[TSP-FCOS]Rethinking Transformer-based Set Prediction for Object Detection

文章目录
- 1. Motivation
- 2. Contribution
- 3. What Causes the Slow Convergence of DETR?
- 3.1 Does Instability of the Bipartite Matching Affect Convergence?
- 3.2 Are the Attention Modules the Main Cause?
- 3.3 Does DETR Really Need Cross-attention?
- 4. The Proposed Methods
- 4.1. TSP-FCOS
- 4.2 TSP-RCNN
- 5. Experiments
- Ablation study
1. Motivation
DETR达到SOTA性能的同时,也需要更长的时间来收敛converge。
DETR is a recently proposed Transformer-based method which views object detection as a set prediction problem and achieves state-of-the-art performance but demands extra-long training time to converge.
基于此,作者来探究DETR训练中优化的困难。Faster RCNN只需要训练30epochs,而DETR需要训练500epochs。
Therefore, in what manner should we accelerate the training process towards fast convergence for DETR-like Transformer-based detectors is a challenging research question and is the main focus of this paper.
Transformer decoder是造成慢收敛的主要问题。在DETR中的匈牙利loss运用的二分图具有不稳定性,也造成了慢收敛。
2. Contribution
作者提出了TSP-FCOS,TSP-RCNN两个模型来解决匈牙利loss以及Transformer cross-attention mechanism中的问题。
To overcome these issues we pro- pose two solutions, namely, TSP-FCOS (Transformer-based Set Prediction with FCOS) and TSP-RCNN (Transformer- based Set Prediction with RCNN).
- 最新的FoI(Feature of Interest)模块应用于TSP-FCOS,来帮助Transformer 编码多尺度的特征。
A novel Feature of Interest (FoI) selection mechanism is developed in TSP-FCOS to help Transformer en- coder handle multi-level features.
- 为了解决匈牙利算法中二分图的不稳定性,作者同样为这2个模型制定了一个新的二分图匹配,在训练中加速收敛。
To resolve the instability of the bipartite matching in the Hungarian loss, we also design a new bipartite matching scheme for each of our two models for accelerating the convergence in training.
3. What Causes the Slow Convergence of DETR?
3.1 Does Instability of the Bipartite Matching Affect Convergence?
作者认为匈牙利算法中进行二分图匹配的不稳定在于以下2点:
- The initialization of the bipartite matching is essentially random;
- The matching instability would be caused by noisy conditions in different training epochs.
作者提出了matching distillation方法用来检测这些因素。首先,作者使用一个预训练的DETR作为teacher model,预训练的DETR预测的matching作为student model的ground truth label assignment,许多随机的模块例如dropout 以及batch normalization都被关闭,确保deterministic。
如图1所示,显示了前25个epochs的original DETR和matching distilled DETR的结果,可以得出matching distillation可以最开始的epochs加速收敛,但是15个epochs后就insignificant。
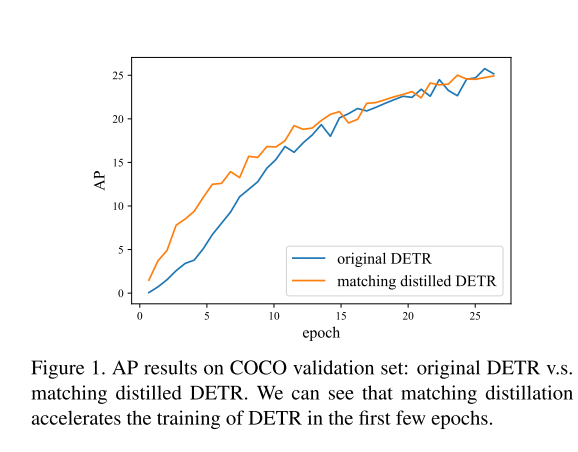
这意味着二分图匹配的不稳定性只导致了部分的慢收敛,特别是在训练的早期阶段,并不是主要的原因。
3.2 Are the Attention Modules the Main Cause?
Transformer attention maps几乎组成了初始化的阶段,但是在训练的过程中逐渐sparse。在BERT中,利用sparser module(卷积操作)取代了部分的attention head,来加速训练。
作者关注于稀疏动态的cross-attention部分,因为cross-attention是一个关键的模块,decoder部分的object queries从encoder中获得到了物体的信息。
Imprecise (under-optimized) cross-attention may not allow the decoder to extract accurate context information from images, and thus results in poor localization especially.
