python lol脚本_Python爬虫获取op.gg英雄联盟英雄对位胜率的源码
通过第三方BeautifulSoup库来爬取op.gg网页静态数据
主要思路
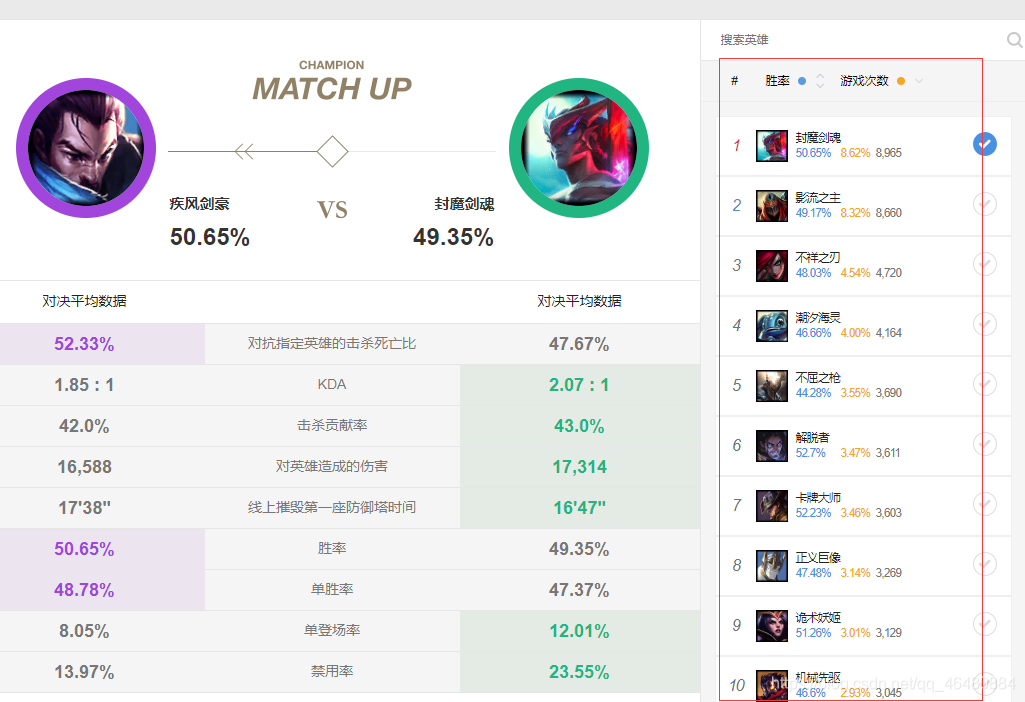
网站以出场率高低排名,并且列出对位胜率,在高出场率的前提下,胜率有很大的参考意义,在counter位很有帮助
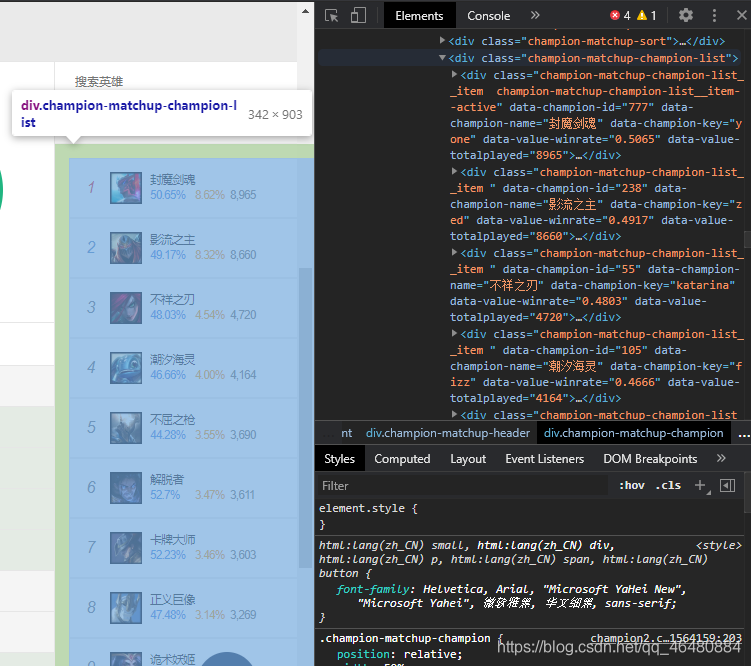
通过开发者工具找到对应部位源码,发现数据就在源码中,证明这是一个静态数据,确定使用BeautifulSoup库。
源码
import requests
from bs4 import BeautifulSoup
championname={'阿卡丽 ':'akali','牛头':'alistar','阿木木':'amumu','冰鸟':'anivia','安妮':'annie','艾希':'ashe','机器人':'blitzcrank','火男':'brand','女警':'caitlyn',
'蛇女':'cassiopeia','大虫子':'chogath','飞机':'corki','诺手':'darius','皎月':'diana','蒙多':'drmundo','德莱文':'delevin','蜘蛛':'elise',
'寡妇':'evelynn','ez':'ezreal','稻草人':'fiddlesticks','剑姬':'fiora','鱼人':'fizz','加里奥':'galio','船长':'gangplank','盖伦':'garen',
'酒桶':'gragas','人马':'hecarim','大头':'heimerdinger','刀妹':'irelia','凤女':'janna','皇子':'jarvaniv','贾克斯':'jax','杰斯':'jayce','卡尔玛':'karma',
'死歌':'karthus','卡萨丁':'kassadin','卡特':'katarina','天使':'kayle','凯南':'kennen','螳螂':'khazix','大嘴':'kogmaw','妖姬':'leblanc','盲僧':'leesin','女坦':'Leona','露露':'lulu','拉克丝':'Lux',
'石头人':'Malphite','马尔扎哈':'Malzahar','大树':'Maokai','剑圣':'Yi','女枪':'MissFortune','猴子':'Monkeyking','铁男':'Mordekaiser','莫甘娜':'Morgana'
,'娜美':'Nami','狗头':'Nasus','泰坦':'Nautilus','豹女':'Nidalee','梦魇':'Nocturne','雪人':'Nunu','奥拉夫':'Olaf','发条':'Orianna','潘森':'Pantheon','波比':'Poopy','龙龟':'Rammus','鳄鱼':'Renekton','狮子狗':'Rengar',
'瑞文':'Rivan','兰博':'Rumble','瑞兹':'Ryze','猪女':'Sejuani','小丑':'Shaco','慎':'Shen','龙女':'Shyvana','炼金':'Singed','塞恩':'Sion','希维尔':'Sivir','蝎子':'Skarner','琴女':'Sona','奶妈':'Soraka','乌鸦':'Swain','辛德拉':'Syndra'
,'男刀':'Talon','宝石':'Taric','提莫':'Teemo','锤石':'Thresh','小炮':'Tristana','巨魔':'Trundle','蛮王':'Tryndamere','卡牌':'TwistedFate','老鼠':'Twitch','乌迪尔':'Udyr','厄加特':'Urgot','维鲁斯':'Varus','薇恩':'Vayne',
