深度学习 游戏关卡_强化学习的游戏关卡设计
深度学习 游戏关卡
演示地址
Procedural Content Generation (or PCG) is a method of using a computer algorithm to generate large amounts of content within a game like huge open-world environments, game levels and many other assets that go into creating a game.
程序性内容生成(PCG)是一种使用计算机算法在游戏中生成大量内容的方法,例如巨大的开放世界环境,游戏级别以及创建游戏所需的许多其他资产。
Today, I want to share with you a paper titled “PCGRL: Procedural Content Generation via Reinforcement Learning” which shows how we can use self-learning AI algorithms for procedural generation of 2D game environments.
今天,我想与大家分享题为“一文PCGRL:程序内容生成通过强化学习 ”,这显示了我们如何能够利用自我学习的人工智能算法程序生成2D游戏环境。
Usually, we are familiar with the use of the AI technique called Reinforcement Learning to train AI agents to play games, but this paper trains an AI agent to design levels of that game. According to the authors, this is the first time RL has been used for the task of PCG.
通常,我们熟悉使用称为“强化学习”的AI技术来训练AI代理玩游戏,但是本文通过训练AI代理来设计该游戏的级别。 这组作者说,这是RL首次用于PCG的任务。
推箱子游戏环境 (Sokoban Game Environment)
Let’s look at the central idea of the paper. Consider a simple game environment like in the game called Sokoban.
让我们看一下本文的中心思想。 考虑一个简单的游戏环境,例如在名为《 推箱子》的游戏中。
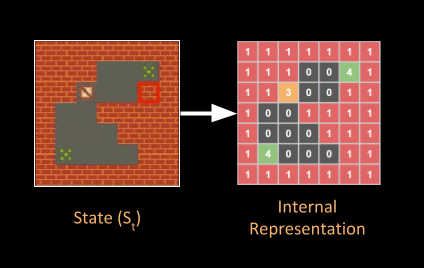