因为attention maps可以被解释为概率分布,因此作者使用negative entropy作为一种稀疏性的直观度量方法。首先,已知一个n×mn \times mn×m的attention map aaa,通过公式1m∑j=1mP(ai,j)logP(ai,j)\frac{1}{m} \sum_{j=1}^{m}P(a_{i,j})logP(a_{i,j})m1∑j=1mP(ai,j)logP(ai,j)先计算每一个源位置i∈[n]i \in [n]i∈[n]的sparsity,ai,ja_{i,j}ai,j从source position iii到target position jjj的attention score。 然后作者对于每一层上的所有attention heads上和所有的source postions的稀疏取平均。
如图2所示,作者发现cross-attention的稀疏性统一的增加,并且即使到了100个epochs,还是没有达到plateau(高原)。这意味着DETR中的cross-attention部分对于慢收敛起到更决定性的作用。
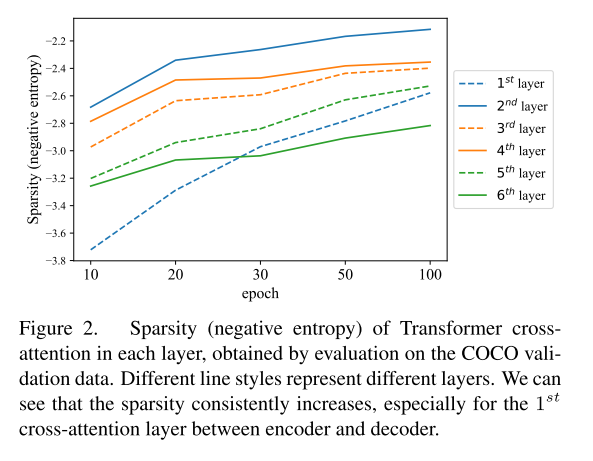
3.3 Does DETR Really Need Cross-attention?
Our next question is: Can we remove the cross-attention module from DETR for faster convergence but without sacrificing its prediction power in object detection? We
作者制定了一个只有encoder的DETR版本,并且比较了它和原始DETR的收敛性。
在encoder-only的版本中,作者直接使用encoder的输出部分用于目标检测(category label 和 bounding box),每一个feature喂进检测头用于预测检测的结果。图3比较了原始的DETR和encoder-only DETR以及TSP-FOCS和TSP-RCNN的网络模型。
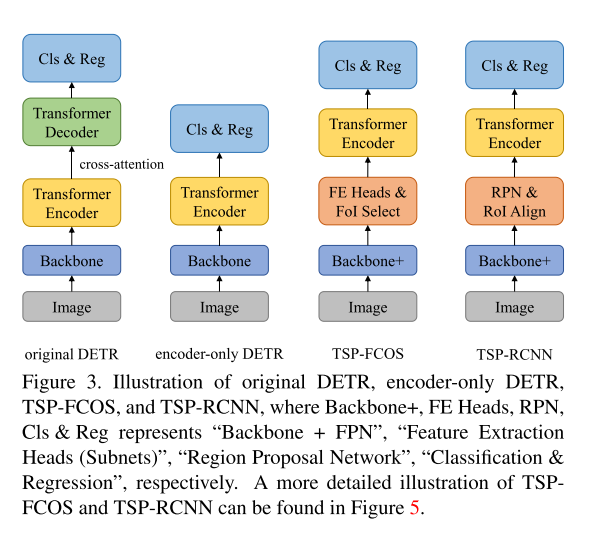
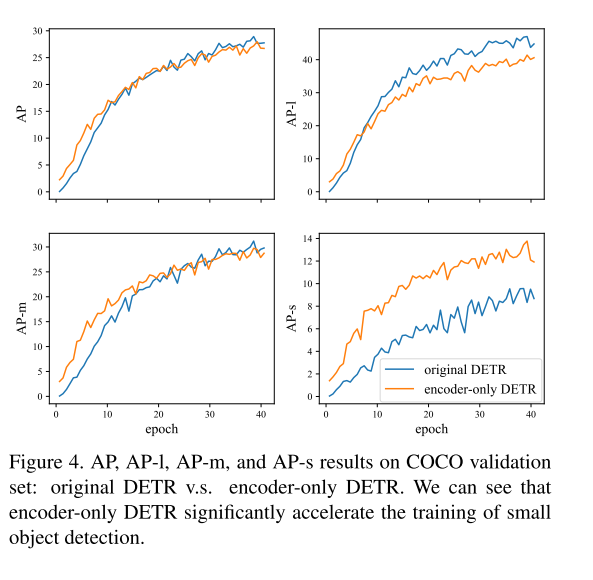
图4表示了原始DETR和encoder-only DETR的AP曲线。第一个图表示2者总体的AP曲线,可以发现两者的性能几乎一样。这表明我们可以去除cross-attentiuon部分,这是一个positive rusult。而且encoder-only DETR对于小物体以及部分的中物体的性能是优于原始DETR,但是在大物体的AP上较低。
A potential interpretation, we think, is that a large object may include too many potentially matchable feature points, which are difficult for the sliding point scheme in the encoder-only DETR to handle.
