分布式系统关注点(3)——过去这几十年,分布式系统的「数据一致性」精华都在这了!...
阅读目录
- 为什么需要事务
- 事务的来源
- 分布式系统中的事务问题
- 分布式事务的解决方案
- 结语
暂时还未涉及的园友们,可以收藏防身哦~
本文是本系列的第三篇。与前两篇《不知道是不是最通俗易懂的《数据一致性》剖析了》、《烦人的数据不一致到底怎么解决?——通过“共识”达成数据一致性》形成完整的「数据一致性」合集。
一、为什么需要事务
如果说「共识」解决的是「水平」问题,那么「事务」解决的是「垂直」问题。是如何让一条绳上的蚂蚱共同起舞?
事务只是一个计算机术语,而事务的体现形式其实在我们生活中也无处不在。任何我们认为应该是这样的事情,去确保它达到预期的过程就是「事务」。 往小了说,我们平时在走路的时候,向前摆动左手的同时抬右腿,如果不是这样的话就是不一致,别人会说你走路不协调。所以我们小时候父母会通过各种方式教会我们这个,这些各式各样的方式就好比我们在软件开发中去实施「事务」一样,一题是多解的。
二、事务的来源
提到事务不得不提到「XA规范」[1],这是分布式还没大行其道的时期,被大多数的数据库作为其内部分布式事务实现的接口标准。
![]()
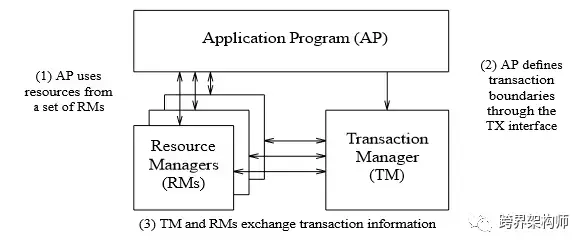 ▲图片来源于论文中,版权归原作者所有
▲图片来源于论文中,版权归原作者所有
「XA规范」就是上图中「RM」和「TM」的交互规范和接口定义。仅仅是定义了xa_和ax_系列的函数原型以及功能描述、约束和实施规范等,并不包括建议的实现方式。后面会提到的两阶段提交(2PC)是「TM」协调「RM」们完成事务的方法。
所以其实可以说,事务起源于数据库,辉煌于分布式系统。在摩尔定律还适用的时候,软件系统为了承载更大的流量或者说用户数,开始运用「分治」的思想来设计。然后随着互联网的蓬勃发展,B/S应用大行其道的背景下,分布式系统越来越常见。并且随着一个个巨无霸互联网公司的出现,越来越被鼓吹和传颂。
一轮明月的背后是一个阴暗面,从来不让人看见。
能被吹捧的永远是有益的一面,再加上耀眼的数据:多少TPS、多少QPS,更抓人眼球。但是这背后为了让「分治」后的系统能够尽可能的像单个个体一样运作,各类专家学者们通过多年研究,才有了如今的各种著名理论和解决方案。
三、分布式系统中的事务问题
正如前面所说,事务问题其实一直存在,只是在分布式系统中被放大了。并且随着系统拆分的粒度越细,问题的复杂度成指数上升。
分布式系统的事务,不得不提到被广为流传的两个理论:「CAP」、「BASE」。
「CAP」理论由Eric Brewer在2000年PODC会议上提出[2],所以还被称为Brewer定理。是Eric Brewer在Inktomi期间研发搜索引擎、分布式web缓存时得出的一个猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
后来Seth Gilbert和Nancy Lynch对其进行了证明[3],成为我们熟知的「CAP」定理(感谢园友@bangerlee的信息收集)。
对,就是下面这张经典的图。
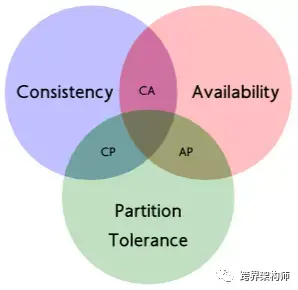
一致性(consistency):这里的一致性指是「线性一致性」。(关于线性一致性的解释,点我可阅读)
可用性(availability):每个请求都在一定时限内得到响应。
分区容忍性(partition-tolerance):这应该是这三点中最晦涩的。允许丢失以一个节点发给另一个节点的任意多的消息。只要是分布式系统,这项是无法逃避的,因为网络、硬件说不准啥时候就出问题了。