'小法':'Veigar','蔚':'Vi','维克托':'Viktor','吸血鬼':'Vladimir','狗熊':'Volibear','狼人':'Warwick','泽拉斯':'Xerath','赵信':'XinZhao','掘墓':'Yorick','劫':'Zed','炸弹人':'Ziggs','时光':'Zilean','婕拉':'Zyra','佐伊':'zoe','永恩':'yone','萨米拉':'samira','亚索':'yasuo',
'塞拉斯':'sylas','卢锡安':'lucian','艾克':'ekko','阿狸':'ahri','瑟提':'sett','奇亚娜':'qiyana','龙王':'aurelionsol','克烈':'kled','妮蔻':'neeko'
}
position_all = {'top':'top','jun':'jungle','mid':'mid','ad':'bot','sup':'support'}
#由于网站反爬虫机制,使用请求通来伪装成浏览器,否则会被检测为爬虫,爬取数据失败
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'}
name_input = input('输入名字:')
myname = championname[name_input]
myposition = input('输入位置:')
position = position_all[myposition]
print('正在查询,请稍等~~~')
#向url发出请求,将请求头传入,返回结果保留在res中,res为response对象
res = requests.get('http://www.op.gg/champion/{}/statistics/{}/matchup'.format(myname,position),headers=headers)
#res.text是要解析的网页源代码,html。parser是python的解析器
soup = BeautifulSoup(res.text,'html.parser')
#find方法返回tag对象,find_all返回有tag对象组成的列表,tag是BeautifSoup中的对象
#查找class属性为champion-matchup-champion-list__item的div标签,组成名为items的列表
items = soup.find_all('div',class_='champion-matchup-champion-list__item')
print('英雄 胜率')
for i in items:
#div中的data-champion-name属性值为英雄名字
name = i['data-champion-name']
#div属性中的data-value-winrate属性值为查找的英雄胜率,这里转换为供选择的英雄胜率
rate = 1-float(i['data-value-winrate'])
print(name,'{}%'.format(round(rate*100,2)))
由于网址为英文,英雄英文名字个别十分难记难拼,所以我在字典中以中文名或者耳熟能详的外号为key,以url中英雄英文名为value,进行输入转换。
位置使用top,jun,mid,ad,sup方便输入。
到此这篇关于Python爬虫获取op.gg英雄联盟英雄对位胜率的源码的文章就介绍到这了,更多相关Python爬虫英雄联盟内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
python lol脚本_Python爬虫获取op.gg英雄联盟英雄对位胜率的源码相关推荐
- python soup歌词_Python 爬虫获取网易云音乐歌手的歌词
上一篇文章爬取了歌手的姓名和歌手的 id ,这篇文章根据上篇爬取的歌手 id 来直接下载对应歌手的歌词.这些我其实可以写成一个大项目,把这个大项目拆成小项目一来方便大家的理解,二来小项目都会了的话,拼 ...