We can look at this map or game level as a 2D array of integers that represent this state of the game. This state is observed by the Reinforcement Learning agent that can edit the game environment. By taking actions like adding or removing certain element of the game (like solid box, crate, player, target, etc. ), it can edit this environment to give us a new state.
我们可以将地图或游戏级别视为代表游戏状态的2D整数数组。 强化学习代理可以观察此状态,该代理可以编辑游戏环境。 通过采取诸如添加或删除游戏某些元素(如实心框,板条箱,玩家,目标等)之类的动作,它可以编辑此环境以赋予我们新的状态。
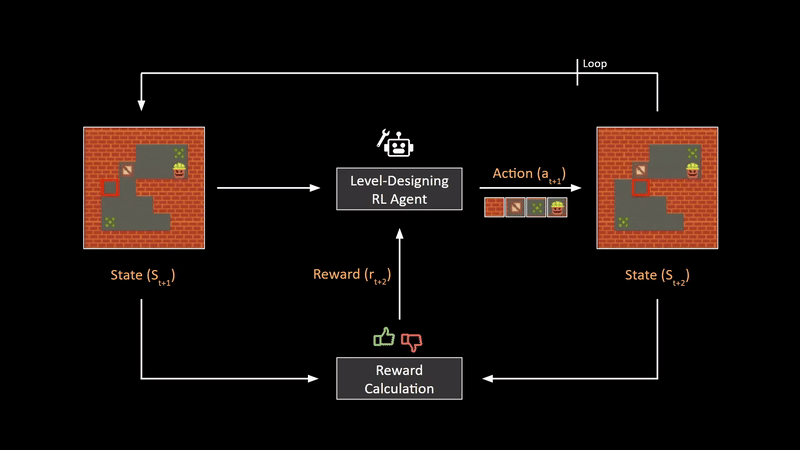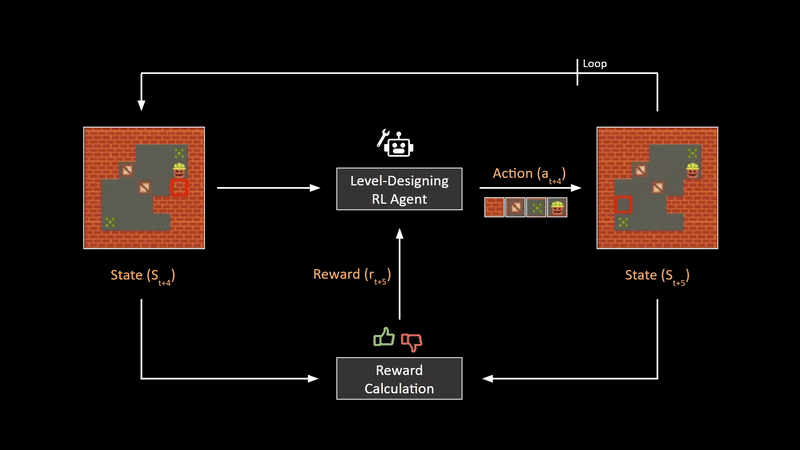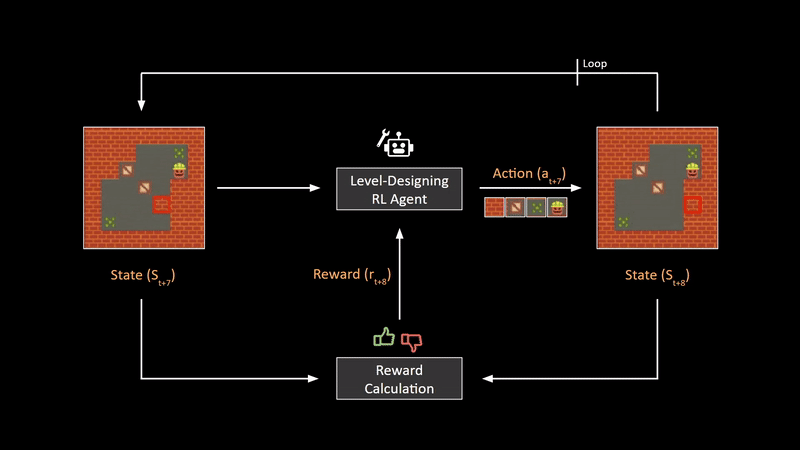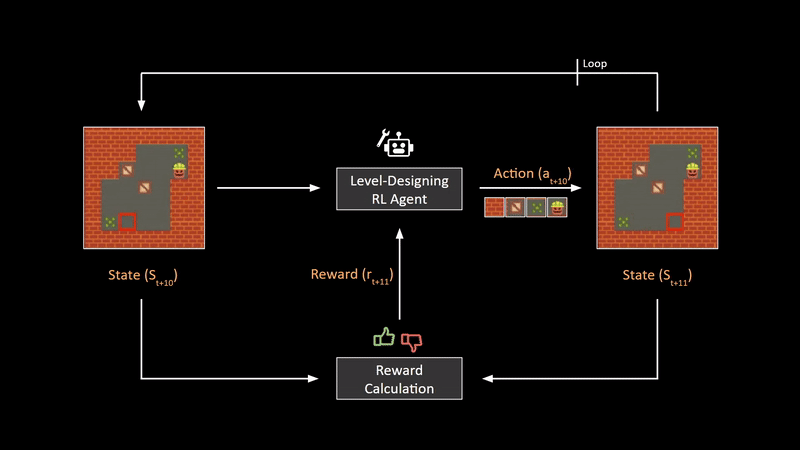
Now, in order to ensure that the environment generated by this agent is of good quality, we need some sort of feedback mechanism. This mechanism is constructed in this paper by comparing the previous state and the updated state using a hand-crafted reward calculator for this particular game. By adding appropriate rewards for rules that make the level more fun to play, we can train the RL agent to generate certain types of maps or levels. The biggest advantage of this framework is that after training is complete, we can generate practically infinite unique game levels at the click of a button, without having to design anything manually.