4. The Proposed Methods
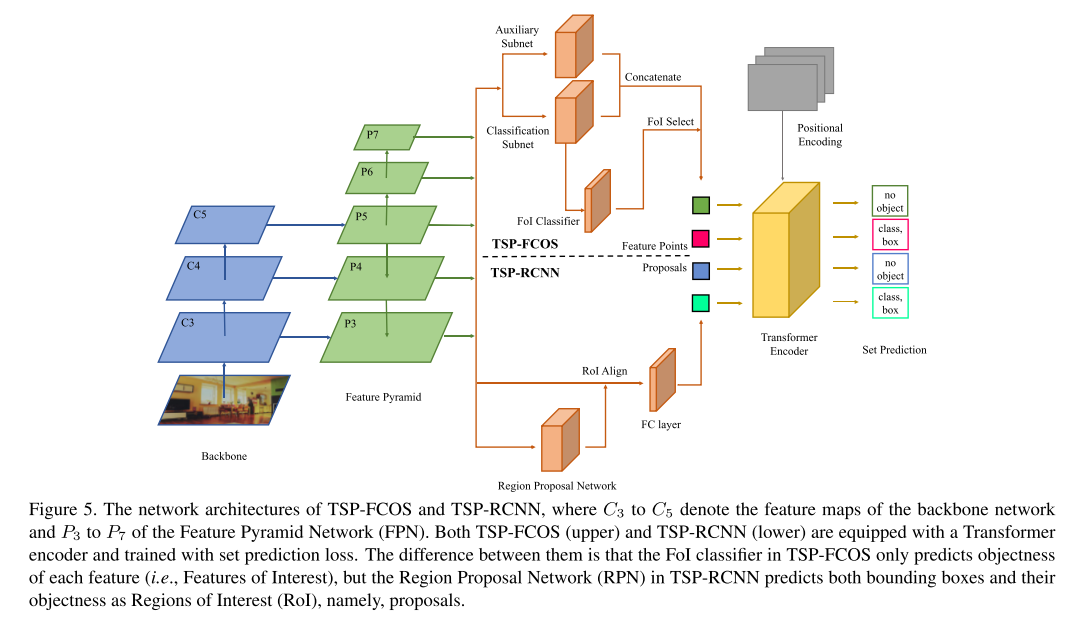
4.1. TSP-FCOS
TSP-FCOS结合了FCOS和encoder-only DETR的优点,带有一个新的组成部分,名为feature of Interest(FoI)选择器,FOI可以让transformer encoder来挑选多尺度的特征,还制定一个新的二分图匹配方法。图5上半部分表示了TSP-FCOS的网络架构。
- Backbone and FPN
- Feature extraction subnets
auxiliary subnet (head) 和classification subnet (head).
Their outputs are concatenated and then selected by FoI classifier.
subnet网络结构:
Both classification subnet and auxiliary subnet use four 3×3 convolutional layers with 256 channels and group normalization [37].