- python查天气预报_Python爬虫获取最近七天天气预报信息
#encoding:utf-8 import requests import psycopg2 import datetime import re from bs4 import BeautifulS ...
- python英雄联盟脚本是什么_Python3爬取英雄联盟英雄皮肤大图实例代码
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API:然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有"正在加载中" ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图...
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲-爬虫和反爬的对抗过程以及策略-scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- java毕业设计——基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(毕业论文+程序源码)——网络新闻分析系统
基于java+Jsoup+HttpClient的网络爬虫技术的网络新闻分析系统设计与实现(毕业论文+程序源码) 大家好,今天给大家介绍基于java+Jsoup+HttpClient的网络爬虫技术的网络 ...
- python3网络爬虫--爬取b站用户投稿视频信息(附源码)
文章目录 一.准备工作 1.工具 二.思路 1.整体思路 2.爬虫思路 三.分析网页 1.分析数据加载方式 2.分词接口url 3.分析用户名(mid) 四.撰写爬虫 五.得到数据 六.总结 上次写了 ...
- python 操作键盘,鼠标 。我这个是自动企业微信加好友的,源码可以修改成别的。挺好使!
python 操作键盘,鼠标 .我这个是自动企业微信加好友的,源码可以修改成别的.挺好使! 键盘的按键码可以去百度搜,大体就是这么操作的 import win32con import win32api ...
- 【Python】基金/股票 最大回撤率计算与绘图详解(附源码和数据)
如果你想找的是求最大回撤的算法,请跳转:[Python] 使用动态规划求解最大回撤详解 [Python]基金/股票 最大回撤率计算与绘图详解(附源码和数据) 0. 起因 1. 大成沪深300指数A 5 ...
- 【爬虫】使用requests爬取英雄联盟英雄皮肤
使用requests爬取英雄联盟英雄皮肤 自己做的 import requestsresponse = requests.get("https://game.gtimg.cn/images/ ...
- python下载图片并保存_Python爬虫获取图片并下载保存至本地的实例
1.抓取煎蛋网上的图片. 2.代码如下: import urllib.request import os #to open the url def url_open(url): req=urllib. ...
最新文章
- java时间格式转换_Java中System.currentTimeMillis()计算方式与时间的单位转换
- 设置 tableview 的背景颜色,总是不生效
- 集成显卡与独立显卡的区别
- cmd暂停快捷键_是否有键盘快捷键可以暂停正在运行的CMD窗口的输出?
- 全网销售额超 2.67 亿!德施曼连续 5 年蝉联双11全网智能锁销冠
- http断点续传的原理
- 做词云时报错cannot import name ‘WordCloud‘ from partially initialized module ‘wordcloud‘的解决办法
- 手把手教你学项目管理软件project
- java简历专业技能,附详细答案解析
- 2016 server win 假死_Win7运行程序无缘无故发生假死现象五种解决方法
- java定义一个盒子类box_C++定义一个Box(盒子)类 看完你就知道了
- 银行主要业务--负债业务
- JetPack Room数据库组件使用方式
- 浙大版《C语言程序设计实验与习题指导(第3版)》题目集
- nodejs下上传文件formidable、multer、body-parser的区别
- 个人导航网站系统源码附带后台
- 【20考研】数学:高数复习的先后顺序
- 麒麟V10双网卡绑定测试
- vue-echarts的ZRender事件
- 基于阈值方法的大津法(OTSU算法)---图像分割