现在,为了确保此代理生成的环境具有良好的质量,我们需要某种反馈机制。 本文通过使用手工奖励计算器针对此特定游戏比较先前状态和更新状态来构造此机制。 通过为使关卡更有趣的规则添加适当的奖励,我们可以训练RL代理生成某些类型的地图或关卡。 该框架的最大优点是,训练完成后,我们只需单击一下按钮,便可以生成几乎无限的独特游戏关卡,而无需手动进行任何设计。

The paper also contains comparisons between different approaches that the RL agent can use to traverse and edit the environment. If you’d like to get more details on the performance comparison between these methods, here is the full text of the research results.
本文还包含了RL代理可以用来遍历和编辑环境的不同方法之间的比较。 如果您想获得这些方法之间的性能比较的详细信息,下面是全文的研究成果。

总体研究方向 (General Research Direction)
While the games that were use in this paper’s experiments are simple 2D games, this research direction excites me because we can build upon this work to create large open-world 3D game environments.
尽管本文实验中使用的游戏是简单的2D游戏,但该研究方向使我很兴奋,因为我们可以在此工作的基础上创建大型开放世界3D游戏环境。

This has the potential of changing online multiplayer gaming experience. Imagine, if at the start of every multiplayer open-world game, we could generate a new and unique tactical map every single time. This means we do not need to wait for the game developers to release new maps every few months or years, but we can do so right within the game with AI, which is really cool!
这有可能改变在线多人游戏体验。 想象一下,如果在每个多人开放世界游戏开始时,我们都可以每次生成一个新的独特战术地图。 这意味着我们不需要等待游戏开发人员每隔几个月或几年发布一次新地图,但是我们可以使用AI在游戏中完成发布,这真的很酷!
有用的链接 (Useful Links)
Paper Full-Text (PDF)
论文全文(PDF)
Code (GitHub)
代码(GitHub)
Thank you for reading. If you liked this article, you may follow more of my work on Medium, GitHub, or subscribe to my YouTube channel.
感谢您的阅读。 如果您喜欢这篇文章,可以关注我在Medium , GitHub上的更多工作,或者订阅我的YouTube频道 。
翻译自: https://medium.com/deepgamingai/game-level-design-with-reinforcement-learning-52b02bb94954
深度学习 游戏关卡
http://www.taodudu.cc/news/show-2190968.html
相关文章:
- Gameplay - 多人游戏关卡设计
- php 三消算法,三消游戏关卡设计教程(初级篇)——基本地形设计
- 优秀关卡设计的十个原则
- 益智类游戏关卡设计:逆推法--巧解益智类游戏关卡设计
- 稳妥方法论:如何完整地设计出游戏关卡及场景
- 浅谈游戏关卡设计
- 泛微E9 获取附件内容,泛微Ecology9获取附件范例,Ecology9附件、E9 附件下载及上传集成平台
- 泛微E8调整附件大小和属性
- 【泛微Ecology9.0】安装\启用非标功能
- 泛微 E9开发视频教程
- 【泛微E9开发】E9客户端下载页面修改方法
- 泛微 - eteams
- 泛微e9隐藏明细表_泛微e-cology的Ecode二次开发无侵入定制说明
- 泛微E8创建自定义文档
- 超全 泛微 E8 E-cology 8 开发资料大全 开源下载资料
- 超全 泛微 E9 Ecology 9开发资料大全 开源资源下载 泛微E9二次开发 泛微开发资料
- 泛微E8、E9二次开发、泛微开发获取流程文档主、明细表单值,提供泛微ecology8二次开发完整项目下载,泛微把流程文档内容推送HR、ERP、SAP操作,泛微与ERP、SAP、HR集成
- 泛微E8使用 xlsx.core.js 导入页面数据
- 泛微移动端数据库 :H2数据库
- 泛微e9隐藏明细表_泛微Ecology权限整理大全,相当全要点
- 泛微e9隐藏明细表_泛微Ecology权限整理大全相当全要点
- 泛微 E9开发视频教程,零基础泛微开发
- 泛微 linux mobile手册,泛微E-Mobile5.0服务端安装手册.doc
- 泛微E8的数据展示集成方法
- 泛微E9 MVC开发
- 泛微 漏洞汇总
- 泛微E8后台开发
- 泛微平台ecology8.0二进制文件流下载对接接口
- Matlab音频信号的基本处理与分析
- 数字信号处理(1)- 频谱分析
深度学习 游戏关卡_强化学习的游戏关卡设计相关推荐
- 重拾强化学习的核心概念_强化学习的核心概念
重拾强化学习的核心概念 By Hannah Peterson and George Williams (gwilliams@gsitechnology.com) 汉娜·彼得森 ( Hannah Pet ...