- Feature of Interest (FoI) classifier
为了改善self-attention的性能,作者制定了一个binary的分类器来挑选一个限制的features并且将他们作为FOI,二进制FOI分类器通过FCOS的label assignment的方法进行训练。
After FoI classification, top scored features are picked as FoIs and fed into the Transformer encoder.
In FoI selection, we select top 700 scored feature positions from FoI classifier as the input of Transformer encoder.
- Transformer encoder
输入:
After the FoI selection step, the in- put to Transformer encoder is a set of FoIs and their corresponding positional encoding.
输出:
The outputs of the encoder pass through a shared feed forward network, which predicts the category label (including “no object”) and bounding box for each FoI.
- Positional encoding
位置编码定义为[PE(x):PE(y)][PE(x):PE(y)][PE(x):PE(y)],[:]表示concaternation,PE被定义为公式3,其中dmodel为FoI的维度:
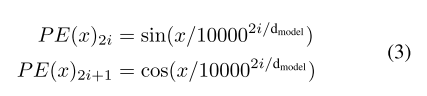
Faster set prediction training
由FCOS可知,一个特征点会被制定为gt object的条件是他在这个bbox内部,并且在适合的FPN level中。接着,用于优化检测结果和gt objects的matching,即更严格的cost-based matching(公式2),会被用于公式1(匈牙利loss)。
a feature point can be assigned to a ground-truth object only when the point is in the bounding box of the object and in the proper feature pyramid level.
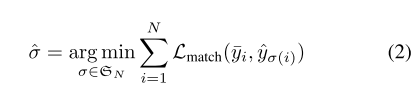
4.2 TSP-RCNN
which requires more computational resources but can detect objects more accurately.
- Region proposal network
we follow the design of Faster RCNN [30] and use a Region Proposal Network (RPN) to get a set of Regions of Interest (RoIs) to be further refined.
不同于FoIs,每一个RoI不仅仅包含了objectness score,还包含了一个预测的bbox,作者使用RoIAlign来 从多尺度的特征图中提取RoIs的信息。图区的特征接下来被flattened并且送入全连接网络来形成Transformer encoder的输入。
- Positional encoding
(cx,cy,w,h)(cx,cy,w,h)(cx,cy,w,h)来定义RoI proposal的位置信息。(cx,cy)∈[0,1]2(cx,cy) \in [0, 1]^2(cx,cy)∈[0,1]2表示归一化后的中心坐标,(w,h)∈[0,1]2(w,h) \in [0,1]^2(w,h)∈[0,1]2表示归一化后的高度和宽度。作者使用[PE(cx):PE(cy):PE(w):PE(h)][PE(cx):PE(cy):PE(w):PE(h)][PE(cx):PE(cy):PE(w):PE(h)]来作为proposal的位置编码。
Faster set prediction training
与TSP-FCOS不同的是,作者使用了Faster RCNN中的gt label assignment方法,来用于更快的set prediction的训练。
specifically, a proposal can be assigned to a ground-truth object if and only if the intersection-over-union (IoU) score between their bounding boxes is greater than 0.5.