举个不是特别严谨的例子,这就好比要实现一个系统不能产生BUG(C),并且10天内完成上线(A),以及需要多人团队一起协作进行(P)。我们做开发的也很清楚这三者是无法兼得的。况且只要是一个组织,团队协作是无法避免的,正如这里的分区容忍性一样,比如得考虑人员请假的问题。剩下的2项,如果说可以达到没有BUG的话,那就是时间无限延长,但也只是无限趋近于0,并不能达到真正的0,因为没有人可以保证发现了所有的BUG。
「BASE」理论是由时任ebay架构师的Dan Pritchett提出的[4],本质上就是对「线性一致性」的弱化。弱化的方式正如本集合的第一篇文章中所提到的「顺序一致性」和「最终一致性」。(关于这两种一致性的解释,点我可阅读)
「BASE」理论解释如下:
基本可用(Basically Available)。分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
软状态(Soft State)。状态可以有一段时间不同步,且这个状态不影响系统可用性。
最终一致(Eventually Consistent)。确保最终数据能够一致,而不是时时保持强一致。
「BASE」理论的提出并不是取代「CAP」理论,让我们在实际的工作中就可以完全的撇开「线性一致性」。并不是这样,而是引导我们可以区分核心和非核心,然后分别对待,核心部分还是需要用CAP理论来保证「线性一致性」。为什么要区别对待?根本上还是无法容忍「线性一致性」带来的巨大的性能损耗,因为它是反可伸缩性的。但是只要涉及到Money之类的高敏感数据的操作部分,还是必须保证「线性一致性」。
还是上面的例子,我们侧重于降低核心功能的BUG,不花过多精力在非核心功能上(BA)。我们允许产生不影响核心功能的BUG(S),但是必须最终要修复(E)。
四、分布式事务的解决方案
如果说「CAP」理论和「BASE」理论是「道」,那么围绕这两个理论演化的解决方案就是「术」。对我们来说,在实际的运用中根据所处的场景找到最合适的,是我们最重要的事。
以「CAP」为基础的强一致性解决方案都会引入一个类似“协调器”的东西来作为全局事务的掌控者,可以来看一下。
01 两阶段提交(2PC)[5]
![]()
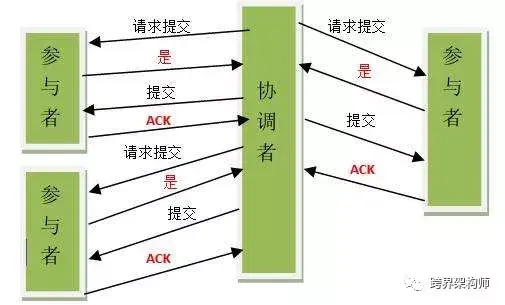 ▲图片来源于网络,版权归原作者所有
▲图片来源于网络,版权归原作者所有
印象中左耳朵耗子(陈皓)之前拿西方结婚时的仪式做过一个形象的比喻。大致好像是牧师分别询问男女双方“你愿意吗?”相当于这里的「请求提交」,得到的“yes”相当于「是」这个答复。然后再要求给对方带上戒指,这个要求就相当于这里的「提交」,带完戒指之后的反馈就是「ACK」。
另外值得注意的是,参与者在答复「是」之前会将自己的内部资源变为阻塞状态。因此如果在产生阻塞后协调者出问题,那么这些被阻塞的资源有可能就一直不被释放了,需要额外的介入。
2PC相对来说是最简单的事务模型,但缺点也更多。其它缺点诸如:在某些场景下的数据不一致(参与者与协调者共同与「提交」环节挂了)、阻塞范围过大等问题。
02 三阶段提交(3PC)[6]
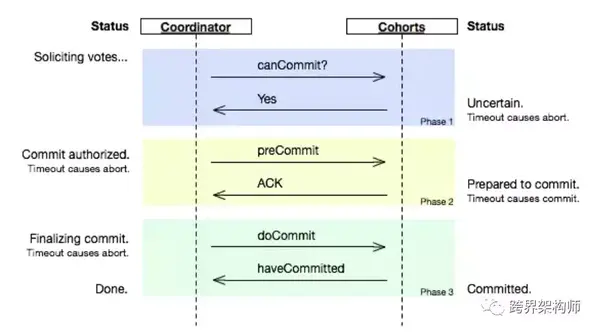
3PC的出现就是通过增加复杂度(性能也因此降低)来解决或优化2PC中的一部分问题。本质的变化就是在2PC的「请求提交」之后增加了一个「准备提交」环节,以增加每个参与者需要等待其它的参与者确认后方可进行具体的操作。