- 强化学习-动态规划_强化学习-第4部分
强化学习-动态规划 有关深层学习的FAU讲义 (FAU LECTURE NOTES ON DEEP LEARNING) These are the lecture notes for FAU's Yo ...
- 深度学习之强化学习(1)强化学习案例
深度学习之强化学习(1)强化学习案例 强化学习案例 1. 平衡杆游戏 2. 策略网络 3. 梯度更新 4. 平衡杆游戏实战 完整代码 人工智能=深度学习+强化学习--David Silver 强化学 ...
- 游戏中应用强化学习技术,目的就是要打败人类玩家?
来源:AI前线 作者:凌敏 采访嘉宾:黄鸿波 2016 年,DeepMind 公司开发的 AlphaGo 4:1 大胜韩国著名棋手李世石,成为第一个战胜围棋世界冠军的人工智能机器人,一时风头无两.Al ...
- python原理_强化学习:原理与Python实现
强化学习:原理与Python实现 作者:肖智清 著 出版日期:2019年08月 文件大小:17.18M 支持设备: ¥60.00 适用客户端: 言商书局 iPad/iPhone客户端:下载 Andro ...
- 强化学习笔记1:强化学习概述
七个字概括强化学习适用的问题:多序列决策问题 1 agent和environment 强化学习讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的环境(environment) ...
- 强化学习笔记4:强化学习分类
1 model-free & model-based model-based(有模型) RL agent,它通过学习环境的状态转移来采取动作. model-free(免模型) RL agent ...
- 【强化学习】什么是强化学习算法?
[强化学习]什么是强化学习算法? 一.强化学习解决什么问题? 二.强化学习如何解决问题? 2.1.强化学习的基本框架 2.2.强化学习系统的要素 2.3.强化学习与监督学习的区别 2.4.强化学习与非 ...
- 百度强化学习框架PARL入门强化学习
1.什么是强化学习? 强化学习(Reinforcement Learning, RL),又称再励学习.评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互 ...
- 强化学习—— 多智能体强化学习
强化学习-- 多智能体强化学习 1. 多智能体关系分类 1.1 合作关系(Fully Cooperative) 1.2 竞争关系(Fully Competitive) 1.3 混合关系(Mixed C ...
最新文章
- Java中的策略模式实例教程
- 【金三银四跳槽季】Java工程师的面试之路,需要“解锁”哪些技术盲点?
- docker客户端连接远程服务器
- 【Azure Show】|第三期 人工智能大咖与您分享!嘉宾陈海平胡浩陈堰平
- Windows Embedded CE 6.0开发初体验(四)跑个应用程序先
- eclipse中查看mysql_eclipse中怎样查看sqlite数据库的表
- 基于Tensorflow实现FFM
- anspython_python堆(heapq)的实现
- 如何用计算机寒假计划表,如何制定寒假学习计划表
- caffe安装系列——综述
- Deprecated: Function eregi() is deprecated in ……【解决方法】
- python爬今日头条app_今日头条app数据爬虫demo
- 主视图和左视图算体积最大最小值
- 页面使用html生成一个n行n列表格,HTML静态网页:表格、表单
- 算法的时间与空间复杂度(一看就懂)
- python经典书记必读:Python编程快速上手 让繁琐工作自动化
- 学会给视频添加渐入、色彩变幻特效,简单几步骤做创意小视频
- 价值 20 万美元的爱马仕包包是用蘑菇做的,你还会买吗?
- android开机动画bootanimation 分析
- csdn博客 代码块的显示设置以及图片的插入技巧