5. Experiments
Ablation study
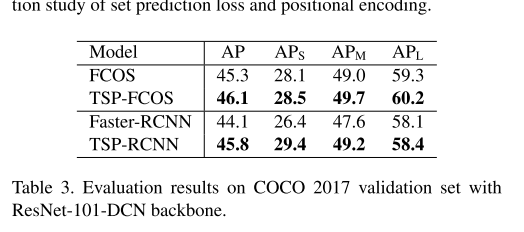
- Compatibility with deformable convolutions
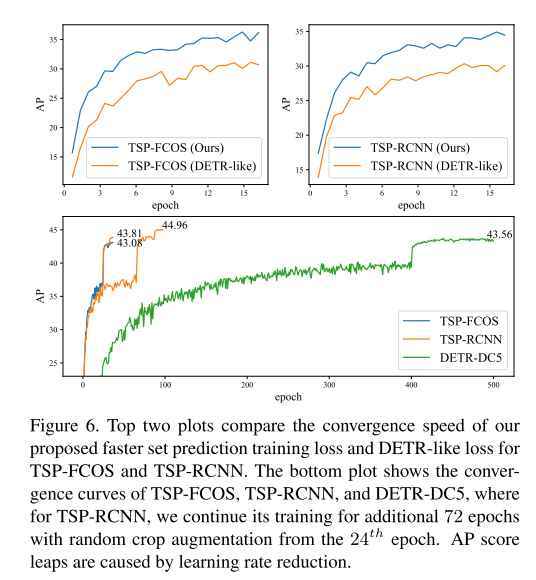
- Analysis of convergence
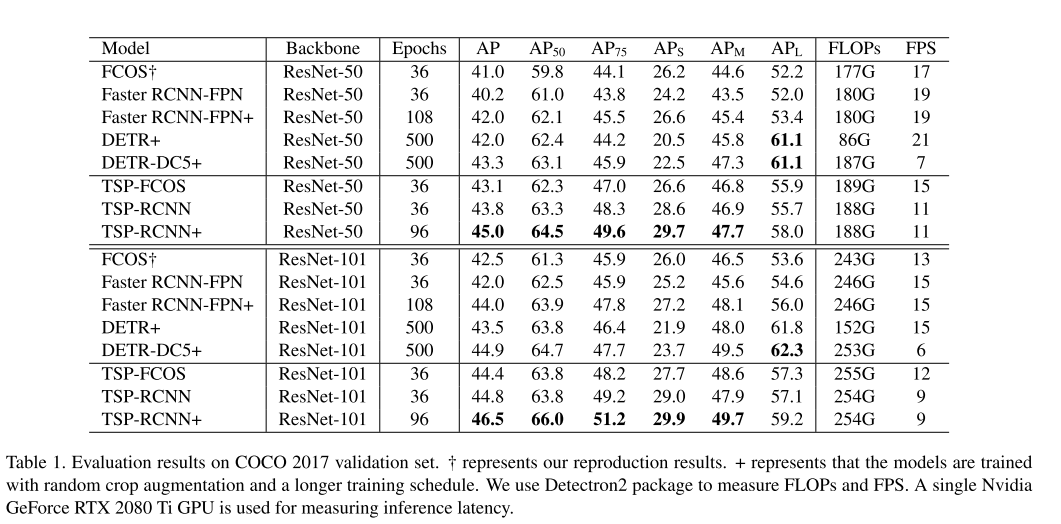
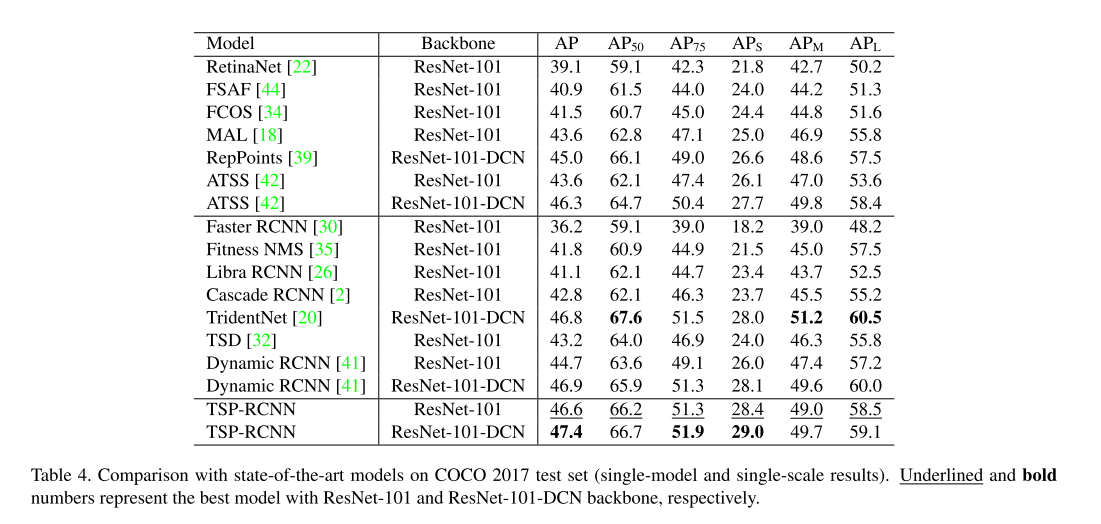
- Comparison with State-of-the-Arts
[TSP-FCOS]Rethinking Transformer-based Set Prediction for Object Detection相关推荐
- 【arXiv2022】GroupTransNet: Group Transformer Network for RGB-D Salient Object Detection
paper:https://arxiv.org/abs/2203.10785 目录 一 动机 二 方法 三 网络框架 3.1 模态纯化模块(MPM) 3.2 尺度统一模块 (SUM) 3.3 多 Tr ...