「阻塞」这个动作延后到这个「准备提交」环节再做,使得阻塞范围缩小为2PC的2/3(图中背景黄色和绿色部分)。正如上面的例子,在交换戒指之前增加了把戒指交给牧师的动作。
同时还解决了协调者的单点问题。故障恢复或者新接替的协调者,可以利用「准备提交」产生的状态结果,来作为参与者和协调者在「提交」出现故障恢复后的界定依据。还是前面的例子,夸张点,交换戒指的时候我失忆了,意识恢复后我只要看到牧师手掌上托着戒指或者我的手上已经被戴好了戒指,就知道我的妻子已经答应了,我只要继续给她做带戒指这个事就好了。
新引入了timeout机制,在发生超时执行默认约定,避免了永久阻塞,也因此对多个参与者下的100%数据一致性作出了妥协。比如,协调者在向参与者A发送「doCommit」时timeout了,会引发广播「abort」,但是这个「abort」又未能投递到参与者B,导致参与者B执行了「ACK」后的timeout默认约定「commit」。
03 TCC
在国内,由于阿里的光环加持下TCC好像更火,风头盖过了2PC和3PC。其本质上是另辟蹊径达到了和3PC类似的效果。
![]()
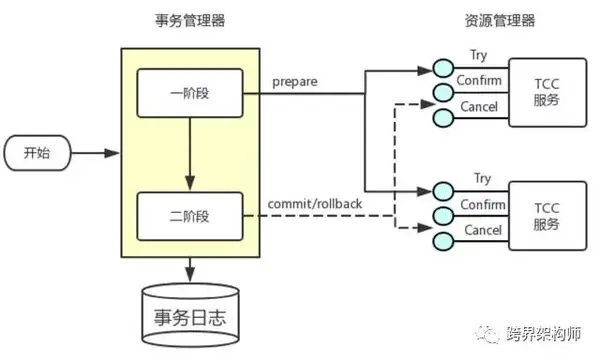 ▲图片来源于网络,版权归原作者所有
▲图片来源于网络,版权归原作者所有
通过运用本地事务代替了全局事务,使得可以不需要协调者的存在,避免了协调者的单点问题。
3PC中协调者的另一个作用:故障恢复后的数据一致性。在TTC里通过事务日志来确保。
这个概念最初是由Pat Helland于2007年提出的[7],那时还叫「Tentative-Confirmation-Cancellation」,在2008年的软件开发2.0技术大会上支付宝CTO(程立)将其在国内推广开来。
以上这三种就是主流的DTS(Distributed Transaction Service)框架。值得一提的是,不管是3PC还是TCC,只要涉及到故障恢复或者重试机制,那么「幂等性」问题必须要提上来了。比如3PC中「提交」阶段某个参与者和协调者同时挂了,但是这个参与者在挂之前已经做了commit操作。那么故障恢复后其实没人知道它是否执行过了commit,协调者只会为了能100%确保commit指令被送达,又会发起一次commit通知,这时候如果没有做好「幂等性」就会发生重复commit的问题。
下面聊聊以「BASE」理论为基础的解决方案。
01 异步消息——本地消息表
▲点击图片可查看大图
这种实现方式的思路,源于ebay,与提出BASE理论在同一篇论文中[4]。设计思想是将远程分布式事务拆分成一系列的本地事务,借助关系型数据库中的表即可实现。
02 异步消息——不支持事务的MQ
▲点击图片可查看大图
其实大部分的MQ都是不支持事务的,所以我们需要自己想办法解决可能出现的MQ消息未能成功投递出去的问题。有个便宜可以捡的是,如果需投递的MQ消息条数仅有1的话,可以将本地事务的commit放于消息投递之后即可避免此问题。伪代码如下:
try{ beginTrans(); modifyLocalData1(); modifyLocalData2(); deliverMessageToMQ(); commitTrans();
}
catch(Exception ex){ rollbackTrans();
}![]()
03 异步消息——支持事务的MQ
▲点击图片可查看大图
据我所知,目前唯一支持事务的MQ框架是RockerMQ,并且于近期才开源了事务部分实现,《RocketMQ 4.3正式发布,支持分布式事务》(http://www.infoq.com/cn/news/2018/08/rocketmq-4.3-release)。这样的确能省很多事~,直接放一张阿里方面给出的图感受一下实现细节。
