射展示。简单介绍下这种新型的web-fongt反爬虫机制:使用web-font可以从网络加载字体,因此我们可以自己创建一套字体,设置自定义的字符映射关系表。例如设置0xefab是映射字符1,0xeba2是映射字符2,以此类推。当需要显示字符1时,网页的源码只会是0xefab,被采集的也只会是 0xefab,并不是1:

因此采集者采集不到正确的票价数据:
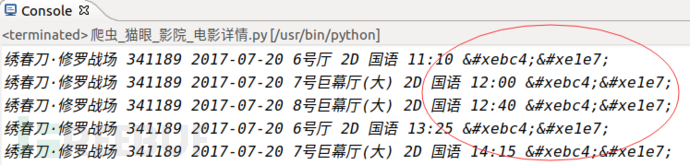
采集者只能获取到类似的数据,并不能知道””映射的字符是什么,实现了数据防采集。而对于正常访问的用户则没有影响,因为浏览器会加载css中的font字体为我们渲染好,实时显示在网页中。也就是说,除去图像识别,必须同时爬取字符集,才能识别出数字。
查看猫眼的网站源文件正是如此:

所有的票价信息都是由动态font字体“加密”后得到的。既然知道了原理,我们就继续发掘,通过分析网站HTML结构,我们发现网站每次渲染票价的font字体都可以在网页的script标签中被找到:

字体是由base64加密后存储在网页中的,于是乎,上python:
#将base64加密的font文件解密转存本地
font = re.findall(r"src: url\(data:application/font-woff;charset=utf-8;base64,(.*?)\) format",response_all)[0]
fontdata=base64.b64decode(font)
file=open('/home/jason/workspace/1.ttf','wb') file.write(fontdata) file.close() 我们在爬取时将font文件解密后存储在本地存储为ttf文件,留做备用。
前文提到过这种web-font定义了字符集,要通过unicode去映射展示,所以,我们要构建ttf字体文件中unicode映射出来的字符字典:

python代码:
import fontforge
def tff2Unicode():#将字体映射为unicode列表 filename = '/home/jason/workspace/1.ttf' fnt = fontforge.open(filename) for i in fnt.glyphs(): print i.unicode我们猜测映射关系如下:

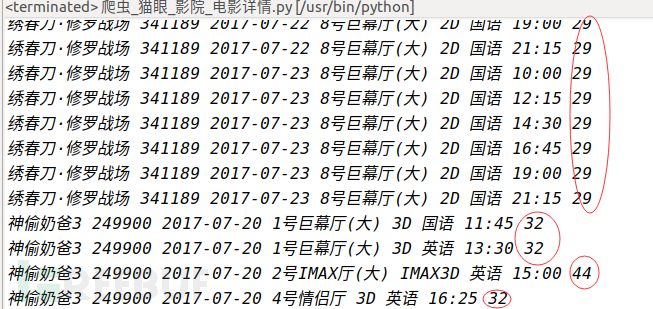
还记得嘛,第三张图我们爬取到的数据是“绣春刀·修罗战场 341189 2017-07-20 6号厅 2D 国语 11:10 ”,我们将“&#”替换成“0”后对应上表得出的票价不是刚好是“29”嘛!
python代码:
tmp_dic={}
ttf_list = []
def creatTmpDic():#创建映射字典 tmp_dic={} ttf_list = [] num_list = [-1,-1,0,1,2,3,4,5,6,7,8,9] filename = '/home/jason/workspace/1.ttf' fnt = fontforge.open(filename) ttf_list = [] for i in fnt.glyphs(): ttf_list.append(i.unicode) tmp_dic = dict(zip(ttf_list,num_list))#构建字典 return tmp_dic,ttf_list def tff2price(para = ";",tmp_dic={},ttf_list = []):#将爬取的字符映射为字典中的数字 tmp_return = "" for j in para.split(";"): if j != "": ss = j.replace("&#","0") for g in ttf_list: if (hex(g) == ss): tmp_return+=str(tmp_dic[g]) return tmp_return好的,到此,我们已经可以说已经完成了对票价“加密”数据的破解啦~还是有点小小的成就感呢!但是,这里面还是有个很坑的地方:开发者已经想到采集者可以通过分析,知道每一个映射代表的意思,从而进行采集后转换处理,所以我们每次访问都是随机得到一种字体,而且开发者还定期更新一批字体文件和映射表用来加大采集的难度,所以我们在采集的过程中不得不每采集一个页面就更新一次本地的该网页的web-font字体,无疑会大大增加爬虫的爬取成本和爬取效率,所以从一定意义上确实实现了反爬虫。
参考文献:
http://blog.csdn.net/fdipzone/article/details/68166388
https://baijiahao.baidu.com/s?id=1572788572555517&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/20520370?columnSlug=python-hacker
转载于:https://www.cnblogs.com/h2zZhou/p/7248261.html
反击“猫眼电影”网站的反爬虫策略相关推荐
- python爬取网页防止重复内容_python解决网站的反爬虫策略总结
本文详细介绍了网站的反爬虫策略,在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下. 从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分.这里我们只讨论数据采集部分. 一般网站从三个方面 ...
- Scrapy绕过反爬虫策略汇总
文章目录 一.Scrapy无法返回爬取内容的几种可能原因 1,ip封锁爬取 2,xpath路径不对 3,xpath路径出现font,tbody标签 4,xpath路径不够明确 5,robot协议 6, ...
- 代理ip网站开发_网站反爬虫策略,用代理IP都能解决吗?
很多人会使用到网页采集器,其实这也是通过程序来进行采集的,如果没有使用代理IP,采集速度快了,照样是会被封住的.另外,这些网站还有其他的一些反爬策略,同样也会影响到我们采集网页的数据,这是如何限制的呢 ...
- 网站反爬虫策略VS反反爬虫策略
网站反爬虫策略 1.通过User-Agent校验反爬 2.通过访问频度反爬 3.通过验证码校验反爬 4.通过变换网页结构反爬 5.通过账号权限反爬 反反爬虫策略制定 1.发送模拟User-Agent: ...
- 使用scrapy做爬虫遇到的一些坑:网站常用的反爬虫策略,如何机智的躲过反爬虫Crawled (403)
在这幅图中我们可以很清晰地看到爬虫与反爬虫是如何进行斗智斗勇的. 在学习使用爬虫时,我们制作出来的爬虫往往是在"裸奔",非常的简单. 简单低级的爬虫有一个很大的优点:速度快,伪装度 ...
- python应对反爬虫策略_如何应对网站反爬虫策略?如何高效地爬大量数据?
看了回答区,基本的反爬虫策略都提到了,下面说几个作为补充. 1.对于处理验证码,爬虫爬久了通常网站的处理策略就是让你输入验证码验证是否机器人,此时有三种解决方法:第一种把验证码down到本地之后,手动 ...
- web爬虫——某电影网站字体反爬
某电影网站字体反爬 爱好学习及分享,若文章侵权,优先联系本人删帖处理. 几个关键点 base字体文件分析 打开目标网页,找到woff文件链接 下载该woff文件,并在字体编辑器里打开 记录下数字与字符 ...
- 各大前端巨头反爬虫策略
各大前端巨头反爬虫策略 1. 前言 对于一张网页,我们往往希望它是结构良好,内容清晰的,这样搜索引擎才能准确地认知它. 而反过来,又有一些情景,我们不希望内容能被轻易获取,比方说电商网站的交易额,教育 ...
- scrapy框架开发爬虫实战——反爬虫策略与反反爬虫策略
反爬虫.反反爬虫 简单低级的爬虫有一个很大的优点:速度快,伪装度低.如果你爬取的网站没有反爬机制,爬虫们可以非常简单粗暴地快速抓取大量数据,但是这样往往就导致一个问题,因为请求过多,很容易造成服务器过 ...
最新文章
- 查看PID 进程是否存在的一个小技巧
- 其他系统 对外接口设计_设计模式分类及设计原则
- 区块链BaaS云服务(40) 泰岳FruitChain
- springboot 后台模板_spring boot实战
- 中国第一大善人是他!福布斯2019中国慈善榜发布:马云才排第三
- Python可以这样学(第六季:SQLite数据库编程)-董付国-专题视频课程
- 已安装jre1.7的情况下安装jdk1.6
- 《精通Unix下C语言编程与项目实践》读书笔记(2)
- (七) 三维点云课程---ICP(Point-to-Point)
- 植物大战僵尸tv版显示无法连接服务器,创维云电视植物大战僵尸tv版总是无法连接服务器...
- 全力以赴助梦起航 | 盐城北大青鸟祝各位中考考生万事胜意前程似锦
- 通过GB28181实现对安防摄像头的直播回放控制
- 在htmlfor循环制作菱形基础上制作空心菱形
- Idea无法自动补全代码,ctrl+Alt+v无法使用解决方法
- 新人小白面试软件测试必问
- 零基础使用Swift学习数据科学
- 泛型中的类型擦除和桥方法
- 《软件测试---你必须掌握的100个问题》
- 2019年“华为杯”研究生数学建模比赛总结
- 唐骏:10亿身价的智慧与悲哀~
热门文章
- Let’s Build the Tiniest Blockchain In Less Than 50 Lines of Python (Part I)
- Android Treble架构解析
- android后台截屏实现(3)--编译screencap
- ACL 2016 | Modeling Coverage for Neural Machine Translation
- Linux常用指令收集
- keil2c语言使用教程,Keil教程(2)
- freeyellowe—book_剑桥少儿英语yellow book内容
- 互斥锁 QMutex Class 的翻译
- 【学习笔记】自然数幂和
- sudu在linux的命令,Linux的sudo命令