- 论文阅读:Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection
Softer-NMS 文章 和之前同样出自Megvii的一篇论文IoU-Net一样,这篇论文的出发点也是,two-stage detector进行NMS时用到的score仅仅是classifica ...
- TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captu
TPH-YOLOv5 文章目录 TPH-YOLOv5 参考 Introduciton Structure CSPDarknet53 Transformer CBAM Ms-testing and mo ...
- 【深度学习】网络架构设计:CNN based和Transformer based
从DETR到ViT等工作都验证了Transformer在计算机视觉领域的潜力,那么很自然的就需要考虑一个新的问题,图像的特征提取,究竟是CNN好还是Transformer好? 其中CNN的优势在于参数 ...
- 【Transformer】CrossFormer:A versatile vision transformer based on cross-scale attention
文章目录 一.背景 二.动机 三.方法 3.1 Cross-scale Embedding Layer(CEL) 3.2 Cross-former Block 3.2.1 Long Short Dis ...
- 【论文阅读】MPViT : Multi-Path Vision Transformer for Dense Prediction
发表年份:2021.12 发表单位:Electronics and Telecommunications Research Institute (ETRI), South Korea 期刊/会议:CV ...
- 跌倒综述 Deep Learning Based Systems Developed for Fall Detection A Review
文章目录 1.基本信息 2. 第一节 介绍 3. 第二节 跌倒检测系统文献 4.第三节 讨论和未来方向 5. 第四节 结论 6. 参考文献 1.基本信息 题目:Deep Learning Based ...
- 孤读Paper——《FCOS: Fully Convolutional One-Stage Object Detection》
<FCOS: Fully Convolutional One-Stage Object Detection> 简单.鲁棒的Anchor free目标检测算法,核心思想 是利用FCNs- ...
- FCOS:Fully Convolutional One-Stage Object Detection 论文翻译(非解读)
全卷积单级目标检测器 摘要: 1.介绍 2.相关工作 3.方法 3.1. 全卷积单级目标探测器 3.2. FCOS的FPN多级预测 3.3. Center-ness for FCOS 4. 实验 4. ...
- 深度学习之目标检测(Swin Transformer for Object Detection)
目录 1.MMdetection系列版本编辑 2. MMDetection和MMCV兼容版本 3.Installation(Linux系统环境安装) 3.1 搭建基本环境 3.2 安装mmcv-fu ...
最新文章
- android去掉button默认的点击阴影
- SQLite header and source version mismatch解决方案
- WebService与使用风格RPC/SOA/REST
- 企业关系网络分析,大数据时代淘金利器
- git分支操作、分支合并冲突解决
- S3 exercise -- 文件操作函数
- python笔记之序列(list的基本使用和常用操作)
- [python交互]Excel催化剂与python交互原理剖析,py开发者按此规范可自行扩展功能...
- php100并发cpu告警,多线程并发导致CPU100%的一种原因和解决办法
- 服务器与项目之间的关系,项目 服务器 和数据库的关系
- 解决IDEA GIT密码输入错误后,报Authentication failed ... 不再弹出输入框,提交更新失败
- Python学习记录——函数
- caffe的googlenet模型使用
- 最新白白iApp手册开源-iApp源码 非常牛逼
- 什么是需求跟踪矩阵RTM
- Bilibili宋红康老师MySQL高级篇笔记-架构篇(有完整的md格式笔记,迟点整理好会挂链接)
- c语言生成exe文件,打开exe文件闪退怎么办
- Microchip Studio 7.0项目移植(从ICC AVR移植到Microchip Studio 7.0)
- 利用计算机名称共享打印机步骤,如何连接其他电脑共享的打印机(图文教程)...
- 解决微信内红域名无需申诉过白