▲图片来源于网络,版权归原作者所有(点击图片可查看大图)
不过其实有一个疑点我没有去验证,有知道的小伙伴们可以留言下,就是RocketMQ是否有防止consumer(上图中的订阅方)在消费完成后发送的ACK丢失的机制。如果能达到这点,对于consumer内部的方法幂等性需求就低了很多。
04 Saga
▲点击图片可查看大图
Saga是1987年就提出的概念[8],核心是:
将一个分布式事务拆分为多个本地事务,并且击鼓传花给下一个,不用阻塞本地事务等待响应。且允许嵌套至多一层子事务。
除了最后一个参与者之外,都需要定义一个「回滚」接口,便于在遇到无法进行下去的情况下撤销之前上游系统的修改。当然这里的撤销除了Update还可以是冲抵类的操作。
Saga原则上是个链式的「长活事务」,整个处理耗时可能会很长。所以可以通过增加save point(保存点,类似于游戏里的存档),便于故障恢复和提速,如向前恢复(重试)和向后恢复(回滚)。不过,也可以并行多个子事务,但一般在运用中心节点的Saga模式中,如图。
▲点击图片可查看大图
只是在我们打破了链式规则后必须要额外确保执行了「回滚」之后再接收到「正向请求」,等于“请求无效”的效果。中心节点模式还有一个比较大的好处是能够更好的避免事务之间的循环依赖关系。
05 Gossip协议
额外提一下,这个其实是一个具体的、运用BASE理论实现的协议,借由Cassandra的热火而让更多人知道了。这协议一般会用于数据复制、P2P拓扑构造、故障探测等。
看这些案例我们可以发现,基于「CAP」的解决方案都是在线的,而「Base」是允许离线的。好比前者是,累倒了必须得马上爬起来继续干货,要不然就是失败。而后者是,慢慢来,只要最终能干完。
不管怎样,如果每个解决方案中增加「重试」和「回滚」会大大提升程序的自我修正能力,以降低需要人为介入的比例。识别是否需要人为介入的方式就是类似于「对账」的机制,这个机制就是兜底的。最后还需要做一道选择题来防止混乱:确保参与者的接口符合「幂等性」,或者在中间件里做到「正好一次(Exactly-once)」。
这些基于「BASE」的解决方案都是可以作为「CAP」解决方案出现问题时的PlanB来用的,起到补充作用。当然,如非必要,可以优先考虑基于「BASE」的方案,毕竟这才是天然易伸缩的,自然也能带来更好的性能。
五、结语
解决方案如此多,所以不管我们是架构师、还是在成为架构师的路上,甚至在日常生活中,都需要养成Balance的习惯,找到那个最适合的方案。
最后还有一招终极大法 —— 减少冗余。
是亦彼也,彼亦是也,彼亦一是非,此亦一是非。 ——庄子
「事物都具有两面性」,所以,在选择走向分布式之前,慎重考虑下是否有必要,以免给自己徒增麻烦。
论文可在微信公众号后台直接回复关键字“一致性”,打包下载。下篇将开启「高可用」主题,敬请期待~
▶ 公众号后台回复“一致性”关键字,可打包下载哟~
[1] Distributed TP: The XA Specification , X/Open Company Ltd. , 1991
链接:https://publications.opengroup.org/c193
[2] Harvest, Yield, and Scalable Tolerant Systems, Armando Fox , Eric Brewer, 1999
链接:https://cs.uwaterloo.ca/~brecht/servers/readings-new2/harvest-yield.pdf
[3] Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web, Seth Gilbert, Nancy Lynch, 2002
链接:https://pdfs.semanticscholar.org/24ce/ce61e2128780072bc58f90b8ba47f624bc27.pdf
[4] Base: An Acid Alternative, Dan Pritchett, 2008
链接:http://delivery.acm.org/10.1145/1400000/1394128/p48-pritchett.pdf
[5] Consensus Protocols: Two-Phase Commit, Henry Robinson, 2008
链接:http://the-paper-trail.org/blog/consensus-protocols-two-phase-commit/
[6] Consensus Protocols: Three-phase Commit, Henry Robinson, 2008
链接:http://the-paper-trail.org/blog/consensus-protocols-three-phase-commit/
[7] Life beyond Distributed Transactions:an Apostate’s Opinion, 2007
链接:https://cs.brown.edu/courses/cs227/archives/2012/papers/weaker/cidr07p15.pdf
[8] Sagas, Hector Garcaa-Molrna & Kenneth Salem, 1987
链接:https://www.cs.cornell.edu/andru/cs711/2002fa/reading/sagas.pdf
作者:Zachary
出处:https://www.cnblogs.com/Zachary-Fan/p/consistency3.html
▶关于作者:张帆(Zachary,个人微信号:Zachary-ZF)。坚持用心打磨每一篇高质量原创。欢迎扫描右侧的二维码~。
定期发表原创内容:架构设计丨分布式系统丨产品丨运营丨一些思考。
如果你是初级程序员,想提升但不知道如何下手。又或者做程序员多年,陷入了一些瓶颈想拓宽一下视野。欢迎关注我的公众号「跨界架构师」,回复「技术」,送你一份我长期收集和整理的思维导图。
如果你是运营,面对不断变化的市场束手无策。又或者想了解主流的运营策略,以丰富自己的“仓库”。欢迎关注我的公众号「跨界架构师」,回复「运营」,送你一份我长期收集和整理的思维导图。
转载于:https://www.cnblogs.com/Zachary-Fan/p/consistency3.html
分布式系统关注点(3)——过去这几十年,分布式系统的「数据一致性」精华都在这了!...相关推荐
- 「数据一致性」理解分布式系统中的一致性
首先,什么是一致性? 一致性是指分布式系统中多个节点为达到某一数值而达成的协议. 具体来说,可以分为强一致性和弱一致性. 强一致性:所有节点的数据在任何时候都是相同的.同时,您应该得到节点A中的key ...
- 分布式系统关注点(8)——99%的人都能看懂的「熔断」以及最佳实践
如果这是第二次看到我的文章,欢迎右侧扫码订阅我哟~ > 本文长度为3319字,建议阅读9分钟. 阅读目录 熔断是什么 熔断怎么做 做熔断的最佳实践 总结 当我们工作所在的系统处于分布式系统初期 ...
- 分布式系统关注点:弹性架构
点击蓝色"程序猿DD"关注我哟 来源:跨界架构师 如果我们的开发工作真的就如搭积木一般就好了,轮廓分明,个个分开,坏了哪块积木换掉哪块就好了.但是,实际我们的工作中所面临的可能只有 ...
- 分布式系统关注点(14)——「弹性架构」详解
如果第二次看到我的文章,欢迎右侧扫码订阅我哟~ ? 本文长度为3633字,建议阅读10分钟. 坚持原创,每一篇都是用心之作- 如果我们的开发工作真的就如搭积木一般就好了,轮廓分明,个个分开,坏了哪块 ...
- 分布式系统关注点(12)——「无状态」详解
如果这是第二次看到我的文章,欢迎右侧扫码订阅我哟~ ? 本文长度为2728字,建议阅读8分钟. 坚持原创,每一篇都是用心之作- 前面聊完的2个章节「数据一致性」和「高可用」其实本质是一个通过提升复杂 ...
- 分布式系统关注点:无状态
来源:跨界架构师 初识「状态」 之前在「负载均衡」中提到过一个例子,我们再翻出来一下. 开发Z哥对运维Y弟喊:"Y弟,现在系统好卡,刚上了一波活动,赶紧帮我加几台机器上去顶一下." ...
- 分布式系统关注点(9)——想通关「限流」?只要这一篇
如果这是第二次看到我的文章,欢迎右侧扫码订阅我哟~ ? 本文长度为2869字,建议阅读8分钟. 可能你在网上看过不少「限流」相关的文章,但是z哥的这篇可能是最全面,最深入浅出的一篇了(容我飘几秒-) ...
- 纠正一个错误,分布式系统关注点第17篇
这里是Z哥的个人公众号 每周五早8点 按时送达 当然了,也会时不时加个餐- 我的第「78」篇原创敬上 今天来加个餐,紧急纠正一个错误.先和大家说一声抱歉:D 昨晚睡觉前,惯例打开「订阅号助手」回复一些 ...
- 分布式系统关注点(2)——烦人的数据不一致问题到底怎么解决?——通过“共识”达成数据一致性...
阅读目录 "共识"是什么?为什么会产生? 拜占庭将军问题 BFT类算法 CFT类算法 结语 这次准备开启一个新的系列来写了,聊聊分布式系统中的关注点.节奏不会排的太紧凑,计划两周一 ...
- 分布式系统关注点(20)——阻塞与非阻塞有什么区别?
如果第二次看到我的文章,欢迎右侧扫码订阅我哟~ ? 每周五早8点 按时送达.当然了,也会时不时加个餐- 前面一篇文章中,Z哥和你聊了「异步」的意义,以及如何运用它.错过这篇文章的可以先去看一下再来( ...
最新文章
- 如何使用TensorFlow Eager执行训练自己的FaceID ConvNet
- 用polt3画曲面_用SolidWorks建模一个:防滑板曲面造型
- python for循环习题
- java memcachedclient_Java memcached client怎样建立长连接
- 《Android编程权威指南》PhotoGallery应用梳理
- pcs7更改项目计算机名时出错,PCS7 C/S报警问题-工业支持中心-西门子中国
- postgresql数据库去重方法
- WIN 10 安装 Hadoop 2.7.7 + Spark 2.4.7 记录
- linux认令牌操作错误,验证令牌操作错误
- 关于一些电脑使用的小技巧
- mysql_用户_操作
- java复习系列[3] - Java虚拟机
- 剑指offer——12.矩阵中的路径(不熟)
- Linux命令之awk:高级输入输出(四)
- imsi、 ICCID、ki、IMEI
- dubbo学习视频教程
- DirectX修复工具
- 开启本地网易云api接口后端服务器
- 宝塔面板添加站点及运营商SSL免费证书的申请与使用
- Duplicate Cleaner Pro v5.0.13 电脑重复文件查找清理工具